
Doc2vec在政策文本分类中的应用研究
2019-10-08 11:55李峰柯伟扬盛磊
软件 2019年8期
关键词:文本分类
李峰 柯伟扬 盛磊

摘 要: 政策文本(Policy Text)是指因政策活动而产生的记录文献,当前多数的政策文本分类方法存在特征维度高、缺乏上下文信息这两个缺点。基于此,本文采用Doc2vec算法,通过词向量化解决特征维度高的问题,采用CBOW方法获取词语上下文信息。本文采用的方法经过实验测试,结果显示该方法对提高政策文本的分类准确率有着显著作用。
关键词: 政策文本;文本分类;Doc2vec
中图分类号: F224-39 文献标识码: A DOI:10.3969/j.issn.1003-6970.2019.08.018
本文著录格式:李峰,柯伟扬,盛磊,等. Doc2vec在政策文本分类中的应用研究[J]. 软件,2019,40(8):7678
【Abstract】: Policy text refers to documentation produced by policy activities. Most current classification methods of policy text have two defects: high feature dimension and lacking context information. Based on this, the paper solves problem of high feature dimension through word vectorization with Doc2vec algorithm, and obtain word context information with CBOW method. Experimental results show that method adopted in the paper has significant effect on improving classification accuracy of policy texts.
【Key words】: Policy text; Text classification; Doc2vec
0 引言
政策文本是指因政策活动而产生的记录文献,既包括政府或国家或地区的各级权力或行政机关以文件形式颁布的法律、法规、部门规章等官方文献,也包括政策制定者或政策领导人在制定过程中形成的研究、咨询、听证或决议等公文档案。目前政策文本分类[1]主要分为两类:人工分类和机器分类。其中,人工分类费时费力,且分类准确率不高;机器分类是通过训练一个适当的规则或分类器,从而对政策文本进行预测分类。
对于文本分类,很多专家学者都进行了深入的研究。文献[2]在文档主题生成模型(LDA)的基础上提出了新的文本分类模型,利用主题模型对当前高维的文本进行降维并获取特征,同时使用SoftMax回归算法解决文本多分类的问题,有效降低新闻文本特征维度并且取得很好的分类效果;文献[3]提出了一种基于粗糙集和相关性分析的K近邻(KNN)分类算法,将训练集文本向量空间分成确定集和不确定集2个部分,确定集直接进行类别判断,不确定集通过KNN分类算法进行文字相关性分析确定类别,大大提高了文本分类的效率和准确性,且满足处理大量文本数据的要求;文献[4]提出了一种基于加权的KNN算法和蜂群算法的组合算法,利用文本向量之间的距离的倒数进行计算权重,在一定程度上提高了分类准确度;文献[5]提出了一种使用N-Gram方法进行特征扩展的短文本分类方法,针对短文本特征的稀疏性,从训练集中选取单词序列使用N-Gram进行特征扩展,再使用朴素贝叶斯(Na?ve Bayes, NB)算法进行训练,结果表明这种算法显著提高了分类性能;文献[6]介绍了一种耦合矩阵分解和逻辑回归的方法对高维数据集进行同步特征提取和二分类,从对数似然函数开始使用梯度下降法进行推导得到模型,该模型在新闻文本数据集上取得了较好的分类结果,同时在主题聚类问题上保持了精度。
