
大数据环境下智慧图书馆智能推荐系统设计及其在高职教育中的应用研究
2019-10-08 05:35盛铨
新世纪图书馆 2019年8期
盛铨


摘 要 在探讨如何创建大数据环境下的智慧图书馆,感知学生阅读与学习需求,使之成为高职教育重要的组成部分的基础上,论文设计了一种能够用以收集、分析、处理和可视化呈现多种来源数据的大数据系统,以及专门适用于高职院校的智慧图书馆智能推荐系统。该系统能够较好地满足高职学生需求,为其搜寻和推荐个性化的内容资源,促进数据驱动决策理念在图书馆服务与高职教育中的应用。
关键词 高职院校图书馆 高职教育 大数据 推荐系统 智慧图书馆
分类号 G258
DOI 10.16810/j.cnki.1672-514X.2019.08.010
Abstract This paper explores how to create a smart library in a big data environment, and make the smart library an important part of higher vocational education by sensing the reading and learning needs of students. Then it designs a big data system that can collect, analyze, process, and visualize data from multiple sources, as well as an intelligent recommendation system for smart library that is specifically designed for higher vocational colleges. The research results show that the intelligent recommendation system can better meet the needs of higher vocational students, search and recommend personalized content resources for them, and promote the application of data-driven decision-making concepts in library services and higher vocational education.
Keywords Higher vocational college library. Higher vocational education. Big data. Recommendation system. Smart library.
0 引言
智慧圖书馆所倡导的智慧化理念始于2008年11月IBM总裁兼首席执行官Samuel J. Palmisano提出的“智慧地球”概念[1]。“智慧地球”旨在将依托数字化与网络化的智能技术应用于所有物品,以便对这些物品进行感知、度量、互联和深入分析,为社会提供高度智能化的服务,最终推动社会经济走向新的发展历程。而智慧图书馆则将物联网、云计算技术及其设备引入到图书馆,以建设能够进行智慧化管理、个性化智能推荐、实现知识有效共享与精准感知读者需求的图书馆。其中,智慧化推送是智慧图书馆的核心功能之一,主要目标在于通过对读者需求、收益及其满意度的感知与预测,为读者提供高精准度、智慧化的资源与服务。国内有些高职院校也积极进行了智慧图书馆建设,在运用信息采集、处理与分析数据等技术方面提升了服务能力,但在感知学生阅读与学习需求方面还有待进一步深入研究,使大数据技术在处理海量信息、多样类型、高价值、快速处理方面成为高职院校建设智慧图书馆的重要保障,以便能够为读者提供高质量的智能推荐服务。
综观国内研究,目前对智慧图书馆及其智慧服务的研究以理论研究为主,而较少以特定的实践需求对智能推荐服务进行具体系统设计与实证研究。因此本文拟在大数据环境下以高职院校智慧图书馆智能推荐服务及其在高职教育中的具体应用作为研究问题,探讨如何整合高职院校图书馆内外的多个来源大数据,构建大数据环境下智慧图书馆智能推荐系统模型,根据学生兴趣推荐图书馆资源,以实现智慧图书馆智能推荐服务与高职教育的结合。
