
基于大数据的多金属矿综合信息找矿模型研究
2019-09-04 12:40朱飞燕
中国锰业 2019年4期
朱飞燕
(西安航空职业技术学院,陕西 西安 710089)
全球经济一体化战略的深入推进为我国工业发展带来前所未有的机遇,作为工业生产的主要原料,金属矿产资源受到来自于各领域的密切与广泛关注[1]。当前,我国矿产资源短缺,供不应求,因此,国家战略明确提出要实施地质找矿战略工程,加强勘察,进行金属矿等重要矿产资源储备体系的建立,取得地质找矿重大突破。然而,面对国家地质数据爆炸式增长态势的出现,我国金属矿勘察工作由原来的浅部、易识别逐渐转变为隐伏、难识别,从而加大了找矿难度,因此,勘察工作的成功需要依靠新理论、新技术方法的提高。积极研究新的更有效的金属矿产资源信息采集与分析方法,有效提高找矿效率。
大数据技术包括对海量数据的获取、存储、计算、分析及可视化技术,是现阶段第4范式的主要工具,正引发地球科学领域的深刻变革。数据的大并非大数据的关键,其关键应当是思维的新,他从数据出发,让数据说话,以人工智能方法为支持,逐渐让机器学习、深度学习、可视分析等技术成为必需[2]。怎样从数据抽象出模型,并对模型进行分析。从理论层面看,只要具备代表性足够的样本,便可采取数学方法确定一个或一组模型的组合,使其与真实情况相类似。计算机技术的进步、大数据的普及使基于大数据的模型构建与分析得以实现。以大数据的发现与挖掘为入手点,进行多金属矿综合信息找矿模型的建立,并基于大数据机器学习完成找矿模型预测,为矿产资源大数据的发现与挖掘、找矿模型建立与预测工作的开展提供可借鉴的方法。
1 大数据处理流程
图1为大数据的处理流程[3]。从数据源处获取的数据,在结构上存在结构、半结构、非结构的不同,需采用特殊的方法进行相应的处理与集成,使其转变为标准统一的数据格式,为后期的处理工作提供便利;之后,运用恰当的数据分析方法处理与分析这些数据,在可视化技术支持下将结果呈现给用户。
1.1 数据采集
大数据之“大”,本就是数量多、种类复杂的体现,采用多种方法获取数据甚为关键。在大数据处理流程中,最基础的就是数据采集,目前较为常用的数据采集手段是:传感器收取、视频识别、数据检索分类等。随着智能手机、平板电脑等移动设备的普及,越来越多的移动软件被开发应用,社交网络不断扩大,在加快信息流通速度的同时亦提高了数据的采集精度。
1.2 数据处理与集成
主要是处理、清洗已采集到的数据,并对其进行进一步的集成与存储。经各种渠道获取的数据种类与结构十分复杂,需将其转换为单一或便于处理的结构,为后期的数据分析打基础。这些数据中可能掺杂一些噪音与干扰项,故还需对他们进行“去噪”与清洗,确保数据可靠性。常用的数据清洗去噪方法是进行一些数据过滤器的设计,采用聚类或关联分析等规则方法过滤无用或错误的离群数据。另外,数据的集成与存储亦十分重要,如果随意放置已整理好的数据,会影响其后期的取用。目前常用的数据集成与存储方法为建立专门的数据库,对类型不同的数据信息进行类放置,以此减少数据查询与访问时间,提高提取效率。

图1 大数据处理基本流程
1.3 数据分析
