
中文非功能需求描述的识别与分类方法研究*
2019-10-24 02:09贾一荻
软件学报 2019年10期
贾一荻, 刘 璘
(清华大学 软件学院,北京 100084)
在软件开发过程中,软件需求分析工作占有重要地位.软件需求工程的一个主要任务就是将系统的功能需求和非功能需求尽可能完整、准确地表示出来.与描述系统能力的功能需求相比,用于约束系统质量属性的非功能需求更容易被忽视,却也造成了许多项目的最终失败[1].Bajpai 等人[2]更是在实际调研后,得出了如下结论:相较于具备明确非功能需求描述的项目,缺少非功能需求分析的项目会在失败率上高出60%.李凤麟等人[3]提出了一种从质量属性的角度分析非功能需求的方法.Boehm 等人[4]的研究则指出,质量需求之间同样存在冲突,需要进行权衡和优化取舍.由此可见,在软件开发的各个阶段关注非功能需求,尤其是在软件开发的前期明确相应的质量属性,会对项目的最终结果产生积极的影响.
相较于被集中撰写的功能需求,软件的非功能需求描述通常分散甚至隐含在不同语句、段落、文档之中,因此极容易被忽视.而面对复杂的系统和巨大的文本量,人工分析、提取非功能需求意味着大量的时间成本,且难以避免疏漏之处.所以,将上述过程在一定程度上自动化,即通过软件辅助完成非功能需求的识别、分类工作,对保障需求分析过程的效率和质量具有重要意义.
非功能需求相关的概念本体和分类模型研究在国内外有一定的基础,但在软件工程实践中,用户在表达非功能需求时没有明确的规范[5].本文重点围绕性能、可靠性、可用性、安全性、可维护性这5 类典型、常见的非功能需求展开研究.在识别非功能需求描述的基础上,将其划分到最为近似的分类.具体来说,本文的主要贡献包括:
(1)针对性能、可靠性、可用性、安全性、可维护性这5 类非功能需求,整理了其通用描述词汇,并针对中文需求文本,整理了功能需求和非功能需求数据集.
(2)针对中文需求文本,提出了一种自动化的非功能需求识别方法,并对其效果进行了实际测试.
(3)针对中文非功能需求描述,提出了一种自动化的分类方法,并对其效果进行了实际测试.
值得一提的是,上述方法主要适用于功能需求和非功能需求界限不清晰的中文需求描述,如非结构化的需求文档、用户评论、专家意见等.而结构化很强的需求文本,通常已经区分了功能需求和非功能需求,甚至区分了非功能需求的种类.在这样的情况下,一般可以直接依据需求模板的格式提取相应内容,无需采用本文的方法.
此外,本文提出的识别方法主要针对非结构化的中文需求文本.例如,可以将需求文档作为输入,然后采用本文的识别方法标识出其中可能包含非功能需求的语句,从而缩小人工检查的范围.而本文提出的分类方法则用于进一步确定非功能需求的分类.例如,针对人工确认包含非功能需求的语句,或是已区分功能需求和非功能需求的结构化文档,可以使用此方法完成非功能需求语句的类别划分.本文将识别和分类的过程分开完成,一方面,可以使上述方法在不同的应用场景下更为灵活;另一方面,如果在识别和分类过程之间加入人工确认的步骤,则能够以较低的人力成本有效地提升分类效果,具体的讨论和相关实验结果将在后文中进行阐述.
本文第1 节概述国内外现有的研究成果.第2 节对实验数据集进行描述.第3 节介绍中文文本中的非功能需求识别方法.第4 节阐释非功能需求分类的具体过程.第5 节总结全文,并对后续可进行的研究工作进行初步探讨.
1 研究背景
为了高质量、高效地完成需求分析阶段的各项工作,自动化的需求文本分析工具曾一度是需求工程领域的研究热点.而随着软件系统的不断复杂化,非功能需求的重要性也逐渐显现出来.
