
基于差分隐私保护的兴趣点推荐算法设计
2019-09-13 03:38张青云李万杰李晓会
计算机应用与软件 2019年9期
张青云 张 兴 李万杰 李 帅 李晓会
(辽宁工业大学电子与信息工程学院 辽宁 锦州 121001)
0 引 言
目前,基于位置的社交网络(Location-Based Social Networks,LBSN)应用非常广泛,典型的LBSN有美团、街旁、大众点评网等。这些社交网站为用户提供兴趣点(Point of Interests,POI)的签到、评论以及分享功能,这些功能积累的大量数据可作为兴趣点推荐的基础数据。兴趣点推荐服务是基于用户偏好和地理位置的一种社交网络服务类型,主要是向用户推荐满足自身偏好并且从未去过的位置。在互联网的快速发展中,兴趣点推荐服务可以让用户更加方便地在网络上与朋友分享信息、推荐信息,但与此同时也存在弊端。用户需要暴露隐私信息来接受推荐服务,会带来隐私泄露的风险,例如:观察用户每天的出行路线,可以大致推测出用户的家庭住址以及公司地址;将用户的历史访问兴趣点进行分类统计,能够大致得出用户的个人喜好以及经济情况。所以用户可能会因为隐私问题不愿意接受这样的推荐服务,因此亟需设计出一种算法来解决这个问题。传统的兴趣点推荐算法首先收集用户的行为记录,然后使用协同过滤推荐算法发现用户的偏好并为用户寻找偏好相似的其他用户,最后结合偏好相似用户的历史行为记录、好友行为记录和用户地理位置等因素,将新的兴趣点推荐给有需求的用户。
如今,兴趣点推荐系统引起了大量学者的关注,他们对其进行了深入地研究并提出了很多改进算法。Park等[1]根据用户对各类餐厅的喜好程度,运用贝叶斯分析方法构建数学模型,将用户可能感兴趣的餐厅反馈给用户。Nunes等[2]提出了一种基于位置的推荐方法,主要通过位置感知技术和构建高斯模型进行推荐。Zhang等[3-4]提出了兴趣点推荐系统需要考虑的几点因素:地理位置、好友信息、用户偏好以及时空关系,详细地列举了影响兴趣点推荐的几个方面。曹玖新等[5]将社交网络图和签到轨迹图结合起来,计算每条路径的关联度,为用户推荐兴趣点。Jeh等[6]结合Page Rank算法,提出了两种改进的位置推荐算法:基于好友关系的标签涂色算法和基于位置-好友关系的标签涂色算法。Yang等[7]结合时间和空间因素提出了一种改进的兴趣点推荐算法。
上述文献提出的算法虽然能从不同角度满足兴趣点推荐系统的要求,但是并没有考虑到用户的隐私泄漏问题。为了在保护用户隐私信息的同时不影响推荐效果,本文对传统兴趣点推荐算法进行改进,在其基础上添加差分隐私保护机制,以此来防止攻击者的恶意攻击。
1 基本工作原理
1.1 传统兴趣点推荐算法工作原理
