
基于微博多维度及综合权值的热点话题检测模型
2019-09-05 10:32程克非邓先均陈旭东
重庆邮电大学学报(自然科学版) 2019年4期
程克非,邓先均,周 科,罗 昭,陈旭东
(1.重庆邮电大学 网络智能与网络技术重点实验室,重庆 400065;2.重庆市公安局 网络安全保卫总队,重庆 401120)
0 引 言
中国互联网络信息中心(China internet network information center, CNNIC)在京发布第42次《中国互联网络发展状况统计报告》[1]显示,截至2018年6月30日,中国网民规模达到8.02亿,互联网普及率为57.7%。越来越多的网民可以随时随地方便快捷地借助网络来自由表达对舆情事件的看法、态度和主张。如今网民可以自由地在互联网平台上畅所欲言,正所谓人人都是新闻记者,人人具有发言权,正如人人面前都有一个“麦克风”,互联网已然成为群众维权和表达民意较为快捷方便、有效的平台之一。自然而然,网络舆情对于社会的发展影响也就越来越重要。
微博作为网络舆情的主战场之一,对微博中的网络舆情进行研究具有重要意义。与传统的话题检测相比(如在线新闻和报纸),微博具有传播方式简单、传播速度快、影响力大、参与性和互动性强等特点,而且微博对热点话题非常敏感,这些使得微博对热点事件的传播起到了很大的作用。
微博热点话题检测不仅具有深远的经济和社会价值,而且也为各种商业和社交应用提供了更加强大和灵活的支撑。用户可以实时地了解重大事件、掌握社会热点、追踪社会动态[2];企业可以了解相关领域的发展动态,在对用户有吸引力的热点话题中寻找机会;相关部门可以及时了解当前社会热点事件和社会舆论的方向,对于帮助其及时有效地引导舆论、落实相应政策具有较大意义。
本文的贡献包括:①提出一个多维度热点话题度量模型,对话题热度进行多方位度量,能够更准确地对话题进行热度度量;②引入热度变化率,高效地过滤掉热度值较低的话题,再从微博网络舆情演化理论出发,使用回复加速度过滤掉已处于衰退、消亡阶段的话题,从而提高突发性热点话题检测的准确性;③提出的方法可以准确地检测出突发性热点话题,并跟踪其发展趋势,从而将较新的、有价值的热点话题推荐给用户,具有较高的应用价值。
1 相关工作
微博中的大部分数据都是关于人们的日常生活,只有部分微博含有流行事件信息。因此,面对复杂多样的微博信息,如何从中准确地提取出热点话题变得越来越重要。