针对英文需求文本,已有不少研究围绕非功能需求的提取和分类展开.Cleland-Huang 等人[6]提出了一种基于特征词的非功能需求识别方法,从人工标注的训练数据中提取各类非功能需求的特征词,并根据特征词的出现频率对文本进行分类.在面对新的领域文本时,上述方法可以达到79.9%的召回率,能够有效缩小人工识别的范围.但是,其精确率只有20.7%,并且需要人工标注部分数据才能完成迭代训练,因此仍然需要较多的人工参与.为了降低人力成本,Casamayor 等人[7]提出了一种半监督学习方法,并且达到了70%的准确率.Hindle 等人[8]采用了不同的思路,直接基于话题模型获得词汇列表,进而将其对应到各类非功能需求.近年来,Sunner 等人[9]使用基于遗传算法的神经网络,实现了非功能需求和功能需求的分类.Ramnani 等人[10]基于文本模式,实现了非功能需求识别.基于模糊规则的问题本方法也在非功能需求分类中得到了有效应用[11].
整体来看,针对英文需求文本自动检测的研究已颇有进展.但是,由于语言之间的巨大差异性,这些研究成果无法直接对中文需求文本提供支持.中文词语间无空格分隔、歧义现象普遍、实词运用灵活等特点,更是形成了其特有的复杂性和难度.刘婷婷等人[12]以情感分析和主题分类两种任务为背景,基于IMDB、RCV1 这两个英文数据集和豆瓣影评、搜狐新闻这两个中文数据集,分别应用传统机器学习方法和深度学习方法进行实验.使用传统的机器学习方法进行情感分类,英文的分类准确率达到了90.70%,而中文的分类准确率仅达84.00%.引入深度学习方法后,虽然部分实验结果表明中文可能获得更高的准确率,但是英文分类的整体效果依旧好于中文.考虑到本文所使用的训练数据量难以满足深度学习模型所需,我们将重点关注传统的机器学习方法.虽然对软件非功能需求代价权衡方法[13]和对非功能性元需求集[14]的研究已经体现出了国内对非功能需求的逐渐重视,但是与国外相比,针对中文非功能需求的自动化分析方法,研究程度尚显不足.倪瑜泽等人[15]提出了一种基于用户评论的演化需求发现方法,达到了93.32%的平均精确率和78.42%的平均召回率.由于我们基本上没有找到对中文非功能需求进行自动分类的相关工作,因此我们的实验结果将主要对比上述国外相关工作和国内的中文文本分类工作.考虑到我们的训练数据量以及前文提及的中文文本处理上的难度,我们认为,近似或略低于上述实验效果的结果均是可接受的.
本文的研究聚焦于两个方面.第一,识别中文需求文本中的非功能需求.前文已经提到,针对非功能需求的描述往往较为分散,且很有可能隐含于系统的功能描述之中.例如,“系统在用户登录过程中,验证其身份和权限”这句话,就隐含了安全性这一非功能需求.诸如此类识别工作如果均由人工完成,则需要大量的时间成本.因此,本文将首先探讨非功能需求的自动化识别方法,并在这一阶段重点考虑非功能需求的召回率,以期缩小人工检查的范围.第二,针对包含非功能需求的语句,确定相应非功能需求的具体分类,即判定语句是否包含性能、可靠性、可用性、安全性、可维护性这5 类非功能需求中的某一类或某几类,并通过准确率对分类结果进行评价.
2 实验数据集
本文所使用的实验数据可大致分为3 个部分.
第1 部分是需求文本数据,主要来源于清华大学软件需求工程课程的学生作业,也有部分来源于互联网上的博客和文档.我们对上述数据进行了筛选和整理,数据所属的系统包括信息管理系统、网络通信软件、车载导航软件、在线教育软件、游戏软件、微信小程序、手机应用软件等多种类型,尽可能地保证文本覆盖较多的项目领域.上述系统的规模相对较小,复杂度相对较低,但其需求描述较为全面.我们将包含非功能需求或纯粹描述某一功能模块的几句或几段话作为用于实验的1 条数据.最终,我们获得训练数据400 条,其中,功能需求描述和非功能需求各占200 条,不同类别非功能需求的数据量见表1.考虑到识别非功能需求可以将各类别数据整合使用,本质上属于二分类问题;而非功能需求分类则基于初始特征词和语句中的关键词.因此,这一数据量基本上能够满足实验和测试要求.

