
基于自更新混合分类模型的肌电运动识别方法
2019-09-15 23:58丁其川赵新刚李自由韩建达
自动化学报 2019年8期
丁其川 赵新刚 李自由 韩建达
基于表面肌电(Surface electromyography,sEMG)的运动识别(肌电运动识别)技术已被广泛用于实现假肢/假手、康复机器人、外骨骼机器人等辅助系统的交互控制[1−3],其中融合动作分类方法设计的肌电假手作为一种典型应用,受到了研究者更多关注.尽管肌电假手研究成果层出不穷,但真正投入市场应用,并被残疾人普遍接受的产品仍寥寥无几,造成该现状的一个重要原因,是在肌电时变性及外界干扰条件下,现有假手系统的鲁棒性较差,直接影响使用者的操控体验[4].
现有肌电假手所采用的动作分类方法,一般是针对固定数量的已知动作类型,先离线训练分类模型,随后使用训练后的固定参数模型,利用在线肌电数据识别出具体动作,进一步利用识别结果控制假手执行相应运动[5−10].实际应用中存在的两类干扰必然会影响肌电假手的鲁棒性:1)sEMG 时变性干扰.用于训练分类模型的sEMG 数据仅是有限量数据,而sEMG 是一种受肌肉即时状态影响的非平稳时变信号[11],因肌肉疲劳等因素导致在线sEMG 与离线训练数据存在较大差异时,分类模型的动作识别性能会大幅降低[12];2)外部动作数据干扰.训练的分类模型是针对少量已知目标动作的,其识别能力仅限于这些目标动作数据,在线应用时,若出现训练阶段未出现的动作数据,会作为外部动作数据干扰,直接影响模型识别的稳定性.
针对肌电时变性干扰,研究者提出模型更新策略以提升分类模型的鲁棒性.Kato 等[13]提出针对学习数据的自动增减及选择添加的在线管理方法,依据使用者指令,在线更新神经网络参数,使之识别动作能力适应sEMG 的时变特性;Yang 等[14]利用自适应SVM 识别9 种手部姿势,并引入遗忘因子降低过去sEMG 数据的影响,从而提高支持向量机(Support vector machine,SVM)长时动作识别的稳定性;Chen 等[15]提出自增强线性判别分析(Linear discriminant analysis,LDA)/二次判别分析(Quadratic discriminant analysis,QDA)算法,无需人工设置参数及大存储空间,所建立的分类模型可以根据样本特性更新参数,因此其长时识别性能不受sEMG 变化影响,从而提高肌电控制的鲁棒性.上述研究建立的自适应分类模型,仅是针对已知/目标动作的sEMG 变化进行参数更新[16],并未考虑外部动作数据对模型识别的干扰.针对外部动作干扰问题,Scheme 等[17]提出基于无关联线性判别分析(Uncorrelated LDA,ULDA)的多类1-vs-1分类策略,对每个已知/目标动作的sEMG 建立区间包络,当新sEMG 数据未进入任一包络区间,便被判定为未知动作数据干扰,该方法具备排除外部干扰的性能,但需人为设置较多阈值参数,影响其适用性;Li 等[18]提出一种强化随机森林分类器,通过调整后验概率平衡阈值,其识别已知目标动作与排除未知外部动作的精度都能达到80%;此外,一类SVM 与一类高斯分类器也用于排除外部动作干扰,提高分类模型的鲁棒性[19−20].上述方法都是在训练阶段,引入排除外部数据干扰的机制,训练后的模型并未在线更新,因此仅能排除外部动作数据,无法将其作为新的目标动作数据加入到模型识别中,同时这些方法也不能克服sEMG 时变性干扰的影响.
为了同时克服这两种干扰,并提升分类模型的在线识别能力,提出一种自更新混合分类模型(Selfupdate hybrid classification model,SUHC),用以实现肌电运动识别.本文的主要工作归纳为以下三点:1)融合一类分类算法与多类分类算法,提出一种混合分类算法框架;2)结合一类SVM 和多类LDA,建立一个混合分类模型,并引入了自更新策略;3)利用提出的自更新混合分类模型,建立可克服sEMG 时变性与外部动作数据干扰的肌电运动识别模型.与已有的仅针对单一干扰的方法相比,在基于SUHC 的肌电动作分类中,一类SVM 用于排除外部动作数据干扰,多类LDA 用于分类目标动作数据,而自适应更新机制用于克服sEMG 时变性干扰,并提高模型识别能力.通过手部动作识别实验验证本文提出方法,结果显示提出的SUHC 在抵抗sEMG 时变性及外部动作数据干扰方面,都表现出优越性能.
1 自更新混合分类模型
参考文献[19−21],定义{ω1,ω2,···,ωK}为K个已知目标类,对于样本x,若存在ωi,i=1,2,···,K,使得x ∈{ωi},则称x是目标类样本;否则x是未知/外部类样本.
1.1 混合分类模型框架
针对外部类数据干扰,本文提出一种融合一类分类器和多类分类器的通用混合分类模型框架,其中一类分类器用于判断样本数据是否属于外部类,而多类分类器将非外部类样本分配到某一确定目标类.图1 给出了该模型框架的示意图,其中添加不同的分类器,可形成具体混合分类模型.
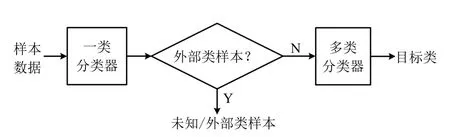
图1 混合分类模型框架Fig.1 The framework of hybrid classification model
1.2 融合一类SVM 和多类LDA 的SUHC
基于混合分类模型框架,融合一类SVM 和多类LDA,建立一个混合分类模型,进一步针对两种分类方法分别引入自适应更新策略,以对抗样本数据时变性干扰,从而形成SUHC.
