
目标边界点集的层次化描述及其形状检索应用*
2019-10-24 05:50刘锋,王斌,2
软件学报 2019年9期
刘 锋,王 斌,2
1(南京财经大学 信息工程学院,江苏 南京 210023)
2(江苏省电子商务重点实验室(南京财经大学),江苏 南京 210023)
通讯作者:王斌,E-mail:wangbin@njue.edu.cn
近些年来,随着数字信息技术的快速发展、图像数据库规模不断扩大,为有效管理和利用海量的图像数据,基于内容的图像检索(CBIR)[1]技术在计算机视觉领域得到了广泛的研究与应用.通过计算机软件对图像的特征进行自动识别和提取,以用于图像的检索和分类[2].由于形状是大多数物体固有的视觉属性,是人类视觉系统对物体进行识别和分类的重要依据,因此,形状分析成为CBIR 研究领域十分活跃的分支,并且已经在文本分析、神经科学、农业、生物医药、工程技术等领域产生了大量的应用[3,4].
在图像处理中,对于从场景中分割出来的目标形状,我们可以将其表示为分布在目标区域的所有像素点的集合,如果可以将其简化成一条仅由边界像素点构成的曲线,而且形状信息能够完全保持(该闭合曲线所围成的区域即为目标区域),我们称该类形状为轮廓线形状.如果形状存在不联通的目标区域,或区域是联通的,但目标区域内有孔洞,使其具有复杂的内部结构,则该类形状为区域形状.我们在图1 中给出了形状分类框图以及两类形状的示例图像和对应的边界图,以便于观察这两类形状的特点,其中,轮廓线形状和区域形状的示例分别取自MPEG-7 CE-1 轮廓线形状图像库和MPEG-7 CE-2 区域形状图像库.
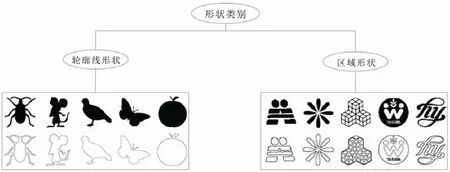
Fig.1 Classification of shapes and its example images and edge maps图1 形状的分类及其示例图像和边界图
形状描述是形状分析的核心步骤,旨在提取目标形状的有效特征,以用于后续目标形状的匹配、检索和分类等形状分析任务[4].现有的形状描述方法可分为基于曲线的描述方法和基于点集的描述方法两大类.
基于曲线的描述方法根据目标边界像素点的邻接关系进行轮廓跟踪,从而得到一条轮廓线曲线,即轮廓的有序点集.这类方法近些年得到广泛和深入的研究,研究成果[5-23]如傅里叶描述子[13,14]和曲率尺度空间[15,16],二者是经典的轮廓线形状描述子,后者被MPEG-7 推荐为标准的轮廓线形状描述子,其在MPEG-7 CE-1 形状测试集上获得了75.44%的检索准确率[15].又如多尺度凹凸性[5]、内部距离[6]、三角形面积[7]、轮廓柔韧性[8]、形状树[17]、分段多项式描述子[18]、局部仿射不变描述子[19]以及一些其他轮廓线描述子[9-12,20-23].该类方法可借助曲线分析的数学工具,如傅里叶变换、小波变换、微分几何等,产生许多具有强辨识力的形状描述子,还可以利用深度学习的方法对特征进行有效的选取[24,25].而在形状匹配阶段,可以借助像素点的有序信息进行轮廓线的精确匹配,如采用动态规划的匹配方法,又如利用距离度量学习的方法进行形状相似度的度量[26].该类方法形式优美,性能优越,虽然这些方法在MPEG-7 CE-1 轮廓线形状测试集上报告的检索精确率大都超过了85%,但这些方法是专门为轮廓线形状设计的,需要把目标形状的轮廓表示为一条曲线才能进行特征抽取,因而只能处理图1中的轮廓线形状.但对于图1 中的区域形状,由于其轮廓不能用一条曲线来进行表示,该类方法则无能为力.综上,我们可以看出基于曲线的描述方法因对目标形状轮廓的提取质量有着严重的依赖性,不能处理具有复杂内部结构的区域形状,因此具有很大的局限性,不能用于一般的形状识别任务.
基于点集的方法是另一类形状描述方法,该类方法将目标形状区域的像素点看成一般的点集,抽取点集的几何特性,产生形状描述子.该类方法又可进一步地分为基于区域点集的描述方法和基于边界点集的描述方法:前者在抽取形状的特征时,考虑目标形状区域的所有像素点,即将所有的目标像素点看成一个点集;而后者则仅考虑目标形状的边界像素点,将边界像素点构成一个点集来进行特征抽取.我们在图2 中给出了形状描述方法的分类框图.由基于点集的形状描述机制可知,基于区域点集的描述方法和基于边界点集的描述方法都能够描述轮廓线形状和区域形状.

