
基于簇过滤的优势集模糊聚类集成
2019-09-10 01:17周冰李飞侯位昭苏攀
计算机与网络 2019年7期
周冰 李飞 侯位昭 苏攀
摘要:提出了一种基于簇过滤的优势集聚类集成改进方法,以成员簇表示节点,采用相似性关系来表示成员簇之间的连接,从而构成图。与传统的基于图的集成技术不同,使用优势集搜索的方法找出其中的超簇,并在超簇上进行聚合得到最终的聚类集成结果。在UCI数据集上对模糊C均值聚类算法进行测试,结果表明,提出的基于簇过滤的优势集聚类集成改进方法比原始方法具有更高的精度。
关键词:聚类集成;簇过滤;优势集;模糊聚类
中图分类号:TN393文献标志码:A文章编号:1008-1739(2019)07-61-4

0引言
聚类是实现从未标记或标记的数据集中提取隐藏结构的一种方法。通常,聚类的目的是将对象分配给各个簇,尽量使得同一簇中的对象彼此相似,并且与其他簇中对象不相似。文献[1-2]已经提出并应用了许多聚类算法解决实际应用中的各种问题。例如,聚类算法可以应用到系统的异常情况检测中。在众多聚类技术中,聚类集成技术在某些应用中可以超越单一的聚类方法[3]。类似于分类器集成[4]和特征选择集成[5],聚类集成将多个基础聚类成员的结果通过一致性函数处理,得到最终的聚类集成结果。在聚类集成的实现中通常有2个关键步骤:基础聚类成员的生成和一致性函数。已有工作中对一致性函数的研究较多,包括基于投票的方法、基于标签分配矩阵的方法、基于对象成对相似性的方法和基于图的方法[6]等。基于优势集合的聚类方法可以应用到聚类集成结果所构成的图上,从而得到基于优势集的超簇。因此,本文提出了基于簇过滤的优势集聚类集成改进方法,提出了一个定量检测指标并依此过滤掉表示能力较差的成员簇,避免其对优势集抽取过程的干扰。提出的方法在UCI数据集上进行测试。测试结果表明,在准确性方面,提出的基于簇过滤的优势集聚类集成改进方法比原始方法具有更高的精度。
1模糊聚类集成
模糊聚类已被成功应用到实际问题中[7-8]。不同于传统的聚类,模糊聚类允许一个对象依照隶属度属于不同的簇,克服在某些问题中布尔边界所带来的不自然甚至违反直觉的聚类结果。



综上所述,提出的基于簇过滤的优势集模糊聚类集成改进方法步骤如下:①生成模糊聚类集成成员;②使用模糊簇显著度对每个聚类成员中的模糊簇进行筛选;③使用筛选后的模糊簇计算加权邻接矩阵并抽取优势集得到超簇;④将超簇中的所有模糊簇通过聚合和规范化,得到最终的聚类集成结果。
3实验结果
为了评估提出方法的性能,使用UCI公开数据集对提出的方法和原方法[10]进行对比实验。数据集中对象的真实标签是已知的,但未在聚类过程中使用该标签,标签信息在测试聚类结果时作为真实类标使用来评估所得结果的精度。为了仿真出聚类成员中存在的聚类信息不明确现象,在实验中将模糊均值聚类的迭代次数设置为20。
模糊均值聚类算法用于生成聚类集成成员。成员的个数设置为每个数据集中的非标签属性的个数。每个成员中的簇的数量设置为从2~15的整数。通过采用簇过滤技术和原始方法的结果进行对比,将显著度计算时的参数设置为0.02,0.04,0.06,0.08,0.10。模糊C均值和模仿者动态都在每次运行中随机初始化,但同次集成结果对比在相同的聚类成员结果下进行。实验结果如图2、图3、图4和图5所示,图中每个点为10次实验的平均。
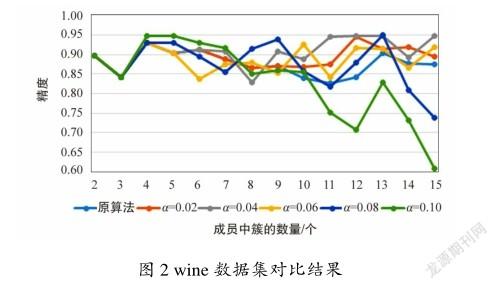
如图2所示,在wine数据集上大多数测试结果可以达到0.9的精度。随着聚类集成成员包含的簇的数量大于9时,没有簇过滤机制的原算法精度低于本文提出的方法。
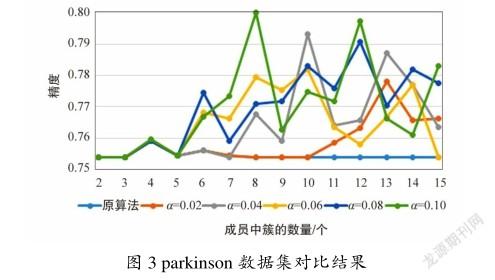
如图3所示,提出的方法的优势在parkinson数据集上更加明显。在所有测试参数中,改进后的方法所获得的精度都不低于原算法。当聚类集成成员包含的簇的数量大于10时,所有采用簇過滤机制的集成结果都要优于原算法。
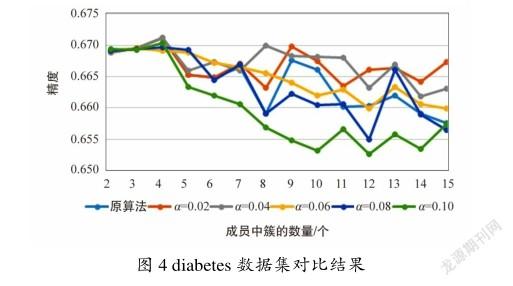
如图4所示,当显著度计算时的参数设置为0.02,0.04时所提出的方法在diabetes数据集上获得的结果要优于原算法。当设置为0.08,0.10时提出的方法结果要劣于原算法。主要原因是在仿真环境下可能由较多的簇由于迭代次数过低而导致样例之间的隶属度差异很小。因此,当的值设置过高时有过多的簇被过滤,使得集成可用的簇数量过少,从而导致聚类集成精度的下降。
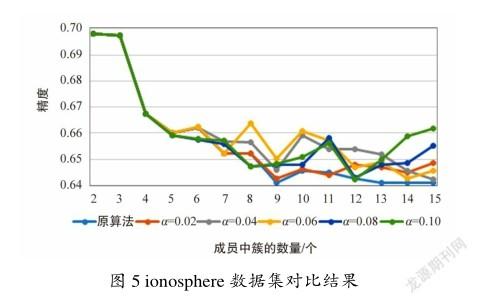