1.2.1 自更新一类SVM
一类SVM 又称一类支撑向量数据描述器(Support vector data description,SVDD)[21],用于判断样本数据是否属于已知目标类.已有K个目标类{ω1,ω2,···,ωK},设i=1,2,···,K是已获得的一个属于ωi的样本集,其中Ni是样本个数.使用Xi训练一个一类SVM 分类器,即是求一个以a为中心,R为半径的最小体积超球面,可以封闭包围所有的目标样本或其高维映射.该优化问题如下:
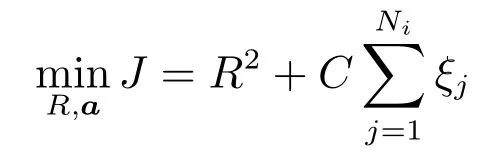
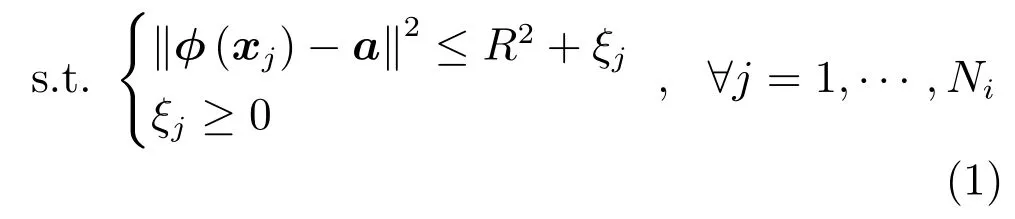
其中,C是惩罚因子,ξj是松弛变量,φ(·)是非线性函数.需要注意的是,式(1)中的变量/参数都是与类ωi关联的,为表述简洁,没有再对上述变量/参数加指标i.
通常将式(1)转化为它的对偶问题,通过求解对偶问题,获得优化参数,这些参数满足Kuhn-Tucher(KT)条件[21−23].基于KT 条件,训练样本集Xi中的样本分为3 个部分:1)其高维映射落入超球内的样本点,组成保留样本集Er;2)映射恰处于超球面上的点,组成边沿支撑向量集EmSV;3)映射处于超球外的点,组成偏差支撑向量集EeSV.EmSV和EeSV组成支撑向量集ESVs.
利用优化的参数和支撑向量集ESVs,可以计算超球中心a和半径R,于是便建立了类ωi的一类SVM 分类器.对于一个新样本z,若式(2)成立,则z是目标类ωi的一个样本,否则z相对于ωi是一个外部类样本,
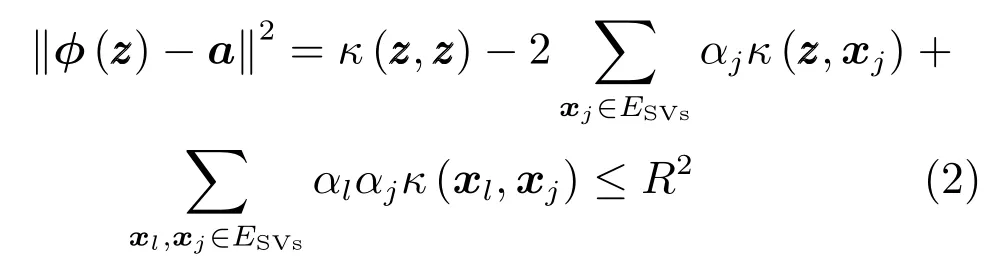
其中,κ(xk,xj)=φ(xk)·φ(xj)是核函数(本文使用径向基核函数),αj是对偶问题的优化解.
因此,为每个类ωi分别建一个一类SVM,便可以使用这些一类SVM 构成的分类器集合,判断任一新样本z是否是外部类样本.定义Z={z1,z2,···,zM}为在线获得的一个新样本数据集,包括M个样本.使用Z更新已训练的一类SVM 分类器,可分成两种情形:
1)若Z中所有样本都来自同一目标类ωi,则更新ωi的一类SVM.在线更新方法可以参考文献[22−23].更新过程,新样本加入会改变Er、EmSV和EeSV中原来样本的所属关系,即某些样本可能从一个集跳到另一个集,但经过优化后,最终各集合样本及其优化参数,仍要满足KT 条件.
2)Z中所有样本都属于同一外部类,则使用这些样本直接训练一个一类SVM(要求Z中样本个数要大于并将训练后的一类SVM 添加到分类器集合.
1.2.2 自更新多类LDA
使用一类SVM 分类器集判定一个新样本属于目标类样本后,进一步可以使用多类LDA 将该样本归到具体的目标类.需要强调一点,虽然依照第1.2.1 节中的方法,也可以将一个新样本z归到某个确定的目标类,但上述求得的针对不同目标类的一类SVM,其封闭包围区域可能重合,从而造成落入重合区域内的样本分类混乱.
多类LDA 算法需求取一个投影矩阵W,使得原始样本经过W线性变换后,同类样本的投影类间距最小,异类样本的投影类间距最大[24].利用各目标类已获得的样本集Xi,i=1,2,···,K,先计算各类的样本均值mi,样本平方和Gi,样本协方差矩阵Si,以及所有目标类的总样本均值m;然后可计算所有目标类的类内间距矩阵Sw和类间间距矩阵Sb.