Fig.2 Classification of shape decription methods图2 形状描述方法的分类
人类的视觉系统对目标的边界信息非常敏感.从图1 中形状的边界图可以看出,无论是轮廓线形状还是区域形状,在移去目标区域内的所有像素点,仅保留边界像素点的情况下,人的视觉系统仍然能对目标形状进行准确辨识.因此,目标形状的边界像素点为我们抽取具有强辨识力的形状特征提供了重要的线索.相较于基于曲线的描述方法,基于边界点集的描述方法克服了前者仅能处理轮廓线形状的局限性,能够一般地处理两类目标形状,且由于不需要对边界点进行序化操作,从而避免了因序化操作所带来的不稳定性.而相较于基于区域点集的描述方法,基于边界点集的描述方法由于仅需处理边界像素点,因此降低了点集的基数,从而具有非常高的计算效率;且其直接从边界提取特征,使得描述子更具辨识能力.因此,本文着眼于基于边界点集的形状描述方法.其主要贡献在于:提出了一种目标边界的分层描述模型,通过对目标边界从多个方向的分层度量,多尺度地抽取了目标形状几何特征,无论是在标准的MPEG-7 CE-2 区域形状测试集上,还是在MPEG-7 CE-1 轮廓线形状测试集上,该方法都以较低的计算成本,取得了比同类方法(基于点集的描述方法)更高的形状检索精确率.
1 相关工作
本文提出的是一种新的基于边界点集的形状描述方法,所以,与本文联系最紧密的工作是近年来一些基于点集的形状描述方法.本节中,我们对一些常见的基于点集的方法按基于区域点集和基于边界点集的分类展开综述.
常用的基于区域点集的形状描述方法有几何不变矩[27]、Zernike 矩(Zernike moments,简称ZM)[28]、伪Zernike 矩[29]等各种基于矩的形状描述方法和通用傅里叶描述子(generic Fourier descriptor,简称GFD)[30]等基于傅里叶变换的形状描述方法.在众多基于矩的形状描述方法中,Zernike 矩[28]是一种经典的基于区域点集的形状描述方法.它将图像投影到一组定义在单位圆上的基于Zernike 多项式的正交化函数,矩的大小用以生成对图像进行描述的特征向量.Zernike 矩能够很容易地构造图像的任意高阶矩,并能够使用较少的矩来重建图像.虽然其计算比较复杂,但是Zernike 矩在图像旋转和噪声敏感度方面具有较大的优越性.由于Zernike 矩具有图像旋转不变性和较低的噪声敏感度,且可以构造任意高阶矩,所以被广泛地应用于模式识别等领域中,MPEG-7 标准中已将Zernike 矩列为一种标准的区域描述符[31].基于Zernike 矩,文献[32]提出一种Zernike 矩边缘梯度方法(Zernike moments &edge gradient,简称ZMEG)用于商标图像检索,这种方法将Zernike 矩作为目标形状的全局特征,提取形状的边缘梯度共生矩阵作为局部特征,结合全局特征和局部特征对形状进行描述.文献[30]提出一种通用傅里叶描述子,该方法首先对图像进行预处理,将原始图像变换为极坐标图像,再对其进行二维傅里叶变换,用其变换系数的模作为描述子.该方法满足对目标形状的旋转、缩放和平移的不变性,适合于一般的形状图像检索应用.近年来,Yang 等人[33]提出一种自适应分层质心的算法,这种方法递归地对形状区域进行分割,通过若干次分割,将形状区域分割成越来越小的区块,每一次递归,计算当前的形状区块的质心,根据得到的质心,将当前区块分割成4 个更小的区块,将每次递归产生的区块质心坐标构成的集合,作为描述形状的特征向量.基于这种对图像递归地进行分块的技术,Sidiropoulos 等人[34]提出了一种自适应分层密度直方图(adaptive hierarchical density histogram,简称AHDH)的方法,该方法用每一个形状区块的密度特征代替质心坐标来产生特征向量,以此来表示形状区块像素点的分布特性.这两种方法在对形状进行分割时,分割的方向依赖于目标形状所处的坐标系统,因此不满足旋转不变性.此外,随着递归次数的增加,区块数量会呈指数级增长,导致计算的复杂度很高,难以满足实时性需求.
