
基于SOM聚类的多模态医学图像大数据挖掘算法
2019-08-29 02:33李晓峰
西安工程大学学报 2019年4期
李晓峰,李 东
(1.黑龙江外国语学院 信息工程系,黑龙江 哈尔滨 150025; 2.哈尔滨工业大学 计算机科学与技术学院,黑龙江 哈尔滨 150001)
0 引 言
SOM聚类是一种由自组织映射神经网络衍生出的信息处理算法,可以按照图像或文本的一般发展规律,对需要处理的数据信息进行分类操作,且最终归为一类的信息参量大多都具备明显的事物特点。从信息层面来看,这种操作方法是无指导性的,且在分类处理的过程中不需要对事物进行区分判断,只是依靠信息间的特征相似性来满足聚类处理需求[1-2]。不同于其他聚类算法,SOM聚类对特定数据及其所处环境的密度条件进行了严格限制,并且完成处理操作后的数据集中不可能含有任何不相关因素,具备较为精准的聚类处理结果。
在现有技术手段的支持下,相关医学研究组织只能依靠耦合字典技术,对已成片的医学图像进行分类存储处理[3-4]。但随着成片量的不断增加,一部分图像开始出现严重的帧率重叠行为,不仅造成原始图像灰度的急剧下降,也会引发一系列的图像数据冗余问题,对后续图像信息的挖掘调度造成极大困扰。所谓图像数据冗余是指在数据成像的过程中,由数据重复引发的存储不均或过量存储现象,不仅会造成图像中真实信息的大量流失,也会对图像的成像清晰度造成一定的负面影响。帧率重叠是一种常见的图像故障问题,常与图像数据冗余现象伴随出现。在特定情况下,一定程度的帧率重叠可能带来图像清晰度的小幅提升,但过量的帧率重叠行为会导致图像模态属性的严重损伤,进而造成冗余区域内图像数据的大量攀升。为解决上述问题,引入SOM聚类理论,搭建一种具备提升成像质量能力的多模态医学图像大数据挖掘算法,并通过逐层分析运算的方式,验证该方法的实际效果。
1 基于SOM聚类的多变量分析
1.1 SOM拓扑结构搭建
联合SOM拓扑结构,在确保良好聚类变量初始权值设定结果的基础上,完成基于SOM聚类的多变量分析处理。SOM拓扑结构作为神经网络的分支体系,遵循严格的分层组织交流形式。相邻神经网络层、邻近神经元、上下级神经元等网络组织间的交流连接,组成了SOM结构的组织拓扑关系。