Table 1 Amount of data for various NFRs表1 各类非功能需求的数据量
第2 部分是用于非功能需求分类的初始特征词.本文以需求工程领域对非功能需求的常用描述词汇为基础,实现基于文本相似度的分类方法.上述描述词汇主要整理、提取自相关研究文献[16-18].同时,考虑到同一英文词汇可能对应多种中文表达,因此,我们适当进行了同义词扩充,其结果见表2.
第3 部分是在实际测试中使用的数据.这一部分的测试数据及结果来自工业界实际项目,项目规模大,复杂度较高,需求描述也比较规范和准确.

Table 2 NFRs and descriptive words表2 非功能需求及其描述词汇
3 基于中文文本的非功能需求识别方法
中文需求文本中,非功能需求描述可能分散、隐含在各个语句中,但也有部分语句与非功能需求无关.例如,“用户可以对文本进行查看,增加,删除,编辑等操作.”就是纯粹的功能描述.因此,需要首先识别出与非功能需求相关的语句,即对语句是否包含非功能需求进行判断,本质上是一个二分类问题.本节将重点介绍中文非功能需求识别的具体流程,并对实现效果和测试结果进行总结和说明.为了尽可能地缩小人工检查的范围,这一部分工作将重点关注非功能需求的召回率.
3.1 非功能需求识别的流程
中文非功能需求识别包含分词和提取关键词、选择文本特征、训练分类模型、测试文本分类这4 个主要步骤,其流程如图1 所示.接下来,我们将对每一步骤的实现方法进行具体介绍.

Fig.1 Chinese non-functional requirements identification process图1 中文非功能需求识别流程
(1)分词和提取关键词
本文采用的非功能需求识别方法基于文本关键词,因此,首先需要对需求文本进行分词和词性标注处理,并提取其中的关键词.ICTCLAS[19]、HanLP[20]等近年来广泛应用的中文文本分析工具均提供了上述功能,因此,本文将直接使用HanLP 工具完成上述工作.
(2)选择文本特征
在获得需求文本中的关键词后,需要确定文本特征的表达方式.常用的文本特征模型包括BoW(bag-ofwords)和TF-IDF 模型.BoW 模型统计文档中各词汇的出现次数,并使用无序词集合表示整个文档.TF-IDF 模型的主要思路是:如果一个词语在某一文档中出现次数较多,且出现该词语的文档数量较少,则该词语对文档的区分能力较强.我们分别尝试使用上述两种特征进行后续实验,并对其结果进行了比较,具体实验结果将在第3.2节给出.
(3)训练分类模型
将文本以特征形式表示后,即可基于此训练分类模型.我们分别尝试了逻辑斯蒂回归(LR)、朴素贝叶斯(NB)、NBSVM(Naïve Bayes-support vector machine)[21]等分类模型,并在参数调整后选取了最优模型用于后续的测试文本分类,具体的实验结果同样在第3.2 节给出.
(4)测试文本分类
使用步骤(1)中的分词和关键词提取方法及步骤(2)中的文本特征选择方法,将测试文本以特征的形式进行表述.之后,将特征作为分类模型的输入,模型会给出“包含非功能需求”和“不包含非功能需求”两类标签.
3.2 实验结果及总结
我们组合使用不同的文本特征和分类模型,实现非功能需求识别,并采用五折交叉验证的方法进行测试,即将全部数据平均划分为5 份,每次取其中的4 份用于训练,1 份用于测试.实验和测试均采用第2 节中所描述的数据集.5 次实验的精确率、召回率及其均值见表3.
