
基于WEKA平台的乳腺癌分类及早期预测
2019-09-10 07:22赖碟
信息技术时代·上旬刊 2019年2期
赖碟




摘要:由于电子的医疗数据爆发式地增长和现今的机器学习、数据挖掘技术的演进,深度学习方法在医疗行业的分量也越来越重。人们利用数据对患者的病情进行预测、检测不良药物、检测不良反应等等,通过挖掘的数据源、方法和案例研究,来进行知识发现,并将挖掘出的知识呈现给医学专家,从而进行更加快速准确的判断。医学数据挖掘是提高医疗信息管理水平,为疾病的诊断和治疗提供科学,准确的决策,促进医疗事业的发展。本文使用了一些数据集,基于WEKA数据挖掘平台,简单分析了乳腺癌数据的分类并比较了不同挖掘算法的分类准确性。目的是基于WEKA数据挖掘平台寻找最适合乳腺癌诊断和医学数据早期预测的算法,为后期医疗行业的大数据分析和挖掘提供新思路。
关键词:数据挖掘;WEKA平台;乳腺癌;预测;分类器比较
研究背景
随着电子信息技术的发展,以及“互联网+”的广泛应用,电子病历和医疗记录、医疗设备和仪器也实现了数字化,大多医院在自己的数据库系统中积累了大量的有关患者病例,诊断,检查和治疗的临床信息。通过大量文献调查,发现数据挖掘技术可以应用于预测与心脏,癌症和肾脏相关的一些主要身体疾病。数据挖掘技术是指利用一种或多种计算机学习技术,从数据中自动分析并提供信息的过程。目的是寻找和发现数据中潜在的有价值的信息、知识、规律、联系和模式。数据挖掘与计算机科学有关,通常使用机器学习、统计学、联机分析处理、专家系统和模式识别等多种方式来实现。医学数据挖掘是提高医学信息管理水平,为疾病的诊断和治疗提供科学准确的决策,促进医疗发展的需要。
近年乳腺癌的发病率在不断升高,中国更是乳腺癌发病率增长最快的国家之一,但总体死亡率有不断下降的趋势,这离不开乳腺癌的早期诊断、预防工作以及乳腺癌综合治疗的进步。在乳腺癌危险因素研究的基础上,很多国家和医学组织都在构建风险评估模型,旨在确定高危人群范围,以便采取更为积极的筛查或预防措施。乳腺癌的风险评估模型是建立在不同国家和学术组织的研究基础上的,所以适用的人群不同,侧重基因检测及流行病学资料也各有不同。
因此,掌握医学数据挖掘的能力越成为开展基础医学和临床医学等医学课题的先决条件。本文在WEKA数据挖掘平台的基础上,对乳腺癌数据进行挖掘分析,并比较不同挖掘算法的分类准确性。旨在基于WEKA数据挖掘平台寻找最适合医学数据乳腺癌诊断和早期预测的算法,为后期医疗行业的大数据分析及挖掘提供新思路。
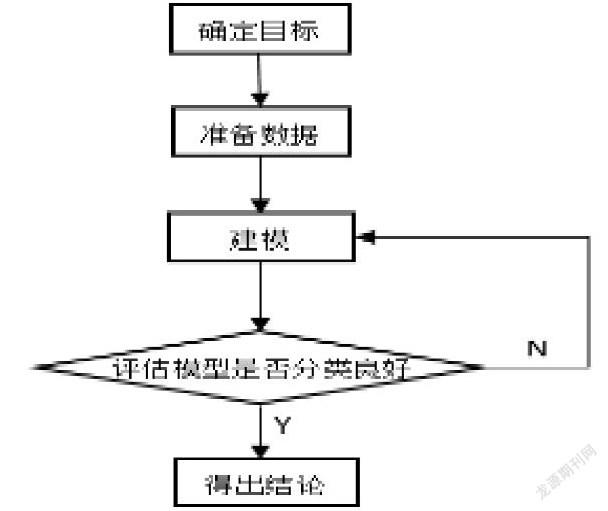
1 确定KDD目标
使用以下流程,通过构建几种不同乳腺癌分类模型,对病人的病情分别进行评估预测,判断是否患有乳腺癌,并分析模型的好坏。
2 数据准备
2.1获取数据
通过http://archive.ics.uci.edu/获取数据集
2.2数据信息
本实验是针对威斯康辛州(原始)的乳腺癌数据集进行分类,该数据集共有699个数据实例,其中类分布:良性458个,恶性241个。
该数据集的数据属性如下:
attribute domain
Sample code number(样本代码) id number
Clump Thickness(丛厚度) 1-10
Uniformity of Cell Size(均匀的细胞大小) 1-10
Uniformity of Cell Shape(均匀的细胞形状) 1-10
Single Epithelial Cell Size(单个上皮细胞大小) 1-10
Bare Nuclei(裸核) 1-10
Normal Nucleoli(正常核仁) 1-10
Mitoses(有丝分裂) 1-10
Class(类型) 良性2个,恶性4个
2.3数据预处理
数据集中有16條缺失数据,这里我们直接将16条数据删除,由于总共有699个实例,占比十分小,所以删除的实例对结果不会有太大的影响。
对于有指导学习,删除缺失后的数据总共683条数据,我们这里将前400个实例作为训练数据集,后283个实例作为测试数据集。
3 确定KDD模型及评估指标
3.1分类器
使用WEKA数据挖掘工具实现了各种算法,用于实验分析,选取的算法介绍如下。
J48:用于对数据进行分类的简单决策树算法。J48是以分类为目的的监督学习方法。它是基于分而治之的方法。它将整个数据分成一个子范围,是基于样本训练数据集中已经可用的值的当前属性值
基本思想是选择具有最大增益率的属性作为分支节点来分类实例数据。信息增益表示当x取属性x_i值时,其对降低x的熵的贡献大小。信息增益越大,越适宜对x进行分类。计算属性A的增益率公式如下:
根据信息熵的公式,可以很容易得出 。 为当前数据集所有实例所表达的信息量, 为根据属性A的k个可能取值分类I中实例之后所表达的信息量。计算 和 的公式如下所示:
其中,n为实例集合I被分为可能的类的个数,k为属性A具有k个输出结果。
