
一种基于Logicboost的软件缺陷预测方法
2019-10-08 11:55张洋
软件 2019年8期


摘 要: 针对软件缺陷預测中对不平衡数据分类精度较低的问题,提出了一种新的基于LogitBoost集成分类预测算法,使用SMOTE方法对原始数据集进行平衡处理,然后使用随机森林算法作为弱分类器算法进行分类预测,最后使用LogitBoost算法以加权方式集成各弱分类器的结果。通过在NASA MDP基础数据集上验证得出本文提出的分类预测算法比数据集均衡处理前准确率高出0.1%-11%,同时在均衡处理后比KNN算法平均高出0.9%,比SVM算法平均高出0.4%,比随机森林算法平均高出0.1%。
关键词: 不平衡数据;LogitBoost集成算法;随机森林算法;软件缺陷预测
中图分类号: TP206+.3 文献标识码: A DOI:10.3969/j.issn.1003-6970.2019.08.019
本文著录格式:张洋. 一种基于Logicboost的软件缺陷预测方法[J]. 软件,2019,40(8):7983
【Abstract】: Aiming at the problem of low classification accuracy of unbalanced data in software defect prediction, a new integrated classification prediction algorithm based on LogitBoost is proposed. SMOTE method is used to balance the original data set, then random forest algorithm is used as weak classifier algorithm for classification prediction. Finally, the results of weak classifiers are integrated in a weighted way using LogitBoost algorithm. Through the verification on NASA MDP basic data sets, the classification prediction algorithm proposed in this paper is 0.1%-11% higher than that before data balancing, 0.9% higher than that of KNN algorithm, 0.4% higher than that of SVM algorithm and 0.1% higher than that of random forest algorithm.
【Key words】: Unbalanced data; Logitboost integration algorithms; Random forest algorithm; Software defect prediction
0 引言
软件缺陷是指计算机软件或程序中存在的某种破坏正常运行能力而导致的问题和错误或者其他隐藏的功能缺陷。2011年“甬温线”列车因控制软件设计缺陷导致列车追尾事故造成了大量人员伤亡、2012年美国骑士资本集团的交易软件缺陷问题造成股票交易异常损失近4.4亿美元、2019年波音737MAX因软件缺陷导致多起坠机事件,大量的人员伤亡和财产损失无不在警示人们对软件质量的重视,也进一步促进了对软件缺陷预测的研究。
因为软件缺陷客观存在,而且某些隐藏较深的缺陷不容易发现,而一个软件缺陷如果在开发早期发现那么解决该问题的成本会比较小,而越往后解决缺陷问题的成本会逐渐增加,而开发完成后才发现的缺陷最严重的情况是有可能项目需要重新开发,所以研究软件缺陷问题的关键就是如何最大程度的发现软件或程序中的隐藏缺陷,而开发一款高质量的算法让其能判定软件中的大部分缺陷是解决当前问题的重中之重[1]。
1 相关研究
