
改进K-means算法在高校舆情中的应用
2019-10-11 11:24徐建国韩琮师
软件导刊 2019年7期
徐建国 韩琮师

摘 要:互联网时代,网络焦点话题讨论对当代高校学生的思想有很大影响,因此对高校舆情进行监测具有十分重要的意义。通过改进的K-means算法对高校舆情进行聚类,获取舆情热点。通过聚类算法获取热点话题,进而对热点舆情话题进行引导,对改进高校学生思想政治工作作用显著。对改进算法进行实验,结果表明该算法准确率达到75%,比传统算法高出8%,改善了传统算法的聚类效果。
关键词:高校舆情;聚类;K-means算法
DOI:10. 11907/rjdk. 191734 開放科学(资源服务)标识码(OSID):
中图分类号:TP319文献标识码:A 文章编号:1672-7800(2019)007-0142-03
Application of Improved K-means Algorithm in University Public Opinion
XU Jian-guo, HAN Cong-shi
( College of Computer Science and Engineering,Shandong University of Science and Technology,Qingdao 266590,China)
Abstract: In the Internet age, the discussion of network focus topics has a great influence on the thinking of contemporary college students. Therefore, it is of great significance to monitor public opinion in colleges and universities. Through the improved K-means algorithm, the college public opinion clusters, the hotspots and the hot topics of the current colleges and universities are obtained through the clustering algorithm, which can guide the hot topic of the hot topics and play an important role in the development of college students' thoughts. Experiments on the improved algorithm show that the accuracy of the algorithm reaches 75%, which is 8% higher than the traditional algorithm, which improves the clustering effect of the traditional algorithm.
Key Words: university public opinion; clustering; K-means algorithm
