
基于RFM的汽车售后服务业客户分类的研究
2019-09-03 08:14张婧
锋绘 2019年6期
张婧


摘 要:提出汽车售后服务企业客户消费的RFM模型,通过AHP法得到汽车售后服务业RFM指标的权重,并应用K-means聚类法对客户进行分类。分析各类客户的客户等级,并结合指标权重对各类客户进行客户价值比较分析。实证研究表明本文所提出的模型和方法可以有效地对汽车售后服务企业客户进行分类。
关键词:客户生命周期价值;客户分类;RFM;K-means聚类算法
1 引言
客户生命周期价值(Customer Lifetime Value,CLV)是客户细分最为重要的依据。依據客户生命周期价值对客户群进细分,可以使企业根据客户价值级别的不同决定如何在客户中分配企业有限资源,然后根据客户的不同需求,设计和实施不同的客户保持策略。其目的在于牢牢保持那部分对企业最有价值的客户,并把有潜力的当前低价值客户在未来转化为高价值客户,鼓励那些不论是现在还是将来都对公司无价值的客户转向其竞争对手,从而最终达企业的总体利润最大化。本文利用基于所提出的RFM的聚类算法对汽车售后服务业客户进行分类,分析每一类客户的消费行为特征和CLV,并基于某汽车售后服务企业2017年度的服务记录数据进行实证研究。
2 汽车售后服务业RFM模型及权重
2.1 汽车售后服务业RFM模型
RFM由三个基本因素构成,即近期(Recency, R)、频数(Frequency, F)和金额(Monetary, M)。RFM模型是一个简捷、实用的客户或市场划分的模型。RFM模型同样适用于汽车售后服务业的客户分类。该行业的RFM指标与传统的RFM指标含义比较如表1所示。
2.2 RFM权重分析
三个指标变量(R,F,M)对于衡量汽车售后服务业的客户的忠诚度和价值的重要性是不一样的。本研究利用层次分析法(AHP)计算出RFM三种指标的权重,从而为用RFM分析划分客户群提供科学、可行、简便的方案。
用层次分析法分析问题大体要经过以下五个步骤:(1)建立层次结构模型;(2)构造判断矩阵;(3)层次单排序;(4)层次总排序;(5)一致性检验。其中后三个步骤在整个过程中需要逐层地进行。
3 基于K-means聚类法和CLV的客户分类
应用K-means聚类法,以加权RFM为指标,将具有相同RFM变动情况的客户归为一类,然后计算各类的客户生命周期价值CLV,根据CLV的取值对客户进行二次分类,基本思路如下:
(1)应用AHP法确定RFM各个指标的权重wR 、wF、 wM;
(2)将RFM各指标标准化,并将各个指标加权:
由于R,F,M这三个变量的度量不统一,为了避免聚类结果对度量单位的依赖,数据应当使用统一的度量标准,即数据应当标准化。
设θL为客户群中R(F或M)变量的最大变量值,θS为客户群中R(F或M)变量的最小变量值。对于R变量,它对客户生命周期价值有负的影响,因此,R变量用公式θ′=θL-θθL-θS来进行标准化。R标准化后的变量用R′来表示。对于F和M两个变量,它们对客户生命周期价值有正的影响,因此,F和M两个变量用公式θ′=θ-θSθL-θS来进行标准化。F(或M)标准化后的变量用来F′或(M′)表示。
设加权后的RFM变量分别计为R″、F″、M″,则:
R″=wR×R′,F″=wF×F′,M″=wM×M′
客户价值细分最终根据加权的RFM变量即R″、F″、M″进行聚类分析。
(3)确定聚类的类别数量m。
本模型中客户分类通过每位客户类别RFM平均值与总RFM平均值相比较来决定的,而单个指标的比较只能有两种情况:大于(等于)或小于平均值,因此可能有2×2×2=8种类别。
(4)应用K-means聚类法对加权后的RFM指标进行聚类,得到m类客户。
用于聚类分析的数据R″、F″、M″得到后,即可以开始进行聚类分析。
首先,进行数据清洗。包括异常值处理和数据标准化。
然后,将得到的清洗过的数据采用K-means聚类法进行聚类,使用spss软件将数据分成m类;
