基于随机森林的LPG价格预测方法
2019-11-06 03:03
数据与计算发展前沿 2019年3期
1.中国科学院计算机网络信息中心,北京 100190
2.中国科学院大学,北京 100049
引言
目前我国沿海发达地区液化气需求旺盛,国内资源供不应求,液化气进出口贸易活跃,市场竞争激烈。对于各个液化气公司来说,在自有大型存储库建成前,无法对市场价格进行有效预判成为业务突破的一大瓶颈,仅靠认为经验,缺乏信息支撑,液化气进口贸易金额巨大,判断失误将造成巨额损失,操作风险极大。同时液化气价格,特别是进口气价格,涉及国内外原油市场、物流运输、地缘政治等众多影响因素,能够第一时间获取相关信息并进行分析处理,最终通过运算预测价格,显得尤为关键。虽然很多公司借助行业网站开展对国外货源、国际船舶、国内市场等信息进行跟踪收集,人为预测价格,但信息渠道缺乏集成管理,来源分散,过程繁琐,导致信息缺乏时效性,在经营决策中所起的作用相对有限。综上所诉,目前急需开发一套液化气价格预测分析系统,通过收集影响价格变动的主要因素,建立价格预测模型,实现价格预测,为经营管理提供信息化保障和支撑,进而促进进口气业务良好可持续发展。
现在有很多方法被用来预测石油价格,石油价格预测主要采用机器学习,神经网络和时间序列模型三种技术,分别或多种组合进行预测。Neha Sehgal和Krishan K.Pandey 在2014年提出了一种方法,包括两个阶段,称为MI3 算法。该算法被用来确定影响油价的参数,结果证实该算法采用级联神经网络,多层感知神经网络和一般回归神经网络用于预测,取得了与其他传统方法相比更好的效果[1]。2013年,申玄俊等人采用半监督学习方法研究经济因素对石油价格的影响,并利用该方法研究了价格走势的变化算法[2]。Hassan Mohammadi and Lixian Su 用多种 ARIMAGARCH 模型预测从 1996年1月到2009年10月世界范围内的一些石油市场的每周的石油价格,结果显示 ARIMA-GARCH 模型与其它方法对比有更好地效果[3]。I.Haider,S.Kulkarni and H.Pan 提出了一个前馈式人工神经网络,由三层网络组成,用于短期预测石油价格。结果显示即使是含有非线性或噪声的数据,其精度也达到了很高的水平[4]。Edmundo G.de Souza e Silva 等人研究了使用非线性时间序列模型来预测未来石油价格的波动。他们利用隐马尔可夫模型(HMM)发展了一套新的预测方法,用来作为一种分析影响石油的因素的辅助决策机制[5]。