通常情况下,每一层神经网络中的神经元数量基本相等,且这些结构节点间始终保持纵横交错的拓扑连接关系。在神经网络下端只包含3个单独的SOM节点,作为网络与外界图像或文本信息进行物理交流的通路,所以在神经网络中处于末级位置的神经元必须包含3个额外的连接通路。与其他神经元组织相比,末级神经元具备更加完善的图像或文本信息感知能力,且作为与SOM节点最为靠近的物理结构,可以始终保持较为高速的数据传输能力。
1.2 聚类变量的初始权值设定
聚类变量初始权值设定是在SOM拓扑结构的基础上,对可利用挖掘图像或文本信息进行的集成收敛能力判断。现有数据挖掘算法主要采用随机赋权的方式,处理本体结构的权重输出数值,所以最终的输出值只能在0和1之间随机选择,且整个挖掘输出层模式只能处在一个有限的空间结构之中[5-6]。而SOM聚类分析却将可利用挖掘图像或文本信息的初始权值作为定义变量的重要数据,不仅在各个随机方向上,对权值可能出现的分布区间进行了假说模拟,也要求所有初始权值出现的节点位置必须达到收敛要求。如果D代表SOM拓扑结构的聚类变量上限,G、J分别代表可利用挖掘图像或文本信息初始权值位置条件的上、下限定数值,联立D、G、J可将SOM具备变量的初始权值设定结果表示为
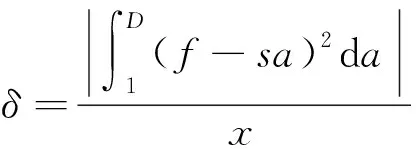
(1)
式中:f为可利用挖掘图像或文本信息的最大化采集数值量;s为数据挖掘系数;a为可同时处理的数据挖掘量;χ为初始权值的位置限定参量。
2 多模态医学图像的集成聚类融合
以医学图像作为处理目标,利用基于SOM聚类多变量分析结果,按照图像预处理、多模态集成正负性相关的操作流程,实现多模态医学图像聚类融合标准的建立,完成大数据挖掘算法搭建的前期准备操作。
2.1 原始医学图像预处理
原始医学图像预处理以SOM聚类多变量分析作为操作基础,在确保图像信息初始权值满足应用需求的前提下,对像素波段进行提取、罗列等处理,使医学图像的成像对比清晰度得到有效提升,并通过定义原始和预处理后图像灰度的方式,建立满足多模态相关要求的图像集成正负性标准。在正常情况下,原始状态下的医学图像始终保持黑白表现关系,成像清晰度相对较低,且图像中的脑部组织形态表现不明确,不能通过反射成像原理充分确定图像背景与中心目标间的成像温度差,进而易导致被定义的多模态集成正负性标准出现较大物理偏差[7]。