
基于多尺度特征融合的图像语义分割
2019-11-08 06:54李子印
中国计量大学学报 2019年3期
华 静,陈 亮,李子印
(中国计量大学 光学与电子科技学院,浙江 杭州 310018)
图像语义分割的任务是对图像中各个像素所属类别进行标注[1 -2],它作为图像理解的重要一环,在自动驾驶领域、无人机领域及医疗影像分析领域等应用中都有重要作用。其中,在无人驾驶领域中,检测道路、行人、车辆,获得物体轮廓信息,以辅助驾驶和避让[3-6]。在无人机领域中,定位落地点和识别落地点场景[7]。在医疗影像分析领域,诊断肿瘤和龋齿[8]等。
早期的图像语义分割主要包括像素级别阈值法[9]、基于像素聚类[10]的分割方法和基于图论划分的分割方法。但是传统的方法过分依赖于人工标注的特征库,无法广泛表示图像特征,在实际生活应用中具有很大局限性。基于卷积神经网络(Convolutional Neural Network,CNN)[11]的方法无人工参与,便可以从大量训练图像中自动地学习有用的语义特征,并能够获得更加精确的分割结果,较传统语义分割方法具有明显优势。
LONG等[12]人于2014年提出语义分割算法的开门之作:基于全卷积神经网络的语义分割算法(Fully Convolution Network,FCN),该模型是一个端到端的网络,允许任意尺寸图像的输入,而不再局限于块级别的输入,极大地降低了计算复杂度。FCN使用卷积层替换传统卷积网络中的全连接层,通过跳转连接将包含语义信息的高层特征和包含位置信息的低层特征进行融合以达到精确的分割效果。基于FCN的思想,Badrinarayanan等[13]人提出了应用于道路场景语义分割的SegNet网络,SegNet的创新点在于所采用的池化层能够记录池化最大值的空间位置,保留池化层索引,在恢复图像尺寸时调用池化层索引从而保证精确的位置关系映射。DeepLab是由Google团队提出的一系列用于语义分割的经典算法,DeepLab v1[14]采用深度卷积网络和全连接条件随机场(DenseCRF)完成语义分割。 DeepLab v2[15]是在DeepLab v1的基础上采用带孔卷积(Atrous Convolution),减少了下采样过程造成的语义信息损失。DeepLab v3改进了带孔空间金字塔池化模型,通过带孔卷积级联获取多尺度的语义特征。DeepLab v3+[16]在DeepLab v3的基础上结合深度可分离卷积(Depthwise Separable Convolution),并且引入编码器-解码器的架构,大大提升了语义分割精度。
为充分利用物体的上下文信息,清晰描绘图像的边缘轮廓,本文在DeepLab v3+的基础上,设计了一种基于多尺度融合的图像语义分割方法,称为MsffNet (Multi-scale Feature Fusion Network),该方法的主要创新点为融合了多尺度的图像特征,包括具有空间位置信息的低层特征和具有语义信息的高层特征,并且提出了一种融合算法,用于结合相邻层次的特征,使得高层特征通过语义信息来选择性地融合低层特征以达到最佳的分割效果。实验结果表明,该方法可以显著提升语义分割性能。
1 MsffNet语义分割模型
1.1 语义分割网络模型
