
面向概念漂移问题的渐进多核学习方法
2019-10-31 09:21白东颖易亚星王庆超余志勇
计算机应用 2019年9期
关键词:支持向量机
白东颖 易亚星 王庆超 余志勇


摘 要:针对概念漂移问题,构建数据特性随时间发生渐进变化特点的分类学习模型,提出一种基于渐进支持向量机(G-SVM)的渐进多核学习方法(G-MKL)。该方法采用支持向量机(SVM)为基本分类器,进行多区间上的子分类器耦合训练,并通过约束子分类器增量方式使模型适应数据渐进变化特性,最终将多个核函数以线性组合方式融入SVM求解框架。该方法综合发挥了各个核函数的优势,大大提高了模型适应性和有效性。最后在具有漸变特性的模拟数据集和真实数据集上将所提算法与多种经典算法进行了对比,验证了所提算法在处理非静态数据问题的有效性。
关键词:概念漂移;支持向量机;多核学习;子分类器;KKT条件
中图分类号:TP311
文献标志码:A
Gradual multi-kernel learning method for concept drift
BAI Dongying1,2, YI Yaxing1*, WANG Qingchao1, YU Zhiyong1
1.Institute of Combat and Support. Xian Institute of High-Tech, Xian Shaanxi 710025, China;
2.Institute of Air and Missile Defense, Air Force Engineering University, Xian Shaanxi 710051, China
Abstract:
Aiming at the concept drift problem, a classification learning model with the characteristics of data changing progressively over time was constructed, and a Gradual Multiple Kenerl Learning method (G-MKL) based on Gradual Support Vector Machine (G-SVM) was proposed. In this method, with Support Vector Machine (SVM) used as the basic classifier, multi-interval sub-classifier coupling training was carried out and the incremental method of constraining sub-classifier was used to adapt the model to the gradual change of data. Finally, multiple kernels were integrated into SVM solution framework in a linear combination manner. This method integrated the advantages of different kernel functions and greatly improved the adaptability and validity of the model. Finally, the comparison experiments between the proposed algorithm and several classical algorithms were carried out on the simulated and real datasets with gradual characteristics, verifying the effectiveness of the proposed algorithm in dealing with non-stationary data problems.
Key words:
concept drift; Support Vector Machine (SVM); multi-kernel learning; sub-classifier; Karush-Kuhn-Tucher (KKT) condition
0 引言
概念漂移问题[1-3]大致可以分为两类:一种是数据的某种特征或分布方式发生突然变化从而导致数据分类模型的突然变化问题;另一种则是数据分布发生着逐渐而又缓慢的变化[4],本文的研究内容为渐变性的概念漂移问题。