经过SOM聚类多变量分析处理后的人体脑组织医学图像。预处理后的医学图像成像清晰度得到显著提升,且脑部组织形态出现非黑白对比关系。在反射成像原理的支持下,图像背景与脑部组织间的成像温差得到有效区分,与原始图像相比,被定义的多模态集成正负性标准更易接近真实数值情况。
2.2 多模态图像的集成正负性相关


(2)
式中:p为多模态集成的相关影响系数;R(δ)为与聚类变量初始权值相关的定义函数。
2.3 图像聚类融合标准的建立
医学图像聚类融合标准是大数据挖掘算法实施的前期条件,可以通过分辨集成正负性相关结果的方式,达到准确限定决策树初始位置的目的。单纯从数值分析角度来看,完成信息融合前的医学图像始终保持预处理完结状态,且色温条件是反应图像信息内容的唯一物理条件。但这种简单的图像内涵排列形式不足以支撑大数据挖掘对信息的物理需求,虽然预处理后的医学图像成像清晰度较高,且色温对比度明显,但大数据决策树是一种具备较强信息提取能力的物理组织,不仅直接屏蔽图像信息中的清晰度关系,也对集成正负性相关结果提出了更高的应用限制条件[8]。总的来说,原始医学图像预处理为多模态图像集成正负性相关提供了便捷条件,而在这种相关性关系支持下,建立的聚类融合标准才是后续图像大数据挖掘所遵循的物理依据。图像聚类融合标准的详细函数结果如表1所示。
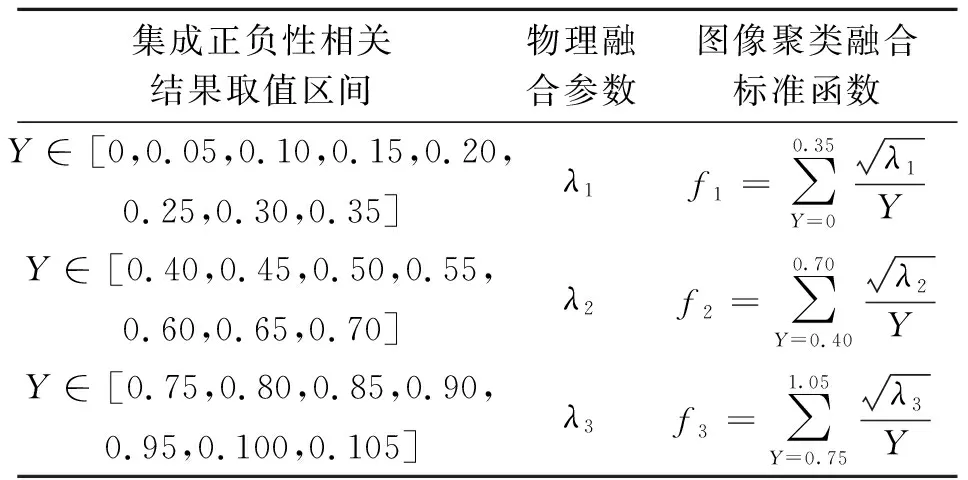
表 1 图像聚类融合标准解析表
3 大数据挖掘算法研究
随着医学图像多模态聚类融合标准的逐渐完善,大数据决策树得以完整构建,并在后续判断与改进原理的支持下,完成全新大数据挖掘算法的建立与应用(后续搭建过程中,默认医学图像聚类融合标准函数满足第一组取值结果)。
3.1 大数据决策树构建
大数据决策树是一种具备信息统计功能的挖掘固件组织,可对待处理的图像或文本信息进行清晰分类处理。作为大数据挖掘算法的骨架支撑结构,决策树采用非回溯搭建原理,从一组无规则的、无序的、类标号情况已知的训练数据样本中推导出树结构的主体树形结构,再进行末级的枝叶结构划分。以多模态条件下的医学图像信息为例,大数据决策树的最顶层根节点应为已成像的医学图像样本,所有叶子节点均表示不同的图像信息类标号,其他内部节点则表示对挖掘结果的逻辑判断结果,而树体的边则代表分级运算的分支结果[9-10]。