最后, 是对A属性的增益值的标准化,目的是消除属性选择上的偏差,即在所有实例的属性A的取值只有一个时,该属性总被优先选取的情况。计算 的公式如下:
随机树:是指随机过程建立的树或者树状图,是一种随机决策树。
随机森林(RF):RF是一种通常适用于随机树的集成方法。在数据集的基础上形成许多分类树,根据分类树每个输入向量,最终分类一个新对象。介绍RF之前,我们需要了解一下Bagging思想。
Bagging是bootstrap aggregating。就是从总体样本当中随机取一部分样本进行训练,通过多次这样的结果,进行投票获取平均值作为结果输出,这就极大可能的避免了不好的样本数据,从而提高准确度。因为有些是不好的样本,相当于噪声,模型学入噪声后会使准确度不高。RandomForest(随机森林)是一种基于树模型的Bagging的优化版本,一棵树的生成肯定还是不如多棵树,因此就有了随机森林,解决决策树泛化能力弱的特点。同一批数据,用同样的算法只能产生一棵树,这时Bagging策略可以帮助我们产生不同的数据集,从样本集(假设样本集N个数据点)中重采样选出N个样本(有放回的采样,样本数据点个数仍然不变为N),在所有样本上,对这n个样本建立分类器,重复以上两步m次,获得m个分类器,最后根据这m个分类器的投票结果,决定数据属于哪一类。
总的来说就是随机选择样本数,随机选取特征,随机选择分类器,建立多颗这样的决策树,然后通过这几课决策树来投票,决定数据属于哪一类。
K-Means:随机选择一个K值,用来确定簇的总数,在数据集中任意选择K个实例,将他们作为初始的簇中心,计算在K个簇中心与其他剩余实例的简单欧式距离,用这个距离作为实例之间相似性的度量,将与某个簇相似度高实例划分到该簇中,成为其成员之一。使用每个簇中的实例来计算该簇新的簇中心。如果计算得到新的簇中心等于上次迭代的簇中心,终止算法过程。否则用新的簇中心作为簇中心并重复步骤。
神经网络: 本文使用weka中的BP神经网络模型。反向传播学习(Backpropagation Learning)是前馈神经网络的有指导学习方法,和所有的有指导学习过程一样,它包括训练和检验两个阶段。在训练阶段中,训练实例重复通过网络,对于每个训练实例,计算网络输出值,根据输出值修改各个权值。这个权值的修改方向是从输出层开始,反向移动到隐层。改变连接权值的目的是最小化训练集错误率。训练过程是个迭代过程,网络训练直到满足一个特定的终止条件为止,终止条件可以是网络收敛到最小的错误值,可以是一个训练时间标准,也可以是最大迭代次数。
贝叶斯分类器:贝叶斯分类器时一种简单,但功能强大的有指导分类技术。模型假定所有输入属性的重要性相等,且彼此是独立的。尽管这些假定很可能是假的,但贝叶斯分类器实际上仍然可以工作的很好。分类器是基于贝叶斯定理的,其定义如下:
其中:H为要检验的假设;E为与假设相关的数据样本
从分类的角度考察,假设H就是因变量,代表着预测类;数据样本E是输入实例属性值的集合:P(H|E)是给定数据样本E时,假设H为真的条件概率;P(H)为先验概率,表示在任何数据样本E出现之前假设的概率。条件概率和先验概率可以通过训练数据计算出来。
3.2性能指标
这里我们使用分类正确度和混淆矩阵确定模型的正确度:
分类准确度=正确预测的实例/測试总实例数
通过混淆矩阵进行正确度分析:
其中,i为矩阵行数,j为矩阵列数。
4 分类器结果的比较
综合以上分类器,使用weka数据挖掘平台进行分析,得出了乳腺癌数据集的分类模型正确度如下:
5 结论
为了实现基于WEKA数据挖掘平台的医学数据分类及乳腺癌的早期预测,使用六种分类器进行WEKA数据挖掘工具的实验。通过对分类器进行比较,并利用模型分类正确度来确定各模型分类精度。对比实验结果表明,较于其他分类器,Random Forest分类器对乳腺癌数据集具有较好的分类准确性。随机森林建立了多个决策树,并将它们合并在一起能获得更准确和稳定的预测。随机森林的一大优势在于它既可用于分类,也可用于回归问题,这两类问题恰好构成了当前的大多数机器学习系统所需要面对的。未来,通过在分类器精度性能调整方面的优化,包括应用装袋(Bagging)、提升(Lift)和参数优化等技术,以及特定疾病的测试数据的加入,可以开发更准确的预测模型。
猜你喜欢
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
恋爱婚姻家庭·养生版(2021年3期)2021-05-08
祝您健康(2018年5期)2018-05-16
女士(2017年11期)2017-12-12
速读·下旬(2016年8期)2017-05-09
电子技术与软件工程(2016年24期)2017-02-23
妇女生活(2017年2期)2017-02-15
哈尔滨理工大学学报(2016年2期)2016-09-12
金点子生意(2014年4期)2014-04-10
