
基于深度学习的甲状腺病史结构化研究与实现
2019-09-12 10:41骆轶姝申舒心陈德华
智能计算机与应用 2019年4期
骆轶姝 申舒心 陈德华

摘 要: 甲状腺病史作为一类重要的非结构化文档,对医疗诊断至关重要。针对具体的甲状腺病史数据,提出一种基于深度学习的甲状腺病史结构化处理方法。首先,构建专业词库和病史本体,使用专业词库指导分词,基于本体结构完成结构化输出;其次,通过使用实体识别技术,完成对分词结果标签的预测;最后,使用标签抽取和词库匹配两种方法对病史数据进行信息抽取,并将结构化结果以RDF进行存储。实验结果表明该方法的准确率和泛化性较传统方法有明显提升。
关键词: 甲状腺;病史;深度学习;实体识别
文章编号:2095-2163(2019)04-0021-07 中图分类号:TP311 文献标志码:A
0 引 言
随着医学信息化水平的不断提高,逐渐积累了越来越丰富的非结构化临床诊疗数据。如何有效利用这些数据已然成为目前智慧医疗领域备受关注的重点研究课题。
甲状腺疾病是内分泌科常见疾病之一。甲状腺病史作為非结构化临床诊疗数据资源,为医生诊断患者疾病提供了重要依据。但甲状腺病史结构化主要面临以下难点:适用于通用数据集的传统分词方法难以对医学领域的专业知识进行准确分词;对于传统的信息抽取方法,当应用在非标准缩写、术语以及拼写错误和不完整句子上时,难以兼顾模型的泛化性和准确性;传统的结构化输出难以为结构化数据的存储、分析、检索起到便捷支持作用。
针对上述问题,本文结合甲状腺病史数据的具体特点,提出一种基于深度学习的甲状腺病史结构化处理方法,以期为中文临床诊疗数据结构化提供参考。
1 方法
甲状腺病史完整的结构化工作包含3个模块,分别是:预处理模块、实体识别模块以及信息抽取模块,如图1所示。其中,预处理模块和此过程中构建的基础专业词库是整个框架的基础,预处理的水平直接决定了实体识别模型的效果;实体识别模块在预处理模块输出的数据集上训练得到一个模型,该模型作为标注工具用以指导结构化;信息抽取模块依赖于实体识别模型的标注结果和本体构建的结果,最终模块会将结构化文本通过RDF(Resource Description Framework)以一种“树型”结构进行存储。
1.1 专业词库构建
构建专业词库主要目的在于数据预处理过程中指导原始数据分词和结构化过程中基于词库匹配进行实体抽取。使用专业词库指导文本分词则旨在避免通用分词工具对专业数据进行误分、错分;基于词库进行信息抽取的核心思想是指结合领域知识和抽取目标信息建立的字符串标识匹配与定位。词库的最初构建来源于多个专业词表,包括:ICD-10疾病标准[1]、2017年国家医保药品目录、ICD-9-CM[2](手术操作编码)、某三甲医院收费明细与收费标准和中华医学会内分泌分会发表的2008《甲状腺疾病诊治指南》[3]。标准词表及其对应的实体类型和举例详见表1。
1.2 病史本体构建
由于甲状腺病史文本表达形式多样且内容繁杂,相较于传统的句子模板,通过使用构建甲状腺病史本体的方法,对甲状腺病史文本数据进行一定程度的抽象概括,更适用于当前结构化任务。相关研究表明,基于描述逻辑和规则的本体可以进一步表述数据的语义,本体基于逻辑的知识表示形式可以有效提高知识的语义表述能力,相应的逻辑推理算法可以改进知识的发现能力和解释能力[4-5]。考虑到对结构化结果的存储、分析、检索的便捷支持需要,本文使用决策七步法构建病史本体,使用自左向右的方法构建甲状腺病史本体中的类和类之间的关系,并采用软件Protégé完成本体模型的构建,继而使用RDF[6]语言描述构建的本体模型。