根据固有的决策树属性可知,医学图像样本的总量必须保持单一且固定,但由于预处理后医学图像的灰度条件有所提升,不同信息结构所表现出的成像温差也有所不同,所以叶子节点数量始终不固定,受到图像信息类标号结果的直接影响[11-13]。
3.2 医学图像的多模态挖掘种类判定
医学图像多模态挖掘种类判定可从局部特征、关联规则、孤立点3个分析角度同时进行。满足局部特征分析要求的医学图像多模态挖掘结果具备最高的对比清晰程度,且可直观表现待挖掘信息在医学图像中的所处位置,但依据此标准所进行的挖掘操作相对粗糙[14-15]。满足关联规则分析要求的医学图像多模态挖掘结果能清晰反应待挖掘信息在纵深方向的位置条件,但不能清晰确定该信息在医学图像中所处的真实位置。满足孤立点分析要求的医学图像多模态挖掘结果真实程度最高,但位置确定水平最薄弱,只适用于单个的信息数据挖掘处理[16-18]。
3.3 图像挖掘节点的并行化改进
根据医学图像多模态挖掘种类判定结果可知,满足大数据挖掘算法应用需求的节点分类现状,共包含3种情况[19-20]。在默认医学图像聚类融合标准函数满足第一组取值结果的前提下,利用大数据决策树对图像信息进行挖掘处理,并将处理后的真实物理量定义为图像挖掘节点的并行化改进结果。设l1、l2、l3分别代表3种不同的图像挖掘节点并行化改进结果,μ1、μ2、μ3代表与其分别相关的大数据决策条件,联立式(2)与第一组聚类融合标准函数取值结果,可将l1、l2、l3的计算过程表示为

(3)
式中:x=0,1,…,5;kx代表多模态医学图像中待挖掘信息的权限值;ε1、ε2、ε3分别代表3种不同的挖掘强度。
4 平台搭建及算法测试
4.1 大数据挖掘平台
大数据挖掘平台作为本次实验的唯一应用背景条件,以含有32G内存空间、2T硬盘空间的4 GHz处理器作为挖掘检测设备。此外,所有数据编码行为均采取Eclipse开发形式。在真实的算法测试现场图中存在主机A和主机B,主机A搭载完整的大数据挖掘平台结构,所有平台搭建背景条件也仅适用于主机A,随着测试时间的不断增加,主机A中会逐渐显示出完整的多模态医学图像(默认挖掘对象为人体脑组织)。主机B为相关实值输出装置,随着测试时间的不断增加,主机B中会显示出于医学图像成像质量、图像数据冗余度相关的波形或数据参量。