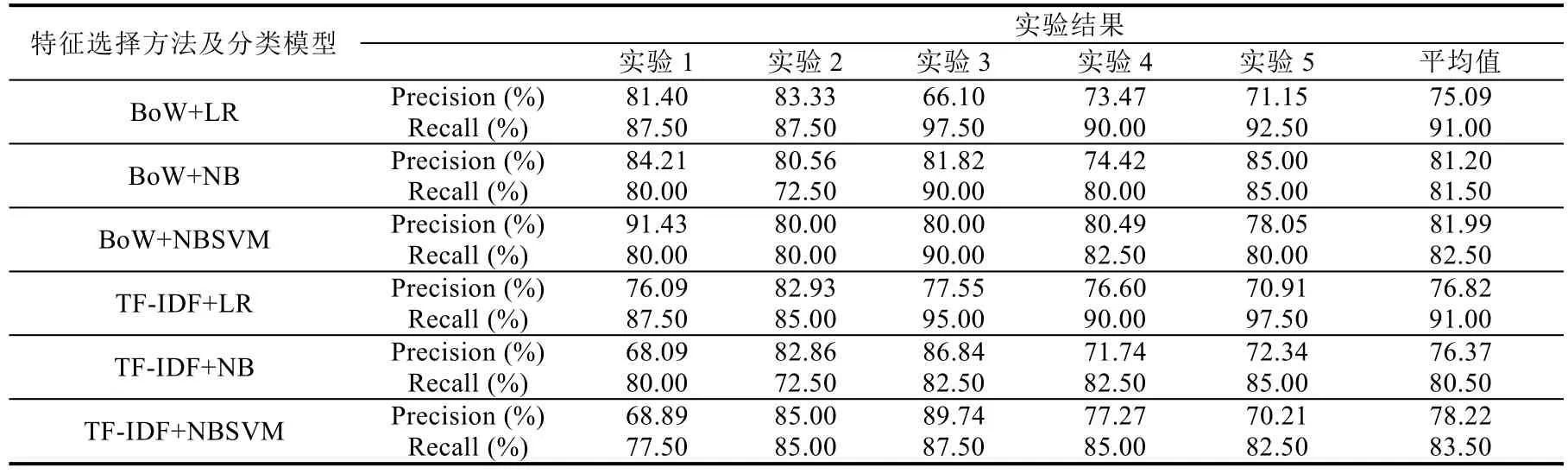
Table 3 Results of non-functional requirements identification表3 非功能需求识别的实验结果
为了对实验结果形成直观认识,将不同模型的平均精确率和平均召回率以簇状柱形图的方式加以呈现,其结果如图2 所示.可以看到,结合使用BoW 和NBSVM 模型取得了最高的精确率;使用BoW 或TF-IDF 表示文本特征,使用LR 进行模型训练均得到了91.00%的召回率.
由于我们的实验文本已经覆盖了较多的项目领域,并且划分数据的过程中采用了随机抽取的方法,因此,实验结果具有一定的普适性.而表3 中列出的单次实验结果,也能够在一定程度上帮助我们判断模型在不同数据集上的稳定性.

Fig.2 Average precision and average recall rate for different models图2 不同模型的平均精确率和平均召回率
这一部分工作的主要目的是提取可能包含非功能需求的语句,从而缩小人工检查的范围,所以我们将重点关注非功能需求的召回率,并在此基础上尽可能地保证精确率以及模型效果的稳定性.因此,最终选用TF-IDF表示文本特征,并使用逻辑斯蒂回归实现分类.我们使用上述模型,在普通配置(Intel(R)Core(TM)i5-4200U CPU@ 1.60GHz,8.00GB RAM)的笔记本电脑上进行实验,针对包含5 万字左右的需求文本,可以在20s 内完成非功能需求的识别和导出,其时间成本远低于人工检查所需时间,可以满足实用要求.
最后,由领域专家对上述分类方法进行生产环境中的测试.测试数据来源于实际项目,项目规模大,复杂度较高,需求描述也比较规范和准确.使用的训练数据共计200 条,其中非功能需求100 条,功能需求100 条;测试数据共计200 条.非功能需求识别的召回率达到88%,精确率约为73%.因此,上述方法的召回率基本上满足实用要求,可以有效缩小人工检查的范围.
整体来看,针对不同系统的需求描述,上述模型均取得了较好的测试结果,比较适用于对召回率要求较高的应用场景.例如,可将需求文档作为输入,然后采用本文的识别方法标识或导出可能包含非功能需求的语句,从而缩小人工检查的范围.在其他应用场景下,若需要重点关注精确率,则应选取其他特征表示方法或分类模型,本文的实验结果也可以提供一定的参考.