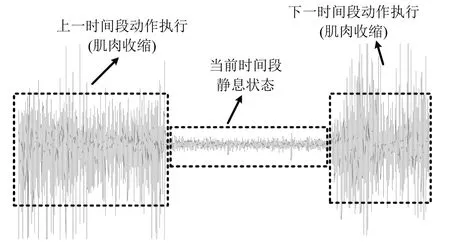
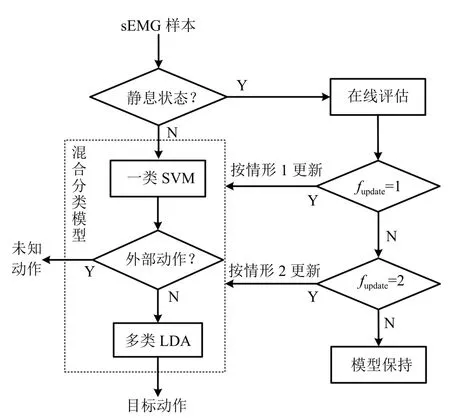
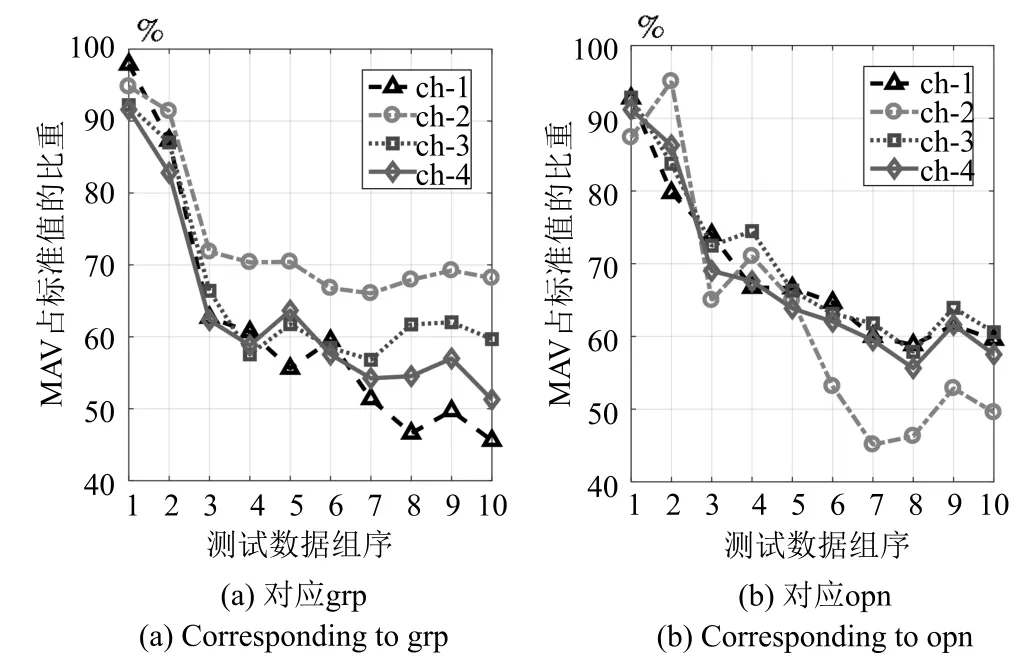
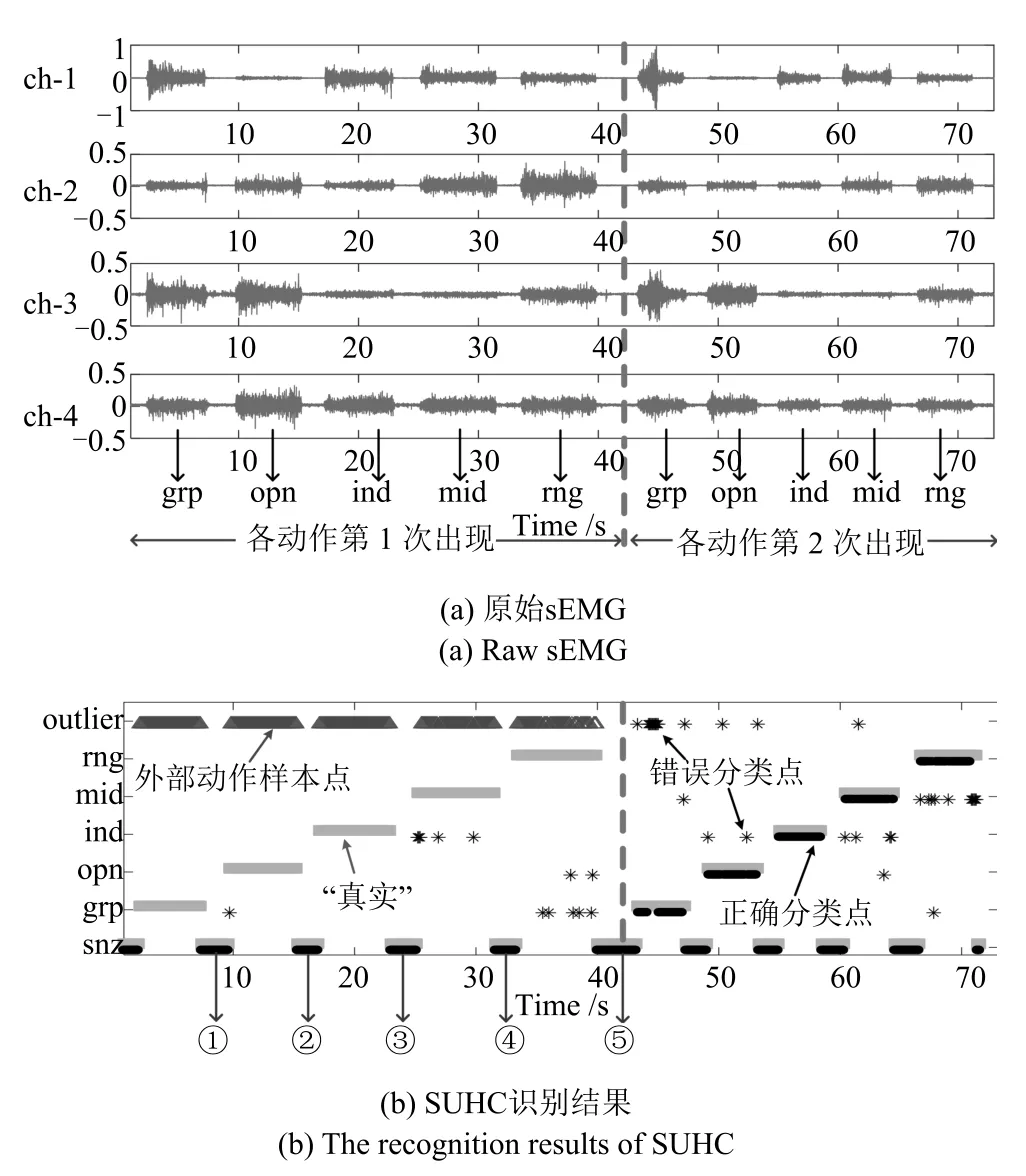
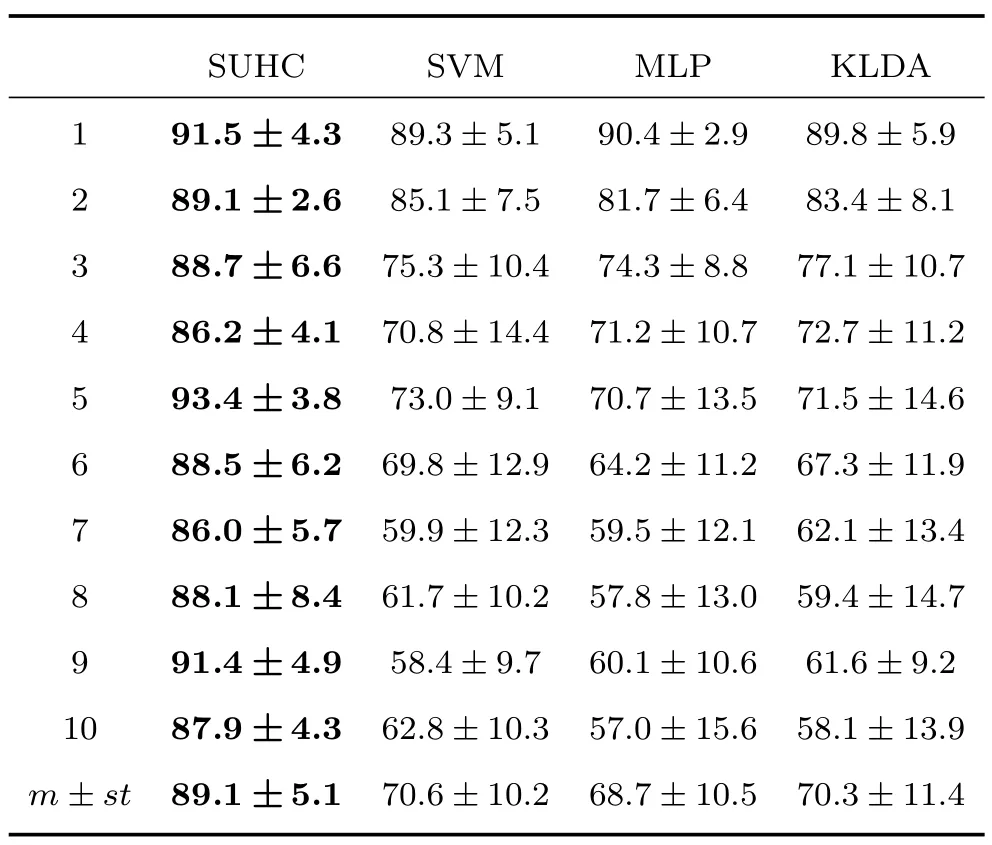
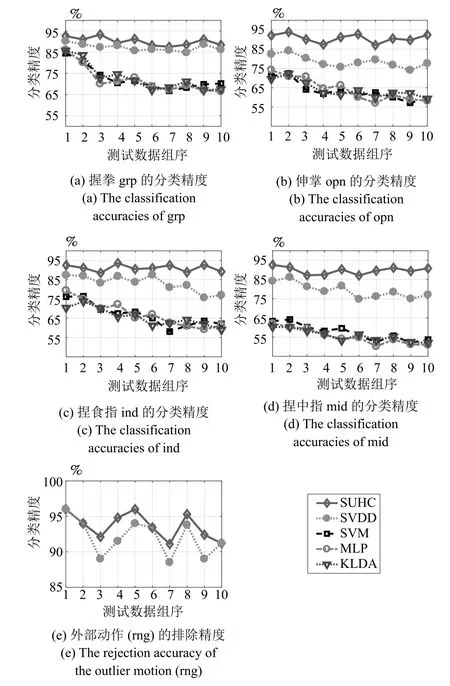
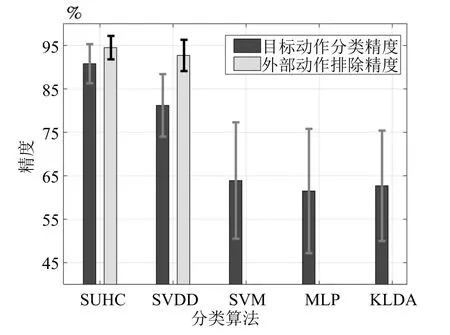
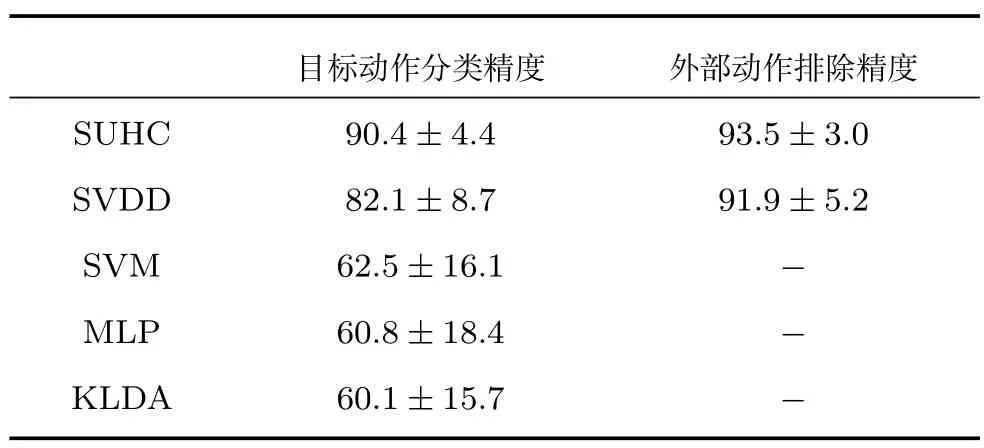
可证明最优投影矩阵W,是由的前q(q 下面将LDA 改进为可在线更新的算法.利用新样本数据集Z={z1,z2,···,zM}更新LDA 算法,即是更新投影矩阵W,也即是更新类内间距矩阵Sw和类间间距矩阵Sb.同第1.2.1 节,也分成两种情形: 1)Z中所有样本都来自同一目标类ωi,对各参量更新为 2)Z中所有样本都属于同一外部类,需要将Z作为新的目标类,并使用其中样本更新Sw和Sb.首先计算新目标类的样本均值、平方和与协方差矩阵, 于是其他参量更新如下 上标“∼”表示更新值.完成更新后,计算的前q个最大特征值对应的特征向量所构成的矩阵,以更新投影矩阵W,便获得更新后的LDA.将自更新一类SVM 和自更新多类LDA 相结合,加入图1 的混合模型框架,便得到本文所提出的SUHC. 将提出的SUHC 应用于肌电动作识别时,要考虑两个问题:1)使用哪些新数据更新模型;2)模型何时自更新.本文将结合人体运动及肌电信号的特点,设计自更新肌电运动识别算法.一方面,人体执行动作时,相关肌肉会收缩,相比于肌肉静息(无动作)状态下采集的sEMG,肌肉收缩激发的sEMG的幅值/频率会有较大变化(如图2),因此通过简单的阈值判定,便可以有效区分肌肉静息(无动作)与收缩(执行动作)状态;另一方面,人(特别是肢体损伤患者)的运动多是慢速的,一个动作执行过程一般会持续一段时间[13],且静息作为各动作的缓冲状态常间隔分布于整个运动过程.基于上述特点,在肌肉处于静息状态时,先对上一时间段内,动作执行过程中获得的在线数据进行评估,根据评估结果,选定更新样本,进而启用自更新算法.评估及更新都在静息时段内完成. 当肌肉处于静息状态时,先计算上一个执行运动时间段内的各动作的分类率及其最大值 其中,Npre_total是上一个执行运动时间段内总样本数,Npre_ωi是归到目标动作类ωi的样本数,βi是ωi的分类率,β最大分类率. β可用于对上一个执行动作时间段内样本数据的评估,设置如下评估及更新准则 图2 肌肉收缩及静息状态下,采集的连续sEMGFig.2 The continuous sEMG signals sampled at the states of muscle contraction and resting 其中,η3<η1<η2是判定更新的常数阈值. 若fupdate=1,说明上一时间段的样本都属于某已知目标动作类,但当前模型的分类正确率较低,需要使用上一时间段的在线样本,按第1.2.1 节和第1.2.2 节中情形1 对模型更新;若fupdate=2,说明上一时间段的样本都属于某个未知外部动作类,利用这些样本,可按照情形2 对模型更新,使之识别动作的能力增量成长(新动作加入后,需要人工设置学习标签);若fupdate=0,则舍弃上一时间段内样本,保持当前模型不变.