
链路预测的方法与发展综述
2019-09-20 07:35
测控技术 2019年2期
(北京信息科技大学 信息与通信工程学院,北京 100101)
复杂网络能够很好地描述社会科学、自然科学、管理科学以及工程技术等领域的相互关联的复杂模型,应用范围广泛。其以复杂系统为研究目标,利用数学、统计学、计算机等科学工具,分析和研究事物的本质结构和规律。复杂网络具有规模庞大、连接结构复杂、节点种类多样以及网络演化过程复杂的特点,使得其研究充满了挑战。但是,掌握了复杂网络的演化规律可以帮助人们更好地掌控网络结构的变化趋势,因此,吸引了越来越多的人去探索复杂网络已存在的结构特征及其发展趋势。
链路预测是研究复杂网络的核心内容之一。在复杂网络中,个体被称为节点,节点与节点间的关系称为链接。链接的内在机制、形式和结构在不同系统中的演变过程揭示了人类在社会活动中的行为和趋势[1]。研究链接的产生有助于塑造和提高对人类行为和社会网络的理解,也有助于推进对其他众多领域的研究,比如社交软件的好友推荐系统、网络超链接的预测以及股市走向等。准确的链路预测为复杂网络的进化研究工作提供了有力帮助。因此,对复杂网络中的结构和链路进行研究和建模是十分必要的。
本文对节点属性、网络拓扑结构、机器学习、最大似然等4类链路预测方法进行总结与概括,介绍了各类方法中学者们提出的一些经典算法,对这4种方法的优缺点进行了阐述。对几种较为常见的评价链路预测算法精确度的方法进行了介绍,最后对链路预测的未来研究方向和发展前景进行了总结和展望。
1 网络模型介绍


表1 网络符号及定义
链路预测的定义为:对选定的真实网络数据集进行处理,将连边集合E分成训练集ET和测试集EP两部分,且训练集和测试集并无交集。一般随机选择边作为测试集的边,时序链路预测中,会将最近时间内产生的边作为测试集。利用链路预测方法,计算出训练集中的给定节点对(x,y)的评分数值Sxy,并将评分数值Sxy按大小进行排序,如果节点对的评分数值越大,那么节点间产生链接的可能性越大,将得到的预测结果与测试集进行对比得出评价结果,从而得出真实网络的演化模型并对其进行预测和分析。其具体过程如图1所示。
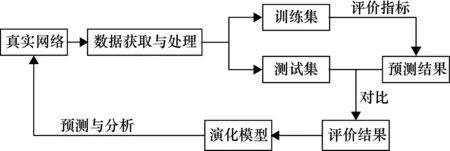
图1 链路预测过程描述
链路预测的方法基本分为4类:以节点属性为基础、以网络拓扑结构为基础、以机器学习为基础以及以最大似然为基础。基于节点属性的链路预测方法有助于提高预测准确度,但是节点属性,如姓名、爱好、地理位置等信息难以获取,而且已获取信息的时效性和真实性不能确定。与该方法相比较,基于网络拓扑结构的方法容易获取网络结构信息,通过网络结构,更容易发现哪些节点更倾向于连接或断开连接。部分学者利用基于机器学习或最大似然等技术更新的链路预测方法,与节点属性、网络结构等信息相结合,综合性地对连接关系进行预测,大大提高了链路预测的准确程度。
2 链路预测方法分类
2.1 基于节点属性的方法
在早期对链路预测的研究中,多数学者采用的是基于节点属性的链路预测方法。两个节点的属性,如兴趣爱好等越相似,就越容易产生连接。在社交网络中,最简单的获得节点属性的方法就是使用标签。卜心怡等人[2]利用微博做出了实证分析,用粉丝数量、微博数量、关注人数、转发微博数量等作为节点属性标签,与基于共同邻居的算法相结合进行节点连接的预测。Jure等人[3]利用包含超过300亿次对话、1.8亿节点与13亿链接的数据集进行了仿真,证明人们更倾向于和相同地区、共同兴趣、爱好相似的人建立新连接。利用节点属性等信息可以提高的预测准确性,但网络用户更倾向于保护自己的隐私,信息的获取变得难度很大,即使成功获取信息也无法保证其准确性。此外,在获取信息后,如何提取有用信息也是较为烦琐的工程。因此,基于节点属性的链路预测方法在实现上具有一定的难度,更多学者倾向于使用以网络拓扑结构为基础的方法进行链路预测。
2.2 基于网络拓扑结构的方法
基于网络拓扑结构的链路预测方法的原理为:以网络结构的相似性为基础,判别节点的相似性,两个节点的结构越相似,那么它们之间越可能产生连接。以网络拓扑结构为研究基础的链路预测方法,可以分为3种研究方向:以局部信息、路径和随机游走为基础。
解决链接预测问题最有效的方法是建立相似性指标。不同的链路预测方法主要区别之一即是相似性指标的不同。相似性指标是定义网络节点之间相似性的评分函数,根据该函数对网络中所有的节点,两两计算相应的评分数值。