4 基于中文文本的非功能需求分类方法
识别出包含非功能需求的文本后,可将其进一步对应到性能、可靠性、可用性、安全性、可维护性这5 类非功能需求中的某一类或某几类.值得一提的是,目前非功能需求的分类并不存在统一的标准[22],因此,在和领域专家交流后,我们最终选取了上述典型、常见的非功能需求.另外,safety 与security 虽然均会被翻译为安全性,但是两者的实际侧重有所差别.前者主要关注人身安全,而后者则强调信息安全.由于软件涉及的安全性需求主要围绕后者,而对前者的涉及较少,因此,我们参考ISO/IEC 25010[23]中的软件质量属性分类,不对safety 和security 进行区分.本节将重点介绍实现中文非功能需求分类的具体流程,并对实现效果和测试结果进行总结和说明.
4.1 非功能需求分类的流程
中文非功能需求分类包含分词和提取关键词、划分关键词类别、扩充特征词、计算特征词权重、文本分类这5 个主要步骤,其流程如图3 所示.接下来,我们将对每一步骤的实现方法进行具体介绍.

Fig.3 Chinese non-functional requirements classification process图3 中文非功能需求分类流程
(1)分词和提取关键词
本文采用的非功能需求分类方法基于特征词和文本关键词,因此,首先需要对需求文本进行分词和词性标注处理,并提取其中的关键词.这一部分工作同样使用HanLP 工具来完成.
(2)划分关键词类别
在获得需求文本中的关键词后,可以计算出每一个关键词与现有特征词的语义相似度.具体来讲,词语间语义相似度的计算需要从《哈工大信息检索研究室同义词词林扩展版》中获得词语编码,之后即可采用田久乐等人[24]提出的计算方法,依照公式求得两个词语间的语义相似度.最后,各个关键词分别被划分到与其语义相似度最高的特征词所属的非功能需求类别.
(3)扩充特征词
由于词语相似度的计算没有考虑到上下文的影响,因此,同一语句中的关键词很可能属于不同的非功能需求类别.例如,从“高峰时段快速响应用户请求.”这一语句中,可以提取出“响应”“快速”“高峰”“用户”等多个关键词.接下来,使用步骤(2)中的方法计算语义相似度,并将关键词划分到其最近似特征词所在的分类.前两个关键词会被划分为性能;后两个词语的最相似特征词分别为“指纹”和“身份”,因此均被划分至安全性.
显然,上述语句描述的是性能这一非功能需求.“用户”这一名词本质上可以在各类非功能需求描述中使用,因此不应该作为特征词出现在任何类别中;而根据经验,“高峰”倾向于出现在描述性能的语句中,因此应该作为性能的扩充特征词.这样一来,对上述两个词语的期望处理方式产生了分歧,且其中应用了大量的人工经验,所以计算机很难对此进行分辨.但是,考虑到非特征关键词可能出现在任何类别的非功能需求中,因此在不断增加训练数据的情况下,该关键词会被加入到各个分类,所以可以考虑在后续步骤中降低其权重,而在本步骤中将所有关键词作为扩充特征词.
接下来,需要确定语句中关键词的最近似分类.为了尽可能地在各分类特征词中引入上下文信息,将一个语句中的全部关键词作为一个整体,确定其最近似分类.“响应”和“快速”均包含在初始特征词中.而根据语义相似度的计算结果来看,“指纹”和“身份”与其最近似词语的相似度并不是很高.所以,相较于直接采用多数投票的方式决定最终分类,对不同的关键词赋予不同的权重更为合理,其计算公式如下:

其中,y表示分类结果,v表示分类,V表示全部非功能需求类别,k表示从文本中提取的关键词数量,δ(v,f(xi))判定关键词xi是否属于类别v,wi则表示关键词权重.考虑到尚未通过大量训练完成特征词的扩充,因此,在现阶段的实验中,初始特征词的相同关键词被分配较高的权重,相似关键词的权重则随着其相似程度的下降而递减.
(4)计算特征词权重
步骤(3)中已经提到,“用户”等非特征关键词极有可能会作为扩充特征词,被加入到各个非功能需求类别中.为了降低这些词语在实际分类过程中造成的干扰,同时提高重要特征词的影响力,需要对不同特征词赋予不同的权重,其计算公式如下:

其中,wi表示特征词权重,|V|表示非功能需求类别总数,v表示具体的非功能需求分类,t表示特征词.这样一来,当特征词出现在越多的分类中时,其权重就会越小,对最终分类结果的影响也就越小.
