
一种改进的MEP决策树剪枝算法
2019-09-10 07:22焦亚男马杰
河北工业大学学报 2019年6期
焦亚男 马杰



摘要 決策树剪枝是将已生成的决策树进行简化的过程,包括预剪枝和后剪枝。为了提高后剪枝算法MEP的剪枝精度,防止因MEP影响因子选取不当造成决策树修剪过度而丢失特征信息的问题,提出一种改进的MEP算法即IMEP方法。首先引入k-折交叉验证(k-Fold Cross-Validation)方法用于选取最优的影响因子m,然后将m带入到MEP算法,再对原始决策树进行剪枝,可以得到最精确的决策树,并保持决策树的影响特征。其次,通过k次交叉验证,可以避免产生过拟合问题,和单独测试集方法相比,经过k次交叉验证后,已经减弱了随机性,防止出现“欠学习”问题。经过验证IMEP方法不仅提高了MEP的精度,能更精准简化决策树,并且保持决策树的影响特征。相比于PEP算法,在数据集较小时有更好的适用性,表现更加稳定。
关 键 词 决策树;剪枝;MEP;PEP ; IMEP
中图分类号 TP391.1 文献标志码 A
An improved pruning algorithm for MEP decision tree
JIAO Ya′nan,MA Jie
(School of Electronics and Information Engineering, Hebei University of Technology, Tianjin 300401, China)
Abstract Decision tree pruning is to simplify the generated decision tree both in the pre-pruning and post-pruning. In order to improve the pruning accuracy of post-pruning algorithm MEP and prevent the problems of excessive pruning of decision tree and loss of feature information caused by improper selection of influence factors of MEP, an improved MEP algorithm called IMEP algorithm is proposed. First, the k-Fold Cross-Validation method is introduced to select the optimal impact factor m, and the factor m is introduced into MEP algorithm. By pruning the original decision tree, the most precise decision tree can be obtained and the impact characteristics of the decision tree can be maintained. Secondly, the problem of over-fitting can be avoided by k-times cross-validation. Compared with the single test set, after k-times cross-validation, the randomness has been weakened and the problem of under-learning has been prevented. After verification, IMEP algorithm not only improves the accuracy of MEP, but also simplifies the decision tree more precisely, and maintains the influence characteristics of the decision tree. Compared with PEP algorithm, it has better applicability and more stable performance when the data set is small.
