
全卷积神经网络仿真与迁移学习
2019-10-08 06:43付鹏飞许斌
软件 2019年5期
付鹏飞 许斌


摘 要: 人们捕获视图,从视图中提取特征并理解含义。同理,驾驶员也通过视觉实现对街景的判断。我们期待, 有一天机器能够通过自主计算完成同样的工作。得益于计算机的强大处理能力,基于CNNs(Convolutional Neural Networks, 卷积神经网络)的深度学习算法能够很好地完成目标识别等计算机视觉任务。但在实际工业应用中,资源往往受限,较大的网络不利于嵌入式移植。通常一个完备的CNN网络包含卷积层、池化层和全连接层[1],本文参考文章[2]中的方法,舍去池化层和全连接层,使用卷积层代替,并对几种网络进行了仿真实验及结果分析,寻找在受限平台使用CNN网络的方法。
关键词: 人脸识别;直方图均衡化;主成分分析;支持向量机
中图分类号: TP391. 41 文献标识码: A DOI:10.3969/j.issn.1003-6970.2019.05.042
本文著录格式:付鹏飞,许斌,等. 全卷积神经网络仿真与迁移学习[J]. 软件,2019,40(5):216221
【Abstract】: As we know, vision is very important for human to understand the world. Similarly, drivers also use vision to anlysis street scene. What we had being expecting is that one day machine can do the same work by itself through computer vision. Thanks to the powerful processing ability of the computer, the deep learning algorithm based on CNNs (Convolutional Neural Networks) can accomplish computer vision tasks well such as object detection. However, in most industrial environment, resources are limited, and larger networks are not easy to embedded transplantation .Now, the architectures of main CNNs used for machine vision include convolution layers and pooling layers alternately and ended with several fully-connected layers [1]. In fact, we can use convolution layers to replace pooling layers, as described in paper [2]。
【Key words】: CNN; Computer vision; Transfer lEARNING; Driving assistance
0 引言
隨着现代社会的不断发展,汽车已成为了人们最主要的交通工具,传统的驾驶行为在处理很多突发情况时,完全依赖于驾驶人员在面对突发情况时的心理素质及驾驶经验,非常容易出现危险的情形。而且长时间远距离的驾驶,会造成驾驶员疲劳,注意力不集中,从而导致交通事故频发。主流的汽车制造商已普遍采取了被动安全的策略,来降低事故对行人的伤害。
但是这种被动的保护措施还远远不够,如果能通过技术手段,主动的辅助驾驶员采取措施,减少甚至避免人员的伤亡,这将会是一项非常具有价值和意义的工作。汽车要能够辅助人类驾驶,首先就要求汽车能够感知到外部的环境,理解环境的构成类型并准确定位。目前主要使用雷达和光学摄像头等传感设备作为传感器,通过算法来实现对外部环境的感知。目前的基于CNN的神经网络,具有较大的参数量,训练过程中要消耗大量的时间,而且在实际的移植的过程时对移植系统的资源要求高,制约了CNN网络向较小的平台或或资源受限的平台扩展。
汽车上很多智能部件以工控机、嵌入式环境为主,属于资源受限平台。尽管具有多层和复杂结构的CNN网络具有很好的检测精度,但是在这样庞大的网络在有限资源的平台上往往效果不佳。论文[2]提出了以全卷积网络的模型,简化经典的CNN网络模型,也能够达到较高的准确率。本文使用论文[2]过实际修改、编写、仿真分析A、B、C三种网络结构,研究CNN网络简化的可能方法,研究大型的神经网络向受限平台迁移的可能性。
1 相关工作
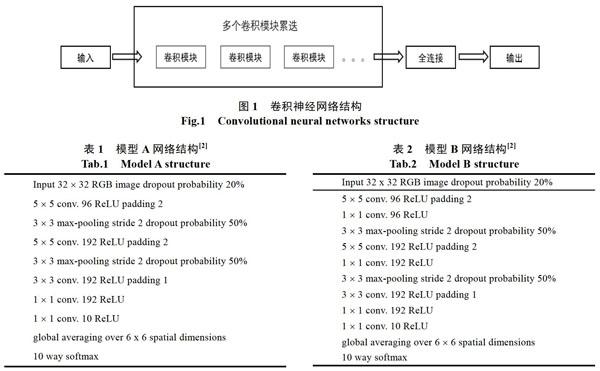