(5)文本分类
针对待分类文本,同样先进行分词和关键词的提取.接下来,计算关键词的最近似类.如果该关键词已存在于特征词中,则使用步骤(4)中计算所得的权重;否则,使用统一的基础权重.这一步骤的计算依旧使用公式(1),只是权重的计算方式与步骤(3)有所差异.
4.2 实验结果及总结
本节的实验和测试均采用第2 节中所描述的数据集.首先,从每类非功能需求中随机抽取10 条数据用于测试,共计50 条,其余150 条数据用于特征词扩充.我们分别使用不同数据量进行特征词扩充,值得一提的是,用于扩充的数据将从各类非功能需求中分别随机抽取,尽量保证各类别数据分布均匀.用于特征词扩充的数据量分别为0、50、100、150,因此,理想情况下,每次总计需要抽取数据50 条,即从各类别未使用数据中随机抽取10条.但是,考虑到数据本身分布不均匀,因此,当某一类非功能需求的数据不足时,平均使用其他类的数据进行补充即可.上述实验的结果见表4.

Table 4 Results of non-functional requirements classification表4 非功能需求分类的实验结果
为了对实验结果形成直观认识,将使用不同数据量实现特征词扩充后的准确率以折线图的方式进行呈现,其结果如图4 所示.

Fig.4 Accuracy for non-functional requirements classification图4 非功能需求分类准确率折线图
通过上述实验可以发现,随着用于特征词扩充的数据量的增加,整体的准确率呈现出先降后升的趋势.分析造成这一现象的原因,特征词扩充的初期之所以会引入一些错误,很大程度上是由于扩充了一些非特征词汇,并且这些词汇初始可能只出现在少量类别的文本中,因此未被调整到适宜权重.例如,“用户”这一名词本质上可以出现在任何类别的非功能需求之中,因此不应作为任何一类的特征词.但是,由于其语义与“身份”最为近似,因此会被划分至安全性.在完成第1 次扩充时,其权重为0.510 825 6,而在完成最后一次扩充后,其权重则下降到0.223 143 55.可见,这类非特征词的加入可能会对整体分类效果产生一定的影响,但是,随着数据量的增加,影响将会逐渐降低.
接下来,使用全量数据进行测试,并分别使用其中的0、50、100、150、200 条数据进行特征词扩充.这一实验的目的主要分为两方面:首先,增加测试数据量,使测试结果更为准确.其次,对于测试数据,判断在逐一对文本进行分类前,先将其用于特征词扩充的可行性.因为这一做法可能会降低非特征词汇对测试结果的影响.上述实验的结果见表5.

Table 5 Results of non-functional requirements classification (test with full dataset)表5 非功能需求分类的实验结果(全量数据测试)
对于上述实验结果,使用如图5 所示的折线图加以直观呈现.
整体来看,在文本分类前进行特征词扩充会对实验结果产生一定的积极影响.但是,具体来看,随着用于特征词扩充的数据量的增加,可靠性的准确率呈现出先升后降的趋势,可维护性的准确率则维持稳定.经过分析,我们认为,这在一定程度上是由于数据分布不均造成的.由于性能这一分类的非功能需求数据最多,且语句中的特征较为明显,因而会造成其他类别词汇或非特征词汇被加入其中.相较之下,可靠性和可维护性的数据量较少,所以,最后两次数据扩充中这两个类别的数据占比较低,因而会影响到扩充的词汇量.

Fig.5 Accuracy for non-functional requirements classification (test with full dataset)图5 非功能需求分类准确率折线图(全量数据测试)
上述方法主要针对包含非功能需求的语句.本文之所以将识别和分类的过程分开完成,一方面,可以使上述方法在不同的应用场景下更为灵活;另一方面,如果在识别和分类过程之间加入人工确认的步骤,则能够以较低的人力成本有效地提升分类效果.第3 节的实验结果已经表明,选用TF-IDF 表示文本特征,并使用逻辑斯蒂回归实现分类,基本能够达到接近90%的召回率和70%以上的精确率.而逻辑斯蒂回归本身,能够表示出分类结果的置信度.因此,在人工确认的过程中,只需重点关注置信度相对较低的语句,所以不会过多地增加人力成本.