传统的兴趣点推荐算法主要使用协同过滤推荐算法来实现推荐功能。该算法可分为两大类,分别是基于用户的协同过滤推荐算法和基于项目的协同过滤推荐算法。下面简单地介绍这两类推荐算法的原理:
基于用户的协同过滤推荐算法:首先根据收集到的用户信息来计算用户之间的相似度,找到与当前目标用户相似度高的所有用户集合,然后再收集这个集合中的用户对其他兴趣点的评分,通过对不同兴趣点的评分等级来推测出目标用户对该兴趣点的喜好程度,从而实现推荐功能。
基于兴趣点的协同过滤推荐算法:首先根据目标用户对兴趣点的喜好程度找到与之相似的兴趣点集合,然后根据用户的偏好和兴趣点集合中的项目进行相似度排序,将相似度高的兴趣点推荐给目标用户。
1.2 差分隐私相关概念
自2006年差分隐私发表以来,在机器学习和数据挖掘领域产生了巨大的影响。Dwork[8]将差分隐私定义为一种类似数据加密的方法。在这种定义下,对于数据集的计算结果而言,单个记录是否在数据集中对结果造成的影响可以忽略不计。因此,攻击者不能计算出某条记录是否在该数据集中。本文使用的定义、定理与性质[8]如下所示:
定义1存在一个含有n条记录的数据集D,记为D=(x1,x2,…,xn),xi是一条记录,取值均在Rd范围内,向量xi的d个元素分别对应每个记录的d个属性。定义隐私保护算法A的取值范围为Range(A),若算法满足以下不等式,则算法A满足ε-差分隐私条件:
P(A(D)∈S)≤eεP(A(D′)∈S)
(1)
式中:S⊆Range(A),数据库D和D′至多相差一条记录,数据库中的每条记录都对应一个个体。差分隐私有两个重要的性质:
性质1若原始数据v是算法A的输出结果,算法A满足ε-差分隐私,那么关于v的任意函数g(v)的输出结果均满足ε-差分隐私。
性质2对原始数据v使用两个隐私保护算法A1和A2,其中,A1满足ε1-差分隐私,A2满足ε2-差分隐私,那么v的隐私保护参数至多为ε1+ε2。
定理1令D和D′为两个至多相差一条记录的数据库,F表示向数据库请求的查询函数,那么查询算法F的敏感度ΔF表示为:
(2)
通俗而言,可以把算法敏感度ΔF理解成随机增加或者删除一条记录对整个数据集查询结果的最坏影响。
定理2如果变量x的概率密度分布函数Pr[x|μ,λ]满足:
(3)
则称x服从拉普拉斯分布。其中参数μ和λ分别表示变量x的期望值和尺度参数。参数λ由算法敏感度ΔF和隐私保护参数ε共同决定,表示为λ=ΔF/ε。
对于数据集D而言,如果查询数据为数值型,则使用拉普拉斯机制对查询结果进行加噪处理;反之,如果查询数据为非数值型,则使用指数机制来处理查询结果。
文献[9]提出了指数机制的概念。指数机制常被用于分类算法中多个分类值的选择问题。打分函数mark(D,r)(r∈D)的设计是指数机制的核心部分,其中r表示随机在值域D中选取的输出结果。