围绕热点话题检测准确度低的问题,国内外诸多学者展开了相关方面的研究。Berardinelli等[3]提出了一种基于多维句子建模和时间线分析的热点话题检测方法;Steinbuch等[4]提出了一个名为潜在狄氏分配(latent Dirichlet allocation, LDA)的3级分层贝叶斯模型,这是一个生成离散数据集合的生成概率模型,如文本语料库。Bigeard等[5]根据查询中的术语改进相关文档的检测,提出了一种自动索引和检索的方法,该方法利用了术语与文档关联中的隐式高阶结构;Golub等[6]基于计数数据因子分析的统计潜在类模型,提出了一种新颖的自动文件索引方法;Sahu等[7]提出了一个在线主题模型,该模型识别文本流的新主题以及这些新主题随时间的变化规律,并自动捕获主题模式;W.Ou等[8]提出了一个正则化的主题模型,通过使用单词共现信息统计来增强主题学习;Kilany等[9]提出了一个名为时间区分概率模型(time discrimination probability model, TDPM)的主题检测模型,该模型在理论上等同于具有时间区分和权重特征选择的经典向量空间模型。所有上述研究成功应用于处理正常文本(如学术论文和新闻文章),但他们没有考虑到微博文本的特殊性。
根据微博的特点,现有的话题检测方法有很多都是针对微博设计的。Giacoumidis等[10]提出了一种改进的单通道聚类技术,该技术使用LDA模型代替传统的向量空间模型,可以提取隐藏的微博主题信息;Z.Yang等[11]提出了一种增量聚类框架,该框架可以基于时间特征和一系列内容快速检测热点话题;Jafariakinabad等[12]采用了一个名为核心项潜在狄利克雷分配模型的微博话题检测模型;Pang等[13]开发了一种新颖的主题模型,可以通过在整个语料库中明确建模词汇共现模式来捕捉短文内的主题;C.Zhang等[14]开发了一种高效的热点话题检测算法,可以在线处理大量推文。
但上述研究并没有考虑到微博热点话题度量的复杂性以及其在社交网络中的传递问题,从而导致热点话题检测精度低,在对突发性热点话题进行检测时尤为明显。
针对上述存在的问题,本文从多角度考虑影响微博话题热度的因素,提出一种多维度热点话题度量模型。该模型首先对话题进行筛选,得到一个热点话题初始集,再通过深入分析微博热点话题在社交网络中的传递机制,融入话题热度的影响力因子,计算各话题的综合权值,将话题的综合权值按照一定的权重与多维度热点话题度量模型进行有效融合得到基于微博多维度及综合权值的热点话题检测算法(hot topic detection algorithm based on multi-dimensions and comprehensive weights of microblog, HTDAMCW),通过对话题综合权值的考量来提高热点话题检测的质量。
2 多维度热点话题度量模型