4.2 实值比对
在确保主机A能提供稳定输出图像的前提下,闭合所有电源装置,开始实验组和对照组的挖掘算法检测操作。利用图像灰度检测软件记录经过挖掘算法处理后的实验组和对照组医学图像灰度数据,并根据软件绘图功能生成如图1,2所示的灰度直方图。已知医学图像成像质量水平与灰度数据间的关系:灰度数据越集中、单一最大值越低则成像水平越高,反之则越低。
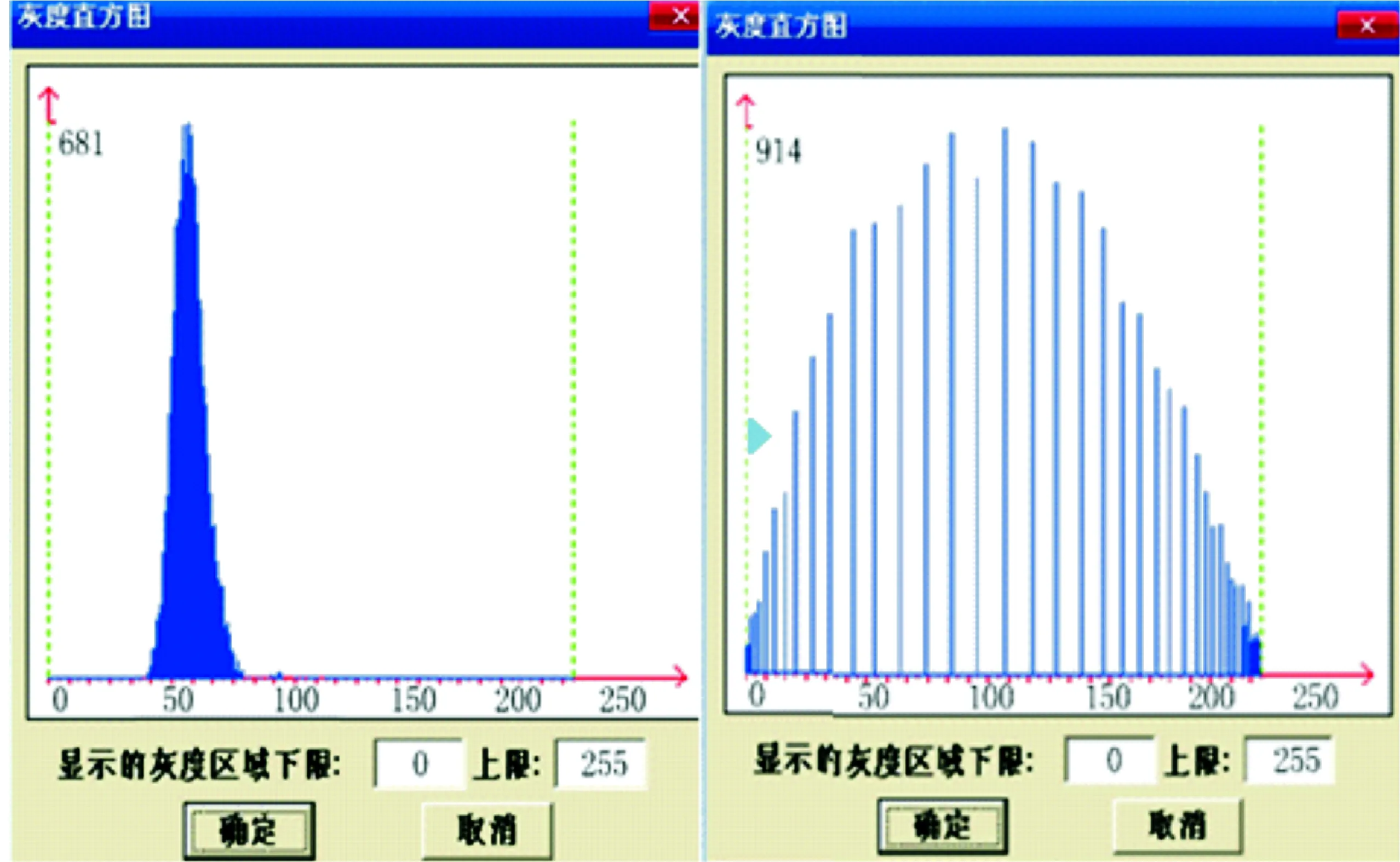
图 1 医学图像成像质量比对图(a)Fig.1 Medical imaging quality comparison chart(a)
在图1中,显示灰度下限为0、上限为255的物理条件下,以每5 min实验时间内最明显的医学图像灰度信息作为目标数据,将45个连续的目标数据表示在同一背景环境中。其中左半部分表示实验组图像灰度结果,右半部分表示对照组图像灰度结果。对比两图可知,应用实验组挖掘算法后,医学图像的灰度分布情况呈现明显的集中状态,且最大值仅维持在681左右;而应用对照组挖掘算法后,医学图像的灰度分布情况稀疏且散乱,最大值更是达到了914左右,远超出实验组数值。
根据图2可知,改变图像显示灰度的上、下限数值,使其分别等于755和255。左、右两部分所代表组别情况保持不变。对比两图可知,应用实验组挖掘算法后,医学图像灰度分布情况虽有小幅度扩散,但总体依然呈现密集状态,且最大值基本保持不变;应用对照组挖掘算法后,所有灰度指标都不再保持单一状态,而是出现了一定的附加数值,从图像来看虽然密集状态有所提升,但混乱的灰度信息易造成医学图像出现失真现象,对医学图像成像质量提升起到负面影响。
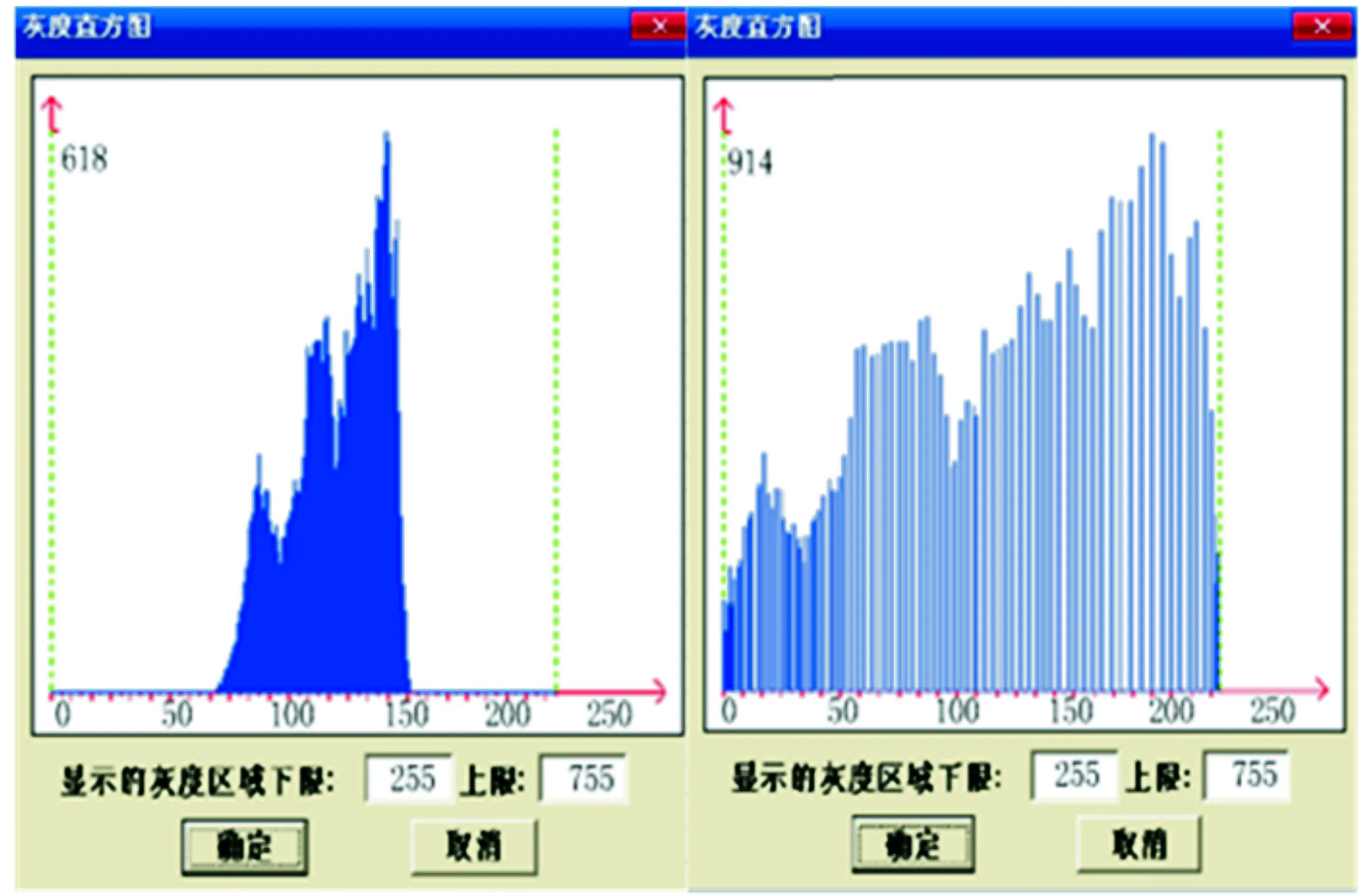
图 2 医学图像成像质量比对图(b)Fig.2 Medical imaging quality comparison chart(b)
调节主机A中的大数据挖掘平台,使其中呈现的医学图像信息达到最清晰状态,利用主机B对主机A中的图像数据进行5次截取处理,并在Lightroom5图像处理软件的支持下对所截取到的数据进行嵌套处理,见图3。