定理3如果F:D→Rd是一个k维的查询函数,ΔF是该查询函数的敏感度,那么加入拉普拉斯噪声的查询函数表示为F(D)+Lapk(ΔF/ε),满足ε-差分隐私。其中Lapk(ΔF/ε)表示加入的拉普拉斯噪声,由此得出加入的噪声大小与查询函数的敏感度成正比,与隐私参数ε的大小成反比。隐私参数ε越小,需要加入的噪声就越大,隐私保护程度就越高,但同时会降低数据的可用性,因此并不是隐私参数ε越小越理想。
2 地理位置隐私保护算法设计
2.1 设计思路
在推荐服务中,兴趣点的推荐服务是一个重要的研究方向。在设计推荐算法时,不仅要有准确的推荐结果,还要同时考虑到用户的隐私泄露问题。文中提出的基于差分隐私保护的兴趣点推荐算法就是在传统的兴趣点推荐算法中加入地理位置隐私保护算法,以此达到预期目的。地理位置隐私保护算法首先根据数据集中各项记录的相互关系建立位置搜索树,然后遍历位置搜索树并运用指数机制挑选出经常访问的k项纪录,最后对这k项记录添加拉普拉斯噪声并发布加噪后的位置搜索树。地理位置隐私保护算法设计框图如图1所示。

图1 地理位置隐私保护算法设计框图
现有的位置隐私保护方法大多都是通过匿名化、位置信息随机化和位置信息模糊化等[10]方法达到隐私保护的效果。当用户向服务器位置服务组件发送一个当前位置信息来请求服务时,尽管发送的实时地理位置是经过处理的,但是对其签到所在的兴趣点信息却没有进行保护。攻击者以及用于数据分析和数据挖掘的信息收集器仍然可以通过获取该兴趣点的相关信息获得用户的实时地理位置,所以对于当前位置隐私保护的程度是远远不够的。因此,本文在原始兴趣点推荐的基础上加入了一种严谨的基于差分隐私保护机制的地理位置隐私保护算法。
在数据集D的频繁模式挖掘中,应该在挖掘top-k频繁模式之前采用指数机制挑选出数据集D中所有访问频率大于min-count的k个频繁模式,然后采用拉普拉斯噪音机制扰动挖掘结果,向挖掘结果中添加适当噪声,以此保护top-k模式的访问频率不被泄露。本文就top-k频繁模式挖掘问题,引入了位置搜索树(LQ-Tree)结构,文中定义关于位置数据库D的LQ-Tree为LQTD。
基于差分隐私保护机制的地理位置隐私保护算法(D-LPP)首先通过建立完整的位置搜索树LQTD来表示数据集中的位置数据,然后在LQTD上选取所有访问频率大于min-count的k个频繁模式记录,对选取的数据进行加噪处理,最后返回并发布加噪后的位置搜索树NLQTD。如算法1所示。
算法1D-LPP算法
《国家中长期教育改革和发展规划纲要(2010—2020年)》明确提出要创新人事管理方式,引导教师潜心教学科研,改善教师工作和生活条件,关心教师身心健康。因此教育行政管理部门和学校应充分发挥广大教师在参与学校校务监督、民主管理中的作用,满足广大教师合法表达利益、对学校事务知情监督的诉求,努力构建和谐的校园。