基金项目:国家重点研发计划项目(2017YFC0804406)
作者简介:徐建国(1964-),男,山东科技大学计算机科学与工程学院副教授、硕士生导师,研究方向为智能信息处理、网络舆情分析、商务智能;韩琮师(1993-),女,山东科技大学计算机科学与工程学院硕士研究生,研究方向为大数据分析、图书情报与数字图书馆、智能信息处理。
0 引言
提高大学生思想水平,正确引导培养其价值观,是我国教育界的重要任务。随着科技进步,网络成为信息传播的主要渠道[1]。据统计,网络传播了90%以上的虚假诈骗信息、消极负面信息等,思想尚未完全成熟的高校学生极易受到网络信息冲击,从而产生消极思想,可能做出危害社会的行为。
K-means算法应用广泛,文献[2]提出将K-means算法用在网络舆情分析中;文献[3]将K-means算法应用在微博热点话题分析中,对实时微博话题进行聚类分析;文献[4]将K-means算法用于大学生消费水平统计,获取大学生消费水平层次;文献[5]通过K-means算法对航空旅客出行目的进行聚类分析,从而有效地推送产品。K-means算法的不足主要表现在选取聚类中心时决策的随机性,这种随机性使得聚类结果浮动性较大。此外在更新聚类中心时,通过样本点的均值求取新的聚类中心容易受孤立点影响。本文借鉴此算法在其它领域的应用情况,提出改进算法并将其应用在高校舆情分析中。
1 改进算法
1.1 K-means聚类算法
K-means算法是基于划分的聚类算法[6-9],其基本思想是对给定的数据集随机选取K个初始聚类中心,将其余数据进行相似性度量,将相似性度量大的数据样本划分到同一类中;然后在每个类中重新计算聚类中心,循环迭代,直到满足终止条件。在K-means算法中,初始聚类中心的选择直接影响聚类结果,而随机选取初始聚类中心具有随机性[10-13],聚类效果差且很不稳定。因此,本文对聚类中心选择进行改进。
对于一个给定的样本集[D={Xi,Xi?Xn}],将其划分为K个簇[C={C1,C2?Ck}],簇内的聚类中心点分别为[ci(i=1,2,?k)],方式如下:
首先,通过式(1)计算样本间的距离。
[dist(Xi,Xj)=(Xi-Xj)T(Xi-Xj)] (1)
其中[Xi]为样本点。
然后,随机选取一个样本点作为初始聚类中心[c1]。如果样本点[Xi]满足式(2),则将样本点[Xi]作为初始聚类中心[c2],如果样本点[Xj≠ck(k=1,2,3?)]且和前面所选取的聚类中心点也满足式(2),则将其作为下一个聚类中心。重复进行直到找到第k个聚类中心[ck]。
[θ=σni≠jndist(Xi,Xj)] (2)
其中[σ]为调节聚类中心间距离参数。通过相似性原则将每个样本点归类,通过下式更新每一个类的聚类中心[ck]。
[c'k=1nkXi∈CkXi] (3)
[ck={Xi|minXi∈Ckdist(Xi,c'k)}] (4)
其中,[nk]为第K个聚类中心所包含的样本个数,[ck]为第K个聚类中心。
通过对初始聚类中心调整,减小了随机选取聚类中心的影响,增大了各类之间的距离,提高了聚类准确性;在更新聚类中心时,本文通过选取类中的样本点作为新的聚类中心,降低了孤立点[14-18]带来的影响。
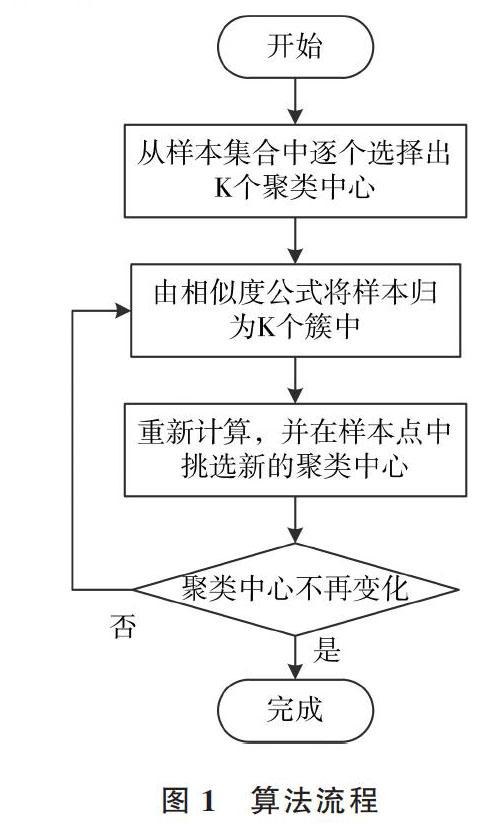
1.2 改进算法流程