微博热点话题度量的准确度会影响其检测质量。话题度量越准确,得到的热点话题初始集就越精确,否则就难以保证对微博热点话题的高质量检测。本文提出的多维度热点话题度量模型,包括点赞、转发、评论等[15-16]度量维度,然后根据实际情况赋予它们不同的权值,进行线性加权得到该话题的热度值,并且引用回复加速度[17]的概念来识别和量化话题热度随时间的变化特性。
通过对话题的热度度量和热度随时间变化特性的识别和量化,不仅可以过滤掉热度值较低或已处于衰退、消亡阶段的微博,保留处于加速或成长阶段的话题,还可以对回复加速度急剧增加的话题给予足够的关注,而这些话题往往容易发展成为突发性热点话题。
2.1 话题热度值度量
对微博话题的热度值进行度量,可以从微博的点赞、转发、评论等方面考虑。某个微博有高的点赞、转发、评论不一定含有热点话题,但如果该微博的点赞、转发、评论等指标不高或者偏低,那么可以肯定该条微博不包含热点信息[18]。所以通过计算话题热度值,给话题进行热度评分,可以有效过滤掉热度值低的话题。
让C={top1,top2,…,topM}成为一个微博话题集,其中,M是话题的数量。让Heat(topi)表示topi的热度,可以表示为
Heat(topi)=αLN(topi)+βFN(topi)+γCN(topi)
(1)
(1)式中:LN(topi)表示topi的点赞数量;FN(topi)和CN(topi)是topi的转发和评论数量;α,β,γ分别表示LN(topi),FN(topi),CN(topi)的权重系数,α+β+γ=1。
2.2 微博话题热度变化率
话题热度降序排列1和话题热度降序排列2分别如图1和图2。从图1和图2可以看出,如果选择前10个话题作为热点话题:对于图1而言,前16个话题热度差距不大,则会过滤掉部分热点话题;对于图2而言,只有前3个话题热度很高,其他话题热度都偏低,则会造成热点话题集中非热点话题过多。

图1 话题热度降序排列1Fig.1 Topic ranking in descending order 1

图2 话题热度降序排列2Fig.2 Topic ranking in descending order 2
针对上述问题,本文引入热度变化率来解决。通过对图1和图2的观察可以看出,当话题热度较低时,其Heat(topi)值会跳变。话题热度的跳跃点被定义为热度变化率的突变点,用Rate(topi)表示topi的热度变化率,计算式为
(2)
然后,根据话题的热度变化率进行过滤,设定阈值δ,如果热度变化率Rate(topi)>δ,那么热度小于或等于跳跃点值的话题将被过滤,否则,topi将作为高频话题变量保留,以便进一步聚类。
2.3 话题热度变化特性
根据微博网络舆情演化理论,微博话题的生命周期可分为突发、成长、衰退和消亡4个阶段[19]。处于衰退阶段的话题即使其热度值很高,已不可能演变成具有时间突发性的热点话题。因此,本文采用回复加速度的概念来识别和量化微博话题热度随时间的变化特性,表示为