本文提出的多尺度特征融合模型MsffNet是DeepLab v3+网络模型的扩展,其网络结构如图1,它包含语义特征提取和语义特征融合两部分,其中特征提取部分与DeepLab v3+相同,由Aligned Xception[17]网络结合带孔空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)获得输出步长为16的语义特征,特征融合部分采用本文提出的融合算法对相邻特征进行融合,并且由高层往低层对多条支路特征融合,获得增强特征。

图1 MsffNet网络结构Figure 1 MsffNet network structure
1.2 特征提取
1.2.1AlignedXception网络
语义特征提取主要使用Aligned Xception分类识别网络提取特征,同时以此为基准网络结合ASPP获取更深层次的特征。Aligned Xception的具体结构如图2,该网络主要包括Entry flow、Middle flow和Exit flow三个部分,其中Entry flow包含2个卷积和3个残差块,Middle flow包括16个残差块,Exit flow包括2个残差块、1个全连接层和一个逻辑回归层。由于Aligned Xception网络在Entry flow中的conv1_1、block 1、block 2、block 3和Exit flow中的block 1的步长均为2,输出的特征图大小都会相较于输入特征图减小一半,因此最终输出的特征图相较于原始图像大小缩小32×32倍。该网络改进了传统的残差块结构,将传统残差块中的普通卷积全都替换成深度可分离卷积(Depthwise Separable Convolution),同时每个3×3的深度可分离卷积后面都接有BatchNorm层和ReLU层,此操作不仅减少了计算消耗和参数量,还在精度上有所提升, Aligned Xception在ImageNet上的top-1错误率为20.19%低于ResNet-101的22.40%。
为了实现MsffNet网络的特征提取部分,本文对Aligned Xception网络进行具体微调:去除Aligned Xception网络的全连接层和逻辑回归层,确保分类网络输出空间维度的特征;将Aligned Xception网络的block 1中的步长改为1,同时加入扩张率为2的空洞卷积,维持感受野范围的变化。经过微调,Aligned Xception网络的输出步长变为16,为了和图1中的特征提取网络相对应,我们根据输出特征图的大小将Aligned Xception网络分为conv1、conv2、conv3、conv4和conv5,具体组成结构如表1。输入图像大小为513×513,由于conv1、conv2、conv3、conv4的步长为2,conv5的步长为1,所以最终输出的特征大小为33×33,本文取conv1、conv2和conv3输出的特征作为低层特征。

图2 Aligned Xception网络Figure 2 Aligned Xception network

表1 Aligned Xception组成结构Table 1 Aligned Xception composition structure
1.2.2带孔空间金字塔池化