近年来,机器学习算法不断被应用在银行、股市、医疗、电子商务等诸多领域[6,7,8,9],并取得了显著的效果。在众多机器学习模型中,随机森林(RandomForest)[10]的表现尤其突出,迅速成为多种分类回归任务中最流行的框架之一。随机森林算法基于决策树算法,决策树算法计算量小,速度快,并且具有很强的可解释性,比较适合处理有数据不完整的样本,它能够处理不相关的特征,擅长对人,地点,事物的一系列不同特征和性质进行评估。随机森林算法就是构建多颗决策树,由于在每次划分时只考虑一部分的属性,因此它在大型数据库上非常有效,随机森林算法还给出了变量重要性的内在评估,对于不平衡样本分类可以平衡误差,可以计算各实例的亲近度,对于数据挖掘,检测离群点和数据可视化非常有用,但它在某些噪音较大的数据时可能会出现过拟合。基于随机森林的种种特点和在价格预测方面的良好表现,本文选择基于随机森林模型进行液化气价格的预测,最终结果达到良好的准确度和实时性,能够帮助液化气公司进行自我管理,提高其液化气盈利水平。
1 LPG价格预测框架
1.1 问题定义
LPG价格预测主要是借助人工智能技术选择符合LPG行业特点的预测模型,根据影响 LPG价格形成的数据之间存在的本质关联,进行数据拟合,模型训练,模型学习,最终提供 7天、10天、15天等不等周期的价格预测。
1.2 随机森林模型
决策树是一个树结构(其可以是一个二叉树或非叉树)。它的每个非叶节点表示数据的一个特征属性的划分。每个分支表示特征属性在一定范围的值的输出,并且每个叶节点存储类别或输出值。使用决策树决策过程是从根节点开始,测试在输入数据中的对应特征的属性,并根据它们的值选择输出分支,直到叶节点到达,并存储最后的类别或值在叶节点被用作判定结果。