(3)
(3)式中:a(topi)t是话题topi点赞、转发、评论加速度;Heat(topi)t为话题topi在时间t的点赞、转发、评论数;Δt为介于Heat(topi)t之间的时间粒度。
同时,定义一个状态函数S(topi):S(topi)→{acc,growth,dec,death},以标识微博生命周期中的不同阶段,该函数定义为
(4)
(4)式中:acc表示微博生命周期的突发期;growth表示微博生命周期的成长期;dec表示微博生命周期的衰退期;death表示微博生命周期的消亡期;θ1和θ2为预先设定的阈值;Heat(topi)t为常量0。
在突发和衰退期,微博的转发、点赞或急剧增加(a(topi)>>0)或强烈衰减(a(topi)<<0);在成长期,微博在单位时间内的转发和点赞基本不变;而在衰亡期,微博点赞、转发、评论数趋近于0。
2.4 微博综合权值计算
对微博进行热度度量在一定程度上能反应微博的热度,但如果要更深入探讨微博话题的热度,还要引入其他因子,如微博的质量(是否为认证用户所发)、话题参与人数等[20]。另外还要对微博的影响力进行度量,一个话题在整个话题集中占的比重越高,则他的影响力就越大,那么它的热度自然也就更高[21]。
本文利用话题的原创微博数量、参与人数、认证用户微博数量这3个因子来衡量话题的权值,为了方便计算,采用最大最小值归一化方法[22]对这3个特征因子作归一化处理。假设特征因子量化后为y,最大值为ymax,最小值为ymin,则归一化后的yn为
(5)
对原创微博数量、参与人数、认证用户微博数量分别进行归一化后,表示如下
(6)
(7)
(8)
(6)—(8)式中,y1,y2,y3分别表示对话题topi下的原创微博数量,参与人数,认证用户微博数量归一化后的结果。
取这3个特征因子归一化后数值的平均值,作为该话题的权值
W(topi)=(y1+y2+y3)/3
(9)
然后,本文再构建融入话题的影响力因素,构造如下公式来计算每个热点话题的综合权值
(10)
(9)—(10)式中:W(topi),W(topj)分别表示topi,topj的权值;n表示话题集中的话题总数;λ,μ表示权重系数,且λ+μ=1。
在此基础之上,对保留下来的微博建立话题集合TP={top1,top2,…,topm},其中,m为话题总量。
3 HTDAMCW
3.1 主题词相似度计算
由于多条微博所讨论的话题可能是同一个热点话题,因此,在对主题词进行聚类处理时,定义2个集合间的Jaccard系数作为它们的相似度度量,即
(11)
(11)式中:topi∈TP;topj∈TP。
3.2 算法描述