图 3 图像数据冗余度比对图Fig.3 Image data redundancy comparison chart
图3左半部分画面代表利用对照组大数据挖掘算法后,得到的医学嵌套图像,右半部分代表利用实验组大数据挖掘算法后,得到的医学嵌套图像。已知画面中数据节点的重叠行为越明显,图像的帧率重叠情况就越严重,即图像数据冗余度越高。分析图3可知,应用实验组大数据挖掘算法后,得到的5次截取图像基本保持全等状态,最终生成的嵌套画面中也不包含明显的数据节点重叠行为,即该图像的帧率重叠程度相对较轻,图像的数据冗余度也相对较低;应用对照组大数据挖掘算法后,得到的5次截取图像不存在明显的全等属性,基本维持相互独立的存在状态,最终生成的嵌套画面中数据节点重叠行为也极为明显,即该图像的帧率重叠程度相对较重,图像的数据冗余度也相对较高。
5 结 语
随着SOM聚类程度的逐渐加深,多模态医学图像的成像清晰度得到有效提升,为后续大数据挖掘算法的实施与应用提供了即为便利的先决条件。在确保医学图像成像质量的基础上,对嵌套画面中的显示数据冗余度进行有效控制,使图像大数据挖掘算法的实效应用价值得到最大化发挥,与现有Intel算法相比,也始终具备更为广泛的应用空间。从搭建完整性角度来看,基于SOM聚类的多模态医学图像大数据挖掘算法对各级基础流程都进行了逐步规划,并细化了决策树等重要物理执行条件,从根本上提升了算法自身的推广价值。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
北京航空航天大学学报(2022年6期)2022-07-02
大众投资指南(2021年35期)2021-02-16
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
天津医科大学学报(2021年1期)2021-01-26
中国交通信息化(2020年1期)2020-07-27
江苏通信(2018年4期)2018-12-04
自动化学报(2017年5期)2017-05-14
自动化学报(2017年7期)2017-04-18
浙江理工大学学报(自然科学版)(2015年7期)2015-03-01