随机森林,顾名思义,是以随机的方式建立的森林。森林是由许多决策树组成的。随机森林的每个决策树之间没有相关性。随机森林形成后,当一个新的输入采样输入时,让林中每个决策树进行单独判断。对于分类模型,其类别被选择最多的一类,就是预测所述样品的类别;对于回归模型,预测结果取所有决策树预测的结果的平均值。图1为随机森林模型图。LPG价格预测的研究属于回归预测问题,随机森林回归的基本思想是:首先利用自助抽样法,每次都有放回地从原始数据集中抽取与原始数据集数量相等的样本,一共抽取 B个样本集;然后对 B个样本集分别构建 B 棵树,得到B个结果;最后,对这 B个结果取平均值得到最终的预测结果。
由上述随机森林算法可得,随机森林的随机性主要体现在如下两方面:(1)bootstrap 抽样产生的样本随机性。关于LPG价格数据,通过 bootstrap 抽样,假设我们得到500个训练集,每个训练集中将近 37%的数据不会出现,训练集之间两两差异很大,由此对数据进行了充分利用;(2)在每个训练集上选择特征的随机性。在每个训练集上每一步进行特征选择时,不同于bagging 选取所有变量的方法,随机森林会根据变量的个数确定选择几个特征。本项目关于LPG价格数据的46个变量中,每一棵树生成时每一步划分我们选择了 7个变量,这 7个变量根据最小均方差计算确定最优的划分变量,生成不剪枝的决策树,依次生成一系列不剪枝决策树,相对于bagging 方法,通过这样的特征选取进一步提高了数据的利用率,从而提高了预测精度。由这两点的随机性决定着随机森林的预测效果。
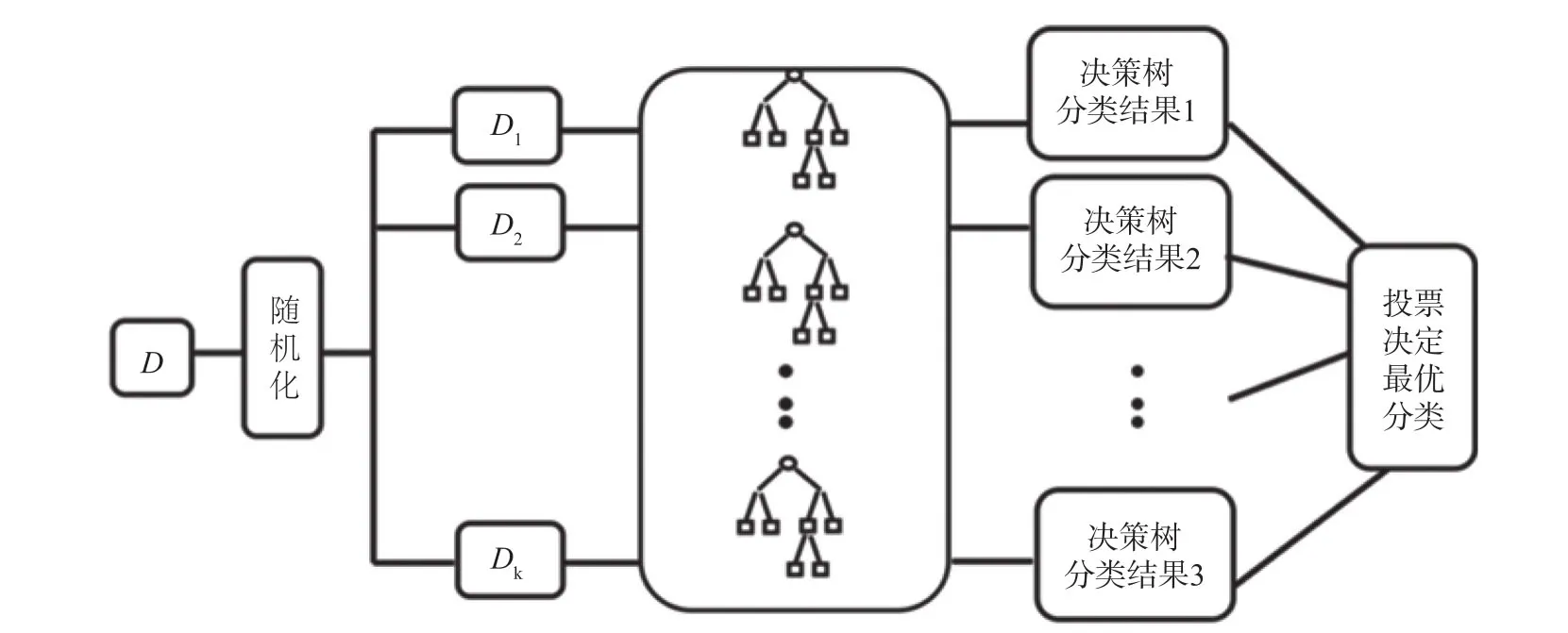
图1 随机森林模型图Fig.1 Random forest model chart
1.3 特征工程
与 LPG价格相关的特征项一共分为国际指标,竞争对手数据和自身历史数据三类。其中国际指标又分为原油价格,cp 指数,进口其成本,现货价格,交易贴水,运费共 20 项,竞争对手数据有 17 项,自身历史数据选取当天和前一周的数据共 8 项,再加上时间序列一共是 46个输入特征项。表1 展示了所有特征项。
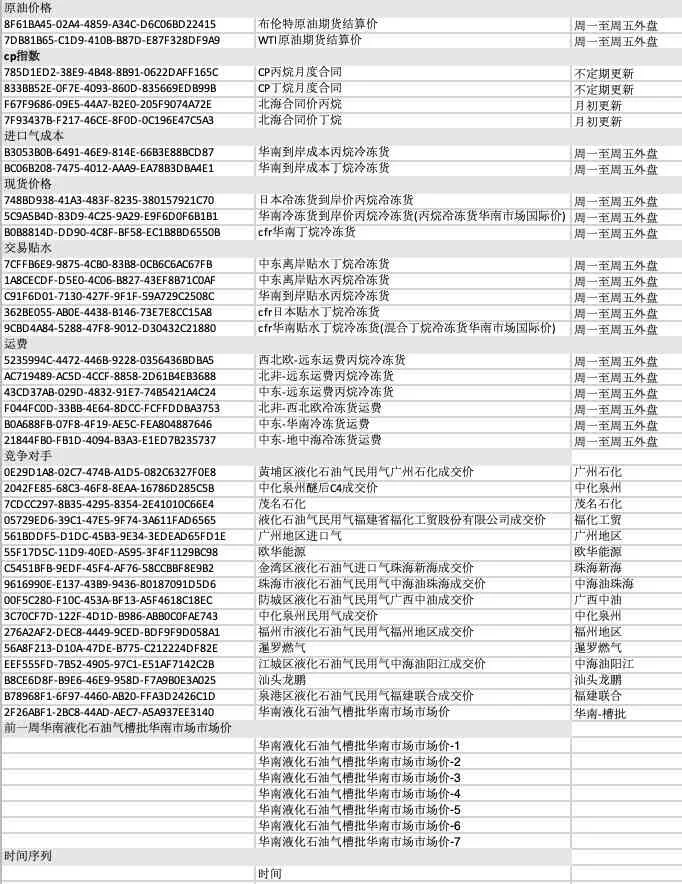
表1 所有输入特征项Table1 All input characteristics
为了更好地学习这些特征与 LPG价格之间的关系,将国际指标,竞争对手数据和自身历史数据三组特征数据分别作为输入特征输入到模型进行训练,再将所有特征数据输入到模型进行训练,通过比较得到的四组测试结果来系统地分析这些特征对 LPG价格的影响和关联度。