(1)确定本体的专业领域和范畴。本文以医学领域为特定的研究领域,构建甲状腺病史本体:通过一套明确的体系规范甲状腺病史数据中的词汇,使数据中的术语得到统一,能够被其它领域认可;基于本体结构,使用词典匹配和实体识别标签抽取实现甲状腺病史的结构化。
(2)考虑复用现有本体的可能性。本文的原始数据来自于上海市某三甲医院的真实临床采集得到,本体的结构依据病史的内容和记录格式,且由于医生的个人习惯原因,病史的记录规则相对比较灵活,且构建本体的目的是为实现病史的结构化,目前也尚未见到可以复用或是具有参考价值的公开本体。
(3)列出本体中的重要术语。通过与标准词表进行匹配构建基础专业词库,通过专家纠错和使用实体识别算法扩充专业词库。专业词库的专业术语样本见表2。
(4)定义类和类的层次。通过实体识别算法构建词典和实体标签,然而大都属于专业术语,且这些实体(见表2)的分布是散乱的,关系不明确,仅仅是信息抽取,很难达到预期结构化的效果。因此本文提出基于原始数据的记录结构,依据标签,将这些实体进行归类。类的顺序按照病史的数据结构自顶向下地逐级排序,依次是时间、地点、诱因、症状、检查、治疗、效果、入院情况和疾病;类的层次结构通常采用自左向右的方法加以确定,即先确定父类,再确定子类。将这种关系定义为part-of关系。
(5)定义类的属性。在第(4)步的过程中,通过提取部分术语定义了类和类之间的关系,然而简单的类名无法体现具体的知识,本体的具体知识通过定义类特有的属性来体现。本文提出将现有的属性分为2种,即:数据型属性和对象型属性。两者间的区别就在于实例的不同。其中,数据型属性是指实例中具有文字、字符串、数字和日期的属性,包括:时间、地点、诱因、症状、效果、入院情况和疾病的属性;对象型属性是指实例中包含另一个子类的属性,即该属性不是具体的属性值,而是另一个父类下的一个子类,包括:检查和治疗两种属性,检查的属性是某种检查项目、接下去才是检查内容,治疗下是某种治疗方式、紧接着才是治疗内容。本文将数据型属性定义为instance-of关系,对象型属性定义为attribute-of关系。
在实体抽取的所有实体中,基本上形成了3种关系,见表3。
(6)本体决策。本体在使用前需要经过3个步骤进行验证,来证明本文构建的本体是否符合实际需求。首先经过逻辑推理证明本体构建逻辑无误;其次,本文基于本体结构,使用实体识别技术进行信息抽取,构建本体;最后,经由专家验证该本体的正确性。
(7)创建实例。本文使用本体的主要目的是为结构化数据的存储、分析、检索提供便捷支持,本体结构如图2所示。
1.3 数据预处理
(1)数据标准化。甲状腺疾病现病史文本数据是由医生手动录入,而不同的医生有不同的输入习惯,这主要体现在标点以及特殊符号使用上的不统一与不规范,导致分词效果并不理想。同时存在比较严重的错别字。故而在预处理过程中需要对标点符号进行规范化,并对错别字做出修改。标准化样例见表4。
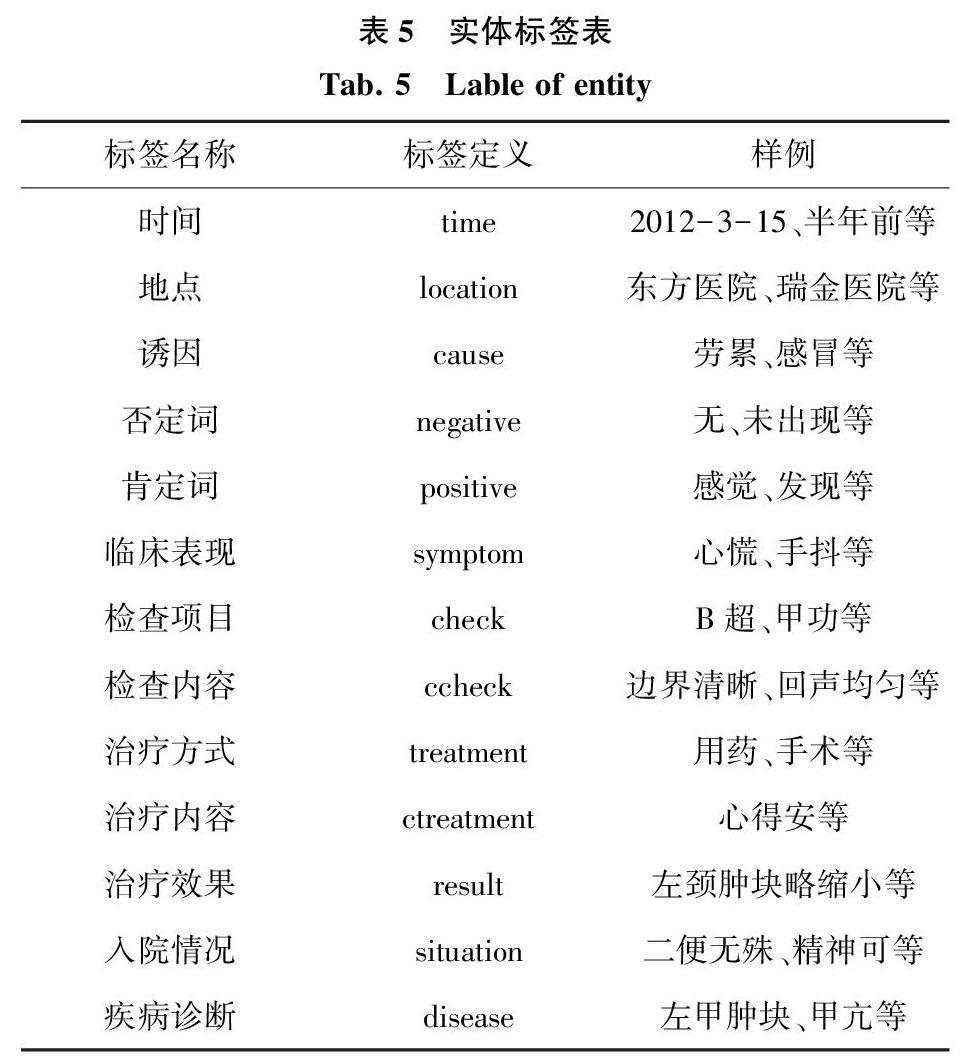
(2)文本分词。为确保实体识别模型的顺利训练,本文依赖基于标准词表构建的专业词库对病史文本进行精准分词。针对现有的中文分词工具对专业性较高的医学文本存在错误分词的问题,建立專业词库,提高分词准确度。专业词库包括症状、疾病、检查和治疗四个子库,初始化来源于几个专业数据集。另外,分词模块中需要对训练集加上标注,专家团队对13类实体进行标注,产生21种标签用于模型的监督学习。本文基于病史数据内容对甲状腺病史分词后的数据设计标签见表5。
