
基于大数据挖掘、分析、聚合的用户个性化推荐算法的研究
——以“今日头条”为例
2019-10-18 11:44张俊生安徽财经大学管理科学与工程学院安徽蚌埠233030
新生代 2019年6期
张俊生 安徽财经大学管理科学与工程学院 安徽蚌埠 233030
一、前言
随着互联网的大众化,人们同时享受着网络资源的极大便利,也受到了“信息碎片化”和“信息超载”的诸多困扰,尽管基于【关键词】的搜索引擎,大体上可以满足用户的需求,但很难满足用户的个性化需求,因此,基于数据挖掘、分析和聚合的个性化推荐系统应运而生,它也成为解决“信息过载”难题的主流方式。自然而然,作为智能媒体时代下的个性化新闻推送的“今日头条”客户端,面对其庞大的用户群,无时无刻不产生着巨大的数据量,这些数据量则依靠着其强大的推荐系统支撑,利用其算法的优越性,进行个性化新闻的推送。本文将通过系统概览、算法实现原理等探讨“今日头条”的个性化推荐算法的基本运作逻辑,并反思其局限,提出相应的优化措施。
二、系统概览
若用一个非感性思维的方式去理解推荐系统,则可以通过拟合一个用户对内容满意度的函数Q=F(X,Y,Z),这个函数需要输入三个维度的变量。第一个维度则是内容,众所周知,“今日头条”现在已经成长为一个综合性内容的平台,文章、图片、视频、UGC小视频、问答、微头条,每一种内容都有各自的很多特征,这就需要系统考虑如何提取不同内容特征做好推荐。第二个维度是用户的特征,每位用户都有其特殊的标签,职业、年龄、性别、爱好等等,不仅如此,还有许多通过模型刻画出的隐式用户兴趣等。第三个维度是环境特征。这也是目前移动互联网时代推荐的特点,用户不可能只处于一种环境下,在工作、吃饭、旅游,游戏等不同的场所,用户的信息偏好也会改动。根据这三个维度的变量,模型会给出一个预估,推测系统所推荐的内容是否适合当前场景的当前用户。在推荐模型中,点击量、阅读时长、点赞、转发、评论等不同的用户行为都是可以定量的行为,并且能够用模型直接拟合做推估。然而,大体量的推荐系统服务于大量的用户,这不能仅靠几项量化的指标来评估,用户的某些反常行为如刷评论、大量转发等可能会“迷惑”后台计算机的分析,因此,仅依赖这些样本统计量进行推荐是错误的,因此,“今日头条”采用了数据指标以外的要素来辅助衡量。例如有的文章很“热”,但是热点已过,不会因为文章的点击率大而继续推送给用户;还有一些关于国内外形势与政策的,如果其有所改变,文章内容不符合未来方向的也不会再次被推荐。
三、主要算法实现
(一)层次化文本推荐算法
在推荐系统中,文本分析的一个很重要的作用就是用户兴趣建模(userprofile),没有内容及文本标签是无法获取用户的兴趣标签。例如,只有知道文章的标签是明星,用户看了明星标签的文章,才能知道用户有明星的标签,其他【关键词】亦是如此。“今日头条”的个性化推荐系统的线上分类采用了非常典型的层次化文本推荐算法,其主要算法模型如下图所示:

最上面根分类器(ROOT),下面第一层的元分类器就像体育、科技、娱乐、财经等这样的大类;然后再进行元分类器细分,例如将体育细分羽毛球、足球、乒乓球等体育项目,足球还可以细分为国际足球和中国足球,依此类推下去,相比于一般的分类器,层次化文本推荐算法能更好的解决数据倾斜的问题。
(二)基于内存的协同过滤算法
1992年,Goldberg、Nicos、Oki和Terry首次明确提出了协作过滤的概念。协同过滤的算法是一种典型的聚类智能算法,其可以描述为:假设以前拥有同类兴趣标签的用户将来也会有同类的兴趣标签,基于假设,其则不需要考虑网络数据资源,只要从该系统中选取与目标用户具备相同特征的用户或项目信息,即可通过分析计算获得推荐依据。其基本工作原理是:根据系统中用户的历史活动,即其在之前浏览的文章,看过视频,回答的问题等记录,无论是点赞、评论还是转发都可以作为其活动记录和偏好信息。然后分析目标用户和其他用户之间的相似性,并为活动用户选择近邻集。最终,分析近邻用户对候选推荐文章媒体的反馈信息,预测目标用户对候选推荐项目的得分,确定推荐的用户。算法分为三个步骤:
1.收集用户信息
搜集能够代表用户兴趣的信息集合,进而构建用户-项目的二维评分矩阵。
2.相似度计算
协同过滤算法的基本步骤是相似度计算,通过计算,可以得到用户的兴趣偏好或两个用户之间的相似度,这里有两种常用的相似性计算方法。
