
不同品种紫花苜蓿转录组分析及营养品质差异的探讨
2019-10-25 00:41成启明格根图撒多文王志军范文强卜振鲲司强李俊峰卢娟贾玉山
草业学报 2019年10期
成启明,格根图,撒多文,王志军,范文强,卜振鲲,司强,李俊峰,卢娟,贾玉山*
(1.内蒙古农业大学草原与资源环境学院,农业部饲草栽培、加工与高效利用重点试验室,草地资源教育部重点实验室,内蒙古 呼和浩特 010011;2.内蒙古自治区科技信息研究院,内蒙古 呼和浩特 010010;3.内蒙古自治区草原勘察规划院,内蒙古 呼和浩特 010051;4.内蒙古自治区农牧业科学院,内蒙古 呼和浩特 010031;5.四川省会东县农牧局,四川 凉山 615000)
紫花苜蓿(Medicagosativa)作为世界上应用最广、经济价值最高和栽培面积最大的多年生优质豆科牧草,在现代草业的可持续发展中具有突出的地位[1]。紫花苜蓿茎叶中含有丰富的蛋白质、矿物质、多种氨基酸、维生素和胡萝卜素等,其总能、消化能、代谢能也较高,被认为是高蛋白优质饲草[2]。作为全球性的饲料作物,苜蓿产业的发展在一定程度上反映着一个国家或地区畜牧业发展的水平和质量。因此,对苜蓿进行全面的营养价值评价是畜牧业发展的必要条件。紫花苜蓿品种多种多样,受自身遗传特性及环境条件的限制,其适宜生长的环境和长势也就有所不同,其内部的营养特性自然也会存在一定的差异。赵燕梅等[3]通过对11个苜蓿品种的营养特性分析发现,不同品种间的干物质、粗蛋白、中性洗涤纤维、酸性洗涤纤维、可溶性糖等营养物质差异极显著。于辉等[4]在哈尔滨地区通过对4个紫花苜蓿品种进行大田试验发现,阿尔冈金苜蓿的草产量高于其他品种,和平苜蓿的营养品质较好,肇东苜蓿的越冬率最高,适合在该地区种植。康俊梅等[5]在北京地区对10个紫花苜蓿品种进行长达6年的引种试验发现,爱菲尼特、牧歌和胜利者3个苜蓿品种的年均干草产量显著高于其他品种,适合在北京地区种植。不同品种苜蓿不但在产量和营养物质含量上存在很大差异,高微微等[6]通过对45个紫花苜蓿品种的代谢产物皂苷进行测定研究发现,不同品种间皂苷含量差异显著。而目前关于从其遗传特性出发,从基因层面探讨造成其营养品质差异的内部机理的研究还鲜有报道。
所有表达基因的身份以及其转录水平,综合起来被称作转录组(Transcriptome),广义上指某一生理条件下细胞内所有转录产物的集合,包括信使RNA、核糖体RNA、转运RNA及非编码RNA;狭义上指所有信使RNA的集合[7]。转录组测序研究在新基因的发现,基因功能注释,基因差异表达和分子标记发展中具有重要价值[8-10]。通过新一代Illumina测序技术,能够全面快速地获得某一物种特定组织或器官在某一状态下的几乎所有转录本序列信息,并已经广泛用于模式和非模式植物的研究。
在本研究中,使用Illumina测序技术,在初花期对种植在同一块试验地的2个紫花苜蓿品种(国外品种:WL319HQ;国内品种:准格尔)的叶片RNA样品进行denovo组装,得到紫花苜蓿的Unigenes数据,从而获得整个紫花苜蓿叶片组织的转录组信息。通过分析其差异基因和代谢通路,试图从基因层面解释造成不同品种营养差异的内部机理。通过该项研究为紫花苜蓿生产实践和遗传育种奠定理论基础,同时为后续的紫花苜蓿转录组研究提供参考。
1 材料与方法
1.1 试验地概况和试验材料
试验地点位于中国内蒙古包头市。地跨东经10°37″-110°27″,北纬40°5″-40°17″。属北温带大陆气候,干旱多风,春季干旱少雨多风,夏季温和短促,秋季凉爽温差大,冬季温长而寒冷。年平均气温6.8 ℃,7月平均气温22.5~23.1 ℃,1月平均气温-13.7 ℃。无霜期约165 d,最大冻土深度1.4 m。年平均降水量330 mm,年平均蒸发量2094 mm,日平均风速3 m·s-1;全年日照时数3177 h,年日照百分率70%,是全国日照最丰富的地区之一。
试验材料为种植在同一试验地的两个品系四倍体紫花苜蓿,中国品种(准格尔)和美国品种(WL319HQ),于2017年6月1日,取2个品种的初花期叶片,并按照说明书使用TRIzol(Invitrogen)分离总的RNA样品。分别设置3个生物学重复,共计6个转录组样品,本试验材料无参考基因组。
1.2 实验流程和测定方法