图3 给出完整算法流程,需要注意的是,在初始时刻,混合模型可以为空(Null),当获得第一个目标动作类数据后,模型在线更新;但仅当目标动作类个数大于等于2 时,才能构建多类LDA. 图3 基于SUHC 的肌电运动识别算法Fig.3 The SUHC-based EMG-motion recognition algorithm 本节通过基于肌电的手部动作识别实验验证提出方法的性能. 共4 名肢体健康受试者参与本文的所有实验(男性,年龄30±5 岁,身高171±4 cm,体重67±9 kg).本文考虑识别5 种手部动作:握拳(grp)、伸掌(opn)、捏食指(ind)、捏中指(mid)、捏无名指(rng),另外手部休息姿态作为间隔各动作的静息状态(snz),如图4 所示.选取4 块与上述运动密切相关的肌肉:掌长肌、桡侧腕屈肌、指伸肌、指屈肌,进行sEMG 采集(图5). 图4 识别的5 种手部动作以及手部休息姿势snzFig.4 The five kinds of hand motions and the snooze state(snz)that were recognized in the paper 图5 选取的肌肉及布置的采集电极,其中ch-i,i=1,2,3,4,表示第i 通道电极Fig.5 The selected muscles and the placement of electrodes,where ch-i(i=1,2,3,4)represents the ith channel electrode 使用无线肌电采集系统(Delsys,Trigno)采集sEMG,采样频率为2 000 Hz,4 个通道的电极布置如图5 所示.进行数据采集时,每名测试者尽可能使用最大力执行每种动作,动作执行按照握拳、伸掌、捏食指、捏中指、捏无名指的顺序,每个动作持续约4 s,每两个动作间隔一个3∼4 s 的静息状态,整个过程循环4 次,则一组数据采集结束(时间约2.5 min),如图6 所示.每组数据采集结束后,约有10 s 的间隔用于数据保存操作,而后进入下一组数据采集.每名测试者共要完成12 组sEMG 数据采集,总时间约32 min,12 组数据集的前2 组作为训练数据,后10 组作为测试数据. 图6 一组数据采集过程Fig.6 The sampling process of one session of sEMG-data 对原始sEMG 进行去偏置、滤波处理,其中滤波器采用10∼500 Hz 的Butterworth 带通滤波器;然后设定一个250 ms 的时间窗加100 ms 增量窗,用于sEMG 特征提取[4].在每个时间窗内,从每通道sEMG 提取7 个特征,包括1 个平均绝对值(Mean absolute value,MAV)和6 个倒谱系数(6-order Ceps)[5−6].4 个通道的所有特征共同构成一个样本,因此每个样本的28 维(4×7)样本生成过程如图7 所示. 图7 sEMG 样本生成过程Fig.7 The generating process of sEMG samples 将获得的sEMG 样本输入提出的SUHC 进行手部动作识别,同时为进行性能比较,三种常用的分类算法:多类SVM(使用1-vs-all 策略)[25]、多层感知器(Multiple layer perceptron,MLP)[26]和核线性判别分析(Kernel LDA,KLDA)[27−28]也被用于执行动作识别任务.