形状上下文(shape contexts,简称SC)[35]是经典的基于边界点集的形状分析方法,该方法将目标形状的边界像素点重新采样成指定个数的点集(一般100 个~300 个点),将这个点集中的每一个点分别作为参考点,通过在该点放置一个极坐标栅格来统计点集中的其他各点相对于该点的空间分布,并产生直方图作为该点的描述子,也称为该点的形状上下文.该方法有效地抽取了边界上点的空间分布信息和相对位置关系,抽取的形状特征具有较强的辨识力,在MPEG-7 CE-1 形状测试集上取得了76.51%的识别准确率.距离集(distance set,简称DS)描述方法[36]是另一种基于边界点集的形状描述方法,该方法对目标形状边界上的点重新采样得到N个点的点集,对点集中的每一个点,计算该点与其最邻近的n(n≤N)个点的距离,构成一个距离集.经过归一化处理的距离集可以用来描述该点与其临近各点的空间关系,而由各点的距离集构成的集合,即距离集的集合,构成了描述整个点集的空间安排.该方法在MPEG-7 CE-1 形状测试集上取得了78.38%的检索精确率.形状上下文和距离集在形状匹配阶段都需要计算点到点的优化问题,该优化问题可归结为经典的二次指派问题,而求解该问题的匈牙利算法[37]的时间复杂度为O(N3),这里,N表示点集的规模.根据文献[35]的报告,形状上下文方法在执行一次两个形状的匹配时,在对每个形状仅采样100 个点的情况下,便需要耗费0.2s.而根据文献[36]的报告,距离集方法在执行形状匹配时,在采样250 个点的情况下,需要耗费0.7s.很显然,考虑到匹配算法的计算复杂度,在使用该类方法时,对轮廓点进行重新采样得到的点集规模不能太大(一般不超过300 个点).而对于具有复杂内部结构的区域形状,如果对边界点重采样构成的点集规模太小,显然不足以描述形状的复杂结构信息.形状上下文和距离集虽然能处理区域形状,但是由于二者计算效率低,所以有着很大的局限性.文献[38]提出一种称为轮廓点分布直方图(contour points distribution histogram,简称CPDH)的方法,该方法将极坐标栅格放置于整个形状的质心,从而得到描述整个形状轮廓像素点空间关系的轮廓点分布直方图.形状的相似性用EMD(earth mover's distance)距离进行度量.该方法实质上是一种全局描述子,因不需要为点集中的每一个点进行特征描述,因此无论在形状描述还是匹配阶段,都减少了计算量.该方法在MPEG-7 CE-1 形状测试集上取得了76.56%的检索精确率.
近年来,一些研究工作将复杂网络模型应用于形状分析当中.
文献[39]提出,将目标形状的边界建模为一个小世界复杂网络.在该模型中,形状边界上的像素点对应网络上的节点,像素点间的连线对应网络上的边,像素点间的归一化欧氏距离作为边的权值.通过网络的动态演化,提取各时刻网络的度特征和联合度特征,组合成一个特征向量作为描述子,在形状匹配阶段,则通过特征向量间的欧氏距离来确定形状间相似度.文献[40]中提出一种无序点集描述方法(unordered point-set description,简称UPSD),该方法将目标形状边界看成无序点集,提出一种新的基于复杂网络模型的目标边界无序点集形状分析方法.该方法用自主的网络动态演化机制分层地提取形状特征,通过对网络的局部测量和全局测量,获取网络的无权特征和加权特征,构成形状的局部描述子和全局描述子.该描述子为目标形状的识别提供了具有强辨识能力的特征,在形状匹配阶段,用较低计算复杂度的Hausdorff 距离和L-1 距离分别作为局部距离和全局距离,从而节省了时间成本.该方法在MPEG-7 CE-1 形状测试集上取得了78.18%的检索精确率.
2 边界点集的分层描述模型
对于一个目标形状的图像,我们首先抽取目标形状的边界像素点,得到边界的无序点集B0,该点集由边界像素点的坐标构成,用(x,y)表示像素点的坐标,则目标形状边界的中心点可以定义为