输入:位置数据集D、k、min-count、差分隐私参数ε
输出:加噪后的位置搜索树NLQTD
1) 将数据集D中的所有元素构建成一个完整的位置搜索树LQTD。
2) 遍历LQTD,得到所以满足访问频率大于min-count的频繁模式记录,将该集合记为A。
3) 运用指数机制挑选出k个满足条件的频繁模式记录,将这些记录表示为bi,由bi构成的集合称为集合B。
4) 对集合B中的k个频繁模式记录bi的访问频率添加拉普拉斯噪声,将该集合记为E。
5) 将集合E与LQTD结合,输出添加噪声后的位置搜索树NLQTD。
2.2 建立位置搜索树
通过用户L一个月内的历史行为记录,筛选出用户经常访问的k个兴趣点,构建用户的位置数据库D,并根据数据库D构建一个位置搜索树。图2表示的是用户L一个月内经常访问的5个兴趣点。
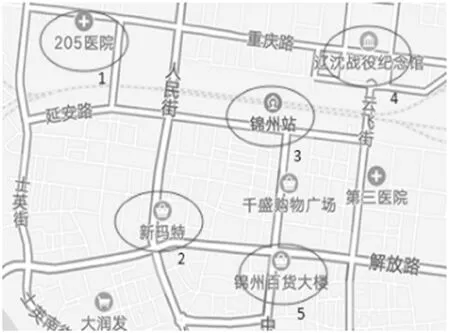
图2 位置数据
对地图上的每个位置进行编号,根据图2的位置数据构建位置对应关系表,如表1所示。

表1 位置对应关系

表2 位置数据库
根据表2的位置数据库,建立如图3所示的LQTD,其中包含了位置数据库D中的所有频繁模式。

图3 位置搜索树
2.3 基于指数机制挑选频繁模式
得到算法1中的集合A后,使用指数机制挑选出经常访问的k项记录。指数机制不仅能够筛选出包含用户隐私信息大于min-count的位置,而且在每次筛选的时候能够合理地控制隐私泄露情况。
通过指数机制在A中选取k个满足下式的频繁模式ai,构成集合B:
(4)
式中:Pr(ai)表示每个兴趣点被选中的概率;ai·weight表示ai频繁模式的权重。如算法2所示。
算法2Select-Patterns(A,ε1)算法
输入:集合A,隐私参数ε1。
输出:挑选出的k个频繁模式构成的集合B。
1)n←|A|
/*n表示集合A中的元素个数 */
2) fori=1 toNdo
3)ai·mark←mark(A,ai)
/* 模式的打分函数 */
/* 打分函数的全局敏感度 */
/* 计算每个模式ai的权重 */
6) end for
7)L←[a1·weight…an·weight]
/* 将权重存入链表L中 */
8) fori=1 tokdo
/* 频繁模式ai被选中的概率 */
10) Randomly selectai∈L;
/* 从链表L中随机选择模式ai*/
11) InsetaiintoB;
/* 把模式ai插入到集合B中 */
12) end
其中,打分函数设置为:
mark(A,ai)=Pr(ai)
(5)
式中:Pr(ai)表示ai模式的访问频率。
2.4 添加拉普拉斯噪声