注意要为每位测试者分别建立相应的肌电运动分类模型. 分两种情况测试模型运动识别的性能:1)无外部动作干扰,离线训练模型时,5 种手部动作都是已知目标动作;2)有外部动作干扰,训练阶段握拳(grp)、伸掌(opn)、捏食指(ind)、捏中指(mid)作为已知动作,捏无名指(rng)作为未知外部动作干扰.先给出1 号测试者(Subject-1)的详细结果,随后给出所有测试者的平均结果. 本节先对实验数据作简要分析.在采集数据时,测试者尽可能使用最大力执行各种动作,整个采集时间超过30 min,在此期间无充分休息,因此该过程会导致肌肉疲劳,而sEMG 特征MAV 可以被当作指示肌电能量的指标.先使用训练数据计算关联各动作的MAV 平均值g1,以此为标准,然后分别使用每组测试数据计算针对各动作的MAV 平均值g2,最后计算比例g2/g1,用于判断肌肉状态变化.图8分别给出了握拳(grp)和伸掌(opn)动作所对应MAV 的占比变化,由图可见,由10 组测试数据获得的MAV 呈整体降低趋势,某些肌肉的MVA 的下降幅度甚至达到50%(如图8(a)的ch-1 和8(b)的ch-2,其中ch-i(i=1,2,3,4)表示第i通道电极获得的数据),由此可见,随着时间推移,肌肉疲劳状态逐渐显现,而采集的sEMG 能量受疲劳影响不断降低. 图8 由10 组测试样本数据计算的MAV 占其标准值比Fig.8 The ratio of MAV with respect to the standard value calculated by using the ten sessions of test data 使用训练数据离线训练模型(仅离线训练SVM,MLP 和KLDA,而SUHC 具有在线更新的特性,后续给出SUHC 的更新建模图示),然后将测试样本按组序(数据采集时各组顺序)输入训练后的模型,分析其动作识别效果.定义评估指标为目标动作分类精度 其中,Ncorr_ωi和Ntotal_ωi分别是正确分类到ωi类的样本数和总的分类到ωi类的样本数,而Nωi_total是“真实”应该属于类ωi的样本数,通过离线统计获得. 设置式(16)中的参数η1=0.6,η2=0.85 及η3=0.45,然后将前2 组训练数据输入到图3 算法中,执行SUHC 在线更新.图9 给出了第1 组训练数据(Subject-1)的前2 个循环输入到算法后的识别结果,图9(b)中三角形点是识别的外部类样本点,实点是“真实”动作样本点(离线统计获得),星号点是错误分类样本点,正方形点是正确分类样本点.由图9(b)可见,当每个动作第1 次出现时,算法会判别它为外部动作,需要在下一个休息状态(①∼⑤状态),人工加入学习标签,以利用相应动作数据更新SUHC,实现其识别能力增量增长.因此当相应动作数据第2 次出现时,SUHC 便可以对它分类识别. 