如此迭代地分割下去,将经过l层分割得到的边界记为,则该边界可以表示为

我们对θ在区间[0,2π)上均匀地采样m个角度,用j=0,1,…,m-1 表示它们的索引.让变量θ依次取这m个值,这样我们可以对目标形状边界沿m个方向进行l层分割,得到m×l个子边界,构成集合:

我们称其为目标形状边界的分层描述模型,其中,m和l为模型的参数,分别表示该描述模型的方向角的个数和分层的层级数.
图3 和图4 给出了目标形状边界的分层描述模型示意图,其中,图3 为对区域形状边界的分层描述,图4 为对轮廓线形状边界的分层描述,模型的参数取m=5,l=3.
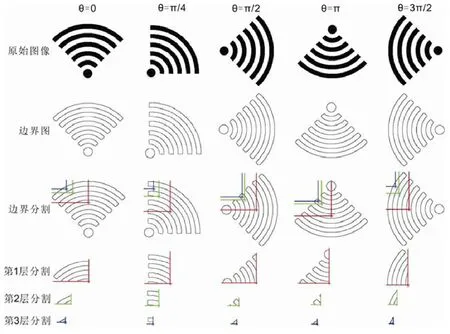
Fig.3 Visual illustration of iteratively partitioning the edge of region-based image in progressively smaller part along different directions图3 沿不同方向对区域形状的边界迭代地分割示意图

Fig.4 Visual illustration of iteratively partitioning the edge of contour-based image in progressively smaller part along different directions图4 沿不同方向对轮廓线形状边界迭代地分割示意图
3 分层度量方法
3.1 分割比
如前所述,当前层边界是对上一层边界进行一次分割得到的,分割后的边界是上一层边界的一个子集,当前层边界上的像素点在上一层边界中占的比重,构成了当前层边界对上一层边界的几何分割的一个度量,这里我们将该特征称为分割比,定义为

图5 给出了边界分割比的示意图,其中,第1 行和第2 行分别表示图3 和图4 中的区域形状和轮廓线形状在j取0、i分别取1,2,3 时的分割比特征.

Fig.5 Visual illustration of partition ratio图5 形状边界的分割比特征示意图
3.2 分散度
度量边界点在二维坐标平面上的分散程度,是另一类刻画形状边界几何特性的有用特征.为描述这一特性,我们对子边界进行如下度量:

计算该序列的均值:


成都工业学院[3]主要在教学内容上增加零部件测量、检测、机构调整、汽车配件质量的鉴别与检测、汽车再制造认识、再生燃料及新能源汽车认识等拓展内容,以引导学生不满足于现状、努力学习,达到强化实践操作技能、提升工作能力的目的。
离心率是一种被广泛应用的形状特征,它反映了目标形状像素点绕着中心点的分散程度[41].这里,我们定义子边界上点的离心率,以子边界的当前层的中心点为参考点来度量该边界上点的分散度.


而边界的主惯性矩是U的特征值,这样,边界的离心率可表示为

这里,λmax和λmin是U的特征值中的最大和最小值.这种描述方法仅仅取决于形状本身,无关于形状的大小和方向.从公式(13)可以看出ecc>1,这里,我们取离心率的倒数来对进行度量,即:

组合上述定义的两类分散度度量,得到特征向量:

总结给出的分层度量方法具有如下优点.
(1)具有形状描述的一般性.该度量方法既可以描述轮廓线形状,又可以描述区域形状;
(2)具有特征抽取的可拓展性.除了分割比和分散度,我们可以将更多其他的对目标边界的几何度量纳入到给出的分层描述模型,从而满足不同精度的检索需求;
(3)具有对目标形状的多尺度描述性.本文提出的分层描述机制使得该形状描述子具有内在的由粗到细的多尺度表征能力;
(4)较低的计算复杂性.由于我们在特征提取时仅仅考虑目标形状的边界像素点,使得给出的分层度量方法具有较高的计算效率.
4 形状相似度度量方法
形状相似度度量的主要任务是测量一副检索图像的特征向量与图像数据集中图像特征向量之间的差异.本节基于定义的目标形状边界点集的分层描述方法,提出一种循环移位的特征匹配方法,以度量两个目标形状的相似度.
4.1 形状描述子的构造