在整个大数据处理流程中,数据分析最为核心,可发现数据的价值所在。传统数据处理分析方法有数据挖掘、机器学习、智能算法以及统计分析等,随着进一步的发展,云计算技术得以出现,分布式文件系统GFS、分布式数据库BigTable、批处理技术MapReduce、开源实现平台Hadoop等均以云计算为依托,共同为大数据的处理与分析提供良好手段。
1.4 数据解释
大数据分析结果的解释与展示是数据信息用户最关心的内容。随着数据量的不断增大,数据分析结果愈发复杂,采用传统数据显示方式已难以对数据分析结果的输出需求予以满足。为了增强数据解释与展示能力,数据可视化技术(基于集合、基于图标、基于图像、面向像素等技术)得以出现并得到了快速的发展,他能形象地展示数据分析结果,为用户理解与接受提供便利。
2 多金属矿找矿模型及预测技术方法
针对多金属矿找矿需求,基于传统的多金属矿综合信息找矿数据应用,对大数据技术加以运用,进行找矿专题信息数据的采集与处理,之后,在大数据分析与解释方法的支持下开展多金属矿综合信息找矿模型的预测工作[4],实现大数据相关技术在多金属综合信息找矿领域的应用,图2为其技术方法。
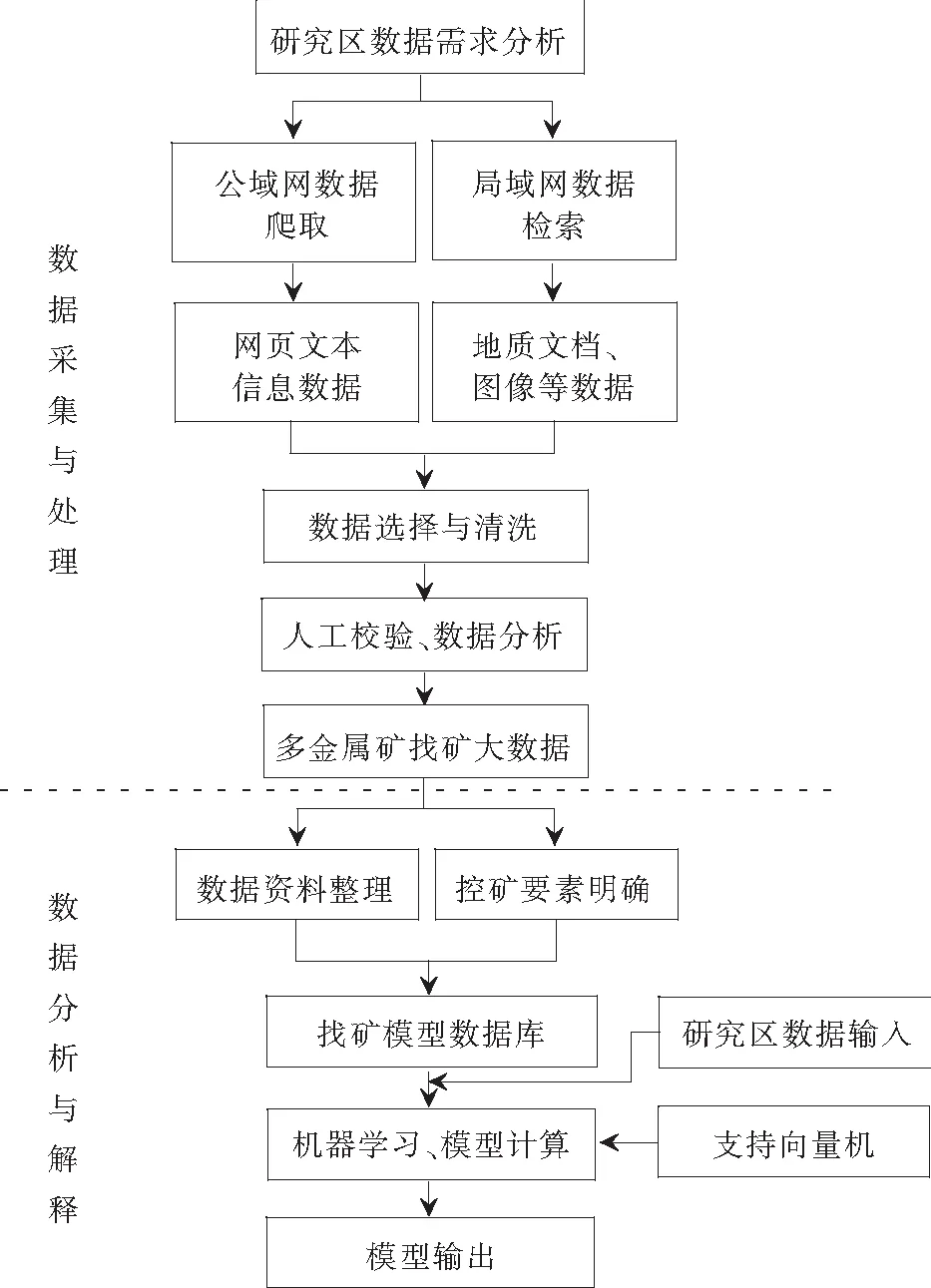
图2 模型构建与预测技术方法
1)多金属矿综合信息数据采集与处理主要通过爬虫与正则表达式爬取与抽取公域网数据,借助Everything.dll方法全盘搜索与获取局域网络内的计算机本地数据,之后,按照统一的清洗与存储标准执行对所采集到的数据的处理操作,得到多金属矿综合信息找矿专题大数据。
2)数据分析与解释是在获取的研究区金属矿综合信息找矿专题大数据基础之上,与人工选择确认的方式相结合对数据进行整理,系统归纳并总结传统的多金属矿综合信息找矿模型,得到研究区的控矿要素,执行对统一找矿模型数据库的建立操作。之后,采用大数据机器学习方法中的支持向量机算法分析研究区数据模型,完成找矿模型预测。进一步地,在原数据中添加得到验证的找矿模型,将其作为之后机器学习的训练样本,丰富数据—信息—知识—价值服务—再数据的大数据应用链。
3 找矿模型构建与预测
3.1 模型构建
找矿模型构建即以多金属矿综合信息大数据为基础,进行找矿模型及找矿模型数据库的建立,提供重要数据基础于后期的机器学习。模型构建工作主要涉及数据整理与模型数据库建立两项工作。
1)数据整理:①对典型矿床式命名与抽象总结式命名两类模型名称进行整理,出于对两者无法统一的考虑,将模型中的关键词统一即可;②整理控矿要素,在模型数量不断增加的过程中,同一控矿要素会重复出现,然而,不同多金属矿综合信息数据资料中控矿要素文本数据并不严格一致,为了使计算机可对控矿要素进行准确的识别,需确保同一控矿要素文本数据的惟一性。
2)模型数据库建立,在多金属矿综合信息大数据的机器学习中,应进行统一的、对全部金属矿床成矿模式或矿床式均有适用性的找矿概念模型数据结构的建立。受资料来源不同、资料记载的成矿地质条件与矿产勘察程度存在差异等因素的影响,致使在建立找矿模型时,对其理解与具体操作并不统一,同一名称属不同概念、不同名称又属同一内涵的情况时常出现于不同资料中。所以需根据多金属矿综合信息大数据建立起找矿模型同控矿要素的对应关系。
3.2 模型预测
运用大数据机器学习理论进行多金属矿综合信息找矿模型预测,即进行能够让计算机自动“学习”的算法的设计,使其自动分析多金属矿综合信息大数据,从中获取隐含的内在数据规律,利用规律预测未知的多金属矿数据[5]。