Key words decision tree; pruning; MEP; PEP; IMEP
0 引言
随着人工智能时代的到来和信息时代的深入,机器学习从起源到深入人心,如今已经被应用到了诸多领域。同时,决策树作为机器学习中一种基本的分类与回归的方法受到普遍关注和广泛研究[1-3]。决策树算法通过学习给定的训练集,学得分类或者回归的规则,继而用于新数据集的预测。决策树模型由节点和有向边构成,节点分为内部节点和叶节点。内部节点对应于一个属性或特征,叶节点对应于一个类。决策树的创建分3步:特征选择、决策树生成、决策树修剪。建立决策树是以自上而下递归的方式来实现的[4]。初始状态时,所有的数据都在根节点,若样本都属于同一类,则该节点为叶节点,并用相应的类别标号标记;如若不是同一类,对当前数据集进行划分,通过某种特征选取规则,对特征属性的每一个取值创建分支;最后,根据相同的规则,对样本进行划分,依次递归形成决策树,直到出现一种以下情况时决策树停止生长[5-6]:1)当前节点上的数据类别都相同;2)没有剩余的特征属性可以划分。
上述过程完成了决策树的生成,但是在实际构造决策树时,存在诸多的不确定性因素,例如孤立噪声、样本关联性较差等。由于决策树的生成并未考虑这些因素,会造成得到的树结构变得很大很复杂。但是决策树结构复杂,并不意味着能得到更准确的分类结果[7-8]。因此,需要对决策树进行剪枝,目前的剪枝方法分为两大类:预剪枝和后剪枝。预剪枝是指决策树在成长完成前,通过某种规则停止其生长;后剪枝是对一个完整的决策树,按照某种规则剪掉部分分支。因为后剪枝会考虑整个决策树的信息,往往优于预剪枝,所以在实际中应用最多[9]。常用的后剪枝算法有:错误率降低剪枝(Reduced-Error Pruning?, REP)、悲观剪枝(Pessimistic Error Pruning,PEP)、最小错误剪枝(Minimum Error Pruning,MEP)和代价复杂度剪枝(Cost-Complexity Pruning,CCP)[10-12]。REP算法是最简单的后剪枝算法之一,采用自上而下的方式进行剪枝,裁剪过程中,非叶子节点只进行一次计算,计算复杂度为线性,但是预测精度取决于训练集与测试集的相关性程度,若相关性较差,会造成决策树的预测能力差。PEP算法是后剪枝算法中精度最高的算法之一,不需要区分测试集与训练集,避免REP相关性的问题,同样采用自上而下的方式剪枝,缺点是会造成决策树过早停止生长。MEP算法主要依托于选取合适的影响因子[m]值,当[m]值过大时会使决策树过于简单,决策树裁剪过度而导致丢失特征信息。因此必须选取合适的[m]值,当选取[m]值得当时,其精度仅次于PEP算法。CCP算法兼顾了预测精度和复杂度,故而时间相较于其他算法更长,但复杂度相较于MEP算法有所降低。
通过对剪枝算法的归纳和对比,PEP算法的精度最高,其次是MEP算法。但是,PEP算法是从上到下进行剪枝,容易造成部分特征属性丢失。尤其是对于样本数较小的数据集,PEP算法就会变得很不稳定。对于MEP算法,[m]的选择会影响剪枝精度。因此,防止因MEP影响因子选取不当造成决策树修剪过度而丢失特征信息的问题,提出了一种基于MEP算法的改进方法,暂称为Improved Minimum Error Pruning(IMEP)方法。
1 传统决策树剪枝算法
MEP[13]是一种后剪枝算法,采用自下而上的方式进行。此方法的提出最初是为了改进ID3算法的缺陷[14-16],改善数据中存在的噪声问题。该剪枝算法利用了贝叶斯方法,考虑了分类问题中先验概率和后验概率,所以可以在数据集上产生最小的分类错误概率。亦可称之为[m]-概率估计。可以认为通过调整[m]值来应对不同的问题。一般而言,决策树的裁剪程度与[m]值成正比。
具体的剪枝方法为:如果样本共有[k]类,那么在决策树节点[t]的训练样本中,属于类别[i]的概率如式(1)所示:
[Pi(t)=ni(t)+Pai(t)×mn(t)+m], (1)
式中:[Pai]为[i]类样本的先验概率,即类别[i]的样本在整个数据集的占比;[m]为[Pai]对后验概率[Pi]的影响因子,所以[m]并不是定值。那么节点[t]的预测错误率[Er(t)]定义为如式(2)所示:
[Er(t)=min{1-Pi(t)}=minn(t)-ni(t)+(1+Pai(t))×mn(t)+m]。 (2)
如果所有类别的先验概率都相同时,即[Pai=1/k],([i]=1,2,…,[k]),即[m=k],此时的[Er(t)]可以表示为