1.2.1RNA提取和RNA-Seq文库构建 使用RNeasy Plant Mini Kit(Qiagen,Germany)试剂盒按照制造商的说明书从2个紫花苜蓿品种的叶片中提取总RNA。通过Agilent 2100生物分析仪(Agilent Technologies,USA)检测RNA样品的质量。通过NEBNext Oligo(dT)25珠(NEB,USA)从50 μL总RNA中富集Poly(A)mRNA。然后按照说明书,通过用于Illumina的NEBNext Ultra RNA文库制备试剂盒(NEB,USA)将富集的mRNA构建成cDNA文库。
1.2.2Illumina测序 将提取的总RNA样品直接送往广州基迪奥生物科技有限公司使用Illumina HiSeq 4000测序平台进行转录组测序。测序得到的原始图像数据先将base calling转化为序列数据,同时过滤数据中这些杂质Raw reads,从而得到Clean reads。
1.2.3denovo组装和Unigenes注释 由于以前没有获得紫花苜蓿基因组信息,因此使用参考基因组独立的Trinity方法[11]进行denovo组装得到Unigenes。使用BLASTx程序(http://www.ncbi.nlm.nih.gov/BLAST/)将Unigenes序列比对到蛋白数据库Nr (http://www.ncbi.nlm.nih.gov)、Swissprot (http://www.expasy.ch/sprot)、KEGG(http:// www.genome.jp/kegg)和KOG (http://www.genome.jp/kegg/ko.html),其E值阈值为1×10-5。根据最佳比对结果获得蛋白质功能注释。
1.2.4差异表达基因的选择 测序后的基因使用Reads per kilobase per million mapped reads(RPKM)法计算基因表达量[12]。使用edgeR软件包(http://www.r-project.org/)来选择品种间的差异基因。差异表达倍数≥2倍的基因被认定是差异基因[13]。对筛选出的差异表达基因进行GO功能富集分析和KEGG途径分析。根据Nr注释信息,使用BLAST2GO[14]将苜蓿叶片转录本进行功能分类,得到Unigene的GO注释信息。得到每个Unigene的GO注释后,用WEGO软件[15]对所有Unigene做GO功能分类统计。基于KEGG途径分析有助于更进一步了解基因的生物学功能。
1.2.5营养指标测定方法 粗蛋白(crude protein,CP)、中性洗涤纤维(neutral detergent fibre,NDF)、酸性洗涤纤维(acid detergent fiber,ADF)按照《饲料分析及饲料质量检测技术》测定[16]。
1.3 数据处理方法
利用 Microsoft Office Excel 2007 软件进行图、表和数据的前期处理,利用SAS 9.1.3(statistical analysis system)软件进行数据计算及方差分析。
2 结果与分析
2.1 不同品种营养品质比较
如表1所示,苜蓿品种对各营养指标含量的影响较大,WL319HQ苜蓿的粗蛋白(CP)含量显著高于准格尔苜蓿(P<0.05),而中性洗涤纤维(NDF)和酸性洗涤纤维(ADF)含量显著低于准格尔苜蓿(P<0.05)。
2.2 测序和组装
如表2所示,为了比较2个紫花苜蓿品种的差异基因,取2个紫花苜蓿品种的初花期叶片,产生了6个DGE文库,具有3个生物学重复。使用HiSeq 4000对所有文库进行测序,得到约39G的总的核苷酸, 2亿多个reads。 其中每个DGE文库得到约6.5G的核苷酸,约4300万个reads,其中质量不低于20的碱基的比例(Q20)均超过了96%,不能测序的核苷酸“N”的百分比为0,碱基G和C数占总碱基数的百分比大于42%。通过Trinity组装得到66734个Unigenes,平均长度为869 bp。
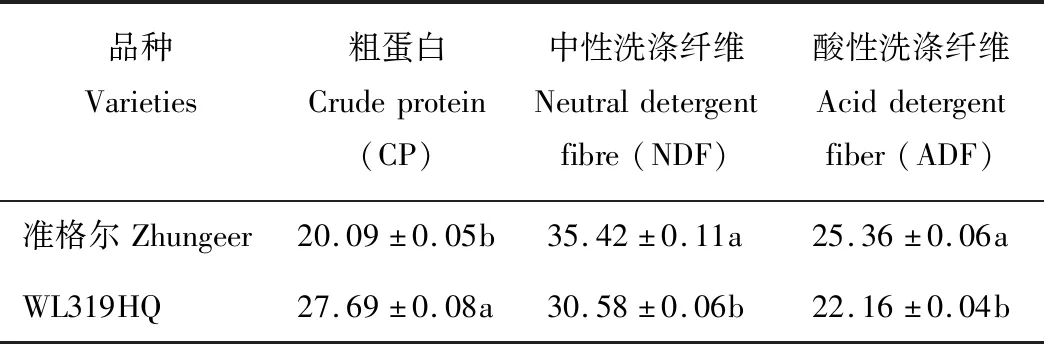
表1 2个苜蓿品种叶片营养品质比较Table 1 Comparison of nutritional quality of leaves of two alfalfa varieties (DM%)
注:同列不同小写字母表示差异显著(P<0.05)。
Note: Different lowercase letters within the same column indicate significant different at 0.05 level.