带孔空间金字塔池化如图3,用于对Aligned Xception输出的最高层特征进行处理,包括:1)对输入特征做卷积核大小为1×1,个数为256的卷积;2)对输入特征分别做卷积核大小为3×3,个数为256的采样率为rate={6,12,18}的空洞卷积;3)对输入特征做全局平均池化。
将1)、2)、3)的输出特征进行通道连接,再经过卷积核大小为1×1,个数为256的卷积,输出特征即为特征提取的最高层特征。
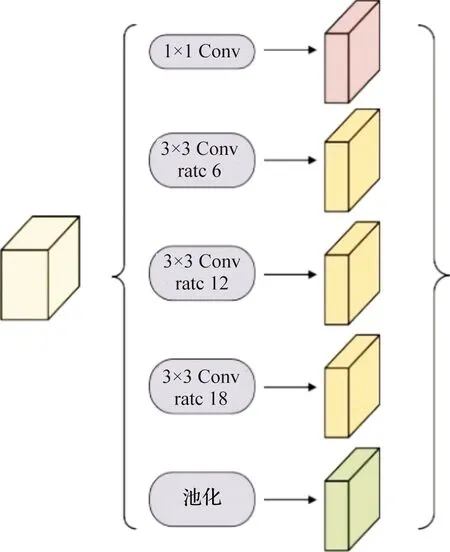
图3 带孔空间金字塔模型结构Figure 3 Atrous spatial pyramid pooling module structure
1.3 特征融合
Aligned Xception是一个多层级的卷积神经网络,能够学习得到像素级标签的强特征,低层特征由于感受野较小,学习局部细节的相关内容,高层特征则学习更加抽象的语义信息[18]。抽象特征对物体的大小、位置和方向不敏感,旋转不变性、平移不变性以及缩放不变性等特点是提升图像分类性能的主要原因,但是这种高层特征感受野过大、语义信息过强,隐式地损失了场景中部分目标的空间信息,牺牲了深度网络的定位精度。直接对高层特征图上采样往往不利于边缘细节的恢复,大部分的空间信息会被过多的降维和通道数增加忽略掉,造成边缘细节粗糙。因此整合多层级多尺度的特征促进低层细节与高层语义的增强互补往往能增强分割效果。如果对低层特征和高层特征直接进行通道连接融合,这种做法忽略不同阶段特征之间的差异性,造成分割目标的不一致性,降低分割精度。
因此提出一种融合算法,该算法作用于邻近两个特征,由高层往低层逐渐融合,如图1所示融合算法首先将ASPP输出的特征与conv3输出的特征融合为fuse_1,然后将fuse_1与conv2输出的特征融合为fuse_2,再将fuse_2与conv1输出的特征融合为fuse_3,最后fuse_3经过上采样实现最终的分割图像。融合算法网络结构如图4,其中所有的卷积核个数都为256。首先低级特征先经过block 1,其中1×1的卷积是用于降低特征图的通道数,减少参数的计算,提高训练模型速度,残差模块主要用来结合特征图的通道信息,达到细化特征图的效果;然后低级特征和高级特征输入到block 2中,低级特征和高级特征先通过通道的叠加,经过全局池化和两个1×1的卷积,与低级特征相乘,再与高级特征相加,其中高级特征提供语义指导选择低级特征,达到选择更具区分力的特征;最后再经过block 3,细化模块的block 3和block 1相同,都是为了细化图像特征。
本文算法不同于其他算法采用最后的输出特征完成预测的做法,而是采用多个支路特征进行融合,得到增强的语义特征,并且提出的融合算法考虑到了不同阶段特征之间的差异性,使得高层特征通过语义信息来指导选择低级特征,从而达到选择更具区分力的特征。
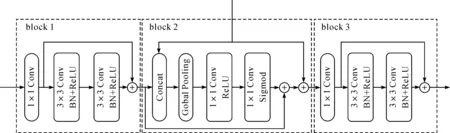
图4 融合算法网络结构Figure 4 Fusion algorithm network structure
2 实验结果分析
2.1 实验设计