[Er(t)=n(t)-ni(t)+(k-1)n(t)+k], (3)
式中:[n(t)]為节点[t]的样本总数;[ni(t)]为节点[t]中主类的样本数量。
最后,分别计算非叶节点的误差[Er(t)],然后计算每个分支的误差[Er(Tt)],再加权相加,权重为分支的样本数量占比,如果[Er(t)]大于[Er(Tt)],则保留该子树,否则剪裁掉该子树。
MEP算法的主要优点是可变的影响因子[m],[m]值决定了树的剪裁程度,选择适当的[m]值,就可以得到最优决策树。例如,当[m]取值很大时,决策树会被剪裁成单个叶节点,从而具有最小分类错误率。但是,也因此造成了一个缺点,[m]值越大,训练集的影响越小,决策树结构越简单;然而在这种情况下,并不能直接生成较小的树。对于每一个[m]值,都必须从原始决策树开始剪裁,所以这种非单调性会使计算度变得复杂。
剪枝算法还有诸如REP、PEP、CPP等,使用情况归纳如表1所示。不同的剪枝算法有不同的优缺点,有不同的适用范围。通过对比上述因素可以发现,剪枝算法最好不需要额外剪枝集,防止过剪枝问题;最好剪枝方式是自下而上,以免出现“视野效应”[17];误差估计对于不同的数据集,有着不同的最优情况,一般连续校正的精度最好;计算复杂度和节点数目最好是线性关系。PEP算法精度最高,其次为MEP算法,但对于数据集较小的样本,PEP算法会不适用,反而不如MEP算法,为提升MEP算法的精度,应该选取合适的[m]值。
2 改进的决策树剪枝算法IMEP
分析归纳现有的剪枝算法后,提出一种基于MEP算法的改进决策树剪枝方法IMEP,以提高MEP剪枝算法的精度。
剪枝过程和CCP算法类似,分为2个步骤。1)剪枝规则和MEP基本相同,不同的是影响因子[m]不再是定值[k],而是一系列的变值,需要选择出最优的[m]值。所以剪枝规则不再是式(3),而是原始规则式(2)。2)对于选择最优的[m]值,在这里采用[k]-折交叉验证(K-Fold Cross-Validation),和CCP算法中的交叉验证类似,不同的是并不是采用单独剪枝集验证一次,而是验证[k]次。
2.1 IMEP剪枝方法
输入:生成算法产生的整个树T;
输出:修剪后子树[Tm];
1)[k]-折交叉验证得到最优[m]值,求节点误差[E(t)],采用最优[m]值,而非[k];
2)计算每个非叶节点误差[Er(t)];
3)自下而上进行回缩;
4) 计算该节点每个分枝的误差[Er(Tt)];
5)如果[Er(t)]<[Er(Tt)],进行裁剪使父节点变为新的叶节点,否则保留该子树;
6)返回2),直到不能继续为止,得到剪枝树。
2.2 [k]-折交叉验证方法
1)将训练集D分为[k]个子集,[D1,D2,…,Dk]作为验证集,对应训练集为[D-Di (i=1,2,…,k)];
2)利用[k]个训练集生成[k]个决策树[T1,T2,…,Tk];
3)选定一个[m]值,对[k]个决策树进行与MEP剪枝规则相同的剪枝,[m]值为选定的值,并非[k];
4)用[k]个验证集分别验证剪枝后的决策树,取所有验证集的正确率的平均数,作为此K-CV分类器的性能评价指标,记录当前指标;
5)改变[m]值,返回3),直到得到最优的性能指标,此时的[m]值为最优[m]值。
根据上述IMEP方法的剪枝过程,可以看出此算法的优点。首先,提高了算法精度,不断选择最优[m]值,得到最高精度的决策树;其次,通过[k]次交叉验证,可以避免产生过拟合问题。和单獨测试集方法相比,经过[k]次交叉验证后,已经减弱了随机性,防止出现“欠学习”问题。但是,IMEP方法的缺点也很明显,就是计算复杂度。[k]次交叉验证再加上重复剪枝选择最优[m]值,会大大增加计算的复杂度,从而剪枝时间也会变长。综上所述,IMEP方法为了提高算法精度,导致计算复杂度增加,牺牲掉了剪枝时间。由于PEP算法对数据量较小时,剪枝效果并不稳定,选取精度次之的MEP算法,因此IMEP处理的数据量较小,由牺牲剪枝时间换取来的精度度是值得的。
3 实验结果与分析
本文实验采用2个数据集分别是西瓜数据集2.0和“Nursery”数据集,来自加州大学欧文分校用于机器学习的“UCI数据库”。对2个数据集分别用C4.5、CART[18-19]算法构建决策树,然后用REP、PEP、MEP、IMEP、CCP剪枝算法进行剪枝,以此来分析IMEP剪枝的性能。