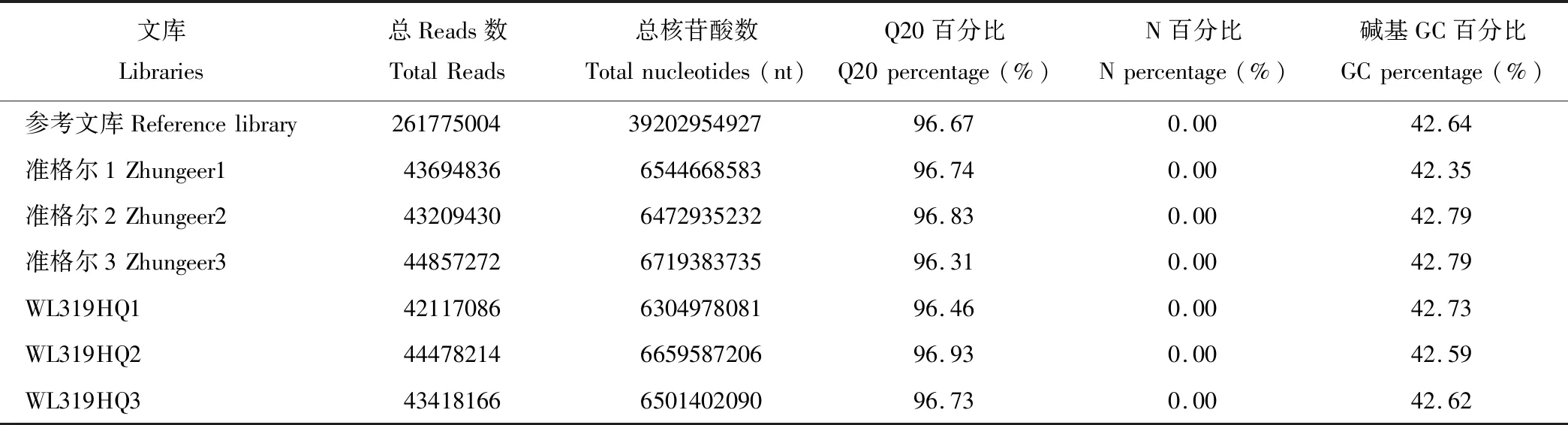
表2 不同苜蓿品种样品测序数据统计结果Table 2 Statistics of sequencing data of the different alfalfa varieties samples
2.3 de novo组装结果的评估分析
如表3所示,总共有26474,24230和28904个Unigenes分别匹配到鹰嘴豆(Cicerarietinum),大豆(Glycinemax),蒺藜苜蓿(Medicagotruncatula)和紫花苜蓿的直系同源编码序列。其中有590(2.23%),457(1.89%)和343(1.19%)个Unigenes的长度分别与鹰嘴豆,大豆和蒺藜苜蓿的同源基因相等(ratio=1);有3001(11.34%),3317(13.69%)和2785(9.64%)个Unigenes的长度分别小于鹰嘴豆,大豆和蒺藜苜蓿的同源基因(ratio<1);有22883(86.43%),20456(84.42%)和25776(89.17%)个Unigenes的长度分别大于鹰嘴豆,大豆和蒺藜苜蓿的同源基因(ratio>1)。如表4所示,9636(58.71%)个鹰嘴豆同源基因,6382(34.68%)个大豆同源基因和8195(49.06%)个蒺藜苜蓿同源基因可以被Unigenes覆盖,覆盖率大于80%;覆盖百分比为50%~80%的3367(20.52%)个鹰嘴豆同源基因,4810(26.13%)个大豆同源基因和2969(17.77%)个蒺藜苜蓿同源基因被Unigenes覆盖;另外有2085(12.71%)个鹰嘴豆同源基因,3779(20.53%)个大豆同源基因和3330(19.93%)个蒺藜苜蓿同源基因能够被Unigenes覆盖,覆盖百分比为20%~50%;此外有1322(8.06%)个鹰嘴豆同源基因,3434(18.66%)个大豆同源基因和2785(13.24%)个蒺藜苜蓿同源基因仅被20%的Unigenes覆盖。