软件缺陷预测方法分为静态软件缺陷预测方法和动态软件缺陷预测方法[2],本文研究内容属于静态软件预测方法。目前针对静态软件预测采用的方法有神经网络[3]、支持向量机(SVM)[4]、决策树方法[5]、贝叶斯网络方法[6]、随机森林算法[7]、关联规则挖掘方法[8]、集成学习方法[9]等方法,其中神经网络方法是一种非监督分类方法依赖传统方法寻找神经网络权值,所以比较难找到全局最优解;SVM方法能较好的应对不平衡数据和数据多维的情况,但容易受到噪声样本数据的影响;其他分类算法因为数据不平衡的问题导致预测精度比较低;集成学习方法集成了多个弱分类器的方法以构成强分类器,所以较单个弱分类器分类预测性能较高,是目前比较好的一种缺陷预测方法。因为以上很多分类预测算法都受到数据集不平衡的影响,所以针对这个问题有非常多的学者进行了研究,而且在软件缺陷预测研究领域中不平衡数据集对软件缺陷预测方法的效果影响很大[10],目前针对数据集不平衡的研究有多种方法,有向上过采样补充少数样本方法[11],有向下欠采样减少多数样本方法[12],还有同时使用过采样和欠采样相结合减少多数类样本增加少数类样本的方法[13]等。本文在研究了以上多种方法后发现采用向上过采样的方法较其他两种方法能保留更多原始样本数据信息并且在软件缺陷预测方法中分类预测效果也比较好,所以本文的实验过程都是在使用SMOTE方法[11](Synthetic Minority Oversampling Technique)对数据集进行预处理的基础上进行实验,然后在此基础上使用新提出以随机森林分类算法作为基分类算法并结合LogicBoost[14]逻辑集成算法集成多个基分类算法进行分类预测的方法进行验证并与其他几类常见的分类预测算法进行了比较,同时为验证对数据集使用过采样平衡处理后算法的性能是否提高本文还对各种方法在原始不平衡数据集和平衡后数据集的分类预测结果进行比较。为更有效的评价分类结果,本文选择了准确率、AUC值、G-mean值三个业界认可的有效性能评价指标对结果进行评价,并使用NASA MDP数据集[15]完成整个实验。
2 基于LogicBoost的软件预测方法
2.1 SMOTE采樣
数据集不平衡的问题一直是分类问题最大的困扰,而对于需要预测的有缺陷的数据集总是少数,而且在某些数据集中占比非常低,为解决样本少,特征缺失的问题,Chawla等人提出了SMOTE方法,该方法通过计算少数样本k个相邻样本间的欧式距离得到最近邻的k个样本,然后生成0到1之间的随机数与随机抽取的近邻样本合并生成新样本,重复这个过程直到样本间达到平衡。其具体生成生新样本的方法如式1所示,其中Pj表示新样本,N表示生成样本数量。
2.2 LogicBoost算法
Logitboost算法是由Friedman等人提出的一种改进型Boosting算法[16],是一种集成各弱分类器结果变成强分类器的集成分类算法。LogitBoost使用加权最小二乘法估计分类函数并以加权的方式对基础分类器的结果进行评价,如果分类结果出现错误则会加大其权重,相反权重减小,通过迭代多次每次给不同的基础分类器重新计算权重,最后采用加权的方式合成各基础分类器的分类结果作为最终分类结果,具体现过程如下:
(1)给定一个测试集(xi1, xi2…xin, yi),yi={Y, N}表示有缺陷和无缺陷两类。
(2)给样本赋予权重wi=1/N, i=1…N,使得每个样本被抽到的概率一致,然后使用基础分类器,根据权重以迭代的方式建立预测模型,每一轮提升都会给错误分类的样本增加权重,正确的减小权重,其中F(x)=0, Pi=1/2。
(3)假定算法迭代M次,m=1,2,…,M
2.3 随机森林算法
随机森林是由Breiman提出的一种基于Bagging[17]算法与随机子空间算法[18]的集成算法,其基本思想是多个决策树对同一个测试数据集进行分类建立随机森林决策树,然后在分类预测过程中通过多个决策树投票的方式统计所有决策树的结果来最终判定样本的分类结果。随机森林的算法主要优点是算法的准确性比单个决策树都高,而且每棵决策树选择分类属性可以随机,同时每棵决策树选择测试数据集也可以随机,这两个随机让算法减少了算法产生过拟合的结果同时也降低了噪声样本数据的影响。算法的实现过程如下:
输入:训练样本数据集,特征集合
输出:随机森林决策树
(1)随机选择训练样本数据集。对于每棵树而言,随机且有放回地从训练集中的抽取N个训练样本作为该树的训练集。
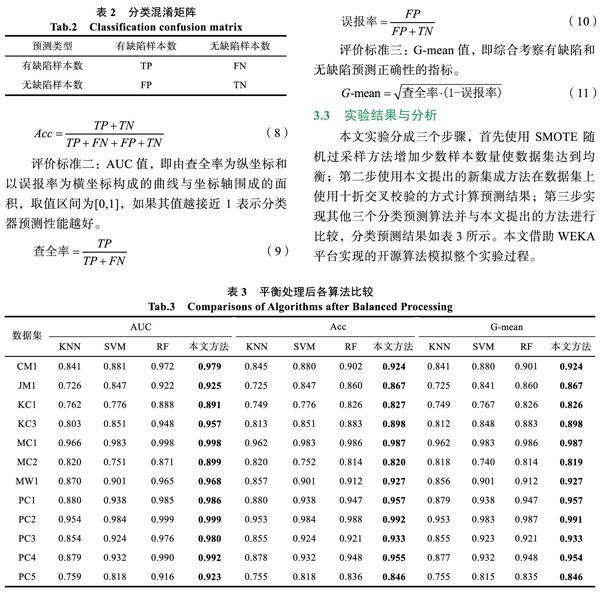