改进的算法流程如图1所示。
图1 算法流程
输入:样本集合[D={Xi,Xi...Xn}],聚类数目K。
输出:聚类后形成的簇[C={C1,C2…Ck}]。
算法流程如下:①输入样本集合D,聚类数目K;②选择初始聚类中心c1,计算各样本间的距离[dist(Xi,Xj)],并根据公式(2)挑选出全部聚类中心;③根据公式(1)计算各样本[Xi(i=1,2,?,N)]到各聚类中心[ck(k=1,2?k)]的相似性,并将样本归入K个类中;④根据公式(3)、公式(4)更新聚类中心。如果聚类中心不变,输出聚类后的簇C,否则返回步骤③。
2 实验与分析
2.1 数据处理与试验指标
本文通过对比实验验证改进算法的有效性。在数据获取上,首先构建一个抓取文本的API工具[19-21],通过此工具对贴吧、微博和论坛等高校学生喜欢浏览并参与的网站进行数据抓取,并通过ICTCLAS分词系统[22-23]对爬取到的数据进行过滤,得到最终所需数据集。
使用传统TDT[24-26]评价标准作为实验评价指标,评价指标分别为:准确率acr,指正确分类的样本数量所占比重;召回率rec,指特定话题样本集在所有相关信息中所占比重;漏报率mir,指未获取的样本集在所有相关样本集中所占比重;误报率fpr,指错误判断的话题信息集在其应该存在的集合中所占比重。公式分别如下:
[acr=A/(A+B)] (5)
[rec=A/(A+C)] (6)
[mir=C/(A+C)] (7)
[fpr=B/(B+D)] (8)
其中,A為分类正确的样本数目,B为错误归类的样本数目,C为未检索到的样本数量,D为不相关样本数量。
2.2 实验结果对比
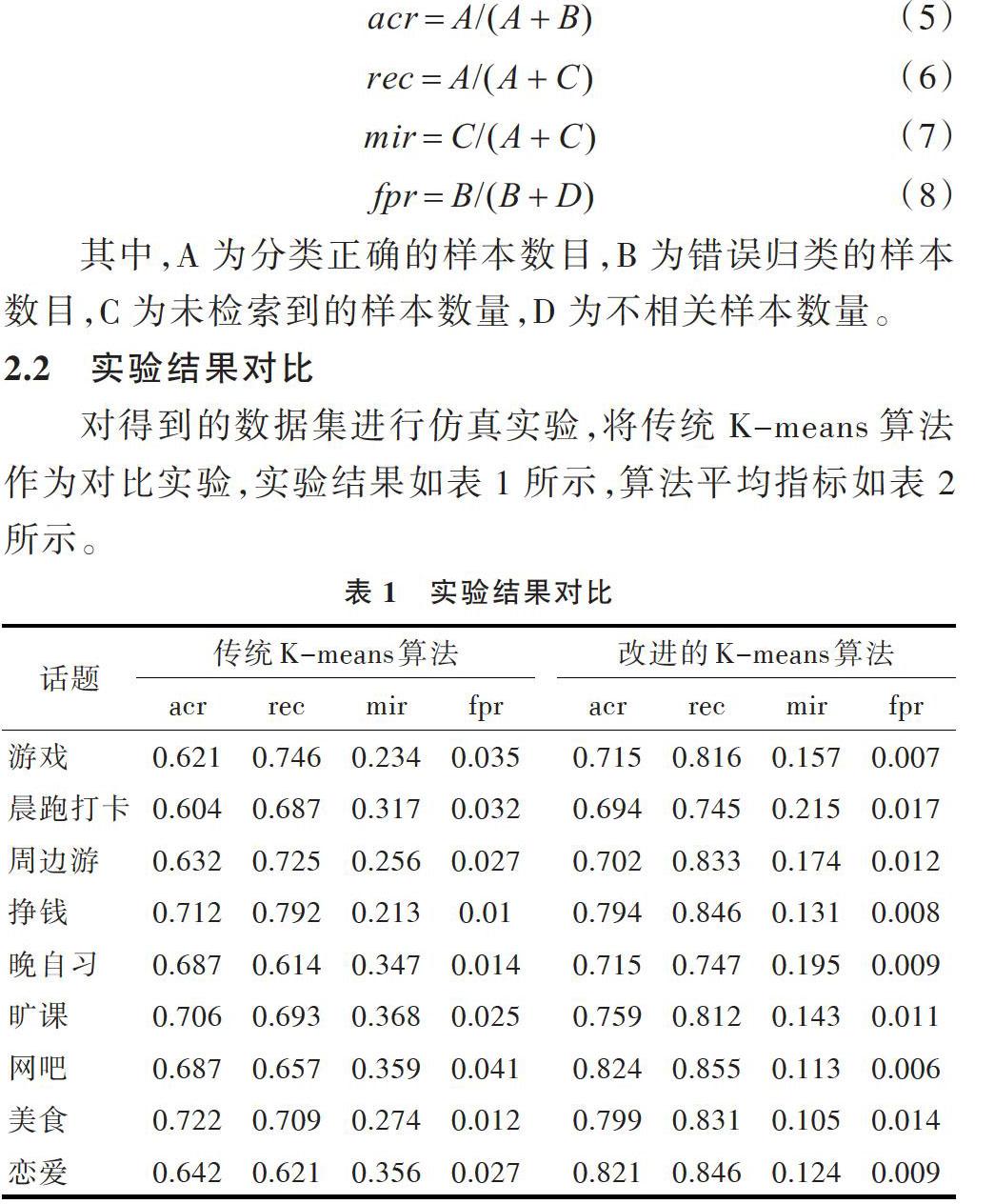
对得到的数据集进行仿真实验,将传统K-means算法作为对比实验,实验结果如表1所示,算法平均指标如表2所示。
表1 实验结果对比
从实验结果可以看出,传统的K-means算法平均准确率为0.671 375,通过改进算法进行聚类得到的准确率为0.750 25,提高了8%。在召回率rec上,本文提出的改进算法比传统算法高出10%,体现了本文算法的聚类准确性。在漏报率mir及误报率fpr上,本文算法均低于传统的K-means聚类算法。
表2 实验结果的平均指标值
通过进一步实验分析,得出高校学生所关注的焦点主要集中在游戏、晨跑打卡、周边游、挣钱、晚自习、旷课、网吧、美食、恋爱等项目中。除了对晚自习进行讨论外,对学习关心很少,需要对学生的学习态度进行引导;此外在恋爱涉及的话题中,很多高校学生对恋爱不知所措,也需要对其进行积极引导。
在高校舆情处理中,本文所提算法提高了聚类准确性。通过改进算法对高校舆情进行分析,能更准确地获取高校舆情热点,进而对学生的思想态度进行引导。
3 结语
本文对传统的K-means算法进行改进,通过阈值逐步选取初始聚类中心,避免了随机挑选聚类中心带来的弊端。在聚类中心更新上,通过样本间距离指标选取样本点作为新的聚类中心,有效降低了孤立点对样本聚类的影响。实验表明,改进算法在性能上得到提升,在很大程度上提高了聚类准确性。通过改进算法对高校舆情进行聚类分析,可有效获取高校学生所关注的话题焦点,从而对其思想状态进行积极引导。
参考文献:
[1] 章永来,周耀鉴. 聚类算法综述[J]. 计算机应用,2019(5):1-14.