本文为模型设计了13种标注,对应不同的语义内容,这些标注包含了一定的实体信息。表5对部分语义内容进行了详细分类。为避免在结构化过程中的稀疏存储,本体定义没有做到细致的属性划分,这些标签最终会有助于定义结构化内容的属性。
1.4 实体识别
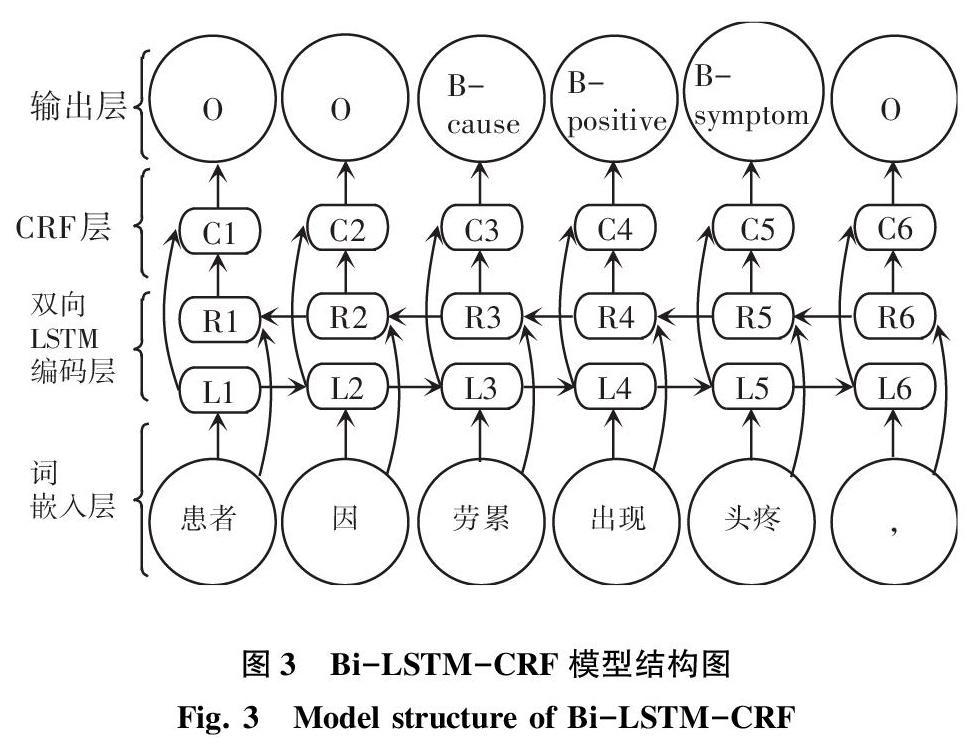
在专业词库构建过程中,通过使用实体识别技术对专业词库进行扩充和更新;在结构化过程中,通过使用实体识别技术对给定文本进行标签预测。本文使用Bi-LSTM[7-10]作为实体识别的主体,该模型在LSTM的基础上加入逆向传播过程,使得网络可以同时利用上下文中的语义特征。另外,由于Bi-LSTM的各输出之间没有相互影响,仅仅获得独立的最大概率标签,造成Bi-LSTM的输出中可能存在非法标签问题,即B-cause后连接I-time,本文为该模型添加CRF[11]的后处理层来适应多变的输出。CRF中的转移特征会分析输出标签之间的顺序,以获得最优的标签序列。Bi-LSTM-CRF网络结构如图3所示。
图3中,第一层为词嵌入层(Word Embedding layer),主要是将基于自定义词典分词后的序列文本数据转化为词向量序列,并将向量序列输入模型进行训练。第二层为Bi-LSTM编码层,通过LTSM的正向推导和反向传播对序列文本数据中的各个词进行独立分类,获取标注信息。第三层为CRF层,通过使用CRF中的条件转移矩阵从已获得标注信息的分词中选取合法标注,获得最优标注序列。第四层为输出层,在给定目标语句的情况下,通过深度学习模型可以对目标语句自动进行单词的语义标注。
1.5 信息抽取
在甲状腺病史结构化过程中,本文主要选取2种方法用于信息抽取研究,即在不同部分的数据使用不同的方法:对于描述相对多样化或是过度依赖上下文语义的实体使用实体识别标签抽取,见表6。
除此以外,对于症状、检查、治疗、疾病这四类描述相对较为规范、固定的实体使用词库匹配的方法进行信息抽取。
最后结合病史本体结构,将通过上述两种方法获得的信息实现结构化输出。
1.6 结构化数据存储
RDF数据模型本质上是一个图结构模型,由主语、谓词和对象组成,底层使用XML/RDF语言实现。由于医学专业知识具有数据库量大和增长快的特点,本文构建的现病史本体也需要以RDF的形式存储。常用的单节点RDF数据库不能满足存储现病史本体实例的需求,使用传统的关系型数据库存储又面临信息冗余高和查询性能低的问题,所以研究和构建分布式的具备图存储功能的本体存储系统是一个可行的方法。资源描述框架模型如图4所示。
2 实验
2.1 实验数据
病史是病历中的一部分,通常包括现病史、既往史、家族史、个人史和婚育史。其中,现病史记述患者发病后的全过程,即发生、发展、演变和诊治的经过,具有数据量最大、内容最多和记录结构最复杂的特点。本文选取上海某三甲医院从2005~2015年十余年间、共9 386条甲状腺病史中的现病史数据内容作为实验数据。
现病史从内容上大致分为4个部分,也就是:疾病发生、病情发展、治疗经过和入院情况。其中,疾病发生主要包括:起病时间、临床症状和起病诱因;病情发展主要包括:病程中主要症状的变化、新出现症状以及伴随症状;治疗经过是指:本次就诊前已经接受过的诊断检查及其结果,治疗所用药物的名称、剂量、给药途径、疗程及疗效;入院情况是指:医生从患者病后的精神、体力状态、饮食情况、睡眠与大小便等方面,对病人得出全身情况的评价。甲状腺病史样例数据可表述如下。