卷积神经网络可以简化认为是多个卷积模块的不断循环运算并输出特征图[1]的过程,通常来说卷积模块包含卷积运算、整流、池化三个部分。通过卷积运算把结果传导至下一层,并且多次重复这样的操作,如图1所示。在整个计算过程中,图片的大小逐步减少,卷积核的个数不断增多,输出尺寸较小而通道较多(较深)的特征向量图,最后通过Softmax函数输出数以确定目标属于某一个物体分类的概率值。目前CNN有四个主流的模型AlexNet[3]、VGGNet[4]、GoogleNet[5]、ResNet[6]模型。尽管不同结构的神经网络,在卷积核大小的选取,卷积核的组合方式,以及向前传播的连接方法会有不同。但总体来看其主要的结构还是如图1所示,通过卷积模块数量的堆叠而把网络推向更深,通过更深的网络学习出特征图。更深网络意味着具有更多的参数,需要占用更多的资源,越不利于向受限平台的移植。
参考文献[2]中提出了一种基于全卷积网络结构的方法,去掉了池化层、全连接层,相比VGGNet,GoogleNet,ResNet采用了较少的深度,以实现模型的精简。这种思路非常有利于在受限平台下的嵌入式移植,有利于在特定工作环境下的高效运行。参考文献[2]方法包含表1-6中所示的A,B,C,Model Stride-CNN-C,ConvPool-CNN-C network,All-CNN-C一共6种模型。本论文通过python编程实现了参考论文中所描述的方法,在数据集CIFAR-10上训练它们,并在数据集CIFAR-10上进行测试,完成图像分类。随后尝试了基于CIFAR-10数据集训练的全卷积网络模型的迁移学习,把学习到的模型应用于CIFAR-100数据集的小子集class1和class2,分析结果,以尝试在受限平台下基于CNN算法的轻量化、专门化研究。
2 实验操作
仿真所使用的系统环境Intel Xeon E5-2665@ 2.4 GHz x 32 CPU,64 GB内存,256 GB SSD,1个Nvidiz TITAN Xp GPU独立显卡和Ubuntu 16.04 64 bit操作系统。使用pyton3.6.6版本安装了Anaconda 3-5.2,pip 10.0.1,pytorch 0.4.1.post2,CUDA 9.0.176系统。在上述环境中完成了以下工作:
1)参考论文中提到的方法,通过python编写的实现代码[7-8],包含A,B,C,Stride-CNN-C,ConvPool-CNN-C network,All-CNN-C一共6种模型
2)在CIFAR-10数据集上训练模型A
3)在CIFAR-10数据集上训练模型B
4)在CIFAR-10数据集上训练模型C
5)在CIFAR-10数据集上训练模型Strided- CNN-C
6)在CIFAR-10数据集上训练模ConvPool- CNN-C
7)在CIFAR-10数据集上训练模型All-CNN-C
8)在CIFAR-10数据集上训练模型All-CNN-C
9)在CIFAR-10数据集上训练模型All-CNN-C
10)在CIFAR-10子数据集1上使用迁移学习训练All-CNN-C,固定前面层的参数只训练全连接层参数
11)在CIFAR-10子数据集2上使用迁移学习训练All-CNN-C,固定前面层的参数只训练全连接层参数
12)在CIFAR-10子数据集1上使用迁移学习训练All-CNN-C,训练全部层参数
13)在CIFAR-10子数据集2上使用迁移学习训练All-CNN-C,训练全部层参数
3 模型结构
模型A是一个包含8个中间层的结构(除去输入层和输出层),采用了5*5和3*3的卷积核,采用了3*3的最大值池化操作,采用了边界填充方法,通道数由输入的RGB的3通道,加深至96,192通道,最后减少至10通道输出,A模型的特点是层数较少,保留了最大池化层,移除了全连接层用全局池化来代替。模型B和模型A较为类似,比模型A多了两层1*1卷积运算,达到了10个中间层,保留了最大池化层,移除了全连接层用全局池化来代替。模型C和模型B较为类似,层数和结构一致,只是卷积核大小的选择,以及填充的数量上有变化。模型Strided-CNN-C在模型C的基础上移除了最大池化层,微调了滑动步长,保持10个中间层。 模型ConvPool-CNN-C在模型C的基础上增加了两个3*3的卷积层,整个模型变得更深达到了12个中间层。模型 All-CNN-C是在模型C的基础上去除了最大池化层,微调了滑动步长,保持有10个中间层。模型 All-CNN-C形式很简洁,没有池化层和全连接层,整个模型是一个全卷积网络构架。6个模型全部采用了dropout的正则化方法,减少过拟合。