数据集:本文在ADE20K和PASCAL VOC 2012数据集[19]上完成训练,1)ADE20K数据集,它是MIT提供的专门用于场景解析的数据集,可应用于场景的感知、理解、分割以及多标签识别等,包含了机场、街道、汽车多个场景,总共150个类别。训练集、验证集和测试集分别包含2万张、3千张和2千张数据。2)PASCAL VOC 2012数据集的图像包含20种类别的物体和1个背景类别,语义分割数据集包含训练集(1464张图像)、验证集(1449张图像)和测试集(1456张图像)3个部分,其中,验证集和测试集不包含训练集的图像。
训练:使用Tensorflow框架实现图1的网络的结构,整个网络是端到端的结构,输入图片的尺寸均是513×513,输入到网络中进行训练,实验使用经过ImageNet数据集预训练的Aligned Xception网络进行初始化网络参数,基础学习率设置为0.000 1,动量(momentum)设置为0.9,权重衰减率设置为0.000 04,采用反向传播和随机梯度下降来计算误差和更新参数。
评价指标:为了评价图像语义分割算法的分割精度,本文采用平均交叠率(Mean Intersection Over Union,MIOU)进行衡量和对比。MIOU通过计算每一类真实标记和预测标记交集与它们并集的比值的平均值作为评估标准,目前研究者主要采用MIOU评估分割模型的性能[20]。假设总共有C类语义标签,nij表示真实语义类别为i但是被预测为j的像素个数,i,j=0,1,…,C-1,ti表示真实语义类别为i的像素个数,则有以下计算公式:
2.2 实验结果
为验证所提方法的可行性,将MsffNet分别与多个图像语义分割方法进行比较,如FCN8s、SegNet、DilatedNet、PSPNet[21]、DeepLabv3+。表2中所示为不同网络模型在ADE20K和PASCAL VOC2012的测试集上的语义分割结果对比。
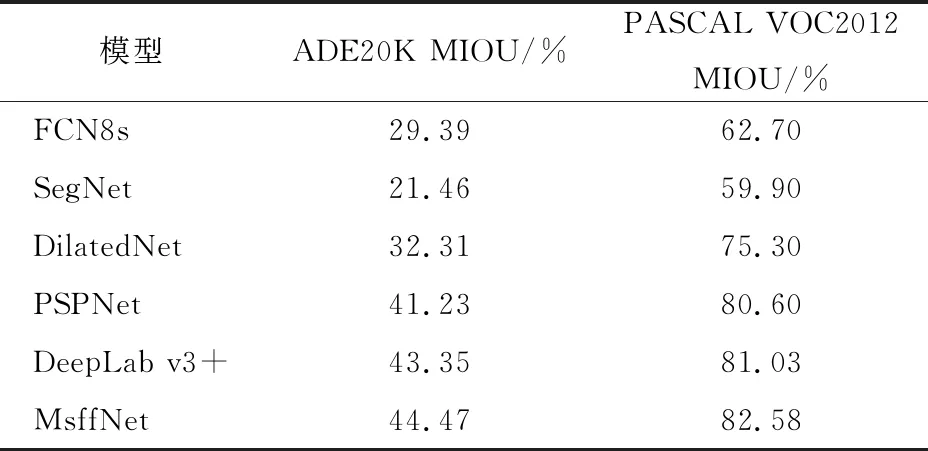
表2 ADE20K和PASCAL VOC2012测试集上实验结果对比Table 2 Comparison of experimental results on ADE20K and PASCAL VOC2012 test sets
ADE20K和PASCAL VOC2012数据集的分割结果表明:MsffNet整体的性能更优异,平均交叠率更高。与DeepLab v3+相比,ADE20K的平均交叠率提高了1.12% ,PASCAL VOC2012的平均交叠率提高了1.55%,这主要归功于多层级多尺度特征的融合和对融合特征的细化处理,有效降低了不同类型特征的之间的差异性,提高了准确度。
图5为DeepLab v3+和MsffNet模型的平均识别准确率随迭代次数改变而变化的图,从图中看出,随着训练迭代次数的增加,图像语义分割精度也在不断提高,训练ADE20K数据集时,当迭代次数为3000次,MsffNet的准确率为34.43%超过DeepLab v3+的准确率25.68%,当迭代训练到30 000次时DeepLab v3+的准确率为44.47%,而MsffNet的准确率为43.65%。训练PASCAL VOC2012数据集时,当迭代次数为3 000次,MsffNet的准确率为75.45%大大超过DeepLab v3+的准确率68.87%,当迭代训练30 000次后准确率变化平缓,趋于收敛,其中DeepLab v3+的准确率为81.03%,而MsffNet的准确率为82.58%。