对渐变数据进行分类的重点在于分类模型不仅要在每一特定时间内对现有数据达到最优,而且要使得分类模型能够平稳递进地变化。这是由于数据分布的稀疏性决定的,在较短的时间片段内获取的少量数据通常不足以建立可靠的模型,反而非常容易使得模型过拟合,因此需要合理利用时间相近的数据为当前时刻构建分类模型[5-6]。
Grinblat等[7]提出时间自适应支持向量机(Time Adaptive Support Vector Machine, TA-SVM),将数据按照时间顺序划分为若干区间,并在不同区间上求解子分类器;其最大的特点在于子分类器间的耦合,即不仅要使子分类器在相应区间内尽量达到最优,而且将相邻子分类器间的变化在目标函数中进行了约束,从而使得分类器能够较好地平衡分类模型在不同时间区间的全局优化和局部优化。
虽然TA-SVM方法可以通过子分类器耦合的方式处理渐变式的概念漂移问题,然而其求解过程并不简单,并且其中涉及到求矩阵的逆和伪逆等问题。Shi等[8]在TA-SVM的基础上提出改进的时间自适应支持向量机(Improved TA-SVM, ITA-SVM),使用增量的概念表示相邻分类器间的变化,将基础分类器与增量序列结合构成各个子分类器。虽然ITA-SVM解决了TA-SVM难以求解的问题,但是ITA-SVM本质是一种核心向量机模型,虽然易于优化,但是在有效性上与支持向量机有一定差距。
为此本文提出了基于渐进支持向量机(Gradual Support Vector Machine,G-SVM)的渐进多核学习方法(Gradual Multiple Kernel Learning, G-MKL),以支持向量机为基本分类器,通过子分类器耦合的方式处理渐变式的概念漂移问题,通过分类器增量的方式使得模型适应数据特性的渐进变化,通过将分类器学习和多核自适应优化置于统一的优化框架,在一组基核上充分发挥各个核的优势,得出最优的组合方式,进一步提高模型的适应性和有效性。
根据上述推导过程,多核渐进支持向量机模型(G-MKL)训练阶段的计算流程可描述为:
步骤1 将按照时间排序的样本序列{x1,x2,…,xN}划分为L个子区间。
步骤2 计算核矩阵K和样本间关系矩阵G。
步骤3 初始化核权值θm=1/m,m。
步骤4 使用序列最小化(Sequential Minimal Optimization, SMO)算法解式(13)所示的QP问题。
步骤5 使用式(24)更新核权重。
步骤6 判断是否满足迭代停止条件,若满足,则训练结束;若不满足,重复步骤4~6,直到满足停止条件。
2 实验与结果分析
为评估本文所提多核渐进支持向量机模型的有效性和可行性,通过实验的方式进行比较分析。实验选择ITA-SVM[8],TA-SVM[10]和G-SVM算法作为基准算法进行对比。实验使用Matlab 2012a作為编程环境,使用SMO算法解SVM。本章的实验内容安排如下:首先在使用人工数据集模拟数据分布模型随时间逐渐变化的情况,在模拟数据集上分析算法跟随数据变化的能力,然后在真实数据集上进行对比分析。
2.1 模拟数据集实验与结果分析
为验证本文所提出渐进支持向量机和渐进多核学习方法在概念漂移问题处理上的有效性,按照和文献[8,10]相同的方法构造了两个人工数据集,以模拟现实世界中数据分布模型随时间变化的情形。两个数据集分别命名为Sliding和Rotating。
数据集Sliding是一个两分类数据集,数据包含两个维度。两个类别的样本都服从高斯分布,并沿着一个二维空间上的正弦函数缓慢漂移,样本点根据式(28)生成:
xi=2πin-π+0.2yi+ε1,sin2πin-π+0.2yi+ε2(28)
其中i=1,2,…,N(N为样本数量);ε1和ε2都取自于均值为0,方差为0.1的正态分布;yi∈{-1,+1}为样本xi的标签。图1所示为数据集Sliding在时刻t(i∈[1,t])分别为25,175,325,475时样本分布情况。其中t时刻最近产生的25个样本使用实心点标记。
Sliding的两类样本在每一较短的时间段内基本上是可分的。但是随着时间的变化,两类样本沿着正弦曲线不断漂移,从整体上看两类样本混淆在一起难以分辨。由于这个数据集具有如此特点,因此也常用来模拟概念漂移问题验证算法对于非静态数据处理的能力。
数据集Rotating是一个旋转数据集,模拟的是正负两类样本的分界面以原点为中心,沿逆时针旋转的情况下的数据分布。两类样本的分界面法向量定义为v,v的变化情况可以用式(29)表示:
v1(t)=cos(2πt/n)10
v2(t)=sin(2πt/n)
v3,4,…,d(t)=0(29)