1)支持向量机原理。在机器学习方法中,支持向量机是一种以统计学习理论为基础的监督分类算法,在模式识别、图像分类等诸多领域均有应用。支持向量机从线性可分情况下的最优分类面演化而来,目的在于按风险最小化原理进行目标函数的构造,尽可能区分两类模式,亦即得到一个最优分类超平面。图3所示为其基本思想。
设样本集为(xi,yi),i=1,…,n,x∈Rd,y∈{+1,-1}。在线性可分的条件下,存在一个能够将两类样本完全分开的超平面w·x+b=0,他是分类距离最大时的平面,满足条件yi[(w·x)+b]≥1,i=1,2,…,n,且分类间隔2/‖w‖最大。

图3 SVM的基本思想
在线性不可分条件下,SVM经非线性映射Φ:Ra→H将样本映射至高维特征空间,采用原空间的函数进行内积运算,并在这一高维特征空间执行线性分析任务。以泛函理论为依据,只要一种核函数符合Mercer条件,他便与某一空间中的内积相对应。故在最优分类上对适当核函数予以采用便可完成此种线性不可分的分类问题。
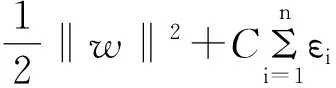
2)基于支持向量机的模型预测。应用R语言包e1071包含的SVM模型进行多金属矿综合信息找矿模型预测,需按以下步骤执行。
①优化SVM参数。采用网格寻优法对样本集进行参数优化,明确惩罚因子C与核函数参数G的搜索范围,计算各样本集SVM模型的最优参数。之后分别选择线性核函数、多项式核函数、径向基核函数以及神经网络核函数参与SVM模型的训练,以已知的样本组合作为测试集,按照预测到的样本组合个数进行最优模型的选择。
②评价不同样本集下SVM模型的预测效果。作为模型评价的一个重要指标,分类精度评价主要对测试样本中正确分类的个数进行统计,得到分类误差矩阵,并对其他分类的精度判断参数进行进一步计算。针对二分类问题,给出一个分类器与训练样本集,前者将后者映射至预测类别,这时可能的输出包括4类,可通过混淆矩阵来表示,如表1所示。

表1 混淆矩阵
表1中的主对角线给出了每一类正确分类的样本个数,非对角线上的元素表示的则是没有被正确分类的样本个数。以该矩阵为基础对模型进行预测的参数包括以下几类:敏感性=TP/(TP+FN);特异性=TN/(FP+TN);总体精度=(TP+TN)/(TP+FP+FN+TN);误分类率=(FP+FN)/(TP+FP+FN+TN);假正率=FP/(FP+TN);假负率=FN/(TP+FN)。
③预测制图。选择具有代表性的样本集作为训练样本,利用SVM回归方法得到各统计单元的预测概率,进行预测概率与累计面积变化曲线的绘制。根据研究区域面积的10%、50%与80%分级预测概率,一、二、三级分别与高、中、低潜力区对应,高与中潜力区即成矿有利区。
4 多金属矿找矿模型构建与预测实例
以内蒙古浩布高地区为例进行分析,主要流程含数据采集、控矿要素选取、机器学习、模型计算以及找矿模型输出。区域内矿床以高铅锌多金属矿床为主,有多处已知多金属矿点。
4.1 控矿要素分析与模型数据库建立