1 政策文本分类基本流程
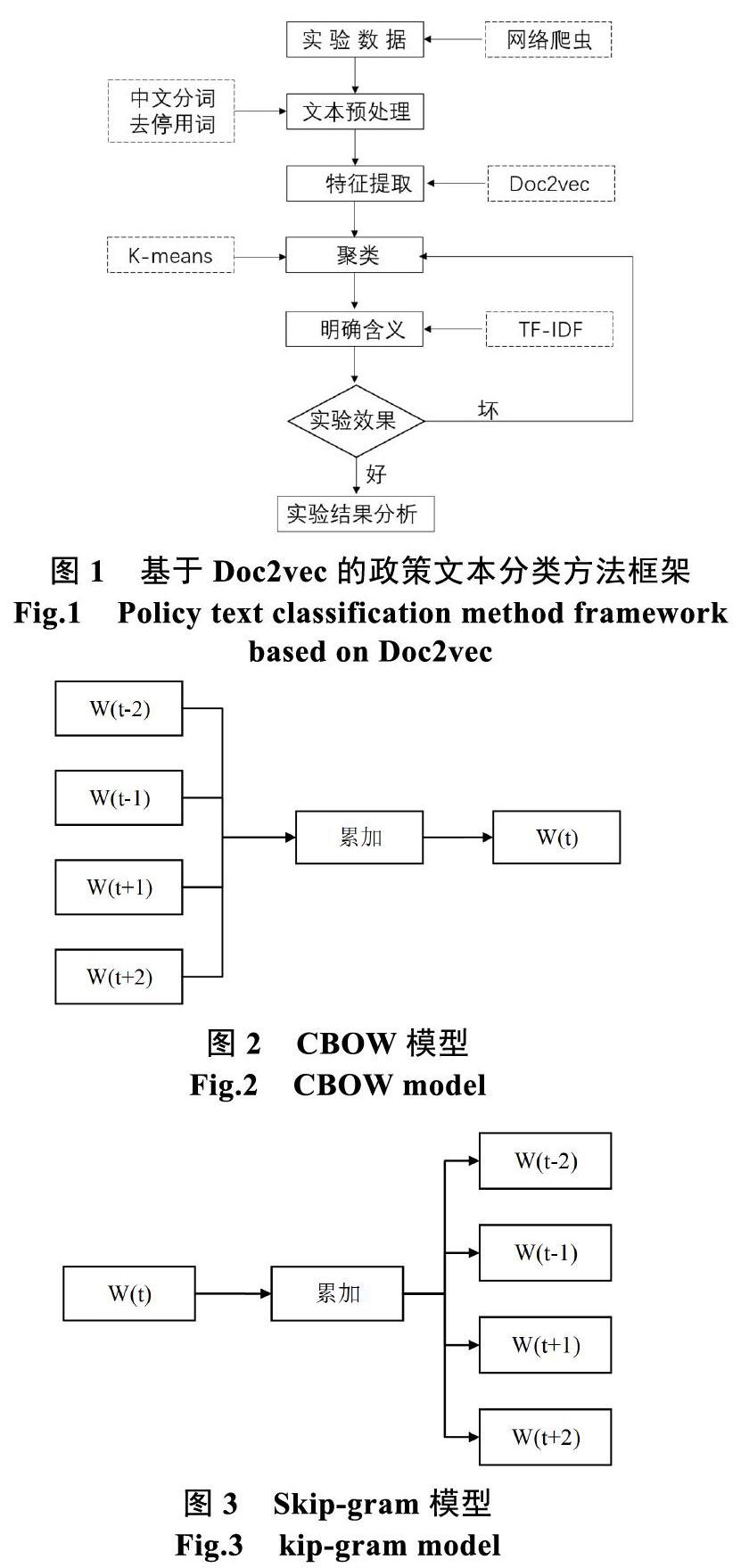
本文提出的政策文本分类方法包括以下过程:①准备好实验数据,本文通过网络爬虫获取政策信息;②文本预处理,包括中文分词和建立停用词库;③利用Doc2vec提取词向量;④采用K-means算法对政策数据进行聚类;⑤使用TF-IDF对每个类赋予实际意义。具体过程如图1所示。
1.1 文本预处理
文本预处理是文本分类中至关重要的一步,中文分词的结果以及停用词的存在都会直接影响特征提取的结果,进而影响文本分类的效果。
1.1.1 中文分词
中文分词技术是自然语言处理领域中很多关键技术的基础,包括文本分類、信息检索、信息过滤等。现如今中文分词的方法很多,大多数研究者的研究重点都是按照提升算法的精度、速度来的,常用的算法可总结如下:字典分词方法、理解分词方法和统计分词方法。
本文采用业界比较知名的Jieba中文分词对政策文本进行分词,同时,考虑到如果直接使用政策内容作为语料库,可能会引起两个类别的政策分到同一类,即存在误分类情况。为了减少这种情况,我们根据换行符等特殊标记将整个政策内容进行分段,通过段落信息构建语料库。
1.1.2 引入停用词
中文分词结果并不能直接用于特征选择,其中,某些词如果作为特征,会干扰政策文本分类最后的结果。此时,需要引入停用词去除分词结果中无用的词,例如:“的”、“吧”、“啊”等。
1.2 特征提取
文本预处理之后,如果直接使用这些数据作为特征向量,可能会引起特征向量的维度达到几万甚至几十万的维度,因此需要用特征选择方法进行处理,降低特征维度,提高分类的效率。目前,特征选择方法有TF-IDF、word2vec等,采用TF-IDF提取文本特征向量;则通过word2vec建立词向量模型,在对文本中的词向量平均化得到文本向量。针对上述两个方法无法全面理解文本语义的问题,本文采用Doc2vec方法进行实验,取得了不错的效果。
Doc2vec是一个无监督框架,学习文本段落的连续分布向量表示,文本可以是可变长度的,从句子到文档。该方法可以应用于可变长度的文本,任何句子或大型文档。通过该方法将文本进行数字化表示,每个词语使用几百维的实数向量表示,然后使用欧式公式计算两个词语的语义相似性。
Doc2vec有两种模型:CBOW(连续词袋模型)和Skip-gram。在CBOW中,它的目的是根据上下文周围的词语预测一个词语,通过训练预料,最后获得模型参数,得到词向量,如图2所示;Skip-gram正好相反,它是基于单个词语预测窗口内周围的词语,从而得到词向量,如图3所示。本文的实验采用了CBOW模型训练词向量。
1.3 聚类
特征提取完毕后,需要进行聚类,本文采用的聚类算法是Kmeans,该算法的步骤大体如下:
(1)首先选择一些类/组,并随机初始化它们各自的中心点。中心点是与每个数据点向量长度相同的位置。这需要我们提前预知类的数量(即中心点的数量),在本实验中对中心点的数据进行了多次测试。
(2)计算每个数据点到中心点的距离,数据点距离哪个中心点最近就划分到哪一类中。
(3)计算每一类中中心点作为新的中心点。
(4)重复以上步骤,直到每一类中心在每次迭代后变化不大为止。也可以多次随机初始化中心点,然后选择运行结果最好的一个。
1.4 确定类别含义
政策文本通过Kmeans聚类之后,获得了每个类中心,但无法确定该中心的具体含义。本文使用TF-IDF确定每个类的具体含义。
2 实验结果及分析
本文从北大法宝网收集到约5万条政策数据作为实验的研究样本,包括住房、人才、科技、创新等政策。同时,将所有政策数据分为两个集合,一个集合数据作为训练集,一个集合数据作为测试集。每篇政策文本包含6个部分:①政策标题;②政策发文机关;③法规类别;④发布日期;⑤效力级别;⑥政策正文。这些部分都通过Doc2vec转换成对应的词向量。
2.1 实验参数设置
在本实验中,Doc2vec中的向量维度、窗口大小以及K-means中的K值都是很重要的参数,它们直接影响到政策文本分类的结果。