1.4 基于随机森林的LPG价格预测
首先输入样本数据集,再进行数据预处理,将缺失的特征值数据填充为0;应用 bootstrap 法有放回地随机抽取 200个新的样本集(bootstrap 每次有放回地抽取与原始数据集等量的数据作为样本集,样本集中存在重复数据),并由此构建 200 棵决策树,每次未被抽到的样本组成了 k个袋外数据(袋外数据用作验证集);样本中有 M个特征变量,在每一棵树的每个节点处随机抽取个变量,然后在个特征中通过最小均方差计算(最小均方差:对于任意划分特征 A,对应的任意划分点 s 两边划分成的数据集D1和D2,求出使D1和D2各自集合的均方差最小,同时D1和D2的均方差之和最小所对应的特征和特征值划分点)确定一个合适的变量,得到相应的分割;每个树生长到最大,而没有任何修整,重复上述步骤,直到最后产生 200个决策树;200个决策树组成随机森林后,新的数据输入由随机森林进行预测,最终的预测值取所有的决策树的平均预测值。
2 实验数据
本实验的实验数据来源于金联创提供的2016年1月- 2019年2月的数据(单位是美元),共 1147条。其中,前 1000条数据划分为训练集,剩下的147条数据划分为测试集。
数据中的原油价格,进口气成本,现货价格,交易贴水和运费是每周一到周五更新;cp 指数是月初更新;竞争对手的数据是每日更新。缺失的数据用零填充。
3 实验结果与分析
3.1 评价指标
在本研究中,采用 MAE(平均绝对误差)作为验证指标,具体的定义如下:
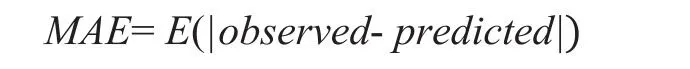
平均绝对误差 MAE 是绝对误差的平均值,在回归模型中,平均绝对误差能更好地反应预测值误差的实际数量情况。
在本实验中,通过预测价格和实际价格的平均绝对误差可以直观地看到模型的预测效果,从而判断结果是否达到预期,也为特征的选取提供了依据。
3.2 实验结果