样本xi的每一维度均服从[-1,1]上的均匀分布,其所属类别为yi=sign(xiv(ti))。在实际实验中每一时刻只生成一个样本点,与文献[8]相同。
按照上面描述的数据产生方式,分别为两个数据集生成数据。按照相同的方式分别产生三组数据,其中第一组为训练集,用于模型训练;第二组为校验集,用于参数选择;第三组为测试集,用于评估算法。为了能更加深入地评估渐进支持
向量机和渐进多核学习算法的优劣,实验共分两步。首先在
校验集上训练模型以检验模型中新增参数对算法的性能的影响,然后使用优化后的参数训练分类模型,使用训练好的决策函数在测试集上对算法的性能进行对比分析。
惩罚因子C∈{0.1,1,10,100,1000},通过交叉验证的方式选择最优参数C。单核支持向量机模型分别使用线性核和高斯核,高斯核宽度通过交叉验证的方式从{0.01,0.1,1,5,10,20,50,100}选择最优值,多核方法G-MKL同时使用线性核,一阶多项式核以及高斯核进行训练,高斯核的宽度σ∈{0.01,0.1,1,5,10,20,50,100},因此共计10个核。
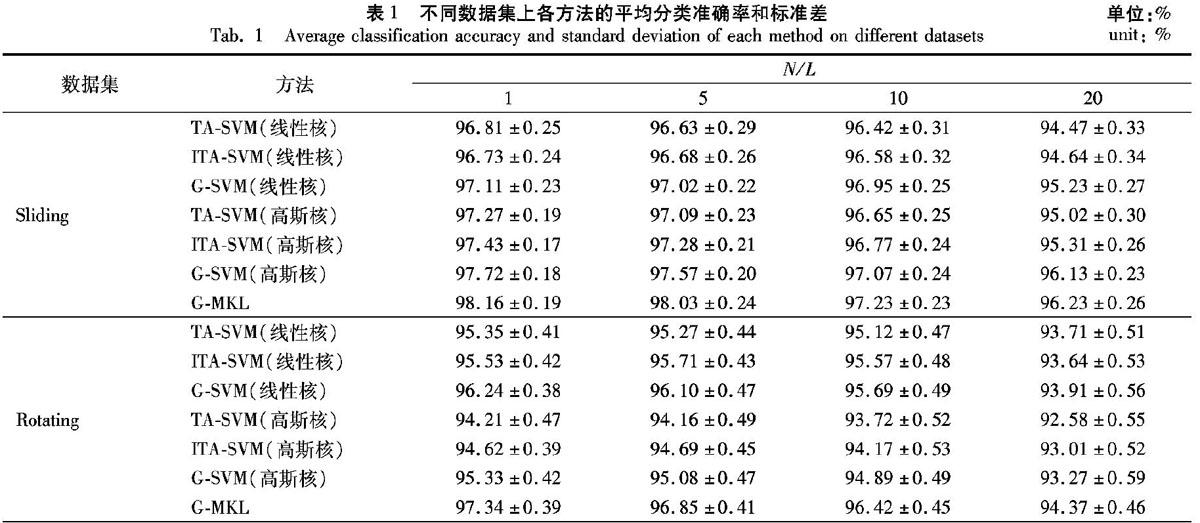
在本节实验中将本文算法与TA-SVM、ITA-SVM、G-SVM在两个数据集上进行对比以评估本文G-MKL的分类效果。因数据生成得较为稀疏,故具有较大的随机性,需要多次实验取平均值。实验过程参照文献[15]的方式进行,首先按照式(24)和式(25)的模型分别生成训练集、校验集以及测试集各100组。将训练集分为L个数据子集,使用训练集和校验集选择该数据集上最优的C,λ和σ。在训练集上训练模型,在测试集上验证模型,重复100次实验取平均值。表1分别记录了不同算法在Sliding数据集和Rotating数据集上的平均分类准确率和标准差。
根据表1可以看出无论使用线性核还是使用高斯核,G-SVM算法的分类准确率均高于TA-SVM和ITA-SVM算法,体现了它在数据分布模型发生变化时可以更好地拟合数据,通过全局优化和局部优化方式学习到良好的分类分界线;而其多核方式G-MKL则在分类准确率上有进一步的提高,体现了本文多核学习方法在优化多核上的优势。
2.2 真实数据集实验与结果分析
1)Spam_corpus數据集
Spam_corpus数据集为垃圾邮件数据集,记录了大约为期18个月发送给指定地址的邮件语料,包含9324个样本。在Spam_corpus数据集中,随着时间推移垃圾邮件的语料特征也随之逐渐变化,因此该数据集是一个常用于检验概念漂移问题的数据集。实验方式与文献[8]相同,按照时间关系将数据等分为36组,每组包含259个样本。每组样本中随机选取一半作为训练集,另外一半作为测试集,在训练集上通过交叉验证的选择各方法的模型参数。使用训练好的模型在测试集上进行测试,实验结果如表2和表3所示。
从表3可以看出ITA-SVM算法在所有月份中共有5次达到最佳,G-SVM和本文所提的G-MKL则分别有5次和8次达到最佳,总体来看四种算法的预测准确率相差不是特别大。
表3记录了在所有月份的平均预测错误率。从表中可以看出,TA-SVM算法错误率略高于其他三种算法,ITA-SVM在预测错误率上较之略有降低,本文的多核学习方法G-MKL表现最优,通常情况下错误率低于其他三种算法,体现了多核组合学习的优势。
3 结语
本文研究了非静态数据的分类问题,提出了渐进多核学习方法。通过将数据划分为若干子数据集,在约束子分类器间的变化的同时优化各子分类器,实现分类模型随数据分布逐渐变化,使用多个核函数进行数据度量,并将多核线性组合的方式求解融入支持向量机求解框架,充分发挥各个核函数的优势。在模拟数据集和真实数据集上的实验结果验证了本文提出的算法在处理概念漂移问题时的有效性。
参考文献
[1]LIOBAITE I, PECHENIZKIY M, GAMA J. An overview of concept drift applications[M]// JAPKOWICZ N, STEFANOWSKI J. Big Data Analysis: New Algorithms for a New Society, SBD 16. Berlin: Springer, 2016: 91-114.
[2]孙宇.针对含有概念漂移问题的增量学习算法研究[D].合肥:中国科学技术大学,2017:12-18.(SUN Y. Research on incremental learning algorithms for conceptual drift problem [D]. Hefei: University of Science and Technology of China, 2017: 12-18).