图9 将Subject-1 的第1 组训练数据输入SUHC(仅给出该组数据的前2 个循环),实现模型在线更新Fig.9 Online updating the SUHC by inputting the first session of training data of Subject-1 into the model(only plot the first two cycles of the data) 将后10 组测试样本按组序依次输入训练后参数固定的SVM,MLP 和KLDA,以及可在线更新的SUHC,计算不同模型的动作分类精度.图10 给出使用Subject-1 的10 组测试数据计算的结果.由图10 可知,不同模型的运动识别结果差异较大.因训练后的SVM,MLP 和KLDA 参数固定,当测试样本(如第1、2 组测试数据)数据与训练样本数据差异较小时,各动作识别精度较高(大于80%),但是随着测试样本与训练样本的差异逐渐变大,识别精度也不断降低;而SUHC 模型在线调整参数,以适应样本数据变化,整个过程都保持较高的识别结果(大于85%).针对5 种动作,可计算平均分类精度 其中,K=5 是动作类个数. 对实验数据分析可知,采用不同测试者的模型和数据计算的结果无显著性差异(设置单因素方差分析显著差异水平为0.05[29],而采用不同测试者模型和数据计算获得p >0.1).使用每个测试者的模型及其10 组测试样本,通过式(19)计算平均分类精度;然后按照数据组序再计算针对所有测试者的平均值和标准差;最后计算总的平均值(m)和标准差(st),结果列于表1 中(表1 中第1 列1,2,···,10 表示10 组测试数据,m和st分别表示均值和标准差).由表1 可知,SUHC 对不同组测试样本的识别结果整体平稳,平均精度达到89%;而SVM,MLP 和KLDA 的识别精度下降明显,整体平均值仅是70% 左右,与SUHC 的精度相比,平均降幅约18%,而最大降幅超过25%,可见针对sEMG 的时变性,SUHC 的鲁棒性远优于常用的SVM,MLP和KLDA. 表1 使用所有测试者的10 组测试样本计算的平均分类精度与标准差(%)Table 1 The mean classification accuracies and standard deviations calculated by using the ten sessions of test data of all subjects(%) 这里将grp,opn,ind 和mid 作为4 个目标动作,而rng 作为外部动作.将训练数据中关联rng 的数据全部去除,然后离线训练SVM,MLP和KLDA;对于SUHC,将rng 的数据去除,即图9中,不会出现rng 的数据和状态⑤.另外,本节也考察单独采用一类支撑向量数据描述器(SVDD)的动作识别结果,将图3 中多类LDA 去掉,即为SVDD的算法过程,随后将去除rng 的训练数据组也输入SVDD,过程与图9 所示相同. 所有的测试数据仍含有rng 数据,以测试各方法排除外部干扰效果.图11 给出各模型对一组测试数据(前2 个循环)的分类结果.由图11 可知,5 种模型都可以对4 种目标动作数据进行分类,因为在训练数据中没有rng 数据,SUHC 和SVDD 会把rng 数据作为外部动作数据排除(测试阶段出现rng数据,只要不添加新类标签,模型便不会针对rng 更新),但是SVM,MLP 和KLDA 没有排除外部干扰的能力,会将rng 数据错分到目标动作类中.