(5)将每类客户的R″、F″、M″平均值和总R″、F″、M″平均值作比较,每次对比有两个结果:大于(等于)平均值和小于平均值,通过对比得到每类客户RFM的变动情况。
(6)根据每个客户类别的RFM的变动情况分析该客户类别的性质,如该客户类别是倾向于忠诚的还是倾向于背离的,然后在此基础上定义客户类型。
(7)对每类客户标准化后的各个指标取平均,将平均值加权求和,得到每类客户的CLV总得分,分析各类客户生命周期价值的差别,运算公式为:
CLVj= M R″+M F″+M M″
其中M R″、M F″、M M″分别代表上文中的R″、F″、M″变量在各类中的平均值。最后,根据总得分的大小来对各类客户来进行排序。
4 某汽车4s店实证研究
4.1 客户分类
本实证研究基于某汽车4s店2017年的服务记录共25645条。确定RFM模型各指标含义后,结合实证数据,确定需要的数据内容,整理出后期用于聚类分析的数据共5486条。
根据判断矩阵计算出三个指标的相对权重。经过对决策小组各专家的咨询,确定出 RFM 变量的权重分别为 wR=0.221,wF=0.341,wM=0.438。可见消费金额(M)对客户生命周期价值的影响最大。
根据筛选出来的某汽车售后服务厂2017年的服务记录结合RFM模型确定的用于聚类分析的数据共24条进行客户类型识别分析。设加权后的RFM变量分别计为R″、F″、M″,则R″=wR×R′,F″=wF×F′, M″=wM×M′,计算后取3位小数。
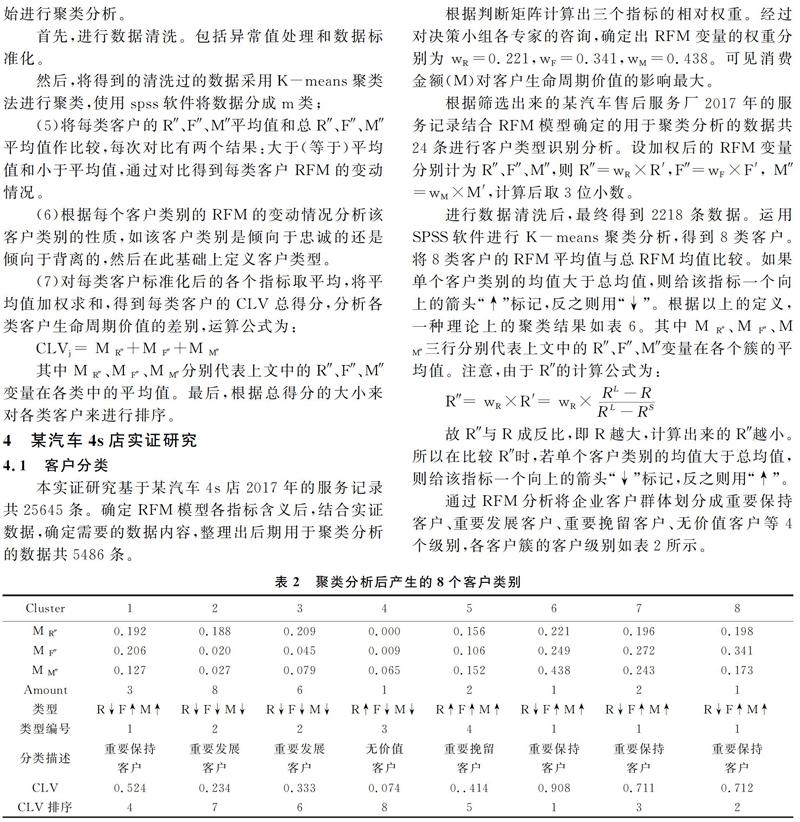
进行数据清洗后,最终得到2218条数据。运用SPSS软件进行K-means聚类分析,得到8类客户。将8类客户的RFM平均值与总RFM均值比较。如果单个客户类别的均值大于总均值,则给该指标一个向上的箭头“↑”标记,反之則用“↓”。根据以上的定义,一种理论上的聚类结果如表6。其中M R″、M F″、M M″三行分别代表上文中的R″、F″、M″变量在各个簇的平均值。注意,由于R″的计算公式为:
R″= wR×R′= wR×RL-RRL-RS
故R″与R成反比,即R越大,计算出来的R″越小。所以在比较R″时,若单个客户类别的均值大于总均值,则给该指标一个向上的箭头“↓”标记,反之则用“↑”。
通过RFM分析将企业客户群体划分成重要保持客户、重要发展客户、重要挽留客户、无价值客户等4个级别,各客户簇的客户级别如表2所示。
4.2 CLV比较分析
根据每一类客户的客户CLV来进行二次排序,运算公式为:
CLVj= M R″+M F″+M M″
其中M R″、M F″、M M″分别代表上文中的R″、F″、M″变量在各个簇中的平均值。最后,根据总得分的大小来对各类客户来进行排序。
排名靠前的客户相对排名靠后的客户具有更高的客户价值,忠诚度更高,对于企业来说更为重要。表2显示,客户簇6的CLV最高,客户簇7和8的CLV次之,客户簇1的CLV最低,因此属于客户簇6的客户是企业最有价值的客户,在企业资源有限的情况下,应最优先考虑该类客户的需求。此外,对于处于同等级的客户簇2和3也进行了细分,从表2中可以看出,尽管都属于重要发展客户,但客户簇3比4的价值更大,应优先发展属于该客户簇的客户。
5 结论及展望
客户分类是根据任何一个客户属性划分的客户集合,它是成功实施客户保持策略的基本原则之一。本文就是运用长期预测的CLV分析法与短期预测的RFM方法两套客户属性指标结合对汽车售后服务业的客户进行基于客户行为数据的分类,针对具有不同特点的每一类客户企业应采用不同的客户策略,以期获得最大的利润。
参考文献
[1]林彦,蔡启明.生命周期意义下的客户资源价值挖掘研究[J].统计与信息论坛,2004,11:31-33.
[2]陈明亮,李怀祖.客户价值细分与保持策略研究[J].成组技术与生产现代化,2001,18(4):23-27.