2015-3患者因劳累出现消瘦、乏力、无多汗、心慌、无手抖等症状,至徐汇区中心医院查甲状腺功能提示甲亢,给予赛治最初20 mg,bid,口服2周后改用10 mg,bid,3周后复查甲状腺功能后改用5 mg,bid,口服半月后复查甲状腺功能FT3、FT4较前升高,1月前(2015-6-20)患者自诉双眼突出逐渐明显,并出现右眼复视,视力下降,2015-7-3随至复旦大学附属耳鼻喉医院查双眼CT提示双侧甲状腺相关性眼病,查甲状腺功能提示FT3 6.41 pmol/L,FT4 16.68 pmol/L,TSH 0.006 5 uIU/ml。今为求进一步诊治,门诊以“甲状腺相关性眼病”收住院。发病以来,患者神志清楚,精神一般,双眼突出,畏光流泪,无明显充血水肿,右眼有复视,无呕血、黑便 ,无腹痛,胃纳可,二便可,夜眠佳,近期未见明显体重下降。
2.2 实验与结果
(1)参数设置。本文通过平均实验结果来确定最優的参数组合,实验中采用的可调参数设置见表7。
(2)评估标准。对于实体关系抽取结果的评价,本文针对全部实体分别计算准确率(precision)、召回率(recall)和F1值。对应数学公式可顺次表示如下:
其中,TP表示本类别中正确识别的样本数;FP表示本类中标注错误的样本数;FN表示原本属于本类的标注,却错误地标注为别的种类的标签的样本数。F1值可以加权调和平均模型的准确率和召回率,能综合地表征一个模型的优劣。
(3)实验结果。实验在现病史共定义13类特征实体,21种标签,通过混淆矩阵计算出各类实体的准确率P、召回率R以及F1值。实验结果见表8。
甲状腺病史中现病史将识别结果绘制混淆矩阵,如图5所示。
图5中,颜色越亮代表该标签预测的准确率越高,混淆矩阵的横轴表示预测结果,纵轴表示真实标记,可以看到在O标记上,本文模型出现的偏差比较明显,但依然保持在较高的水准,这是因为O标记总体数据样本占据的比例最大、也相对更为分散。另外,文本的模型在时间点、肯定词、否定词等关键实体的识别上也达到了较高的准确率,这对本文结构化过程中的按时间节点分段,按肯定词、否定词分句有较大影响。
随机选取一样例做实体识别,识别结果展示如图6所示。
通过实体识别后的数据就可以进行结构化处理,结构化结果中的一个样例如图7所示。
图7中,通过{}及[]不同的括号来区分不同方法得到的结构化信息,{}为实体识别的内容,[]为词库匹配的内容。
(4)结构化存储。将最终的结构化数据以资源描述框架的形式进行存储。结构化存储借助python第三方扩展(rdflib),以XML形式进行RDF序列化存储,最终对每个时间段内的内容都生成一个XML文件。由于文本限制,只截取一条完整病史数据的结构化结果的起始部分内容,序列化的一个样本如图8所示。
3 结束语
本文结合现有自然语言处理技术和甲状腺病史的数据特征,提出了一种甲状腺病史结构化处理方法。首先,构建专业词库和病史本体,分别用于指导分词和实现结构化输出;其次,对原始数据进行预处理,并将预处理后的数据进行实体识别,实现对分词结果的标签预测;最后,基于病史本体结构,使用标签抽取和词库匹配两种方法,实现对甲状腺病史的结构化,并通过RDF将结构化结果进行存储。
参考文献
[1]SUNDARARAJAN V, HENDERSON T, PERRY C, et al. New ICD-10 version of the Charlson comorbidity index predicted in-hospital mortality[J]. Journal of Clinical Epidemiology, 2004, 57(12):1288-1294.