1 大数据环境下智慧图书馆与智能服务研究
近年来,学术界针对智慧图书馆与智能服务进行了大量研究。陈卫静将大数据环境下智慧图书馆的智慧分析归为三种类型,分别是基于用户行为数据、科研数据与业务数据的智慧分析[2]。祝森生认为,大数据时代智慧图书馆着重应当解决的问题是如何有效满足用户与社会发展需求,确保其互联、高效与便利[3]。陈臣从读者的智慧阅读需求出发,探讨了图书馆智慧服务体系的构建及其各服务层的功能,认为该体系能够较好地根据读者需求开展智慧化定制服务及个性化智慧阅读服务[4]。马晓亭提出了基于大数据的图书馆个性化智慧服务质量保证策略,用以解决图书馆在开展个性化智慧服务过程中存在的问题[5]。李欣改进了强关联规则算法,并将其应用到图书借阅和查询数据分析之中,以提高智慧图书馆个性化推送服务的效率[6]。陈臣以大数据时代用户行为数据分析为基础,提出了图书馆个性化智慧服务模式[7]。柳益君提出了基于大数据挖掘和Hadoop平台的图书馆智慧服务模型,并探讨了该模型在知识推荐服务与微知识自动问答服务中的应用[8]。洪亮等构建了大数据驱动的图书馆智慧信息服务体系及其发展策略[9]。宋维维等通过对Spark和HadoopMapReduce两种大数据处理技术进行比较,提出了基于Spark大数据处理技术的图书馆智慧服务框架、服务流程及其应用实践[10]。
2 大数据环境下高职院校智慧图书馆与智能服务目标
在大数据环境下,高职院校智慧图书馆智能推荐服务所要达到的目标在于精准识别和满足学生兴趣需求的同时,能够提高图书馆的资源使用率和服务效率,实现图书馆与高职教育的结合。这也是本文所要研究的目的。
智慧图书馆的主要目的是通过集成各个数据源的数据信息,构建精确和有效的推荐系统,为读者提供个性化推荐服务。数据来源包括高职院校信息门户系统、高职院校教学管理平台、社交媒体网络、个人图书馆和图书馆物联网等主要模块,如图1中所示。在推荐系统中,各类数据源之间的交互以全新的方式进行呈现,且不同数据源在整合之后的可访问性与互操作性也将得到极大提升。
4.2 智慧图书馆数据集
智慧图书馆连接、组合以下来源的数据:教学管理平台上学生学习周期内选定的课程及其在线课程开放平台论坛中的交流信息;学生在教务信息管理系统中选课偏好及其相关的教材与教辅图书信息;从社交媒体网络收集的学生相关信息(绑定智慧图书馆相关平台的学生社交媒体账号);高职院校图书馆OPAC系统服务器日志文件,包含读者属性特征及借阅信息,以及读者的图书查询、荐购等日志信息;从图书馆物联网传感器收集的图书位置及在馆和使用信息;读者通过“我的图书馆”链接到第三方电子图书数据库(如超星电子书等)的电子书搜索、阅读及下载日志信息。
通过连接上述各类数据源,即可得到相应的数据集。我们选取某高职院校的教学活动作为研究数据,数据集包含120个课程、5个学习课程和约1750名学生信息。根据其所选修的课程和可借阅的图书,每个学生在当前学年从图书馆数据库中下载的电子图书大约为3~10种图书,总计共有1000万多条记录。图书馆数据集包含80 571个用户和2955册图书。图书荐购系统包含约3900个图书荐购信息文件、450个用户和1495条有效的数据记录。该校要求每个学生都通过教学管理平台进行选课活动,以了解学生在本学年所选择的课程,每年度的课程数量介于10到12门课程之间。
4.3 智能推荐系统流程
对各种来源的数据集,我们将通过大数据处理系统进行加载、集成到HCatalog中,进行收集、处理和分析,以及对最终内容进行实现和可视化呈现,即基于读者的兴趣为其提供个性化的内容推荐。用户每次访问教务信息系统平台时,Hadoop系统都将分析以下内容:(1)用户所使用(查询、借阅和下载等) 的图书属性信息;(2)教学管理平台中本学年选课数据信息;(3)OPAC系统中读者的图书借阅、荐购历史和读者个人属性等信息;(4)对多个数据的操作日志信息。
系统在对现有数据进行处理后,将根据读者的兴趣需求,为其提供以下建议:一是在高职院校图书馆中已入藏相关图书的情况下,系统会根据图书的ID在读者指定的借阅期限内为其预约该图书;二是将读者感兴趣的图书信息发送给图书馆的采编部门和图书荐购系统。具体流程示意见图2 。