为定量评估模型排除外部干扰性能,参照式(17)和式(18),定义外部动作排除精度 将Subject-1 的10 组测试数据输入各模型,分别计算针对目标动作(grp,opn,ind,mid)的分类精度与针对外部动作(rng)的排除精度,图12 给出结果,其中12(a)∼12(d)是针对目标动作的分类精度,12(e)是针对外部动作的排除精度.利用式(19)计算相应精度的均值和标准差,图13 给出结果. 由图12 和图13 可知,SUHC 对目标动作类分类精度高于SVDD,这是因为SVDD 对不同目标类的封闭包围区域出现重叠,导致位于重叠区域的样本分类混乱,从而降低了SVDD 的分类精度.SVDD的外部动作排除精度略低于SUHC(见图12(e)),是由于两个模型在线更新(针对目标动作数据时变性的更新)次数不同所致.SVM,MLP 和KLDA 的目标动作分类精度远低于前两者,两个原因导致这一结果:1)训练后的SVM,MLP 和KLDA 模型参数固定,由前面分析可知,因疲劳导致的sEMG 时变性会降低它们的分类精度;2)SVM,MLP 和KLDA并没有排除外部动作干扰的能力,而外部动作(rng)类样本会被误认为目标动作样本强制分配到各个目标类,从而进一步降低了分类精度.分别使用每个测试者的模型及其测试样本,计算目标动作分类精度与外部动作排除精度,然后计算针对所有测试者的均值和标准差,结果列于表2.由表2 可知,SUHC的目标动作分类精度达到90%,比SVDD 的分类精度高约8%,更比SVM、MLP 或KLDA 的分类精度高了约28%;SUHC 的外部动作排除精度也达到93%,具有较好的抗外部类数据干扰能力,而这更是SVM,MLP 和KLDA 所不具备的. 图11 使用Subject-1 的1 组测试数据获得的动作识别结果Fig.11 The motion recognition results obtained by using one session of test data of Subject-1 图12 存在外部动作(rng)干扰情况下,使用Subject-1 的10 组测试数据获得的识别结果Fig.12 In the case of outlier-motion(rng)interference,the recognition results obtained by using ten sessions of test data of Subject-1 图13 使用Subject-1 的测试数据,计算的分类精度与排除精度的均值和标准差Fig.13 The means and standard deviations of classification and rejection accuracies computed by using the test data of Subject-1 表2 使用所有测试者的测试数据计算的分类精度与排除精度的均值和标准差(%)Table 2 The means and standard deviations of classification and rejection accuracies computed by using the test data of all subjects(%) 针对肌电运动识别过程中,因肌电时变特性及外部动作干扰导致识别效果差的问题,提出一种自更新混合分类模型SUHC,通过对动作分类结果的在线评估,实现SUHC 参数调整,以适应sEMG 的变化;SUHC 具备排除外部动作干扰的能力,并能将外部动作类作为新的目标动作类加入到运动识别模型中,实现了其识别能力的增量增长.