[2]DEYO R A. Adapting a clinical comorbidity index for use with ICD-9-CM administrative data: A response[J]. Journal of Clinical Epidemiology, 1993, 46(10):1081-1082.
[3]中华医学会内分泌学分会《中国甲状腺疾病诊治指南》编写组. 中国甲状腺疾病诊治指南[J]. 中华内科杂志, 2007, 47(10):867-868.
[4]MAEDCHE A. Ontology learning for the semantic Web[M]// Ontology learning for the semantic Web. Boston, MA:Springer, 2002:117-147.
[5]杜文华. 本体构建方法比较研究[J]. 情报杂志, 2005(10):24-25.
[6]GIBBINS N . Resource description framework[J]. Serials Review, 2009, 27(1):58-61.
[7]QIN Ying, ZENG Yingfei. Research of clinical named entity recognition based on Bi-LSTM-CRF[J]. Journal of Shanghai Jiaotong University, 2018, 23(3):392-397.
[8]ANH L T , ARKHIPOV M Y , BURTSEV M S . Application of a hybrid Bi-LSTM-CRF model to the task of Russian Named Entity Recognition[M]// FILCHENKOV A, PIVOVAROVA L, IKA J. Artificial intelligence and natural language. AINL 2017. Communications in Computer and Information Science. Cham:Springer, 2017,789:91-103.
[9]HUANG Zhiheng , XU Wei , YU Kai . Bidirectional LSTM-CRF models for sequence tagging[J]. arXiv preprint arXiv:1508.01991, 2015.
[10]杨锦锋,关毅,何彬,等. 中文电子病历命名实体和实体关系语料库构建[J]. 软件学报, 2016,27(11):2725-2746.
[11]LAFFERTY J, MCCALLUM A, PEREIRA F. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[C]//Proc. 18th International Conf. on Machine Learning.San Francisco, CA:Morgan Kaufmann, 2001: 282-289.
猜你喜欢
新医学(2022年4期)2022-04-23
中国当代医药(2018年17期)2018-10-23
妇女之友(2018年3期)2018-09-01
中国实用医药(2016年28期)2016-12-07
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
中国实用医药(2016年24期)2016-10-17
杂文选刊(2007年5期)2007-05-14