2.2.1 基于局部信息的方法
在基于局部信息的链路预测方法中,最基本的是共同邻居(Common Neighbor,CN)指标。CN评价指标代表了两个节点间共同邻居的多少。如果其数目越多,这两个节点越可能进行连接。除此之外,CN评价指标还有很多基于邻居其他属性的评价方式:Salton指标[4]、Jaccard指标、Sorensen指标、LHN-I指标等,如表2所示,分别利用了共同邻居、邻居的并集以及节点的度属性等。另外,Adamic和Adar还提出了AA指标,其主要考虑节点对共同邻居的重要程度不同,从而通过共同邻居的度来突出这一特点。Zhou等人[5]对9种基于局部性的指标进行了准确性对比,并提出了准确度更高的资源分配(Resource Allocation,RA)指标。大量的实验结果显示,RA指标与AA指标的表现相近,但在准确性上略微高于AA指标。

表2 相似性指标及其定义公式
2.2.2 基于路径的方法
基于路径的相似性指标有3种不同的研究方向,局部路径(Local Paths,LP)指标、LHZ-II指标以及Katz指标。
CN指标可以看作是考虑两个节点间的二阶路径数目,LP指标在CN指标的基础上进行了改进,在二阶路径的基础上再考虑三阶路径数目。当考虑的阶数越来越多,趋近于无穷时,这一指标的计算公式就相当于Katz指标了,与LP指标相比,Katz指标的计算复杂度也成倍增高。Leicht等人提出了基于自相似度矩阵的LHZ-II指标,表示如果两个节点是相似的,它们在网络中的邻居也相似,那么它们建立连接的可能性较大。LHZ-II指标可以使用网络的邻接矩阵关系,进行多次迭代遍历网络中所有节点的相互关系,进行链路预测。
2.2.3 基于随机游走的方法
基于随机游走的指标,比如Cos+指标、重新开始的随机游走指标(Random Walk with Restart,RWR)以及Sim Rank指标等。
Fouss等人基于马尔科夫随机游走模型,通过计算平均通勤时间等信息,为节点对之间的链接定义Cos+相似性指标。实验结果表明,该算法在Mivieles数据集上表现良好,但不能很好地应用于大型数据集。张学佩[6]定义了局部随机游走的节点相似度指标,并与其他相似性指标进行比较。结果表明,其提出的算法具有更低的计算复杂度。Jeh等人认为,如果两个节点的邻居节点相似,则它们是相似的,并据此提出了Sim Rank指标。
2.3 基于机器学习的方法
现有的链路预测方法除了以相似性为研究基础,还有基于机器学习的方法,主要分为三大类:特征分类、概率模型以及矩阵分解。基于机器学习的算法有助于解决数据挖掘中的常见问题,例如类别不平衡,过度拟合等。
在基于特征分类的链路预测算法方面,很多学者使用监督学习中一些较为常用的算法,比如支持向量机、决策树、径向基网络、神经网络[7]等,对未知链接进行预测,其中预测精度最高的是支持向量机方法。Li等人[8]将快速分类法应用于支持向量机,对分类器进行训练,把大部分预测过程中测试阶段传递到训练阶段,大大减少了预测阶段的时间复杂度。Yuan等人[9]提取推特中用户的情感信息,通过分析情感特征来判断两个用户是否可能成为好友。实验结果表明,提出的模型优于Logistic分类器和随机森林。
基于概率模型的链路预测算法的主要思想为,首先建立一个可以调整参数的可预测模型,然后在调整参数的过程中找到使模型达到最优的参数值,可令模型的预测准确度达到最高。构建概率模型的方法主要有马尔科夫网络关系模型以及贝叶斯网络模型等。Liben等人[10]首先利用机器学习的方法进行了链路预测,且预测准确度较高。Asil等人[11]使用监督学习的方法进行链路预测,并证明多数情况下,加权网络比未加权网络在监督和非监督方法中都有更好的预测结果。Gupta等人[12]将链路预测问题视为二元分类问题,应用贝叶斯分类来预测网络中缺失的链接。基于概率模型的链路预测研究可以扩展到包括社交网络分析在内的各个领域,可以用来发现生物学中蛋白质的相互作用[19],帮助建立电子社交网络中的推荐系统[13],还可以识别出社交网络中隐藏的连接。