显然,矩阵D的规模为m×l,矩阵S的规模为m×3l(因为).这两个矩阵从m个方向和l个尺度,分别描述了目标形状边界的分割比特性和边界点的分散度.
组合矩阵D和矩阵S,产生一个对目标形状进行综合描述的规模为m×4l的矩阵F0:

其中,ω∈[0,1]为权重变量,用以调节描述矩阵D和S在形状相似性度度量中的贡献.
4.2 循环移位特征匹配
我们将特征矩阵F0的每一行表示成一个行向量Vi,i=0,1,…,m-1,这样,特征矩阵F0就可以改写成一个列向量的形式,即:

需要指出的是,当目标形状发生旋转时,我们对目标进行分割的起始方向会发生改变,使得方向序列(长度为m)会发生循环移位.为此,对于一个待识别的目标形状A,在将其与数据集里的形状进行匹配之前,我们先准备其特征矩阵F0以及F0的m-1 个循环移位后的版本:

这样,形状A与数据集里面的形状B之间的差异度可以定义为

这里,||·||表示L-1 距离.
5 算法性能分析
本节对前面提出的形状描述方法和特征匹配算法的不变性和计算时间复杂度进行分析.
5.1 不变性分析
因在进行分层描述之前已将坐标原点移到了形状边界的中心点,所以产生的描述子已满足对目标形状的平移不变性.由分割比的定义(公式(7)),该度量方法的计算用到了相邻层边界像素点的基数比,当目标形状发生缩放时,缩放因子在计算过程中会被消掉,这就使得分割比具有缩放不变性.对于构成分散度度量的(公式(8)~公式(10)),计算这个两个度量时,已用距离序列的最大值对距离序列中的距离进行了归一化处理,从而度量具有缩放不变性.而对于离心率(公式(14)),我们在计算时要用到边界主惯性矩的特征值,由公式(13)可知,特征值λmax和λmin相除将会消除缩放因子.因此,离心率也具有缩放不变性.因为分散度度量在文中被定义为(公式(15)),因此分散度度量具有缩放不变性.而对于目标形状的旋转变换,在形状匹配时,我们针对从形状中提取的特征矩阵给出了循环移位的形状距离度量方法,从而消除了目标形状旋转的影响.
5.2 算法伪代码和时间复杂度分析
本文提出的形状描述算法的输入有:(1)目标形状的边界点集B0;(2)对角度区间[0,2π)的采样频率m;(3)分层的层级数l.我们在算法1 中给出了形状描述算法的伪代码.
算法1.Calculating Hierarchical Descriptor of Unordered Edge Point-set.
Input:
B0:the edge-point set of a shape;
m:the number of sampling angles in range [0,2π];
l:the number of hierarchical level;
Output:

该算法最耗时的计算是从第4 步~第23 步的外层循环(执行m次).其内层循环(第6 步~第21 步)共执行l次,执行第i次内层循环会将子边界分割成4 个部分,并留下左上角的边界作为新的当前层子边界,然后对其进行特征描述.假设初始边界点集B0有n个像素点,由于每次分割都是根据被分割的子边界的中心点,沿坐标横轴和坐标纵轴两个方向将其分割成4 个部分,可以认为被分割的子边界的像素点在这4 个部分分布的概率相等,因此第i次内层循环在对上一层子边界中的个点进行分割后,依概率分布,有个点将会被分到当前层子边界,根据递推关系,可推出.所以在第i次内层循环,完成对子边界分割的算法第8 步的时间复杂度为,而完成对子边界进行度量的算法的第9 步~第17 步的时间复杂度为.因此,执行第i次内层循环的时间复杂度为,从而执行整个内层循环的时间复杂度为.又执行对边界的旋转操作(算法第22 步)的时间复杂度为O(n),所以执行整个外层循环的平均时间复杂度为O(m(n+n))=O(mn),即该算法的时间复杂度为O(mn).
以上是形状描述算法的时间复杂度分析,本文提出方法的另外一部分是形状匹配任务.在得到形状描述矩阵F0(公式(17)和公式(18))后,我们要对其进行m-1 次循环移位(公式(19)),由于F0的规模为m×4l,所以循环移位操作的时间复杂度为O(ml).计算两个特征矩阵的L-1 距离的时间复杂度为O(ml),而我们要将形状A的特征矩阵及其m-1 个循环移位版本与形状B的特征矩阵进行匹配(公式(20)),因此,计算两个形状距离的时间复杂度为O(lm2),从而整个形状匹配阶段的时间复杂度为O(ml+lm2)=O(lm2).值指出的是,l为本文提出的形状描述算法的一个输入参数,若,即算法在执行l次内部循环后仍有个点划分到了边界点集中,这种情况下,算法的内层循环执行了l次,因此,此时形状匹配阶段的时间复杂度小于等于O(m2log2n);若l>log4n,因,算法的内部循环最多执行到log4n步后便会跳出循环,此时,形状匹配阶段的时间复杂度为O(m2log2n),因此,形状匹配阶段的时间复杂度在最坏情况下为O(m2log2n).
上述分析表明,本文提出的算法无论在形状描述阶段,还是在形状匹配阶段,都有着可接受的计算复杂度.
6 实验结果和讨论
为评估本文提出的目标形状识别算法的性能,我们将MPEG-7 CE-2 区域形状测试集和MPEG-7 CE-1 轮廓线形状测试集这两个被广泛采用的形状测试集作为基准测试集.因本文提出的方法属于基于边界点集的描述方法,所以在实验中,我们选择的主要比较对象为4 种基于边界点集的形状描述方法——形状上下文SC[35]、距离集DS[36]、无序点集描述方法UPSD[40]和轮廓点分布直方图CPDH[38].另外,两种基于区域点集的描述方法:Zernike 矩ZM[28]、自适应密度直方图AHDH[34]和一种区域点集和边界点集相结合的描述方法:Zernike 矩边缘梯度ZMEG[32],在实验中也被纳入为比较对象.其中,ZM[28]是MPEG-7 推荐的标准的区域形状描述方法;而AHDH[34]同本文的算法一样,都属于分层的形状描述方法.我们的实验参数设置如下:角度采样频率m=72,层级数l=3;构建特征矩阵过程中,用以调节描述矩阵D和S在形状相似性度量中贡献的权重参数ω=0.8.实验平台为一台CPU 为Intel Core i5-4590 3.30GHz,内存8G,操作系统为Win10 的台式计算机,算法用Matlab 编程实现.
6.1 MPEG-7 CE-2区域形状测试集
我们用于算法评估的第1 组实验是在MPEG-7 CE-2 区域形状测试集[30]上进行的.MPEG-7 CE-2 测试集总共包含3 621 幅区域形状图像,其中的部分样本如图6 所示.该测试集中有651 个样本,被分成31 组,每组有21个样本,同一组中的样本属于同类形状,图7 给出了第8 组形状的21 个样本.我们采用被广泛用于形状检索性能评估的方法——bulls-eye test 评估方法[6-12,15-17,19-23,34-36,38,40,43,44]进行算法的性能评估.采用该方法,我们把数据集中651 个样本依次作为检索样本跟测试集中的3 621 样本进行形状相似性比较,返回差异度最小的前2×21=42 幅图像,统计返回的42 幅图像中,与查询样本属于同一组的数目.假设返回r幅属于同一组的样本,显然r≤21,计算r/21×100%的值作为该查询样本的检索率,651 个样本的平均检索率作为整个测试的检索率(bulls-eye test score).