表3 Unigene长度/直系同源物长度的比率Table 3 Ratio of Unigene length/ortholog length

表4 Unigene/ortholog覆盖百分比Table 4 Cover percentage of Unigene/ortholog
2.4 基因注释结果分析
如表5所示,总共有45657(68.42%)条Unigenes被注释到,而有21077(31.58%)条Unigenes没有被注释。对于Nr数据库,通过BLASTx注释到44888(67.26%)条Unigenes,对于Swissprot,KOG和KEGG数据库分别注释到29190(43.74%),24844(37.23%)和15647(23.45%)条Unigenes。有11690条Unigenes被同时注释到4个蛋白数据库,有47条Unigenes只注释到KEGG数据库,40条Unigenes单独注释到KOG数据库,12156条Unigenes单独注释到Nr数据库,有287条Unigenes单独注释到Swissprot数据库(图1)。
2.5 差异基因的筛选
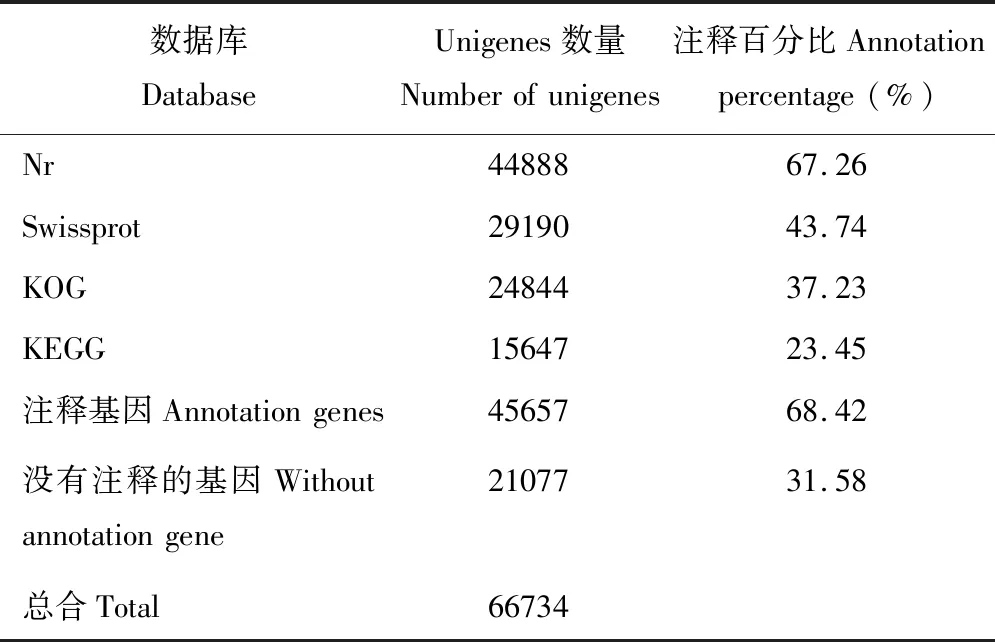
表5 基因注释结果统计Table 5 Statistics of gene annotation results
通过对2个不同紫花苜蓿品种的基因测序, 在错误发现率(false discovery rate,FDR)<0.05 且 |log2 fold change (FC)|>1的筛选条件下找到2个紫花苜蓿品种的差异表达基因。如图2所示,在2个紫花苜蓿叶片中找到1098个差异基因 (DEGs) ,其中有706个Unigenes上调,392个Unigenes下调(准格尔-vs-WL319HQ)。得到的差异表达基因用于后续分析。