在基于矩阵分解的链路预测算法,Menon等人[15]提出了一个扩展矩阵分解的模型来解决有向网络中的链路预测问题,并在实验中证明,显式特征通常能够提供比隐式特征更好地链路预测结果,但两者结合可以更好地提高预测性能。郭丽媛[16]提出用集体矩阵分解方法将可用的链接信息从相对密集的交互网络转移到稀疏的目标网络,通过网络相似性来建立源网络和目标网络之间的对应关系。Ahmed等人[17]针对动态图中的链路预测问题,提出了一种基于非负矩阵分解的方法,该方法从动态网络的时间和拓扑结构中学习潜在特征,可以获得更高的预测结果。该方法应用新的迭代规则构造具有重要网络特征的矩阵因子,并证明了算法的收敛性和正确性。
2.4 基于最大似然的方法
基于最大似然的链路预测方法的基本思路是:根据目前已经观测到的网络中的链路计算网络的似然值,并假设真实网络的似然值最大,最后根据网络似然最大化,计算所有未连接节点间的连边概率。以网络结构为研究基础的最大似然估计方法较为适用于具有组合结构的网络类型。
2008年,Clauset等人提出一种通过网络数据推断网络层级结构的方法,证明层次结构可以用来预测网络中丢失的链接,并具有较高的精确度。刘继嘉[18]提出了一个扩展的经典随机块模型,预测了网络中的丢失链接和错误链接。田甜等人[19]提出了一种基于最大似然估计的层次随机图模型,利用脑网络数据建立层级随机图,通过改进的马尔科夫蒙特卡洛算法对树状图空间进行采样,最后计算脑网络边的平均连接概率,实验验证,该算法比传统的算法计算复杂度低。
3 衡量算法精确度
衡量链路预测算法准确度的指标最常用的有3种:AUC(Area Under ROC Curve,ROC曲线下面积)、Precision和Ranking Score。
3.1 AUC
AUC的评价方式为:每次从测试集EP中随机选取一条边,再随机从不存在的边的集合中选取一条边,对两者的评分数值Sij进行比较,若测试集中的边分数高,则记1分,若两者相等,记0.5分。假定一共比较n次,其中有n′次测试集分数高,有n″次两者分数相同,则AUC计算值为
(1)
3.2 Precision
在链路预测完成后,需要对所有的边计算的评分数值由高到低排序,而Precision计算的是排在前L位的边中,预测正确的边所占比例,即如果在预测后的排序结果中,排在前L位的边有m个与测试集中的边相同,那么Precision的计算值为
(2)
当两个链路预测方法的AUC值相同时,用Precision比较其准确性,Precision值越大,越倾向于把连边准确的节点对排在前面。
3.3 Ranking Score
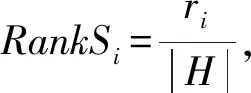
(3)
4 结束语
综上所述,无论是通过节点属性、网络拓扑,还是基于概率模型,都是通过已知的数据,尽可能贴近实际情况刻画链路的连接走向,但它们各自有优缺点。基于节点属性的预测方法通过获取用户信息来确定连接关系,但无法确定用户信息的真实性和准确性,深入挖掘又涉及用户的隐私问题,单从这一方面进行预测,准确率难以保证。通过网络拓扑来进行预测,计算复杂度比较低,只通过网络结构预测链路需要获取的数据较为简单。机器学习是最近较为热门的方向,与链路预测相结合会得到更高的预测准确率。概率模型是数据挖掘的传统模型,它同时考虑了节点属性和网络结构,能够得到较好的准确度,可是计算复杂度和用户属性的获取都是它无法大规模进行采用实施的原因。
目前,链路预测广泛应用于生物系统、社交关系、推荐好友方式、股市走向等方面,已经成为一门热门的交叉学科。如何在不侵犯用户隐私、计算复杂度低的条件下设计出快速、准确的链路预测模型,从而应用于大规模复杂网络上,是接下来要继续攻克的难题。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
机械工业标准化与质量(2022年6期)2022-08-12
移动通信(2021年5期)2021-10-25
装备制造技术(2020年2期)2020-12-14
河北画报(2020年8期)2020-10-27
空间科学学报(2020年3期)2020-07-24
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
浙江大学学报(工学版)(2016年2期)2016-06-05
中国卫生(2015年12期)2015-11-10
中国交通信息化(2014年3期)2014-06-05