如图5所示,在ionosphere数据集的精度随着聚类集成成员包含的簇的数量增大而减小。出现该现象的原因是在仿真时设置的迭代次数过低而导致聚类成员结果没有充分收敛。尽管如此,当聚类集成成员包含的簇的数量大于8时,大多数采用簇过滤机制的集成结果都要优于原算法。
通过对比实验结果可以看出,同样条件下在测试的数据集中,采用了本文提出的基于簇过滤的改进方法可以获得比原始算法更高的精度。特别是随着聚类集成成员包含的簇的数量增大时,引入过滤机制将有助于提高集成结果的精度。此外,当的值设置过高时,有过多的簇被删除,因此会导致聚类集成精度下降。在parkinson数据集中提出的改进方法对精度的提高非常明显。
4结束语
本文使用优势集搜索的方法在聚类集成中找出成员簇中的超簇,并在超簇上进行聚合得到最终的聚类集成结果。由于在聚类集成中某些成员簇对原始数据的聚类结构表示不准确,因此提出了一个基于模糊隸属度的定量检测指标并依此过滤掉表示能力较差的成员簇,避免其对聚类结果的干扰。所提出的方法在UCI数据集上针对模糊C均值进行测试。实验结果表明,所提出的基于簇过滤的优势集聚类集成改进方法比原始方法具有更高的精度。
未来的工作可以考虑将基于簇过滤的优势集模糊聚类集成改进方法应用到实际应用中检验其效果。同时还可以考虑对参数的自动取值方法进行研究。
参考文献
[1] Su P,Shang C,Chen T,et al.Exploiting Data Reliability and Fuzzy Clustering for Journal Ranking [J]. IEEE Transactions on Fuzzy Systems, 2017, 25(5):1306-1319.
[2] Li Z, Shang C, Shen Q. Fuzzy-clustering Embedded Regressionfor PredictingStudent Academic Performance [C]// In Fuzzy Systems (FUZZ-IEEE),2016 IEEE International Conference on IEEE,2016: 344-351.
[3] Yu Z,Zhu X,Wong H S,et al. Distribution-based Cluster Structure Selection [J]. IEEE Transactions on Cybernetics, 2017,47(11):3554-3567.
[4] Diao R,Chao F, Peng T,et al. Feature Selection Inspired Classifier Ensemble Reduction [J]. IEEE Transactions on Cybernetics,2014, 44(8): 1259-1268.
[5] Shen Q, Diao R, Su P. Feature Selection Ensemble[C]// In Proceedings of the Alan Turing Centenary Conference, 2012.
[6] Iam-On N,Boongoen T,Garrett S,et al. A link-based Approach to the Cluster Ensemble Problem [J]. Pattern Analysis and Machine Intelligence, IEEE Transactions on,2011,33(12): 2396-2409.
[7]杨秀媛,董征,唐宝,等.基于模糊聚类分析的无功电压控制分区[J].中国电机工程学报,2006, 26(22):6-10.
[8]李培强,李欣然,陈辉华,等.基于模糊聚类的电力负荷特性的分类与综合[J].中国电机工程学报,2005, 25(24):73-78.
[9] Pavan M,Pelillo M.Dominant Sets and Pairwise Clustering [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(1): 167-172.
[10] Su P,Chen T,Xu W, et al.Dominant-set-based Consensus for Fuzzy C-Means Clustering Ensemble [C]// In 2018 International Conference on Machine Learning and Cybernetics (ICMLC), 2018: 85-90.