(2)随机选择训练样本的特征数。假定样本的特征维度为M,指定一个常数m< (3)每棵树都尽最大程度的生长,并且没有剪枝过程。 (4)所有生成树都停止生长后,随机森林决策树构建完成。 2.4 基于LogicBoost的软件预测算法 输入:测试数据属性集{A1,A2…An}以及样本实例数据 输出:输出分类预测结果和成功率 (1)对原数据集进行清理,清楚重复项,以消除重复项对测试结果过拟合的影响。 (2)根据SMOTE规则对数据集进行数据样本随机过采样增加少数类样本,采样比例=(无缺陷实例数/有缺陷实例数)-1,设置k=5,即通过计算样本间的欧式距离找到最邻近的5个样本,然后使用随机的方式循环地选择近邻样本乘以随机数增加少数样本使数据集均衡。 (3)构建随机森林算法的决策树模型,随机森林算法默认的基分类算法为分类回归树,设置特征选择数量随机生成,通过多次实验得到选择训练样本数量在70%的时候效果最好,同时设置生成树无限生长直到叶子只包含一个类别的样本后停止生长。 (4)建立LogitBoost计算模型,生成样本权重矩阵,并生成工作变量,建立基于最小二乘法的拟合函数估计分类函数,并在每次迭代重新计算权重和样本概率。 (5)使用随机森林算法作为LogitBoost的基础分类器,设置迭代次数为100,并使用十折交叉校验的方式把样本分成十分,每次使用其中九份作为训练数据集一份作为测试集,总共迭代十次最后经过加权统计的方式得到所有样本的分类预测结果。 (6)输出分类预测结果和成功率。 3 实验结果与分析 3.1 数据集 本文采用NASA公布的MDP软件缺陷数据集作为实验数据集,并且对原数据集进行了清理删除了原始数据集中出现的重复样本,具体如表1所示列出了样本集名称、样本总数、有缺陷样本数、无缺陷样本数以及不平衡度,其中不平衡度等于无缺陷样本和有缺陷样本的除数,可以发现数据集非常不平衡,从1.84到45.56不等。 3.2 评价标准 为有效评价各算法性能,使用分类混淆矩阵如表2表示预测完成后各项结果数据,其中TP表 示有缺陷样本被正确预测的数量,FN表示无缺陷样本预测成有缺陷样本数量,FP表示有缺陷样本预测为无缺陷样本数量,TN表示无缺陷样本正确预测 数量。 评价标准一:准确率(Acc),即有缺陷样本和无缺陷样本都预测正确在整个样本中的比例。 3.3 实验结果与分析 本文实验分成三个步骤,首先使用SMOTE随机过采样方法增加少数样本数量使数据集达到均衡;第二步使用本文提出的新集成方法在数据集上使用十折交叉校验的方式计算预测结果;第三步实现其他三个分类预测算法并与本文提出的方法进行比较,分类预测结果如表3所示。本文借助WEKA平台实现的开源算法模拟整个实验过程。 通过以上实验可以得到本文方法在三个评价标准上较其他三个分类预测方法都表现比较好,图1和图2列出了各方法在数据集未做平衡处理与平衡处理后在数据集上的准确率柱形图,可以看到各算法在数据集平衡处理前后算法性能有不同程度的提升,而本文提出的方法样本数据平衡的情况下预测性能比其他方法的准确率都高。 4 结论 本文基于LogicBoost算法和随机森林算法提出一种新的集成分类预测算法,该算法使用随机森林分类算法作为基分类算法,有效发挥了随机森林算法的高分类精度优势,同时结合LogicBoost集成算法进一步提高预测精度。选择的NASA MDP数据集是美国宇航局公布的软件缺陷数据集,该数据集收集了多个软件的度量属性和样本数据,是软件缺陷研究领域可直接进行分类预测的数据集。本文选择了其中 12个基础数据集验证提出方法的预测效果,同时采用原始数据集和使用SMOTE方法随机过采样均衡的数据集两个差异性的数据集进行对比实验,实验结果表明本文提出的方法在均衡数据集上效果比其他预测算法有较高的性能。虽然本文预测结果对比其他几类分类算法较好,但本文未考虑多特征属性对算法结果的影响,下一步将着重研究多特征属性提取后验证本文方法是否有更高的预测精度。 参考文献 [1] 孔军, 吴伟明, 谷勇浩. 基于缺陷模式匹配的静态源码分析技术研究[J]. 软件, 2016, 37(11): 146-149. [2] 郝世锦, 崔冬华. 基于缺陷分层与PSO算法的软件缺陷预测模型[J]. 软件, 2012, 33(2): 51-52. [3] JIN C, JIN S W, YE J. Artificial neural network-based metric selection for software fault-prone prediction model[J]. IET Software, 2012, 6(6): 479-487. [4] LARADJI I H, ALSHAYEB M, GHOUTI L. Software defect prediction using ensemble learning on selected features[J]. Information & Software Technology, 2015, 58: 388-402. [5] WANG J, SHEN B, CHEN Y. Compressed C4. 