西瓜数据集2.0数据量较小,共有17条样本,6个属性,通过色泽、根蒂、敲声、纹理、脐部、和触感这6条属性来判别西瓜是否为好瓜。如表2所示。
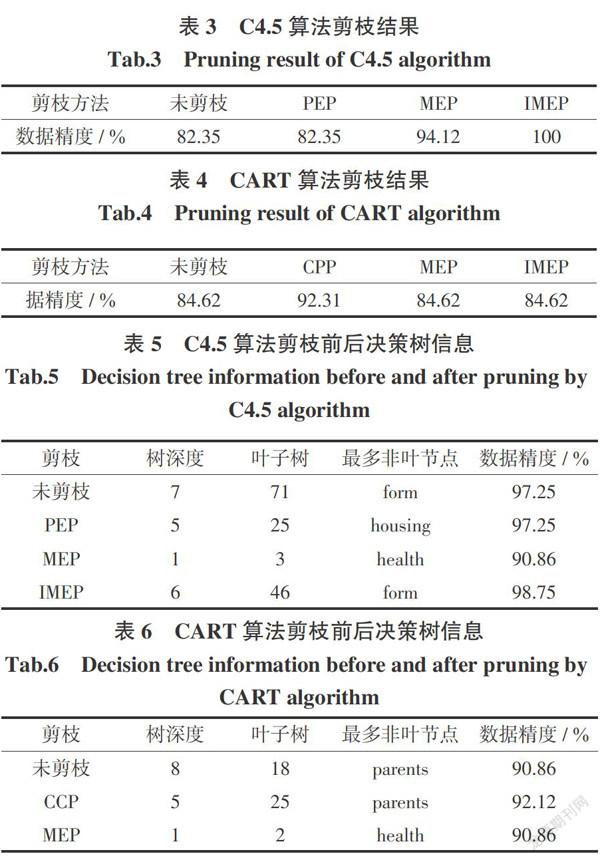
用C4.5算法构建的决策树,PEP剪枝算法使决策树丢失较多特征信息,MEP剪枝算法会改善PEP剪枝所出现的问题,IMEP剪枝方法保留了决策树过多的的特征信息;通过表3可以发现,PEP算法没有影响数据集精度,MEP和IMEP算法都提高了精度,IMEP甚至在这个例子中提高到100%。
用CART算法构建的决策树,MEP剪枝算法裁掉决策树大部分枝节,CCP剪枝算法只剪裁掉决策树一部分枝节,IMEP剪枝方法结果和MEP算法相同;表4可以发现,只有CCP算法会造成数据集精度上升,MEP和IMEP方法的数据集精度均保持不变,而且均简化了决策树结构。
“Nursery”数据集有9个属性,因为数据集的样本数过多(超过1 000),所以构造的决策树非常庞大,没必要再以图的形式展示,所以从3个角度分析:树的复杂度(即深度和叶子数)、最多非叶节点(即影响特征属性)和数据集精度[20]。
由表5可以看出,对于用C4.5算法构造的决策树,对结果影响最大的特征属性是“form”。剪枝后,只有IMEP方法的影响特征没有变化;MEP算法不仅过多剪裁决策树,而且精度下降,影响特征也和其它算法不同,所以MEP算法没有正确剪裁决策树;PEP算法保持剪枝前的精度,同时大大简化了决策树,可影响特征变成“housing”;IMEP方法不仅提高了精度,而且简化了决策树,影响特征属性仍然是“form”。
由表6可以看出,对于用CART算法构造的决策树,对结果影响最大的特征属性是“parents”。剪枝后,只有CCP算法的精度变高了;MEP算法不仅过多剪裁决策树,而且影响特征也发生变化,所以MEP算法误差较大;用CCP算法对决策树剪枝后,树的结构没有变化,影响特征保持不变,但数据精度有所提高;可是IMEP算法,已经无法裁剪此决策树,由此可见CCP算法对于CART决策树的“专业性”,也体现了IMEP算法对于CART决策树的不足。
综上所述,对于不同的决策树算法,影响数据集的特征属性不同。根据剪枝前后的变化和数据集精度,IMEP在用C4.5的剪枝过程中表现出了优秀的特性,不仅提高了数据精度,而且保持特征属性不变,在性能提升面十分显著,而相较于CCP剪枝CART决策树表现不尽如人意,但每种剪枝算法都有自己的适用领域,IMEP相比于MEP已经提升了很多。
4 结束语
对于决策树生成算法,通过不同的数据集和不同决策树之间对比,可以分别概括3种决策树算法特点[21]:ID3算法适合处理特征属性较少,特征取值也较少的数据集;CART算法适合处理特征属性较多,但特征取值较少的数据集;而C4.5算法解决了ID3算法在特征取值较多时的问题,也能保持CART算法在特征属性较多时的优点,所以在复杂度简单或复杂的情况下都有较好的表现。因此,C4.5算法在决策树算法中,得到最广泛的应用。
对于决策树剪枝方法,通过对同一数据集采用不同剪枝算法剪枝,可以概括出以下剪枝方法特点[22]:预剪枝算法虽然算法简单,但是会丢失很多重要信息;REP算法精度较预剪枝会提高,是最简单的后剪枝算法,但需要额外的剪枝集,不适用于数据量少的数据集;PEP算法的精度很高,而且不需要额外剪枝集,适用范围很广,但对于数据量少的数据集可能不太稳定;MEP算法精度仅次于PEP算法,而且也不需要额外剪枝集,但随着数据量增多性能会下降,不适合数据量较多的数据集;CCP算法精度不如其它后剪枝算法,只适用于CART算法生成的决策树,而且需要额外剪枝集,不过对于复杂的CART算法决策树,其他剪枝算法效果比较差,CCP算法就会体现出优点;对于改进的IMEP方法,体现出了极高的精度,但是计算时间比较长,而且和PEP算法类似,树的结构也比较复杂,尤其是数据量多的数据集。因此,PEP剪枝算法的精度比较高,适用范围广,因此得到最广泛的应用。不过对于数据量较少的数据集,PEP算法会表现不稳定,那么IMEP算法可以填补这一缺点。
参考文献:
[1] HU Q H,CHE X J,ZHANG L,et al. Rank entropy-based decision trees for monotonic classification[J]. IEEE Transactions on Knowledge and Data Engineering,2012,24(11):2052-2064.