Fig.6 Samples from MPEG-7 CE-2 dataset图6 MPEG-7 CE-2 数据集的样本

Fig.7 All the samples in the group 8 of MPEG-7 CE-2 dataset图7 MPEG-7 CE-2 数据集中第8 组形状的所有样本
我们在图8 中给出部分形状的前21 个检索结果(框以红色矩形的形状是错误的检索结果),并在表1 中给出了本文提出的方法和参与比较的两种基于边界点集的方法SC[35]和UPSD[40]、两种基于区域点集的方法ZM[28],AHDH[34]和一种区域点集和边界点集相结合的方法ZMEG[32]在MPEG-7 CE-2 区域形状测试集上的检索率.从表中给出的数据可以看出,与同类基于边界点集的方法SC 和UPSD 相比,本文提出方法的检索精确率分别高出了15.48 个和2.33 个百分点.与基于区域点集的方法ZM 相比,本文的方法高出了6.26 个百分点;与区域点集和边界点集相结合的方法ZMEG 相比,本文的方法高出了4.04 个百分点.值得指出的是,与本文的思想最为接近的是同样采用分层描述的AHDH 方法,但该方法在MPEG-7 CE-2 测试集上仅取得了49.94%的检索率.其主要原因是,该方法仅从单个方向上对目标形状进行描述,该方法的描述和匹配依赖于目标形状的方向;而本文提出的方法采用了一种旋转分层的描述框架,从多个方向上描述了形状的分层复杂性,因此其形状匹配结果不依赖于形状的方向.该组实验结果表明:本文提出的方法在MPEG-7 CE-2 区域形状测试集上的测试性能要优于参与比较的同类方法,也好于参与比较的两种基于区域点集的形状描述方法和一种区域点集和边界点集相结合的方法,从而证明本文提出的方法比其他方法更能有效地处理包含复杂内部结构的形状图像,对目标形状检索具有一般性.需要指出的是,对于DS[36]和CPDH[38],由于报告这两种方法的文献没有给出在MPEG-7 CE-2 测试集的测试结果,也没有给出具体的实现细节,因此在本组实验中,我们略去了与这两种方法的比较,但在下一组实验中,我们将直接引用这两种方法报告的结果作为对比.

Fig.8 Top 21 retrieval results of partial shapesin MPEG-7 CE-2 dataset图8 MPEG-7 CE-2 数据集中部分形状的前21 个检索结果

Table 1 Retrieval rates of the compared methods on the MPEG-7 CE-2 shape dataset表1 各种对比方法在MPEG-7 CE-2 形状测试集上的检索率
6.2 MPEG-7 CE-1轮廓线形状测试集
我们用于算法评估的第2 组实验是在MPEG-7 CE-1 轮廓线形状测试集[42]上进行的.MPEG-7 CE-1 轮廓线形状测试集是被广泛采用的用于形状检索性能评估的标准测试集.该测试集共包含1 400 幅轮廓线形状图像,它们被分成70 种形状类型,不同类型形状的样本如图9 所示,每种类型的形状包含20 个样本,如图10 所示.该组实验我们依然用bulls-eye test 评估方法.与上一组实验不同的是,这里我们用测试集中的每一个样本作为一个查询样本,跟测试集中的所有样本进行相似性比较;然后,根据形状的差异度进行排序,返回差异度最小的前2×20=40 幅图像,统计返回的这40 幅图像中有多少幅与查询样本属于同一类.假设有r幅返回图像跟查询图像属于同一类,显然r≤20,计算r/20×100%的值作为该查询样本的检索率,取1 400 个检索样本的检索率的平均值作为整个测试的检索率(bulls-eye test score).

Fig.9 All kinds of shapes from the MPEG-7 CE-1 dataset图9 MPEG-7 CE-1 数据集的所有类型形状样本

Fig.10 All the samples of the camel shape in the MPEG-7 CE-1 dataset图10 MPEG-7 CE-1 数据集中骆驼形状的所有样本
我们在图11 中给出了部分形状的前20 个检索结果(框以红色矩形的形状是错误的检索结果),并在表2 中给出了本文提出的方法和参与比较的4 种基于边界点集的方法(带“*”标识的结果直接引自参考文献)、两种基于区域点集的方法和一种区域点集和边界点集相结合的方法在MPEG-7 CE-1 轮廓线形状测试集上的检索率.

Fig.11 Top 20 retrieval results of partial shapesin MPEG-7 CE-1dataset图11 MPEG-7 CE-1 数据集中部分形状的前20 个检索结果