在Doc2Vec中,向量维度和窗口大小直接影响段落文本向量的表示效果,窗口太小会导致目标词的上下文相关词数量过少,容易漏掉与目标词关联度高的词语;窗口过大会引入噪声词,根据实验结果,本文选取窗口大小为4。文本向量每一维的值代表一个具有一定语义的特征[7],因此高维数的向量可以提升模型的准确率,但是维度过大会引入噪声,根据实验结果,我们选取向量维度为300。K-means中的K值也是很重要的参数,本文实验最佳K值为4。
2.2 实验结果
实验将本文方法与TF-IDF、Glove进行准确率比较,实验结果如表1所示。
3 结语
本文考虑到Doc2vec能够缩短特征向量的维度,能够提取文本的上下文信息,因此采用Doc2vec应用于政策文本分类中。同时,借助TF-IDF对每个类进行标签化,实现政策文本分类的准确和高效。本文后续的研究将在现有方法的基础上,进一步深入挖掘出政策文本所蕴含特征,包括政策发文机构、政策覆盖面和政策条款分布、政策有效期等特征,更好地提高政策文本聚类的准确性,更直观的展示各区域政策特色或量化得分情况,进而支撑政府科学决策。
参考文献
[1] 刘鑫昊, 谭庆平, 曾平, 唐国斐. 几种基于MOOC的文本分类算法的比较与实现[J]. 软件, 2016, 37(09): 27-33.
[2] Li Z, Shang W, Yan M. News text classification model based on topic model[C]//2016 IEEE/ACIS 15th International Con?ference on Computer and Information Science (ICIS). New York: IEEE, 2016: 1-5.
[3] Aizhang G, Tao Y. Based on rough sets and the associated analysis of KNN text classification research[C]//2015 14th International Symposium on Distributed Computing and Applications for Business Engineering and Science (DCABES). New York: IEEE, 2015: 485-488.
[4] Yigit H. A weighting approach for KNN classifier[C]//2013 International Conference on Electronics, Computer and Computation (ICECCO). New York: IEEE, 2013: 228-231.
[5] Zhang X, Wu B. Short Text Classification based on feature extension using The N-Gram model[C]//2015 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD). New York: IEEE, 2015: 710-716.
[6] Türkmen A C, Cemgil A T. Text classification with coupled matrix factorization[C]//2016 24th Signal Processing and Communication Application Conference (SIU). New York: IEEE, 2016: 1697-1700.
[7] 賀益侗. 基于doc2vec和TF-IDF的相似文本识别[J]. 电子制作, 2018(18): 37-39.
猜你喜欢
计算机应用(2016年12期)2017-01-13
湖南大学学报·自然科学版(2016年4期)2016-08-12
中国教育信息化·基础教育(2016年2期)2016-05-31