[2] 徐建国,韩青君,李青. K-means聚类算法及其在网络舆情中的应用[J]. 软件导刊,2018,17(11):65-67.
[3] 刘荣凯,孙忠林. PCA-KDKM算法及其在微博舆情中的应用[J]. 山东科技大学学报:自然科学版,2018,37(6):84-92.
[4] 马幸飞,李引. 基于改进的K-means算法在高校学生消费数据中的应用[J]. 无锡商业职业技术学院学报,2016,16(6):82-85.
[5] 龚婷,普慧洁,张嘉伟,等. 基于K-means的航空旅客聚类研究[J]. 价值工程,2018,37(35):52-54.
[6] 东方. 改进的聚类算法在电子商务中的应用[D]. 南昌:南昌大学,2019.
[7] 邓林培. 经典聚类算法研究综述[J]. 科技传播,2019,11(5):108-110.
[8] 李鹏浩,朱立敬,石秀君. 基于K-means算法微博热点话题预测分析[J]. 数字通信世界,2019(3):84-122.
[9] 冯彩英,刘玉. K-means初始聚类中心优化研究[J]. 计算机产品与流通,2019(2):152-153.
[10] 徐建国,蔺珍,张鹏,等. 网络舆情热点获取与分析算法研究[J]. 软件导刊,2019,18(1):1-5.
[11] 马廷博,刘太安,徐建国,等. 基于改进的K-means聚类算法的汽车市场竞争情报分析[J]. 山东科技大学学报:自然科学版,2019,38(1):74-84.
[12] 刘叶,吴晟,周海河,等. 基于K-means聚类算法优化方法的研究[J]. 信息技术,2019,43(1):66-70.
[13] 杨丹,朱世玲,卞正宇. 基于改进的K-means算法在文本挖掘中的应用[J]. 计算机技术与发展,2019,29(4):68-71.
[14] 陈艳红,向军,刘嵩. 高校网络舆情分析的K-means算法优化研究[J]. 湖北民族学院学报:自然科学版,2018,36(4):442-447.
[15] 杨莉云,颜远海. 基于孤立点自适应的K-means算法[J]. 河南科学,2019,37(4):507-513.
[16] 贺艳芳,梁书田. 优化加权多視角K-means聚类算法[J]. 计算机技术与发展,2019,29(3):81-84.
[17] 黄灵,王云锋,陈光武. 基于密度标准差优化初始聚类中心的K-means改进算法[J]. 电脑知识与技术,2019,15(6):147-151.
[18] 王辉,赵玮,祁薇. 基于用户特征的K-means聚类算法应用与改进研究[J]. 电脑知识与技术,2018,14(35):17-19.
[19] 杜佳颖,段隆振,段文影,等. 基于Spark的改进K-means算法的并行实现[J]. 计算机应用研究:2018(7):1-5.
[20] 徐思,孙仁诚. 结合聚类的半监督分类方法[J]. 青岛大学学报:自然科学版,2018,31(4):49-53.
[21] 杨涛. 中文信息处理中的自动分词方法研究[J]. 现代交际,2019(7):93-95.
[22] 刘燕. 基于抽样和最大最小距离法的并行K-means聚类算法[J]. 智能计算机与应用,2018,8(6):37-39,43.
[23] 唐海波,林煜明,李优. 一种基于K-Means的平衡约束聚类算法[J]. 华东师范大学学报:自然科学版,2018(5):164-171.
[24] 刘荣凯,孙忠林. 针对K-means初始聚类中心优化的PCA-TDKM算法[J]. 软件导刊,2018,17(9):85-87,91.
[25] 许强. 基于Spark的话题检测与跟踪技术研究[D]. 成都:电子科技大学,2018.
[26] 张尚韬. 网络舆情话题检测技术研究[J]. 广东石油化工学院学报,2017,27(3):41-45.
(责任编辑:杜能钢)
猜你喜欢
电子测试(2017年15期)2017-12-18
哈尔滨理工大学学报(2016年4期)2016-11-10
光学精密工程(2016年5期)2016-11-07
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
电子设计工程(2015年6期)2015-02-27
现代电子技术(2014年8期)2014-09-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