Table 2 Retrieval rates of the compared methods on the MPEG-7 CE-1 shape dataset表2 各种对比方法在MPEG-7 CE-1 形状测试集上的检索率
从表中给出的数据可以看出,与同类基于边界点集的方法SC[35],DS[36],UPSD[40]和CPDH[38]相比,本文提出方法的检索精确率分别高出了6.1,4.23,4.43 和6.05 个百分点;与基于区域点集的方法ZM[28]和AHDH[34]相比,本文的方法分别高出了13.71 和18.66 个百分点;与区域点集和边界点集相结合的方法ZMEG[32]相比,本文的方法高出了11.97 个百分点.在本组实验中,我们还比较了各类算法执行的效率,需要指出的是:对于数据集中的形状,用于表征这些形状的形状描述子可以在线下进行提取,所以这里我们比较的是各算法执行线上形状匹配的效率.根据文献[35]报告的结果,采用Shape Contexts 方法,执行一次两个形状的匹配计算(采样100 个点),在一台Pentium III/ 500MHZ 的计算机上需要耗时2×10-1s;根据文献[36]报告的结果,采用Distance Sets 方法,执行一次两个形状的匹配计算(采样250 个点),在一台Pentium III/667MHZ 的计算机上大约耗时7×10-1s;根据文献[40]报告的结果,采用Unordered Point-set Description 方法,在一台CPU 为Intel Core i7-4770/3.4GHZ 的计算机上,执行一次两个形状的匹配计算(采样300 个点),耗时为9.4×10-4s;而采用本文提出的方法,在一台CPU 为Intel Core i5-4590/ 3.30GHZ 的计算机上,执行一次两个形状的匹配计算,仅用时2.7×10-4s.我们在表3 中给出了几种经典方法和本文提出的方法在MPEG-7 CE-1 形状测试集上的匹配时间复杂度和平均匹配时间对比(带“*”标识的结果直接引自参考文献).该组实验结果表明:相较于参与比较的其他方法,本文提出的方法不仅具有更好的检索精确度,而且具有更高的计算效率.

Table 3 Time complexity and average matching time of several remarkable methods and the proposed method on the MPEG-7 CE-1 shape dataset表3 几种经典方法和本文提出的方法在MPEG-7 CE-1 形状测试集上的匹配时间复杂度和平均匹配时间
对于一些基于曲线的方法,如多尺度凹凸性[5]、内部距离[6]、三角形面积[7]、轮廓柔韧性[8]、形状树[17]、局部仿射不变描述子[19],虽然这些方法在MPEG-7 CE-1 测试集上报告的结果大都超过85%,但这些方法是专门为轮廓线形状设计的,对于MPEG-7 CE-2 中的区域形状,这些方法则不能对其进行有效地处理.值得指出的是,本文提出的方法虽然没有用到边界点的有序信息,但其在MPEG-7 CE-1 上的识别率已超过了一些基于曲线的方法,如生物序列(biological code,简称BC)[43]、距离内缘比率(distance interior ratio)[44]等方法.
7 结 论
本文提出了基于目标边界无序点集的形状描述方法,以应用于一般的形状图像检索任务.该方法通过对目标形状的边界点集沿各个方向的逐层分割,建立了一种对目标形状边界的分层描述模型,对各层子边界的分割比和分散度的几何度量,多尺度地描述了目标形状边界点的空间分布特性.通过在MPEG-7 CE-2 区域形状测试集和MPEG-7 CE-1 轮廓线形状测试集上的两组图像检索实验和其他同类方法的对比,验证了该方法的有效性.
总结该算法具有如下优点.是一种通用的形状图像描述算法,既能描述轮廓线形状,又能描述区域形状;具有特征抽取的开放性,虽然基于本文提出的描述框架,我们仅用了分割比和分散度这两种几何度量对每一层子边界进行了度量,但该描述框架具有一般性,每一层子边界还可以引入其他几何度量,如矩特征、傅里叶特征等,以满足对不同精度的形状图像识别任务的要求;具有内在的多尺度特性和对旋转、缩放和平移的不变性;具有比同类方法更好的检索精确率和更高的计算效率.
在未来的研究工作中,在目标形状的特征抽取阶段,我们会将一些其他的边界度量方法纳入到给出的分层描述框架中,结合机器学习的方法进行有效的特征选取,从而获取更加精确的形状描述子;在形状匹配阶段,我们将考虑结合动态规划和距离度量学习的方法,来进行更加准确的形状相似度的度量.
猜你喜欢
计算机仿真(2022年8期)2022-09-28
上海文化(文化研究)(2022年3期)2022-06-28
合肥工业大学学报(自然科学版)(2021年11期)2021-12-10
现代电子技术(2021年1期)2021-01-17
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
现代电子技术(2018年18期)2018-09-12
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
电脑知识与技术(2018年35期)2018-02-27
健康女性(2016年11期)2017-02-14