应用SUHC时,设置合适的在线评估参数(即式(16)中η1,η2和η3)十分重要,直接决定了模型更新次数及分类效果,需要根据实际应用寻求合适阈值. 在验证算法性能的实验中,测试者尽可能使用最大力执行动作,短时内造成肌肉疲劳,导致sEMG有较大波动,结果显示提出的SUHC 能克服sEMG短时大幅波动的干扰,保持动作识别的鲁棒性.不同于本文实验,前期研究中,多是探讨长期采集甚至隔天采集数据的变化对运动识别的影响[12,15],该过程中sEMG 一般缓慢时变,针对该情形如何设置SUHC 的评估参数下一步要探讨的问题.在存在外部动作干扰时,传统的SVM,MLP 和KLDA 都不具有排除外部动作数据干扰的能力,而对外部类数据的错误分配,直接导致目标动作分类精度大幅降低;提出的SUHC 具备排除外部类干扰的能力,其目标动作识别精度超过90%,远高于SVM,MLP和KLDA,而其外部动作排除精度为93%,这两项指标也高于已有文献的结果,如文献[18]中方法的两种精度都是80%,文献[19]中方法的目标动作分类精度为87%. 本文实验仅考虑了sEMG 时变性与外部动作干扰两种非理想情形,实际上进行肌电运动识别时还有很多不确定因素,如肌电数据丢失、电极位置偏移、皮肤汗液及外部电磁干扰等[30],后续工作会继续改进提出的算法,使之可以应对更多非理想情形,从而提升实际肌电识别系统的综合性能.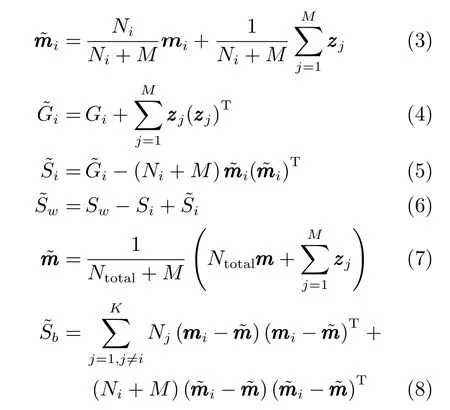
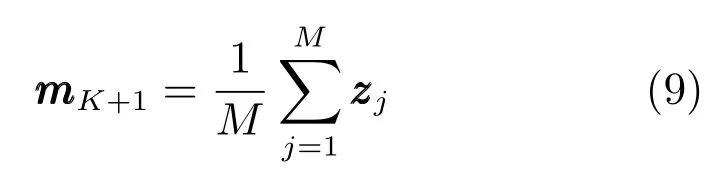
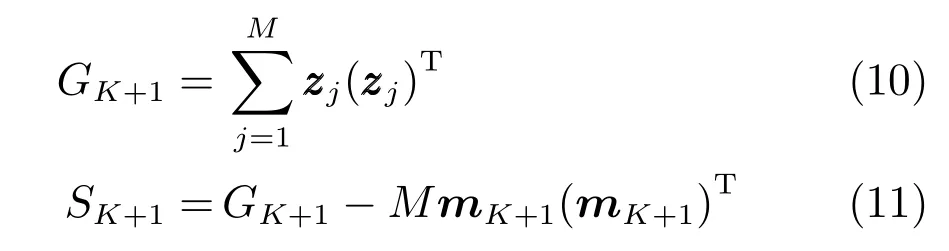
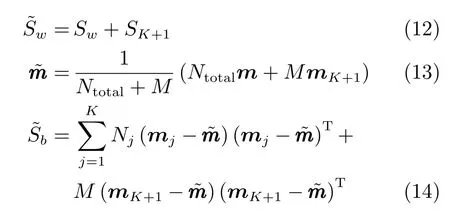
2 自更新肌电运动识别算法
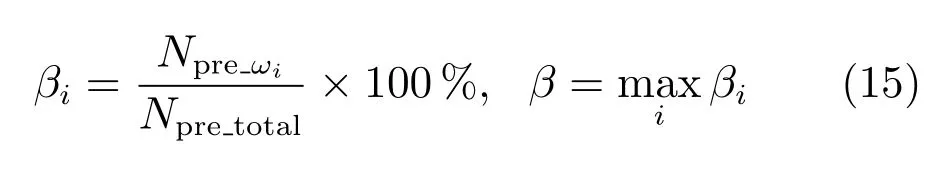

3 手部动作识别实验
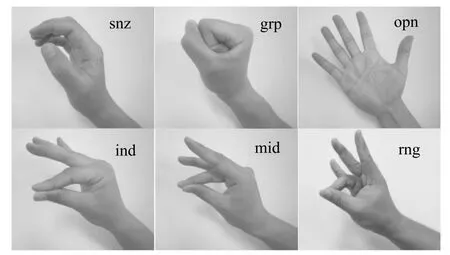
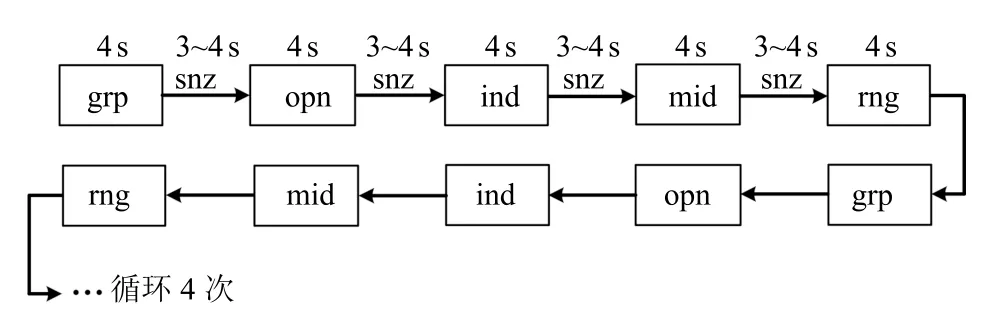
3.1 实验设置
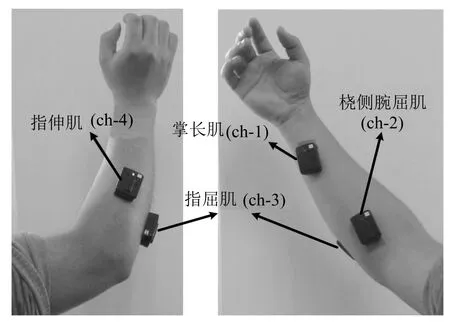
3.2 sEMG 信号采集
3.3 sEMG 特征提取与动作识别

4 实验结果
4.1 无外部动作干扰

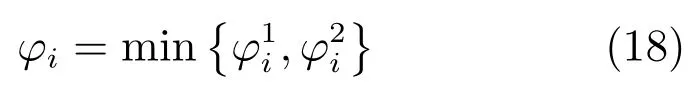
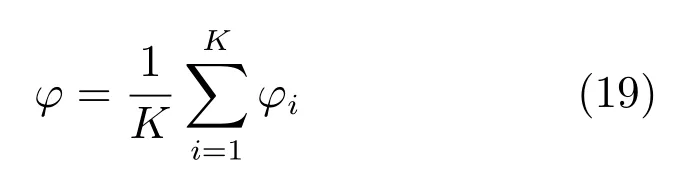
4.2 存在外部动作干扰

5 讨论与未来工作

猜你喜欢
中国典型病例大全(2022年7期)2022-04-22
中国药学药品知识仓库(2022年1期)2022-03-23
一重技术(2021年5期)2022-01-18
计算机系统应用(2021年2期)2021-02-23
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
电子技术与软件工程(2019年18期)2019-11-18
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年11期)2018-08-04
中国美容医学(2018年12期)2018-02-27
电子技术与软件工程(2017年14期)2017-09-08