两个迁移学习的模型是使用的All-CNN-C的模型(全连接层训练feature extractor和全部参数训练fine tuning)。所有的模型都是使用的线性整流激活函数(ReLU),用于文献[2]中提到的在每一卷积层之后进行非线性计算。Kaiming法向函数用于初始化每一个卷积层的参数。Dropout技术用于对模型的正则化,对输入图片用20% dropping 概率,在池化层后面或者被卷积所替代的池化层后面采用50%的dropping概率。2个1*1卷积层用于代替常用的全连接层,最后一个卷积层直接用全局平局池化(global average pooling)输出至每一个softmax函数用于分类。
文中的6个模型相比VGGNet[4]、GoogleNet[5]、ResNet[6]幾个主流模型,其特点在于层数较少,卷积核大小相对固定,也没有复杂的跳层连接,舍去了池化层和全连接层。整体结构相对简洁,是一个由全卷积网络构成的结构。其中有一个新颖点是在最开始的输入层也采用20%dropout正则化方法,减少过拟合。这样的模型结构利于理解,训练时间也较端,单个模型在几个小时之内就可以训练完成。
4 超参数设置及权重初始化
本文训练模型时是采用的是随机梯度下降(SGD)的方法优化模型,设置了0.9的动量,每一个batch的大小是32个样本图片,损失函数使用的是Softmax函数。模型A、B、C、Strided-CNN-C、ConvPool-CNN-C、All-CNN-C的权重衰减率为0.001,初始学习率为0.001,一共迭代350轮,分别在[200, 250, 300]轮时以0.1的比率减小学习率。数据集CIFAR-10包含50000张训练样本图片,10000张测试样本图片,共计60000张图片,10种分类,每种分类包含6000张图片,图片为32*32的彩色图片。本文在使用数据集CIFAR-10训练模型时,将50000个训练样本拆分成了两部分,其中49000张样本图片用于训练, 余下的1000张样本图片用于验证,10000张测试样本图片用于测试。数据集CIFAR-100也包含50000张训练样本图片和10000张测试样本图片,但该数据集有100种分类,每种分类包含600张图片,图片也是32*32的彩色图片,在本实验中使用CIFAR-100数据集主要是为了进行迁移学习训练,选用了其中的2个子数据集,分别为class1和class2,每个子数据集中包含5000张训练样本图片和1000张测试样本图片,且每个子数据集只包含10种分类。本实验将5000个训练样本分成了两部分,其中4900个样本用于训练, 余下的100个样本用于验证,1000个测试样本还是用于测试。更多的细节可以参看表7。
驗证是在训练过程中进行的,如果在验证时发现预测准确率不高,则需要调整初始学习率、权重衰减率等参数,比如在验证时发现准确率提高得很慢,可以尝试减小或增大初始学习率,学习率较大时,会导致在优化权重及偏重等参数时,参数的改变较大,这样就可能会出现跃过全局或局部最优点,从而比较难于收敛;如果学习率较小时,会导致在优化权重及偏重等参数时,参数的改变较小,这样可能会出现训练得比较慢,需要较长时间才会收敛到较好的全局最优点或局部最优点。另外在加载数据集时,也需要对数据利用训练集数据的均值和方差进行正则化处理,以使数据尽量围绕中心分布,避免出现狭长的山谷状分布,如果出现这种山谷状分布,以某个设定的学习率训练模型时,会导致在窄的方向上很容易跃过全局或局部最优点,而在狭长的方向上却要很久才能达到全局或局部最优点,从而使整个训练过程收敛得很慢,甚至很难达到预期效果。测试是在整个训练都完成后才进行的,用于检验模型训练的效果。
在CIFAR-100数据集的数据集1和数据集2子集上实现和训练了两种迁移学习模型。每个子集有5000个训练样本和1000个测试样本。训练样本被分成两部分,一部分是前4900个样本用于训练,另一部分是剩下的100个样本用于验证。两种转移学习模型都是基于All-CNN-C模型,并且使用训练完成的All-CNN-C模型的参数,来帮助在新的数据集上训练。第一个使用已经训练好的All-CNN-C模型作为特征提取器。它冻结了前8个卷积层,并在CIFAR-100数据集的两个子集上重新训练了最后一个卷积层。第二个使用已经训练好的模型All-CNN- C作为fine tuning。它使用已经训练好的参数作为初始参数,使用CIFAR-100数据集子集进行新的训练并重新计算出全部的参数。由于数据集CIFAR-100的子集class1和class2也具有与CIFAR-10相同的10个类,这意味着两个转移学习模型可以与全CNN-C共享相同的网络结构,并且不再需要修改最后的卷积层。
5 实验分析