算法2只是选择出k个频繁模式,但并没有对这k个模式的真实访问频率起到保护的效果,如果直接输出会泄露用户的兴趣点访问频率。于是在输出频繁模式及访问频率之前,应该对这k个频繁模式进行加噪保护,以此来保护用户的位置隐私。如算法3所示。
算法3Add-Noise(B,ε2)算法
输入:查询函数F、集合B、隐私预算ε2。
输出:添加拉普拉斯噪声后的k个频繁模式集合。
1)k←|B|
/*k表示集合B中的元素个数 */
/* 对模式bi添加拉普拉斯噪声*/
3) returnB
在步骤2中添加的噪声服从拉普拉斯分布,分布函数为:
(6)
式中:x表示兴趣点的访问频率。
2 实验与结果分析
用于算法实验测试的数据来源于Foursquare网站,该网站包括从2010年3月到2011年12月的所有数据,其中包含18 293个用户的基本信息、43 186个兴趣点信息以及用户签到所产生的1 903 909次签到数据。
3.1 数据效用性分析
为验证加入差分隐私保护的兴趣点推荐算法所产生的数据的完整性和安全性,分别取 50、100和200个兴趣点数据进行实验。在实验中,设定一个访问频率l,当兴趣点的访问频率高于l时,将该兴趣点称为敏感位置;反之,则称为非敏感位置。根据实验结果,统计出不同模式下的敏感位置数量,如表3所示。

表3 不同模式下的敏感位置数量
图4表示不同模式下,两种推荐算法所产生的敏感位置的数量对比折线图。
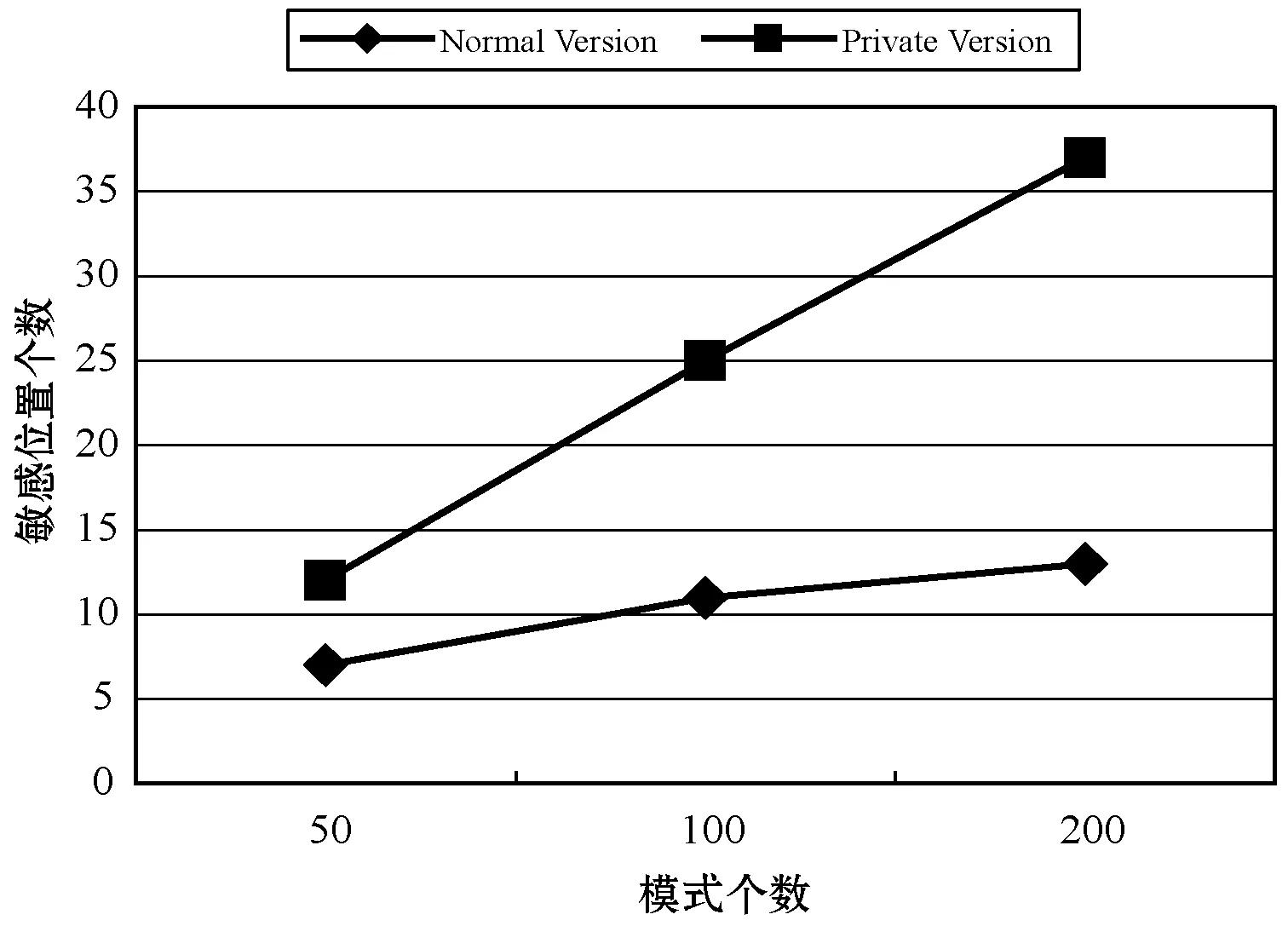
图4 两种推荐算法的Recall对比图
由图4可以看出,经过差分隐私保护的兴趣点推荐算法产生的敏感位置个数明显增加,当取50个兴趣点进行试验时,敏感位置由7个增加到了12个;取100个兴趣点时,敏感位置由11个增加到了25个;取200个兴趣点时,敏感位置由13个增加到了37个。
由实验结果得出,使用差分隐私保护机制对这些实验数据进行加噪处理时,加入的拉普拉斯噪声会使实验数据的访问频率增大,因此更多实验数据的访问频率会达到敏感位置的访问频率阈值,从而使得非敏感位置变成了敏感位置,增加了攻击者的攻击难度,更好地保护了用户的真实位置信息。由此可见,加入差分隐私保护机制的兴趣点推荐算法不仅能够保证数据的安全性,而且还维持了数据的完整性。
3.2 结果分析
实验通过召回率R和准确率P[12]这两个指标来评估该算法推荐效果的好坏。召回率是指推荐算法返回的被标记并加噪的兴趣点数量比上所有被标记的兴趣点数量,准确率是指推荐算法返回的被标记并加噪的兴趣点数量比上所有被加噪的兴趣点数量。令集合A表示所有被标记过的兴趣点集合,集合B表示算法返回的加噪后的兴趣点集合,根据上述定义,得出召回率与准确率的公式为:
(7)
(8)
实验计算中k表示推荐算法待返回的兴趣点个数,k的取值是不断变化的。在k的所有取值情况下(k=5,10,20,50),将召回率和准确率作为评价算法好坏的指标,比较加入差分隐私保护算法后的兴趣点推荐算法与传统的兴趣点推荐算法的性能差异。