表2和图2-5 展示了输入四种类型的特征进入随机森林模型进行训练得到的结果,可以看出,输入所有指标数据,输入竞争对手数据和输入历史数据作为输入特征项得到的预测结果基本相同,都是随着预测天数的增加平均绝对误差也越来越大,但在前七天还是达到了不错的预测效果。相反,输入国际指标作为输入特征项训练模型得到的预测结果则随着预测天数的增加平均绝对误差反而在减小,直到稳定在230左右,而且在七天之后的预测结果优于其它三种。说明竞争对手的数据和自身的历史数据与未来短期内的LPG价格在微观上相关度很大,模型可以很好地拟合数据做出相对精确的预测,但从长期宏观来看,LPG价格趋势与国际指标的趋势大体基本保持一致,所以预测未来十天甚至十五天的价格时反而要比预测未来几天的价格更精确。

表2 测试集上的MAETable2 MAE on the test set
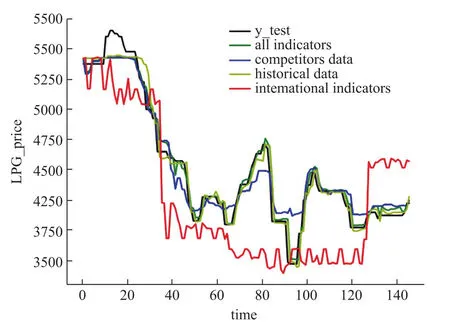
图2 未来第1天的预测结果Fig.2 ResultofpredictingLPGpriceofthe next day
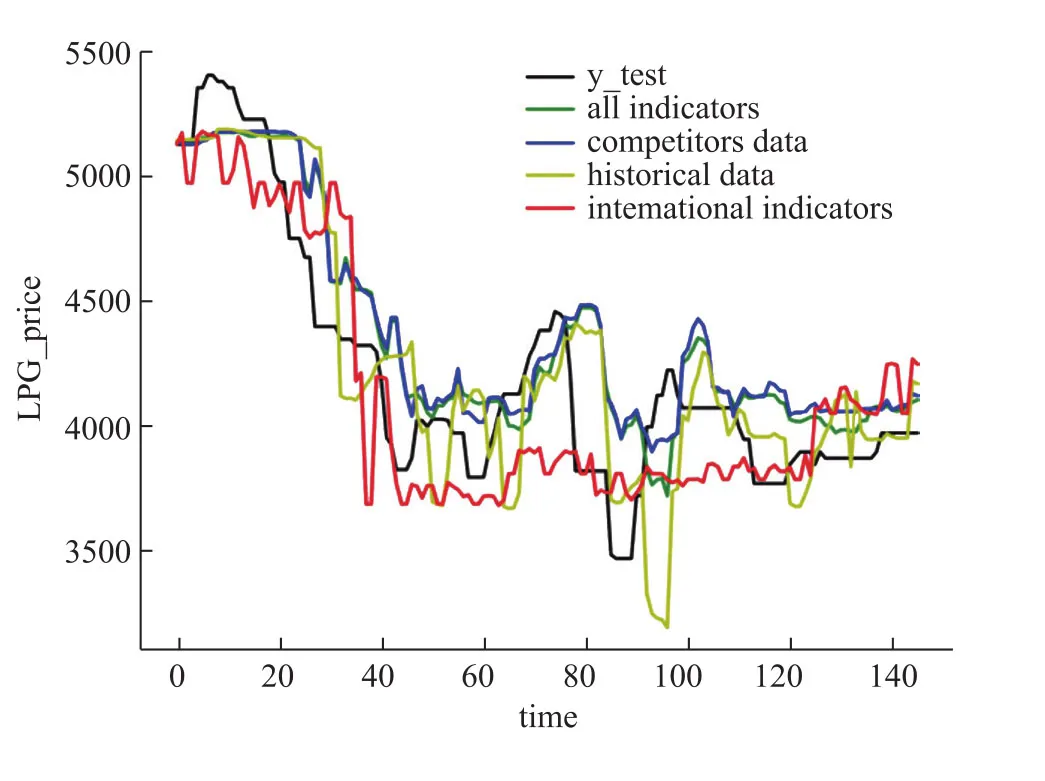
图3 未来第7天的预测结果Fig.3 ResultofpredictingLPGpriceofthe 7th day in the future
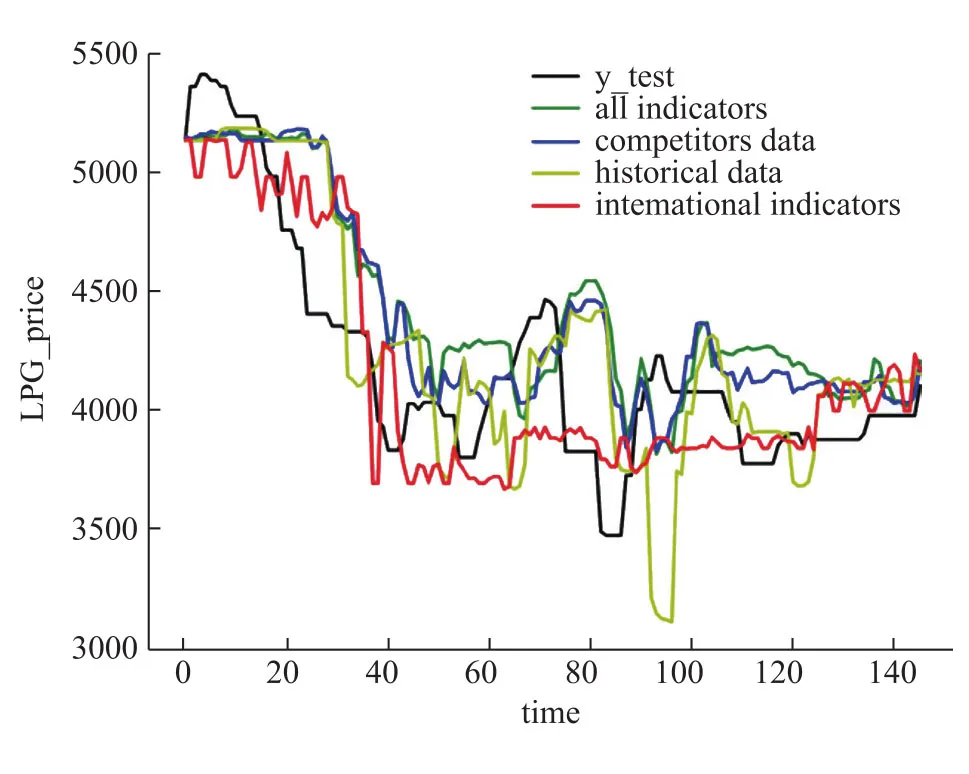
图4 未来第10天的预测结果Fig.4 Resultofpredictingthe tenth day in the future

图5 未来第15天的预测结果现Fig.5 Resultofpredictingthe 15th day in the future
根据最后的预测结果,最终决定用采用所有特征数据作为输入特征值进行训练得到的模型来预测未来 7天的LPG价格,用采用国际指标数据作为输入特征值进行训练得到的模型来预测未来 8-15天的LPG价格。
此外,我们还对各种指标对模型的贡献度进行了分析。当输入特征为全部特征数据时,对模型的贡献度排名前五的指标除了当天的LPG价格外就是竞争对手的LPG价格,并且随着预测天数的增加竞争对手的贡献度越来越大,说明在所有的指标中,除了自身 