作为对比实验,我们将上述两个过程合并进行,即省略识别过程,添加“功能需求”这一类别.考虑到功能需求本身的特征词汇难以定义,我们采用了设置阈值的方法.具体来讲,特征词扩充的过程与上文描述的方法相同,使用全量数据进行特征词扩充.但是,在对测试文本进行分类时,针对加权投票的得分设定阈值.如果投票所得分类的得分超过该阈值,则将文本分类为相应的非功能需求.反之,如果所有分类的得分均低于该阈值,则将文本划分至功能需求.使用不同阈值的实验结果见表6.

Table 6 Results of requirements classification (contains functional requirements)表6 需求分类的实验结果(包含功能需求)
可以看到,随着阈值的增加,文本更倾向于被分类至功能需求,因此,功能需求的识别准确率不断上升,非功能需求的识别准确率则有所下降.与之前的实验相比,当阈值为8.00 时,非功能需求的整体准确率略有下降,功能需求的准确率则与之前的实验结果存在明显的差距.而当阈值为9.00 和10.00 时,功能需求的整体准确率接近于之前的实验结果,非功能需求的整体准确率却明显不及.所以,综合来看,拆分非功能需求的提取和分类过程会获得更好的效果.
最后,由领域专家对上述分类方法进行生产环境下的实际测试.测试数据共计300 条.在不进行特征词扩充的情况下,准确率约为70%.在进行特征词扩充的情况下,准确率约为74%,因此,本方法针对非功能需求分类具备一定的有效性,且扩充特征词能够在一定程度上提升分类效果.
整体来看,本节所述的分类方法,比较适用于无法提供额外标注数据时,非功能需求文本的类别划分.例如,针对已区分功能需求和非功能需求的结构化文档,可以直接依照需求模板抽取其中的非功能需求,并将其作为输入,使用本节所述的方法进行需求描述词汇扩充,进而实现输入文本的分类.此外,由于本文方法的实现基于特征词权重,所以可以对需要人工自定义核心词汇的场景提供良好的支持.
相较于已有的国内外工作,本文将非功能需求的提取和分类过程分开完成.提取过程旨在定位非功能需求,从而缩小人工检查的范围.针对这个二分类问题,仅需要较少地标注数据训练模型,因而更符合工业界的实际情况.接下来,对确认包含非功能需求的语句进行分类,上述过程基于我们整理的非功能需求描述词汇来进行,并且特征词会在系统的使用过程中不断地自动扩充,不再需要额外地标注数据.
5 总结
随着软件系统的日益复杂化,在软件开发过程中尽早明确非功能需求,对于项目具有积极意义.针对英文需求描述,已有不少研究围绕其提取和分类展开.但是,由于不同语言需求表述之间的巨大差异性,这些研究成果无法直接对中文需求文本提供支持.
本文重点研究中文非功能需求描述的识别和分类方法.识别过程采用机器学习方法,从文本中提取出可能包含非功能需求的语句,尽可能地缩小人工检查的范围.分类过程则基于语义距离和相似度计算,将包含非功能需求的语句划分为性能、可靠性、可用性、安全性、可维护性这5 类.本文的分类训练和实验测试基于课题组工作项目整理的实验数据集来进行,并通过工业界的实际领域应用案例,验证了方法的有效性.
我们也注意到,在实验过程中,对于同一语句,不同的中文文本分析工具可能给出不同的分词和词性标注结果.而对于部分领域术语,上述工具也无法很好地进行识别.例如,HanLP 工具会将“用户体验”这一术语拆分为“用户”和“体验”两个词语,其中,前者作为名词,后者作为动词.这样无疑会对特征词的扩充和识别产生一定的影响.但是,现有的工具基本上支持用户自定义词典功能.因此,构建一个非功能需求的领域术语库,并用其辅助分词和关键词提取工作,有望优化特征词的质量,从而进一步提升非功能需求识别和分类的效果,相关工作和实验将在未来的研究中继续进行.
猜你喜欢
计算机技术与发展(2022年8期)2022-08-23
计算机系统应用(2021年9期)2021-10-11
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
现代信息科技(2020年18期)2020-02-22
小学生·多元智能大王(2014年6期)2014-07-09
外语教学理论与实践(2014年1期)2014-06-15
小雪花·初中高分作文(2009年8期)2009-11-16