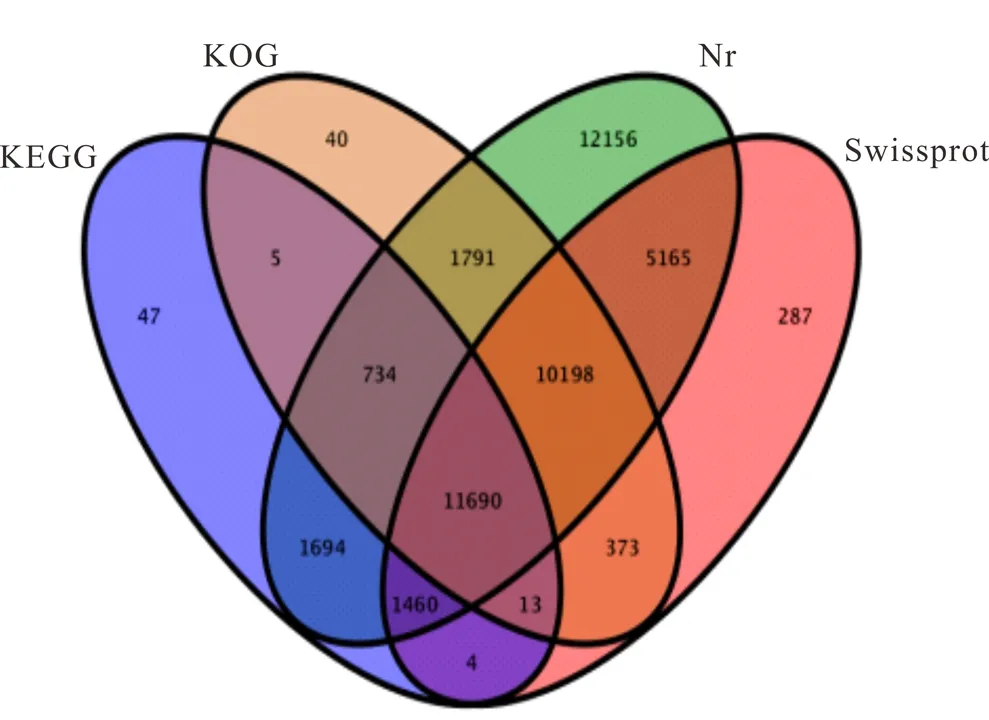
图1 由BLASTx注释的Unigenes数量的维恩图Fig.1 Venn diagram of number of Unigenes annotated by BLASTx
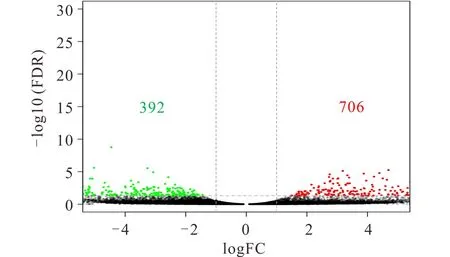
图2 2个紫花苜蓿叶片的差异基因分析火山图 Fig.2 Volcano map of differential gene statistics of 2 alfalfa leaves 横坐标表示两个样品的差异倍数对数值,纵坐标表示两个样品的FDR的负log10值。红色(WL319HQ相对于准格尔表达量上调)和绿色(表达量下调)的点表示基因的表达量有差异(判断标准为 FDR<0.05, 差异倍数两倍以上),黑色的点为没有差异。The abscissa represents the logarithm of the difference multiples of the two samples, and the ordinate represents the negative log10 value of FDR of the two samples. The points of red (WL319HQ is up-regulated relative to Zhungeer) and green (down-regulated) indicate that the expression levels of the genes are difference (the standard is FDR<0.05, the difference multiple is more than twice), while the black points showed no difference.