图5表示在k取值变化的情况下,传统的兴趣点推荐算法和加入差分隐私保护的兴趣点推荐算法的召回率对比图。

图5 两种推荐算法的Recall对比图
图6表示在k取值变化的情况下,传统的兴趣点推荐算法和加入差分隐私保护的兴趣点推荐算法的准确率对比图。
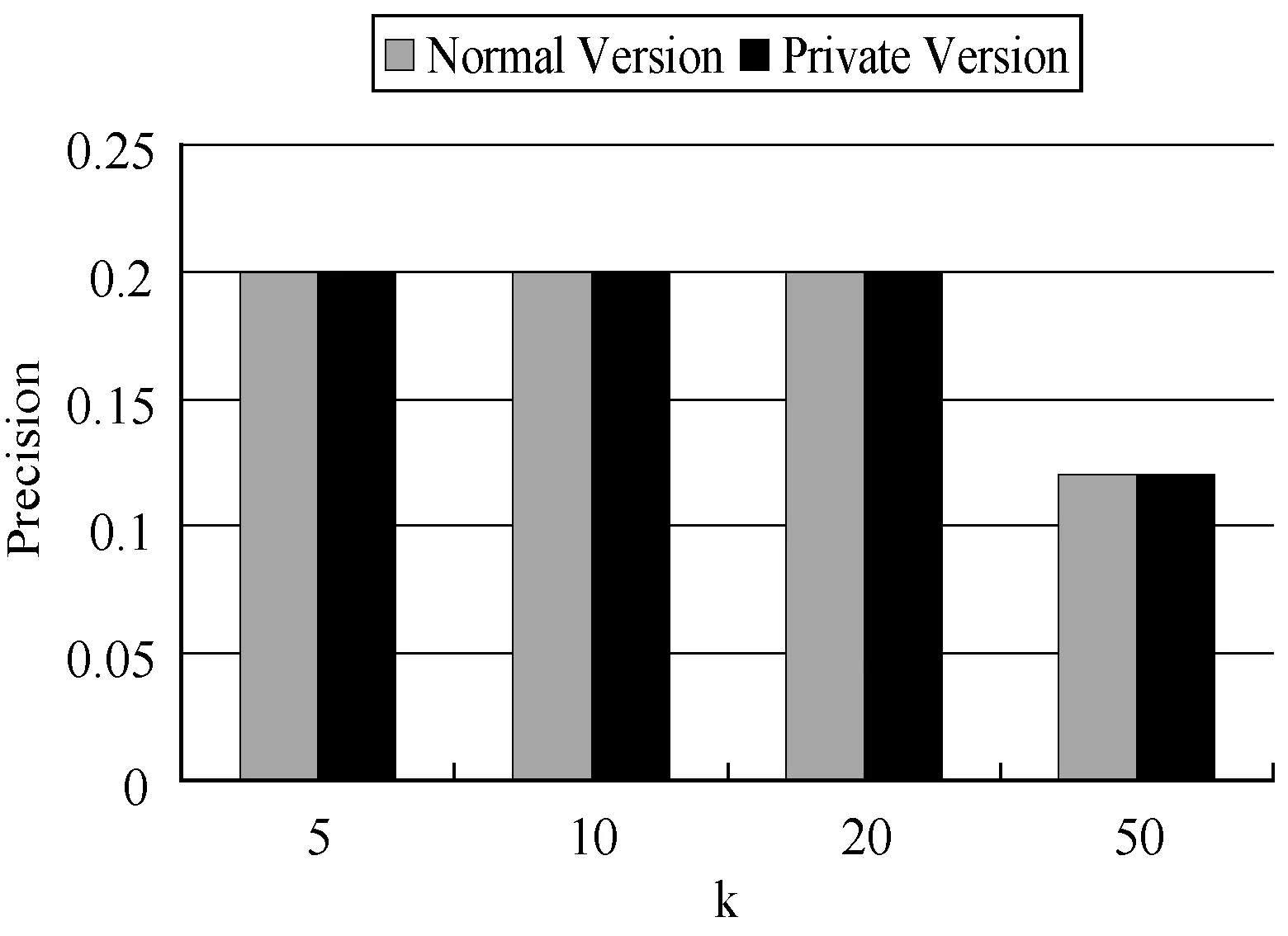
图6 两种推荐算法的Precision对比图
对图5和图6进行分析,可以得出无论是召回率还是准确率,差分隐私保护算法的加入都没有对推荐算法产生非常大的影响。传统的兴趣点推荐算法和加入差分隐私保护的兴趣点推荐算法的有效性总体一致,加入差分隐私保护的推荐算法从召回率和准确率这两个指标上看至少不会比传统的推荐算法差太多。
实验结果印证了我们对差分隐私保护的兴趣点推荐算法优越性的理论分析,使用该算法,不仅能保护用户的位置隐私信息,还能保证良好的推荐效果。
4 结 语
本文提出的基于差分隐私保护的兴趣点推荐算法的核心思想是在传统的推荐算法中加入差分隐私保护算法。通过对差分隐私定义、定理以及性质的理解,本文提出了一种全新的地理位置隐私保护算法。该算法首先根据数据集中各项记录的相互关系建立位置搜索树,方便接下来实验中的查找、加噪和发布处理;然后运用指数机制挑选出经常访问的k项记录;最后对这k项记录添加拉普拉斯噪声并发布加噪后的位置搜索树。该地理位置隐私保护算法与传统的位置隐私算法相比,运用了差分隐私保护机制,采用了树的结构来表示位置数据。对位置记录进行加噪处理时,加噪扰动的对象是节点中的所有位置记录,而不是对单独的位置记录进行加噪处理,这样设计算法不仅能减少加噪次数,使记录具有较高的可用性,还能保持记录之间的关联,提高算法的运行效率。
对实验结果进行对比分析可知,加入差分隐私保护机制的兴趣点推荐算法仍具有良好的性能。在实验过程中,该算法具有较高的数据可用性和安全性,能在很大程度上减少添加的噪声量,从而达到既能保护用户的隐私信息又具有良好推荐效果的目的。
猜你喜欢
上海师范大学学报·自然科学版(2022年3期)2022-07-11
舰船科学技术(2021年12期)2021-03-29
扬州大学学报(自然科学版)(2021年6期)2021-02-14
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
当代陕西(2019年9期)2019-05-20
劳动保护(2019年3期)2019-05-16
文苑(2018年21期)2018-11-09
当代贵州(2018年21期)2018-08-29
计算机应用(2016年10期)2017-05-12
饮食科学(2016年7期)2016-07-27