从表8可以看出,精简之后的全卷积网络(前面6个模型),依然达到了较高的检测精度,从CIFAR-100数据集的检测结果显示完全不比一些复杂的结构差太多。至2014年由VGG开始提出的观点,CNN网络越深对检测结果越有利,在避免梯度消失的情况下,整个深度学习的研究方向是朝着更深网络结构前进。诚然随着网络加深,检测的结果也随之提升,但是庞大网络需要耗费大量的计算资源,训练时间和检测速度回会变慢,这对于嵌入式的移植往往是不利的。采用论文[2]的方法,发现一些精简的模型也能带来不错的效果,为嵌入式移植提供了另外一种思路。虽然笔者实际仿真后的结论和论文[2]中的结论有一些微小的差距,其检测精度比参考论文中的结论稍微低一点,但总体很接近,详情可以参看表8。有可能笔者还需要在超参数选择、初始权重设置等方面需要多做尝试和优化。 All-CNN-C基于CIFAR-100子数据1和子数据集2的检测结果优于论文[2]中的结果。考虑到CIFAR-100中子数据集1和子数据集2相比论文中的全部CIFAR-100数据要小得多,所以不太适合直接进行比较。
All-CNN-C模型在数据集CIFAR-100的子数据集1和子数据集2上进行迁移学习训练时,使用了在数据集CIFAR-10上训练好的All-CNN-C模型参数来初始化新的All-CNN-C模型,然后用这个初始化好的新All-CNN-C模型分别训练了两个迁移学习模型,第一个是特征提取器(feature extractor),即固定住除最后一个分类层外的其它卷积层,只用新数据集训练最后的分类层,第二个是使用新数据集调校(fine tuning)所有层的参数,实验结果表面,第二个调校模型的准确率明显优于第一个特征提取模型。可见对于特有应用环境下,使用当前环境特有的数据采用fine tuning类型的迁移学习的方法进行训练,能够更好的提升当前特定环境下检测的准确性。这十分有利于通用模型向专有工业领域应用扩展,在通用模型基础上使用 fine tuning迁移学习,以实现通用模型向某一领域的更好的扩展,提升某一个特定环境下检测的准确率。
6 结论
虽然全卷积网络结构非常简单,但是从实验结果来看依然表现得不错,在CIFAR-100数据集上达到了很好的精度。池化和全连接也许并不是CNN网络中最必须的结构。由此看来CNN未来的发展的趋势有可能在保证精度的情况下模型变得更加简单,以便于在不同环境下的应用。通过迁移学习的方法能够避免从零开始训练模型,共享一些权重参数,也能够训练特定环境下的数据以提升在这个环境下的检测的准确性。在受限平台如单片机、工控机,不通网络环境或者紧急情况需要依赖本地资源计算的场景,非常适用精简模型。更精简、更具有针对性样本资料训练,也许能够带领CNN网络进入更广阔的工程应用领域。
参考文献
[1] Murphy J. An Overview of Convolutional Neural Network Architectures for Deep Learning [J]. 2016.
[2] Springenberg J T, Dosovitskiy A, Brox T, et al. Striving for simplicity: The all convolutional net [J]. arXiv preprint arXiv:1412.6806, 2014.
[3] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classi-fication with deep convolutional neural networks[C]//Adv-ances in neural information processing systems. 2012: 1097- 1105.
[4] Simonyan K, Zisserman A. Very deep convolutional net-works for large-scale image recognition [J]. ArXiv preprint arXiv: 1409.1556, 2014.
[5] Szegedy C, Liu W, Jia Y, et al. Going deeper with convo-lutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 1-9.
[6] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[7] https://pytorch.org/docs/stable/
[8] https://github.com/pytorch/vision/blob/master/torchvision/datasets/cifar.py
猜你喜欢
作文中学版(2022年1期)2022-04-14
学生天地(2020年31期)2020-06-01
大学教育(2016年11期)2016-11-16
中小企业管理与科技·上旬刊(2016年10期)2016-11-15
考试周刊(2016年84期)2016-11-11
科学与财富(2016年28期)2016-10-14
计算机工程(2015年8期)2015-07-03
电子设计工程(2014年8期)2014-02-27