2.6 GO功能显著性富集分析
如表6所示,通过GO功能注释,在生物过程(biological process)中,“代谢过程”,“细胞过程”,“刺激反应”和“单一生物过程”富集基因相对较多,分别有288,260,174和159个Unigenes。其中“代谢过程”中有195个上调Unigenes和93个下调Unigenes,“细胞过程”中有170个上调Unigenes和90个下调Unigenes,“刺激反应”中有131个上调Unigenes和43个下调Unigenes,“单一生物过程”中的Unigenes有109个上调,50个下调。而“免疫系统过程”和“节律过程”富集的基因较少,只有2个Unigenes。在细胞组分(cellular component)中,大多数基因被注释到“细胞”(210个上调,46个下调),“细胞部分”(210个上调,46个下调)和“细胞器”(156个上调,30个下调)。对于分子功能(molecular function),“结合”(169个上调,97个下调)和“催化活性”(124个上调,99个下调)是富集基因较多的功能类别。
2.7 KEGG途径富集分析
如表7所示,有8414个基因注释到87个代谢通路中, 这些基因中有281个差异基因。其中Unigenes数量注释排名前10的代谢通路分别是:“核糖体”(ko03010),“剪接体”(ko03040),“内质网中的蛋白质加工”(ko04141),“碳代谢”(ko01200),“内吞作用”(ko04141),“氨基酸的生物合成”(ko01230),“RNA转运”(ko03013),“植物-病原互作”(ko04626),“淀粉和蔗糖代谢”(ko00500),“植物激素信号转导”(ko04075)。其中“核糖体”途径注释的DEGs最多,为64 (22.78%),依次为“内质网中的蛋白质加工”(44 个DEGs,占15.66%)、“碳代谢”(22个DEGs,占7.83%)和“剪接体”(19 个DEGs,占6.76%)。
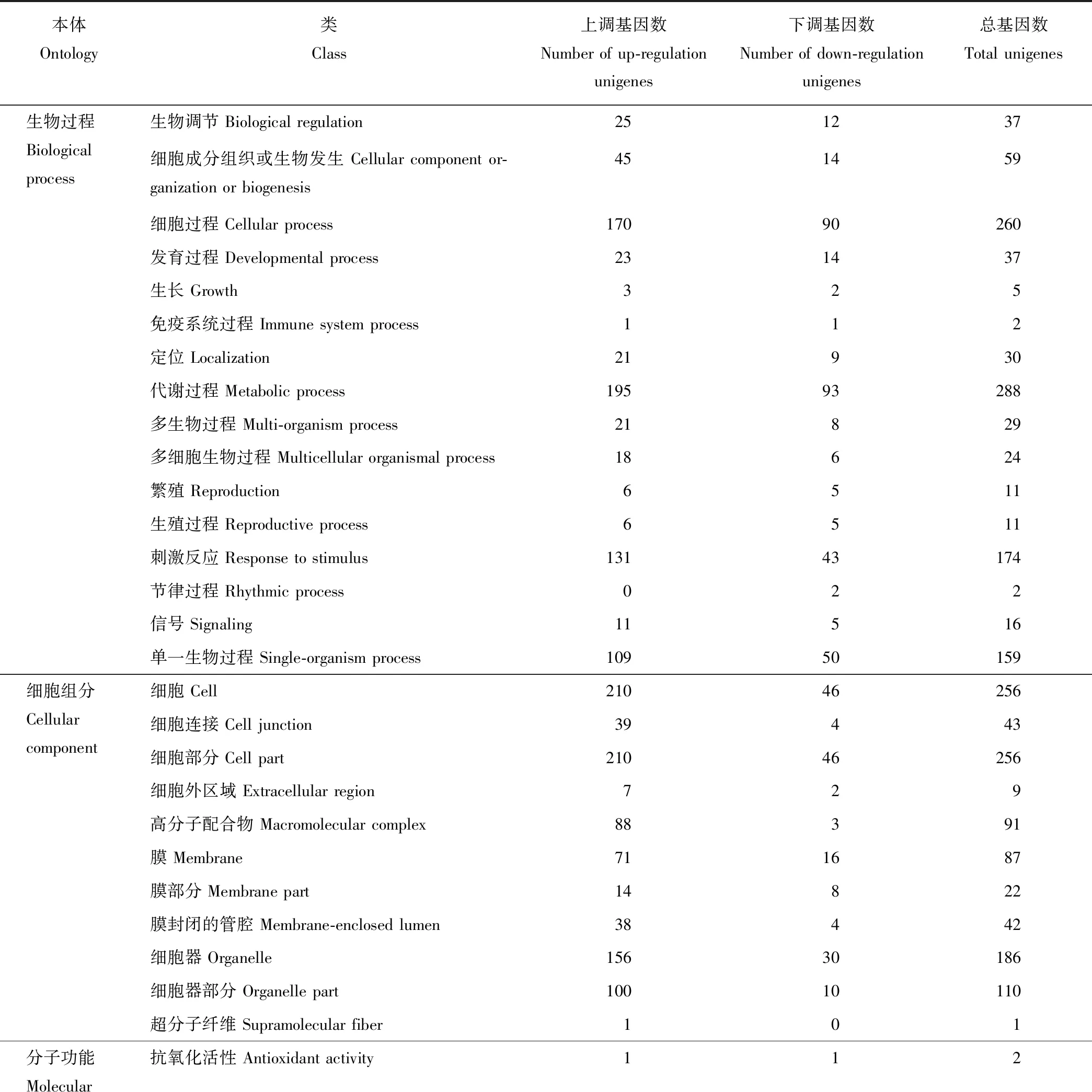
表6 GO功能统计表Table 6 GO functional statistics table

表7 Unigenes 数量排名前10的代谢通路Table 7 Top 10 metabolic pathways involving Unigenes
3 讨论
苜蓿作为国内外优质蛋白质饲草,其适口性和营养价值都很高。而苜蓿原料中粗蛋白(CP)、中性洗涤纤维(NDF)和酸性洗涤纤维(ADF)的含量多少是反映其品质好坏的重要指标,CP含量越高,NDF和ADF含量越低,其饲草品质就越好[17]。在本研究中WL319HQ苜蓿的CP含量显著高于准格尔苜蓿,而NDF和ADF含量显著低于准格尔苜蓿,说明WL319HQ的品质优于准格尔。本研究发现,不同品种紫花苜蓿的营养品质差异显著,该研究结果与赵燕梅等[3]的研究结果一致,造成其营养品质差异可能是因为不同品种的遗传特性差异所导致的,而目前关于从基因和代谢通路层面出发探讨不同苜蓿品种营养品质差异的研究还鲜有报道。因此本研究开展了不同品种紫花苜蓿的转录组测序,想要从基因和代谢通路层面探讨其营养品质差异的内在机理。