HTDAMCW算法主要针对突发性热点话题进行检测,该算法的实现过程主要分为5个步骤:微博热度值计算、话题热度变化率计算、微博话题回复加速度计算、主题相似度计算及选择、微博综合权值计算及热点提取。以下为该算法的具体实施步骤。
输入:R={R1,R2,…,Rn}(舆情话题集合)
输出:TP={th1,th2,…,thp}(热点话题集合)
步骤1对话题集R里面的微博进行分词处理,得到话题集H={top1,top2,…,topi};
步骤2利用(1)式计算舆情话题集H中每个话题的热度值Heat(topi),并按热度值降序排列,得到初始话题集H1={H1(topi)};
步骤3利用(2)式计算话题集H1里面每个话题的热度变化率Rate(topi),如Rate(topi)>δ则过滤,得到话题集H2={H2(topi)};
步骤4利用(3)式计算话题集H2里面每个微博话题的回复加速度a(topi)t,直接过滤掉a(topi)t<0的话题,得到话题集合ST={th1,th2,…,thn};
步骤5对于th1,th2,…,thn,选取最大话题max|thi|,利用(11)式计算相似度,当sim(max|thi|,thj)≥κ,则加入到话题集合H(thi)={thi,thj}中,否则转入步骤6;
步骤6ST=ST-H(thi),迭代计算转入步骤5,从ST中再次选择最大话题max|thi|,直到集合ST为空;
步骤7利用(9)式对热点话题集合H(thi)中每个话题的综合权值Wp(topi)进行计算;
步骤8按综合权值Wp(topi)降序排列热点话题,取前P个话题作为最终热点话题集合TP={th1,th2,…,thp}。
4 实 验
4.1 实验数据
首先,本文利用新浪微博API抓取并收集了2018年1月20日—9月30日共20 678条微博数据进行微博热点分析。该数据集来源于“人民网”、“新周刊”、“环球时报”、“环球网”、“头条新闻”、“微媒热点”、“齐鲁晚报”7大官媒微博平台,其字段为微博ID、关注数、评论数、转发数等。其次,本文利用关键词筛选跟踪爬取了9月1日—9月30日关于“顺风车”事件、“霸座”事件的微博数据用以热点话题走势分析。
4.2 评估指标
本文将基于词频和基于word2vec的检测和提取方法作为参照,利用准确率(precision)、召回率(recall rate)、和F-度量(F-measure)对热点话题检测的结果进行评价[23],具体计算公式如下。
1)准确率(Precision,P):提取的关键词中被确认为正确关键词的比率,计算式为
(12)
(12)式中:numi表示提取到的能正确反映微博主题的热点话题数量;numj表示提取到的不能反映微博主题的热点话题数量。
2)召回率(Recall,R):提取的正确关键词占所有正确关键词的比率,计算式为
(13)