方法一 余弦相似度

夹角余弦相似度将每个使用者评分数据作为一个n维矢量,两个矢量夹角的余弦值表示用户之间的相似程度,夹角余弦值越小,相似性越高,兴趣偏好也越相似。
方法二 修正的余弦相似度
皮尔森相关系数 (Pearson Correlation Coefficient PCC)是余弦相似度在维度缺失情况下的一种更改,在其共有的评分项目上进行相似度计算,皮尔森相关系数公式如下:
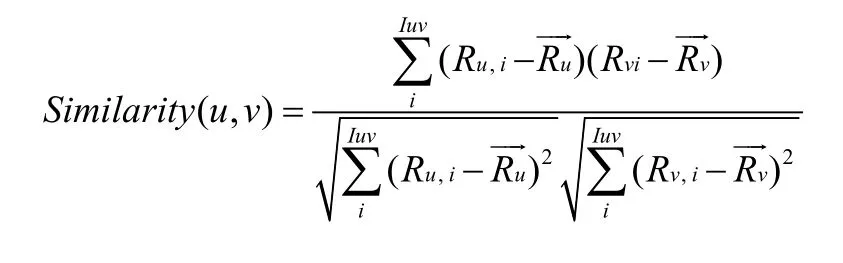
其中, Iuv表示用户u和用户v共有的评分项目, Rui和Rvi分别表示用户Iuv
3.生成推荐列表
有两种方法可以生成最近的邻居集。一种是设置相似性阈值,类似的用户只有在高于阈值时才会确定,另一个是指定目标用户的最近邻居数。
(三)冷启动问题
关于这个问题主要考虑两钟情况:
1. 在推荐系统中,对于新用户,没有用户的阅读记录,很难计算相关性。因此,很难找到近邻集,进而系统很难个性化推荐。
2.在推荐系统中,当向系统添加新的媒体资源时,该媒体资源并不会有相应的评分记录,无法找得到最近邻居并进行推荐或评分推测。
推荐系统使用协同过滤存在的问题被称为冷启动问题,“今日头条”的推荐系统使用了数据相通和用户模型建立的方法去解决这个问题。比如通过关联的社交账号获取其基本信息如性别、年龄、所在地、职业等基础标签,进而获取用户的最的基本画像。
四、主要弊端和优化建议
个性化推荐带来“智媒时代”的同时,但由于其过于依赖算法,极致的了解用户而带来了一定的不足,其主要为片面的强调个性化推荐所带来的弊病。
(一)碎片化阅读严重和新闻阅读深度不够
“今日头条”新闻客户端拥有广泛的新闻媒体资源来源,其中包含着大量的“头条号”创作者,所以个性化推荐系统捕获的新闻量非常大,可以不断向用户推荐。但是,在这个“快餐文化”的时代,人们很难拥有大量的耐心和细心精细化阅读,因此算法迎合用户,大量推荐碎片化新闻,导致用户阅读的深度不够,了解往往都是片面的,很难系统化了解一间事情,而那些真正做到由深度的新闻文章由于初期用户相关度较低,推荐系统往往不再进行推送或者推送很少,导致优秀文章的没有充分发挥其所在价值。
(二)易造成“信息茧房”现象
通过推荐系统个性化推荐算法量化用户行为,正如我们所想象的那样,客户端成为了“一份私人化定制的个人报纸”于是,这很容易导致美国学者尼古拉斯•内格罗蓬特预言的“我的日报”(the daily me)的局面。在“今日头条”用户的“个人日报”中,将以算法为导向的用户体验放在首位,算法不断推荐符合用户兴趣的内容,然而其所了解的世界是他希望看到的,却不是这个世界本来的样子,逐渐导致用户接受信息越来越窄,最后用户不得不受困于“信息茧房”中,对其他领域渐渐变得无知。
(三)优化建议
个性化推荐其实就是信息的把关传递从“人工”转换为“机器”,但机器对信息的判断不具备理性和感性认知,一些虚假和不利于社会的内容往往会顺利进入新闻生产之中,而且一些营销号所创作的“三无”文章往往也会影响使用体验。因此“今日头条”信息平台在传递信息的过程中要主动将自己独立的立场和价值观摄入其中。不能够完全交由机器和算法去实现,首先要组织一批具有新闻专业素养的人工编辑严格把关信息流动,对不合格内容定期整理和清除,提高内容多样性,减少不良内容对健康媒体生态环境的侵蚀;其次,通过树立专业领域“大V”的意见领袖地位,搭建一个客观权威的信息渠道,保证公众能获取公正、真实的信息。此外,内容平台在根据用户兴趣标签精准发放信息的同时,应注重丰富公共领域内容,通过向用户提供不在其标签内的信息,使其接触到不同领域的内容、了解多维观点,跳脱出禁锢思维。通过这种方式使得用户从封闭的“信息茧房”中走出,主动规避自我受限的现象,成为机器与技术的主宰。
猜你喜欢
小康(2022年20期)2022-07-20
中华诗词(2020年3期)2020-09-21
海峡姐妹(2018年3期)2018-05-09
投资者报(2016年45期)2016-11-23
新闻世界(2016年6期)2016-06-20
计算机应用文摘·触控(2016年8期)2016-04-25
齐鲁周刊(2016年9期)2016-03-12
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