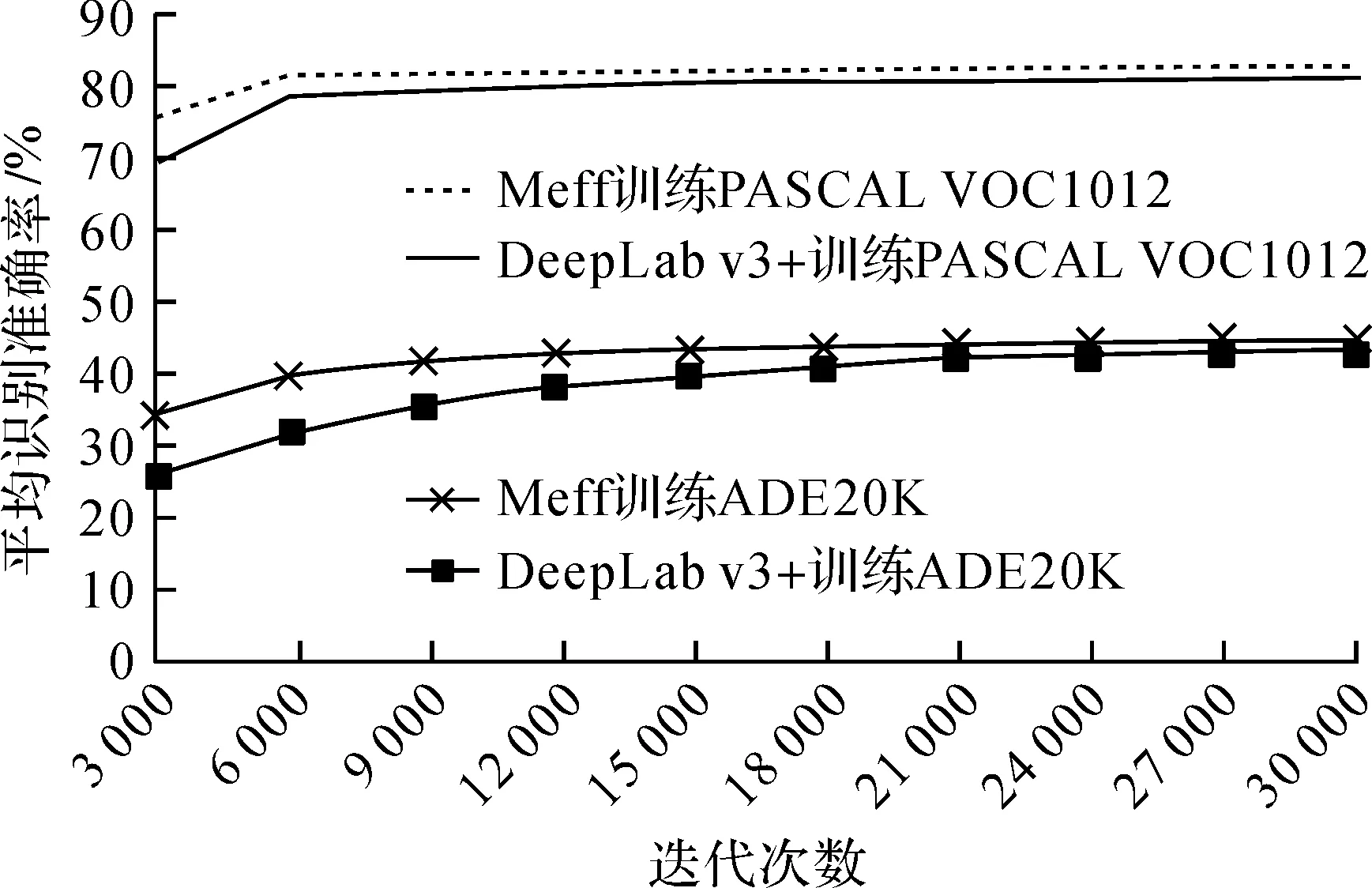
图5 训练精度随迭代次数变化Figure 5 Training accuracy varies with the number of iterations
当训练迭代次数为30 000时,使用训练好的MsffNet和Deeplab v3+对PASCAL VOC 2012测试集进行分割,分割结果如图6, 从上到下依次是原图、真实标签图、DeepLab v3+结果、MsffNet结果,比较前三列DeepLab v3+和MsffNet网络的分割图,可以明显的看出MsffNet分割后的图像中物体的轮廓更精细,如第一张图像中瓶子下半部分轮廓、第二张图像中自行车前轮轮廓和第三张图像中牛的后腿轮廓;比较后两列DeepLab v3+和MsffNet网络的分割图,可以看出MsffNet能准确辨认出沙发和牛,而DeepLab v3+却将一个物体分为两个。
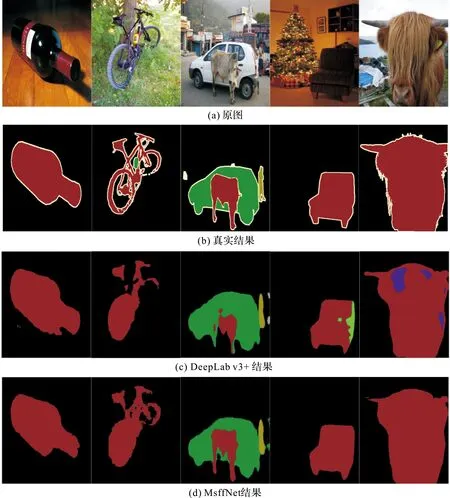
图6 PASCAL VOC2012数据集部分分割结果Figure 6 Partial segmentation results of PASCAL VOC2012 dataset
3 结 论
本文提出了一种基于多尺度特征融合的图像语义分割算法(MsffNet)。首先在特征提取阶段中采用微调的Aligned Xception分类识别网络提取低层特征,取conv1、conv2和conv3输出的特征层作为低层特征;其次将conv5输出的特征通过ASPP获得具有更大语义信息的高层特征,在特征融合阶段中,采用提出的融合算法,由高层往低层逐渐融合邻近两个特征,使高层特征通过语义信息指导有选择性地融合低层特征,最终实现图像的语义分割。实验结果表明,本文算法获得较高的分割精度,传统的语义分割模型大部分直接对高层特征进行上采样损失了图像的边缘细节信息,大部分的空间信息会被过多的降维和通道数增加忽略掉,使得边缘细节模糊。还有部分语义分割模型对低层特征和高层特征直接进行通道连接融合,这种做法忽略不同阶段特征之间的差异性,容易造成分割目标的不一致性,从而降低分割精度。因此本文为了完成多尺度特征融合,提出了一种融合算法和多支路上采样的多尺度特征融合方式,用来生成更加丰富的语义内容。为了对比特征融合效果,在DeepLab v3+完成特征提取的基础上完成特征融合,采用ADE20K和PASCAL VOC 2012数据集进行训练,在ADE20K和PASCAL VOC2012 数据集上的平均准确率分别为44.47%和82.58%。当前语义分割任务的实时性是一个亟待解决的问题,本文语义分割网络需要进一步优化和提升,在保证分割准确率的同时提升速度。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
热带气象学报(2022年2期)2022-08-24
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
开放教育研究(2020年2期)2020-03-31
报刊荟萃(上)(2018年3期)2018-04-24
妇女生活(2016年5期)2016-05-26
长江学术(2016年4期)2016-03-11