[3]HEWAHI N M, KOHAIL S N. Learning concept drift using adaptive training set formation strategy [J]. International Journal of Technology Diffusion, 2013, 4(1):33-55.
[4]ALIPPI C, BORACCHI G, ROVERI M. An effective just-in-time adaptive classifier for gradual concept drifts[C] // Proceedings of the 2011 International Joint Conference on Neural Networks. Piscataway, NJ: IEEE, 2011: 1675-1682.
[5]史荧中.耦合的支持向量学习方法及应用研究[D].无锡:江南大学,2016:89-106.(SHI Y Z. Study on coupled supported vector method and its application [D]. Wuxi: Jiangnan University, 2016: 89-106.)
[6]PALIVELA H, KUBAL D, NIRMALA C R. Multiple kernel learning techniques for ligand based virtual screening [C]// Proceedings of the 2017 International Conference on Computer Communication and Informatics. Piscataway, NJ: IEEE, 2017: 1-6.
[7]GRINBLAT G L, UZAL L C, CECCATTO H A, et al. Solving nonstationary classification problems with coupled support vector machines [J]. IEEE Transactions on Neural Networks, 2011, 22(1): 37-51.
[8]SHI Y, CHUNG F, WANG S. An improved TA-SVM method without matrix inversion and its fast implementation for nonstationary datasets [J]. IEEE Transactions on Neural Networks and Learning Systems, 2015, 26(9): 2005-2018.
[9]汪洪桥,孙富春,蔡艳宁,等.多核学习方法[J].自动化学报,2010,36(8):1037-1050.(WANG H Q, SUN F C, CAI Y N, et al. On multiple kernel learning methods [J]. Acta Automatica Sinica, 2010, 36(8): 1037-1050.)
[10]GNEN M, ALPAYDIN E. Multiple kernel learning algorithms [J]. Journal of Machine Learning Research, 2011, 12: 2211-2268.
GNEN M, ALPAYDIN E. Multiple kernel learning algorithms [EB/OL]. [2018-12-21]. http://delivery.acm.org/10.1145/2030000/2021071/p2211-gonen.pdf?ip=171.221.175.194&id=2021071&acc=OPEN&key=4D4702B0C3E38B35%2E4D4702B0C3E38B35%2E4D4702B0C3E38B35%2E6D218144511F3437&__acm__=1562746429_892bd32fdc36440e5615efc0f82c56b2.
[11]MANOGARAN G, VARATHARAJAN R, PRIYAN M K. Hybrid recommendation system for heart disease diagnosis based on multiple kernel learning with adaptive neuro-fuzzy inference system [J]. Multimedia Tools and Applications, 2018, 77(4): 4379-4399.
[12]MARCINIAK M, AREVALO H, TFELT-HANSEN J, et al. A multiple kernel learning framework to investigate the relationship between ventricular fibrillation and first myocardial infarction [C]// Proceedings of the 2017 International Conference on Functional Imaging and Modeling of the Heart, LNCS 10263. Berlin: Springer, 2017: 161-171.
[13]LIU T, JIN X, GU Y. Sparse multiple kernel learning for hyperspectral image classification using spatial-spectral features [C]// Proceedings of the 6th International Conference on Instrumentation and Measurement, Computer, Communication and Control. Piscataway, NJ: IEEE, 2016: 614-618.
[14]VAPNIK V N. The Nature of Statistical Learning Theory[M]. New York: Springer, 1995: 24-30.
[15]HAN Y, YANG K, YANG Y, et al. Localized multiple kernel learning with dynamical clustering and matrix regularization [J]. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(6): 486-499.
This work is partially supported by the National Natural Science Foundation of China for Young Scholars (61806219).
BAI Dongying, born in 1982, M. S., lecturer. Her research interests include intelligent information processing, integrated command and control.
YI Yaxing, born in 1966, Ph. D., professor. His research interests include system modeling and simulation.
WANG Qingchao, born in 1988, Ph. D., lecturer. His research interests include remote sensing image analysis.
YU Zhiyong, born in 1972, Ph. D., professor. His research interests include electromagnetic compatibility.
猜你喜欢
现代电子技术(2016年23期)2017-01-12
现代电子技术(2016年23期)2017-01-12
无线互联科技(2016年13期)2017-01-10
中国水运(2016年11期)2017-01-04
软件导刊(2016年11期)2016-12-22
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
价值工程(2016年29期)2016-11-14
科学与财富(2016年28期)2016-10-14
考试周刊(2016年53期)2016-07-15