(13)式中,numk表示没有提取到的但却能反映微博主题的热点话题数量。
3)系统综合性能(F-measure,Fm):为了量化系统的精确度,本文用F-measure(Fm)来分析实验结果,计算式为
(14)
(14)式中:Fm表示系统的综合性能;R表示召回率;P表示准确率;ω的值取1,Fm值越高,准确度越高,ω的值是召回率与准确率之间的相对权重,如果准确率更重要,ω的值大于1,如果召回率更重要,则ω的值小于1。在本文实验中设定召回率与准确率同等重要,因此,将ω设为1。
4.3 实验结果对比分析
1)微博热点分析。为了证明本文所提出方法的有效性,针对前面的数据集,本实验抽取了10个微博热点话题,使用基于词频、基于word2vec和HTDAMCW这3种检测方法进行对比分析如表1。表1中第1列是10个微博热点话题的标号;第2列为这些话题的名称;第3列给出了话题的生成时间;第4—6列分别为使用基于词频,word2vec,HTDAMCW 3种检测方法得到的这10个话题的排名。
通过表1可以看出,在微博热点话题检测中,基于词频的方法排在前面的为两会、世界杯、高考等话题,因为基于词频的方法主要计算关键词的频率;基于word2vec的检测方法引入词向量训练模型,挖掘文本之间的关联,因此,其检测准确度更高。但以上2种方法都并没有考虑到话题的时间维度和突发性。本文提出的HTDAMCW算法从多个维度对话题进行了度量,通过热度变化率高效地过滤掉低频话题,再使用回复加速度过滤掉进入衰退或消亡期的话题(两会、世界杯、高考等),最后结合微博的综合权值,有效检测出突发性热点话题。从实验结果可以看出,HTDAMCW算法在检测突发性热点话题时具有更高的准确性。
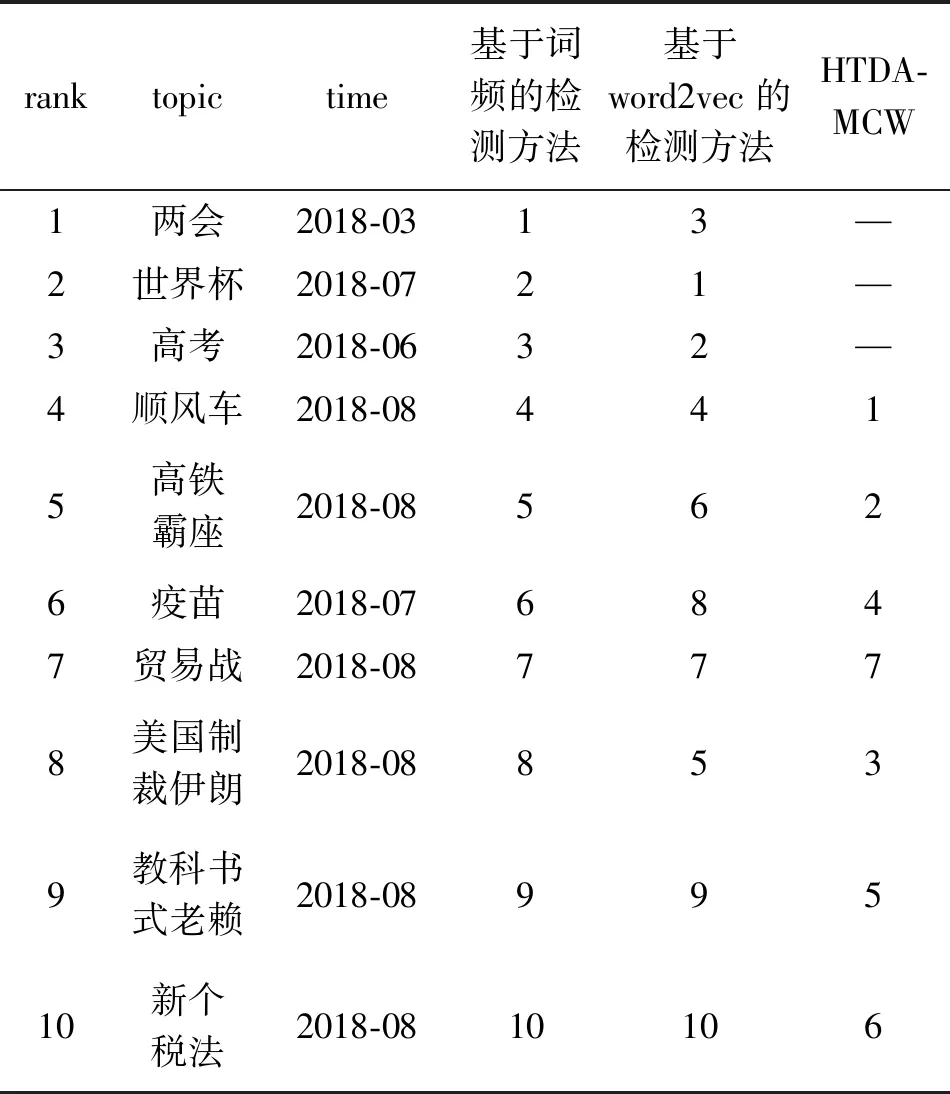
表1 抽取微博热点话题并排序
2)准确率、召回率和系统综合性能对比。对于爬取的20 678条微博信息,本文将HTDAMCW算法与其他传统的检测和提取算法(基于词频和基于word2vec的检测和提取算法)进行对比。实验结果表明,相较于其他2种算法,HTDAMCW算法准确性有明显提高,如图3。
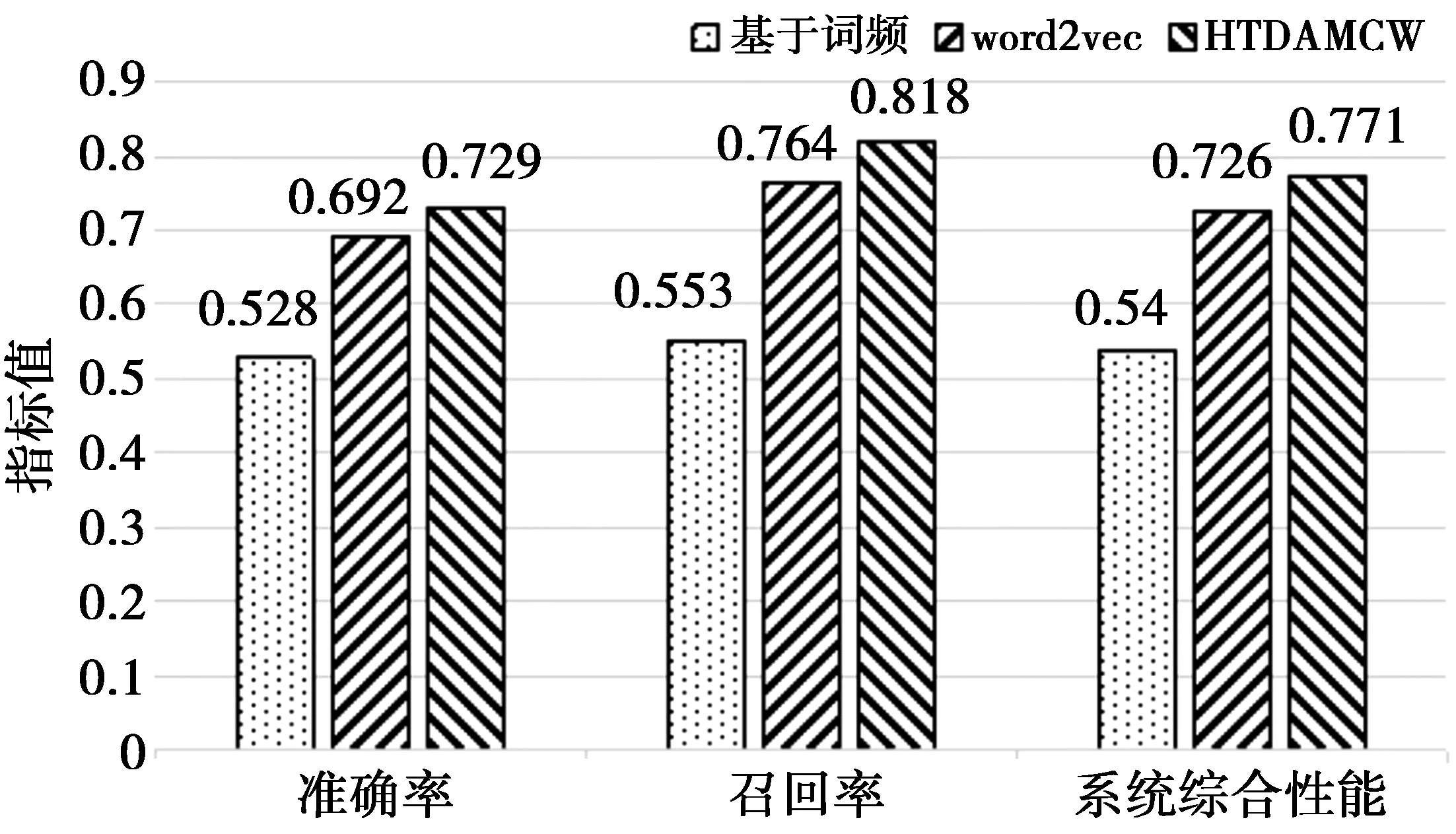
图3 HTDAMCW算法与其他算法对比实验结果Fig.3 Comparison of experimental results between HTDAMCW algorithm and other algorithms
3)突发性热点话题走势分析。为了进一步验证HTDAMCW算法对微博突发性热点话题检测的有效性,本文以“顺风车”、“霸座”2个事件为例,利用该算法,在不同时间点跟踪计算其综合权值。为了便于做图,本实验等比例放大了其综合权值,得到如图4和图5虚线所示的事件热度趋势图,实线表示9月1日—9月30日2大事件的微博官方指数。