基于成矿带范围内资料解释,以金属矿的控矿条件、矿化现象为目标,建立起各类信息的系统关联性,对他们之间的相关关系进行探讨[6],建立内蒙古浩布高成矿带的金属矿综合信息找矿模型。主要控矿要素包括:①控矿构造:以北东向断裂构造为主,矿体的赋存位置在构造的叠加复合处;②含矿地层:二叠系中通大石寨组;③控矿岩体:燕山晚期花岗岩;④接触带:燕山晚期花岗岩与二叠系中通大石寨组地层接触带;⑤围岩蚀变:主要是绿泥石化、萤石化等矽卡岩化蚀变;⑥物探:航磁异常在整体上呈低缓之势,矿化区以低缓正磁异常为主;⑦区域化探:水系沉积物Ag、Pb、Zn异常总体上呈现出北东向展布,有较高吻合度,另外,还有As、Sb、Sn、W等元素异常。
基于GIS进行综合信息找矿专题数据库的建立,该数据库包含的数据有:①地层、岩浆岩、构造、岩脉、蚀变等基础地质;②重力异常与航磁异常的物探数据;③Ag、Pb、Zn与相关元素地区化学异常的化探数据;④已知矿床与多金属矿化点等信息标志。
4.2 基于支持向量机的多金属矿预测
根据已明确的控矿要素与模型数据库,按照100 m×100 m的网格单元对研究区进行划分,一个统计单元中包含的已知矿点数量最大为1,对各单元中10种控矿要素进行统计。经处理,确定20个训练样本集。
1)SVM参数优化。采用网格寻优法优化20个样本集,明确C与G的范围为[2-4,24],得到各样本集最优参数。将已知的矿组合作为测试集,明确4种函数下SVM正确预测的已知矿组合个数。结果显示,径向基核函数的适应性较好,模型训练统一对该核函数予以选用。
2)预测效果评价。以确定的优化参数C与G为基础,对径向基核函数予以选用,就20个样本集作SVM训练,结合混淆矩阵评价分类精度,五五为一组,样本T1~T5、T6~T10、T11~T15、T16~T20的评价分类精度分别为75.03%、81.81%、83.49%、85.08%,标准差分别为3.12%、3.88%、2.68%、2.03%。总体而言,样本集训练数量一致,分类精度较为稳定。另外,在训练样本集中样本个数的不断增加,总体分类精度亦有所上升,意味着训练样本的个数在一定程度上影响模型预测效果。
3)多金属矿预测制图。选择样本个数最多的T20,利用SVM模型进行多金属矿预测,结果显示研究区的中东部区域与西北角区域为成矿的有利区域。
5 结 语
分析以大数据为基础的多金属矿综合信息找矿模型的构建与预测方法,明确了多金属矿综合信息找矿专题数据的自动采集与处理、分析与解释具体方案,是大数据技术在矿产领域的应用与实践。研究过程中,提出了多金属矿综合信息找矿模型的具体建立思路,并对大数据机器学习算法中的支持向量理念加以应用进行相应的预测。模型的基础是地质信息与工作程度,这决定多金属矿综合信息找矿模型的建立与预测具有阶段性。在工作程度不断提高的进程中,信息源与信息量均会对模型产生影响,通过建立此模型,可为今后找矿工作提供一定的理论指导。
猜你喜欢
现代企业(2021年2期)2021-07-20
中学生数理化·高一版(2021年2期)2021-03-19
矿产勘查(2020年7期)2020-12-25
矿产勘查(2020年5期)2020-12-19
建材发展导向(2019年11期)2019-08-24
领导决策信息(2018年16期)2018-09-27
消费导刊(2018年8期)2018-05-25
数学学习与研究(2017年3期)2017-03-09
现代企业(2015年9期)2015-02-28
现代企业(2015年3期)2015-02-28