LPG价格,竞争对手的LPG价格与预测的LPG价格相关度最大,这也是符合实际逻辑的,现实中各个公司的LPG价格往往相差不大,并且它们也会参考竞争对手的LPG价格来制定自己的LPG价格;当输入特征只有竞争对手的数据时,对模型的贡献度最大的是中燃广西的数据,说明华南-槽批与中燃广西的LPG价格是最接近的;当输入特征只有华南-槽批自身的历史数据时,只有当天的LPG价格对模型的贡献度最大,其余天数的贡献度几乎可以忽略不计,说明历史价格只取最近一天的历史(也就是当天的价格)就足够了;当输入特征只有国际指标的数据时,对模型的贡献度较高的是 cp 丁烷丙烷月度合同价和北海丁烷丙烷合同价,说明在国际指标中这些指标最能反映价格的变化趋势。
4 结语
本文以华南-槽批 LPG价格为例,为了预测未来7天,10天,15天的LPG价格,使用了随机森林模型进行训练和预测,为了进一步分析不同指标对 LPG价格的影响和相关性,又对特征进行了特征选择,将特征分为四种不同类型分别作为输入特征输入到模型进行训练,最后对各种特征与 LPG价格的关系进行了详细的分析和说明。
该实验的预测结果为15天平均 MAE195,达到了预期的效果,不足之处就是结果出现了一定的过拟合。根本原因是数据集不够大,训练集与测试集数据分布存在一定的差异,解决方案就是扩大数据集,保证训练集与测试集数据分布一致。后续会增加数据集进行进一步的训练。
LPG价格预测对于LPG公司提高 LPG 营销管理水平,增强对 LPG价格的分析判断能力,进而提高盈利水平具有非常重要的意义。在下一步工作中,我们会将本模型部署到LPG价格预测系统中,作为LPG价格分析和日常监控的辅助手段,同时尝试使用更多模型进一步提高准确度。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
电子制作(2018年16期)2018-09-26
数学学习与研究(2017年3期)2017-03-09
作文大王·笑话大王(2017年1期)2017-02-21
作文大王·笑话大王(2016年10期)2016-10-18
作文大王·笑话大王(2016年7期)2016-08-08
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
中国老区建设(2016年1期)2016-02-28
作文大王·笑话大王(2016年2期)2016-02-24
智能系统学报(2015年4期)2015-12-27