图4 “顺风车”事件HTDAMCW与官方微指数对比试验Fig.4 Comparative test of “free ride” event based on HTDAMW and official micro-index
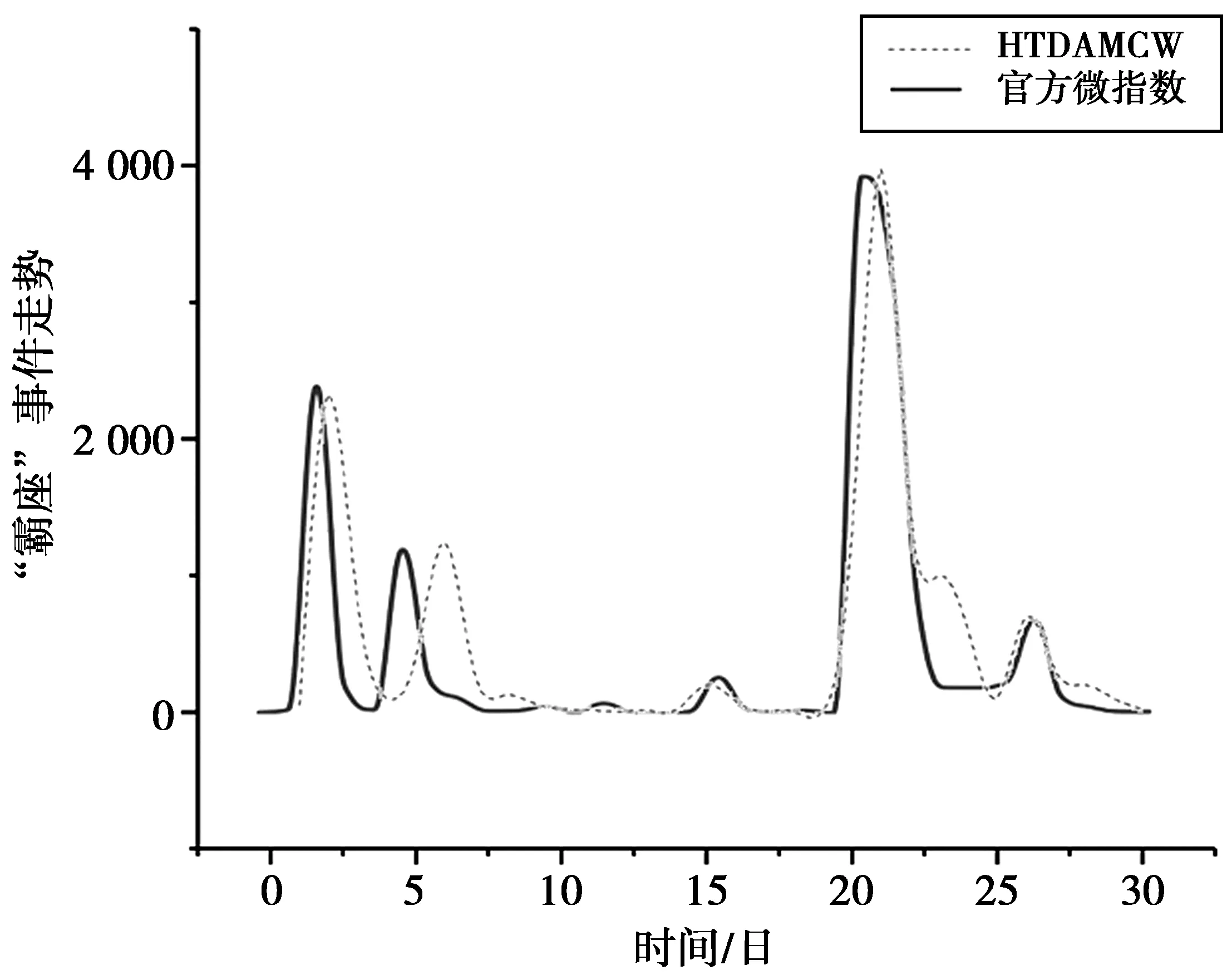
图5 “霸座”事件HTDAMCW与官方微指数对比试验Fig.5 Comparative test of “seat robber” event based on HTDAMW and official micro-index
图4虚线为从9月1日开始就持续跟踪“顺风车”事件的结果,从中可以看出事件很快就发展成为突发性热点事件。通过与官方微指数对比可知,“顺风车”事件走势基本拟合了微博官方走势。图5虚线为从9月1日开始就持续跟踪“霸座”事件的结果,通过与官方微指数对比可知,“霸座”事件走势也整体拟合了微博官方走势。
从以上分析可以看出,本文提出的方法可以准确检测出突发性热点话题,并跟踪其发展趋势,从而将较新的、有价值的热点话题推荐给用户。
5 结束语
传统热点检测算法仅从单一维度衡量话题的热度,导致热点话题检测精度低,在对突发性热点话题进行检测时尤为明显。鉴于此,本文提出一种多维度热点话题度量模型。该模型首先对话题进行筛选,得到一个热点话题初始集,再融入话题热度的影响力因子,计算话题的综合权值,将话题的综合权值按照一定的权重与多维度热点话题度量模型进行有效融合,最终得到一种基于微博多维度及综合权值的热点话题检测模型。实验结果表明,本文提出的算法模型在对突发性热点话题的检测中,其检测准确度相比于传统算法有了较大提高,整体性能表现稳定,从而改善了突发性热点话题检测的质量。然而,本模型也存在一些不足之处,对于大型文本数据集来说,该方法在提取热点话题时的时间复杂度较高,因此,优化本模型,使其更加高效运行将是未来的工作。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年2期)2022-04-26
医学前沿(2021年18期)2021-04-14
中国生殖健康(2020年4期)2021-01-18
作文成功之路·小学版(2020年9期)2020-10-28
中国生殖健康(2018年4期)2018-11-06
动漫界·幼教365(大班)(2018年6期)2018-05-14
中国医药指南(2017年3期)2017-11-13
商周刊(2017年7期)2017-08-22
网络空间安全(2016年3期)2016-06-15
中国有色金属(2014年23期)2014-03-13