我们在实施中所选的开源软件平台是Apache HadoopHortonworks。Apache Hadoop是一种被广泛采用的,也是最成熟的大数据软件平台之一,支持分布式数据密集型应用程序和MapReduce计算范例,允许并行处理大量异构数据。MapReduce和Hadoop被认为是最有效的大数据管理框架[11]。
在系统中,数据存储在提供可扩展和容错存储的HDFS中,HDFS检测并补偿集群错误,将传入的文件拆分为块,并将它们冗余地存储在集群上。文件被分块(每块的大小为64MB或128MB)复制在多个节点上,因而具有较大的容错性,若其中一个节点丢失,并不会破坏文件以及对数据读取性能产生影响。此系统模型中的HDFS通过持续监视集群中的节点及其管理的塊,用以确保数据的可用性。各个块都受到检查和控制,在以块进行读取后,确定正确性(记录值是否正确)。MapReduce提供了并行计算功能和在集群中可共享的大型数据集,使得主节点能够将任务分配给子节点,再收集计算结果。
5 智慧图书馆智能推荐系统模型的实现
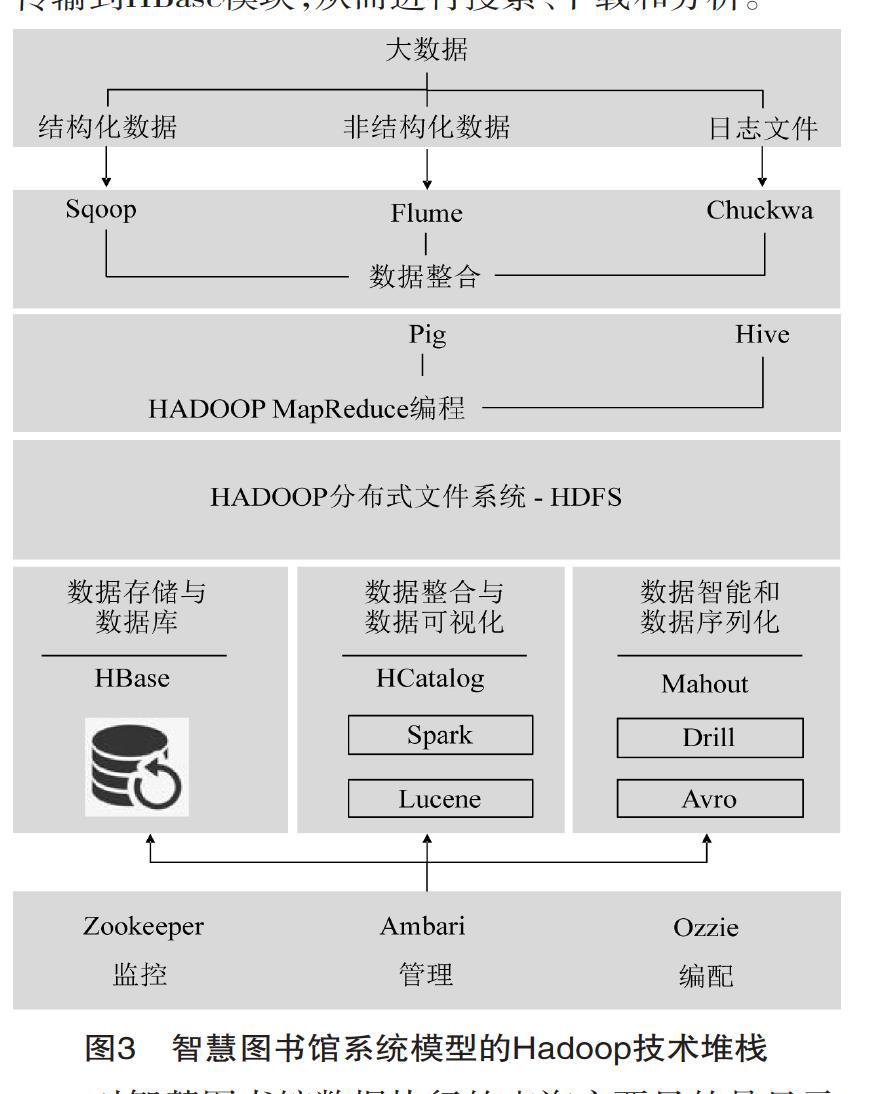
图3显示了创建大数据智慧图书馆所需的重要模块及其Hadoop技术堆栈。系统中的MapReduce编程由Hive模块执行,该模块允许在大型数据集上执行查询命令,并提供数据结构投影机制。该层的突出特征是能够借助于并行化的结构,管理系统中的大数据集,将现有的数据集已加载到HCatalog中,以便在系统管理层上展开进一步处理,再将数据分发和传输到HBase模块,从而进行搜索、下载和分析。
对智慧图书馆数据执行的查询主要目的是显示在给定时间段内借阅特定图书的读者,并准备数据集以供进一步处理,其程序如下:
SELECT debit.person_id,book.title.
COUNT(debit.person_id) OVER (PARTITION BY debit.person_id ORDER BY debit.person_id ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
FROM debit JOIN book ON(debit.book_id 1/4 book.row)
WHERE debit.taking_date>“2017-01-01”AND debit.return_date<“2017-06-14”
执行程序主要根据以下6个步骤搜索和选择最合适的项目:
步骤1:执行查询结果显示书名和在指定日期范围内借阅次数最多的读者ID;
步骤2:Ambari模块执行系统中的监控和管理模块,该模块可以安装、管理和监控集群中的Hadoop服务。该集成模块的主要任务是协调分布式应用程序、同步和集中集群中的服务,并协调和监控相互独立的Hadoop作业流程;
步骤3:系统内外部来源(高职院校及其图书馆、高职院校OPAC系统和教务信息管理平台)读者ID链接到电子邮件帐户;
步骤4:读者在我的图书馆中,可以通过使用他们的个人帐号下载电子书,每位读者当前学年下载的电子书大致介于3到10册之间;
步骤5:每当读者对我的图书馆及图书荐购系统进行任何新的访问时,系统都会分析该读者的查询、借阅、下载和荐购历史,以及读者的个人属性和个性化偏好,生成推荐列表和感兴趣的内容。系统会根据这些信息,对相关图书与之进行相似性排序与比对,再形成基于相似性的图书推荐列表;
步骤6:在读者新登录教学管理平台时,大数据推荐系统将对多个来源的数据进行处理以生成推荐信息,其算法基于不同数据来源的单独系统中所有项目计算相似性,以确定哪些项目最适合读者,计算项目之间相似性的代码如下:
HCatalog 1/4 union(ProductCatalog1, ProductCatalog2, ProductCatalog3, ProductCatalog4 [...])。
其中,ProductCatalog1是实体馆的图书数据;
ProductCatalog2是学校教学管理平台数据;ProductCatalog3是在线荐购系统的数据;ProductCatalog4是“我的图书馆”服务器的日志数据。所选取的数据项目有:图书馆借阅数据项目、电子图书下载数据项目、图书荐购系统的荐购信息、读者的个人偏好及行为信息。根据现有数据,系统将列出大数据处理系统为根据读者ID为其推荐的3册图书,读者可以进行以下选择:在高职院校图书馆中保留推荐的图书,或者由图书馆采编部门从合作书商直接购买推荐的图书。