转录组测序是在高通量测序技术基础上发展起来的转录组分析技术,其中应用比较广泛的转录组测序平台是Illumines测序平台。Illumina测序技术为研究基因结构和功能提供了强大的技术支持,特别是对于无参考基因组的非模式植物进行的denovo从头测序,可以获得该物种的参考序列,从而为其后续的基因研究提供理论基础。目前关于利用Illumina法对没有参考基因组物种进行转录组测序的研究较多,其中包括速生桉(Eucalyptusrobustasmith)[18]、甘薯(Dioscoreaesculenta)[19]、胡萝卜(Daucuscarota)[20]和胡黄连(Picrorhizascrophulariiflora)[21]等。本试验利用高通量测序平台Illumina HiSeq 4000对2个紫花苜蓿品种(无参考基因组)叶片进行转录组分析。基于denovo组装,总共获得66734条Unigenes,平均长度为869 bp,本研究得到的Unigenes数量明显高于刘希强等[22]关于紫花苜蓿转录组测序的研究结果(41734条Unigenes),而低于张森浩[23]的研究结果(192875条Unigenes)。造成这种差异的原因可能是品种和生长环境的不同。本研究获得的紫花苜蓿Unigenes平均长度明显高于鹅掌楸(Liriodendronchinensis)(537 bp)[24]、短丝木犀(Osmanthusserrulatus)(697 bp)[25]和桂花(Osmanthus)(708 bp)[26]等,与火力楠(Micheliamacclurei)(852 bp)[27]和青叶胆(Herbaswertiaemileensis)(901 bp)[28]等相近。总体来讲,本研究得到的转录本和Unigenes长度与已有的紫花苜蓿转录组测序研究结果相似[29-30],说明本研究测序和拼接结果符合预期,其转录组数据可信。在本研究中有些Unigenes不能完全覆盖鹰嘴豆,大豆和蒺藜苜蓿的同源基因的完整编码序列,但是本研究中2个紫花苜蓿品种的Unigenes能够覆盖大部分的同源基因,并且大部分Unigenes长度与鹰嘴豆,大豆和蒺藜苜蓿同源基因长度的比值约等于1,说明本研究的转录组序列质量较好。
将66734条Unigenes序列通过使用BLASTx(评估<10-5),对Nr,Swissprot,KOG和KEGG的4个公开蛋白质数据库进行搜索。从注释的结果中可以发现,45657(68.42%)个Unigenes至少在一个数据库得到注释,大约有11690个Unigenes被同时注释到4个蛋白数据库。其中,Nr数据库注释到的Unigenes数量最多,为44888(67.26%)条,这与邓敏捷等[31]对泡桐树(Paulowniasieb)进行转录组测序的研究结果(65.5%)相似。然而,在本研究中产生了21077条没有被注释的Unigenes,很可能代表着参试种的一个特殊基因群。
目前基于转录组测序平台来研究不同品种紫花苜蓿差异基因的报道很少。本研究利用转录组测序找到了2个紫花苜蓿品种的1098个差异基因 (DEGs),相对于国内品种准格尔而言,国外苜蓿WL319HQ苜蓿中有706个上调基因,392个下调基因。基于序列相似性,将1098个DEGs分配给生物过程(biological process)、细胞组分(cellular component)和分子功能(molecular function)的一个或多个本体。在生物过程中,“代谢过程”(288个Unigenes)和“细胞过程”(260个Unigenes)富集的Unigenes占主体地位,这与张雪松等[32]的研究结果一致。而“免疫系统过程”(2个Unigenes)和“节律过程”(2个Unigenes)富集的基因较少。在细胞组分中,大多数基因被注释到“细胞”(256个Unigenes),“细胞部分”(256个Unigenes)和“细胞器”(186个Unigenes)。对于分子功能,“结合”(266个Unigenes)和“催化活性”(223个Unigenes)是富集基因较多的功能类别。