5 models for software defect prediction[C]//Proc of 2012 12th international conference on quality software.Washington DC: IEEE, 2012: 13-16. [6] 段明璐. 软件故障树算法建模的研究[J]. 软件, 2018, 39(2): 66-74. [7] PUSHPHAVATHI T P, Suma V, RAMASWAMY V. A novel method for software defect prediction: hybrid of FCM and random forest[C]//2014 International Conference on Electronics and Communication Systems (ICECS). Piscataway: IEEE Press, 2014: 1-5. [8] 颜乐鸣. 基于关联规则挖掘的软件缺陷分析研究[J]. 软件, 2017, 38(1): 70-76. [9] WANG T, ZHANG Z, JING X, et al.Multiple kernel ensem-ble learning for software defect prediction[J]. Automated Software Engineering, 2016, 23(4): 569-59. [10] 刘学, 张素伟. 基于二次随机森林的不平衡数据分类算法[J]. 软件, 2016, 37(7): 75-79. [11] CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2011, 16(1): 321-357. [12] SUN Z, SONG Q, ZHU X, et al. A novel ensemble method for classifying imbalanced data[J]. Pattern Recognition, 2015, 48(5): 1623-1637. [13] 戴翔, 毛宇光. 基于集成混合采樣的软件缺陷预测研究[J]. 计算机工程与科学, 2015, 37(5): 930-936. [14] FRIEDMAN J H, TREVOR H,ROBERT T. Additive logistic regression: A statistical view of boosting[J]. The Annals of Statistics, 2000, 38(2): 337-374. [15] SHIRABAD J S, MENZIES T J. The PROMISE repository of software engineering databases[OL]. (2005-03-15)[2019-04- 23]. http://promise.site.uottawa.ca/SERepository. [16] YOAV F. Boosting a weak learning algorithm by majority[J]. Information and Computation, 1995, 121(2), 256-285. [17] BREIMAN L. Bagging predictors[J]. Machine learning, 1996, 24(2): 123-4. [18] HO T K. Random subspace method for constructing decision trees[J]. IEEE Transactions onPattern Analysis & Machine Intelligence, 1998, 20(8): 832-844.
猜你喜欢
黑龙江工业学院学报(综合版)(2020年6期)2020-08-11
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
成都信息工程大学学报(2018年3期)2018-08-29
电子测试(2018年1期)2018-04-18
电子元器件与信息技术(2017年4期)2017-03-08
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
郑州大学学报(医学版)(2015年1期)2015-02-27