6 智慧图书馆智能推荐系统评估
评估所选取的样本是2016—2017学年冬季学期某专业大二的220名学生。
系统的评估首先通过系统大数据进行分析,确定Hadoop系统中最受欢迎的图书,以便发现这些图书的借阅频次是否比去年同期有所增加。大数据分析用于确定以下内容:评估系统最常向用户推荐哪些书籍;2016年和2017年从高职院校图书馆借阅推荐图书的次数分别是多少。分析的目的是评估基于Hadoop的推荐系统是否有助于改善提升图书馆服务水平的潛力,以及增加读者对系统的使用和信任。其次通过在线调查问卷来评估已实施的原型系统,以确定基于多数据来源的Hadoop推荐是否比高职院校在线荐购系统更适合读者。所设计的问卷被整合到学校的教务信息系统中,以确定基于Hadoop的多数据源推荐是否更适合读者(基于他们的印象)。问卷包括十个问题,每个问题均有多个选择或真伪答案,其中两个重要问题以五点李克特量表进行设问。
大数据分析结果显示,在原型系统测试期间,从基于Hadoop的系统上被推荐得最多的图书列表中借阅的图书总量增加了269.5%。
问卷调查结果显示,在参与在线调查问卷的学生中,有40%的学生未曾借阅、下载或荐购任何图书。在没有图书使用信息情况下,系统无法确定读者的偏好,因此无法创建用户模型进行图书推荐,因而这些学生在最终的研究对象中被剔除。其他学生选择从图书馆数字图书馆下载电子书,在图书荐购系统中荐购相关图书,或从高职院校图书馆借阅推荐的图书,符合调查评估的要求。我们通过问卷调查发现,有24.6%的学生认为基于Hadoop的多数据源推荐完全足够,平均得分为3.38,标准差为1.25,而有21.1%的学生认为图书馆传统的图书推荐服务完全足够,平均成绩为3.17,标准差为1.28。显然学生们认为大数据系统的推荐略微优于图书馆以往的图书推荐服务。
参考文献:
张之沧,闾国年.“智慧地球”概念解析[J].自然辩证法研究,2015(11):117-122.
陈卫静.智慧图书馆在大数据环境下的智慧分析[J].图书情报工作,2015(2):49-52.
祝森生.大数据时代关于智慧图书馆的几个研究问题探讨[J].图书与情报,2013(5):126-128.
陈臣.基于大数据挖掘与知识发现的智慧图书馆构建[J].现代情报,2017,37(8):85-91.
马晓亭.大数据时代图书馆个性化智慧服务QOS保障研究[J].现代情报,2014,34(12):69-73.
李欣.强关联规则挖掘在智慧图书馆个性化推送服务中的应用研究[J].情报科学,2018,36(4):95-99.
陈臣.大数据时代一种基于用户行为分析的图书馆个性化智慧服务模式[J].图书馆理论与实践,2015(2):96-99.
柳益君,何胜,熊太纯,等.大数据挖掘视角下的图书馆智慧服务:模型、技术和服务[J].现代情报,2017,37(11):81-86.
洪亮,周莉娜,陈珑绮.大数据驱动的图书馆智慧信息服务体系构建研究[J].图书与情报, 2018(2): 8-15.
宋维维,夏绍模,李赞.基于SPARK大数据处理平台的图书馆智慧服务探索与实践[J].情报科学,2018,36(6):45-49.
KHAN S, LIU X, SHAKIL K A, et al. A survey on scholarly data: from big data perspective[J].Information Processing & Management,2017,53(4):923-944.
猜你喜欢
计算机应用(2016年12期)2017-01-13
电脑知识与技术(2016年28期)2016-12-21
价值工程(2016年32期)2016-12-20
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年25期)2016-11-16
数字技术与应用(2016年9期)2016-11-09
知音励志·社科版(2016年8期)2016-11-05
科教导刊·电子版(2016年21期)2016-08-23
企业导报(2016年8期)2016-05-31
科技视界(2016年10期)2016-04-26