KEGG数据库是全面研究基因产物在细胞中的代谢途径和研究基因产物的功能的数据库,基于KEGG的代谢途径的分析有助于更进一步了解基因的生物学功能[32]。在本研究中,有8414个基因注释到87个代谢通路中,这些基因中有281个差异基因。其中Unigenes 数量注释较多的途径是“核糖体”(622个Unigenes,64个DEGs),“剪接体”(562个Unigenes,19个DEGs),“内质网中的蛋白质加工”(550个Unigenes,44个DEGs),“碳代谢”(484个Unigenes,22个DEGs)。粗蛋白质(CP)是常规饲料分析中用以估计饲料、动物组织或动物排泄物中一切含氮物质的指标,它包括了真蛋白质和非蛋白质含氮物(non-protein nitrogen, NPN)两部分。NPN包括游离氨基酸、硝酸盐、氨等。蛋白质由20种氨基酸组成,其生物合成可分为5个阶段:氨基酸的活化、多肽链合成的起始、肽链的延长、肽链的终止和释放、蛋白质合成后的加工修饰。其合成场所为核糖体,在本研究中“核糖体”代谢途径的注释基因最多,其差异基因也是最多,这可能是导致参试品种蛋白差异的主要原因之一。而“剪接体”、“内质网中的蛋白质加工”和“碳代谢”途径也是直接或者间接影响蛋白质合成的代谢途径,因此,有可能是这些代谢途径的差异,导致这2个品种紫花苜蓿的蛋白质含量差异。不同的组织细胞具有不同的生理功能,是因为它们表达不同的基因,产生具有特殊功能的蛋白质,参与蛋白质生物合成的成份至少有200种,其主要体是由mRNA、tRNA、核糖核蛋白体以及有关的酶和蛋白质因子共同组成。因此蛋白质的合成与转化是一个极其复杂的过程,是多个代谢途径和多个基因联合作用的,因此关于不同品种苜蓿粗蛋白质含量差异的原因有待更加深入的研究。在本研究中,有294个基因注释到“植物激素信号转导”(ko04075)代谢途径,其中有6个差异基因。而“植物激素信号转导”代谢途径主要是控制植物激素的合成和转化。植物激素在植物的生长发育过程中起到至关重要的作用,植物的生长发育伴随着细胞的分裂和分化,从而导致植物细胞壁组分和含量也伴随着变化[33]。植物细胞壁的主要组成成分是纤维素、半纤维素、木质素和果胶。因此,“植物激素信号转导”代谢途径间接地影响着中性洗涤纤维(NDF)和酸性洗涤纤维(ADF)的合成,这可能是导致本研究中2个紫花苜蓿品种的NDF和ADF含量差异的重要原因之一。本研究从基因和代谢通路层面初步探讨出导致2个苜蓿品种营养品质差异的内在原因,然而具体的营养指标差异的内在机理有待进一步深入研究和验证。
4 结论
本研究通过Illumina HiSeq 4000平台,首次利用RNA-seq技术研究了不同紫花苜蓿品种(准格尔、WL319HQ)的差异表达基因,初步建立了它们的基因表达谱。在2个紫花苜蓿品种中找到1098个差异基因 (DEGs) ,其中有706个Unigenes上调,392个Unigenes下调(准格尔-vs-WL319HQ)。对其差异基因进行GO功能分析和KEGG途径分析,初步分析了2个品种营养品质差异的内在原因。本研究极大地丰富了紫花苜蓿转录组数据信息,为今后紫花苜蓿的转录组测序提供理论依据,同时为紫花苜蓿生产实践提供参考。
猜你喜欢
汉字汉语研究(2021年2期)2021-08-30
现代畜牧科技(2021年4期)2021-07-21
心电与循环(2020年1期)2020-02-27
汉字汉语研究(2019年2期)2019-08-27
作文小学高年级(2019年1期)2019-02-18
新高考·英语进阶(高二高三)(2018年8期)2018-01-15
中国三峡(2017年4期)2017-06-06
江苏农业科学(2017年5期)2017-04-15
为了孩子(3~7岁)(2016年6期)2016-05-14
河北书画研究(2016年3期)2016-04-28