[2] RIVERA-LOPEZ R,CANUL-REICH J. Construction of near-optimal axis-parallel decision trees using a differential-evolution-based approach[J]. IEEE Access,2018,6(1):5548-5563.
[3] CHO C,CHUNG W,KUO S. Using tree-based approaches to analyze dependability and security on I&C systems in safety-critical systems[J]. IEEE Systems Journal,2018,12(2):1118-1128.
[4] 路翀,徐輝,杨永春. 基于决策树分类算法的研究与应用[J]. 电子设计工程,2016,24(18):1-3.
[5] 郑伟,马楠. 一种改进的决策树后剪枝算法[J]. 计算机与数字工程,2015,43(6):960-966,971.
[6] 李孝伟,陈福才,李邵梅. 基于分类规则的C4. 5决策树改进算法[J]. 计算机工程与设计,2013,34(12):4321-4325,4330.
[7] HASHIM H,TALAB A A,SATTY A,et al. Data mining methodologies to study student's academic performance using the C4. 5 algorithm[J]. International Journal on Computational Science & Applications,2015,5(2):59-68.
[8] MATTHEW N,ANYANWU,SAJJAN G,et al. Comparative analysis of serial decision tree classification algorithms[J]. International Journal of Computer Science and Security,2009,3(3):230-240.
[9] LIM H,CHOE Y,SHIM M,et al. A quad-trie conditionally merged with a decision tree for packet classification[J]. IEEE Communications Letters,2014,18(4):676-679.
[10] BARROS R C,BASGALUPP M P,FREITAS A A,et al. Evolutionary design of decision-tree algorithms tailored to microarray gene expression data sets[J]. IEEE Transactions on Evolutionary Computation,2014,18(6):873-892.
[11] WANG T,BI T S,WANG H F,et al. Decision tree based online stability assessment scheme for power systems with renewable generations[J]. CSEE Journal of Power and Energy Systems,2015,1(2):53-61.
[12] CHENG Y,WANG P. Packet classification using dynamically generated decision trees[J]. IEEE Transactions on Computers,2015,64(2):582-586.
[13] MA B,WANG D,CHENG S G,et al. Modeling and analysis for vertical handoff based on the decision tree in a heterogeneous vehicle network[J]. IEEE Access,2017,5:8812-8824.
[14] 王小巍,蔣玉明. 决策树ID3算法的分析与改进[J]. 计算机工程与设计,2011,32(9):3069-3072,3076.
[15] WANG X H,WANG L L,LI N F. An application of decision tree based on ID3 [J]. International Conference on Solid State Devices and Materials Sciencet,Physics Procedia,2012,25(4):1017-1021.
[16] YANG S,GUO J Z,JIN J W. An improved Id3 algorithm for medical data classification[J]. Computers and Electrical Engineering,2018,65:474-487.
[17] TONG D,QU Y R,PRASANNA V K. Accelerating decision tree based traffic classification on FPGA and multicore platforms[J]. IEEE Transactions on Parallel and Distributed Systems,2017,28(11):3046-3059.
[18] 赵建民,黄珊,王梅,等. 改进的C4. 5算法的研究与应用[J]. 计算机与数字工程,2019,47(2):261-265.
[19] 张亮,宁芊. CART决策树的两种改进及应用[J]. 计算机工程与设计,2015,36(5):1209-1213.
[20] MüHLBACHER T,LINHARDT L,M?LLER T,et al. TreePOD:sensitivity-aware selection of Pareto-optimal decision trees[J]. IEEE Transactions on Visualization and Computer Graphics,2018,24(1):174-183.
[21] JAWORSKI M,DUDA P,RUTKOWSKI L. New splitting criteria for decision trees in stationary data streams[J]. IEEE Transactions on Neural Networks and Learning Systems,2018,29(6):2516-2529.
[22] LIN G S,SHEN C H,VAN DEN HENGEL A. Supervised hashing using graph cuts and boosted decision trees[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(11):2317-2331.
[責任编辑 田 丰]
猜你喜欢
华文教学与研究(2022年1期)2022-04-27
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
科学与信息化(2019年28期)2019-10-21
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
诗选刊(2019年3期)2019-03-18
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
科学与财富(2016年32期)2017-03-04
农村农业农民·B版(2014年8期)2014-09-16
滇池(2014年5期)2014-05-29
