
引入外部词向量的文本信息网络表示学习
2019-11-09 03:42张潇鲲刘琰陈静
智能系统学报 2019年5期
张潇鲲,刘琰,陈静
(数学工程与先进计算国家重点实验室,河南 郑州 450000)
近年来,随着互联网的发展,以Facebook、twitter、微博等为代表的大型网络不断发展,产生了海量具有网络结构的数据,这些数据的特点在于样本点之间并不完全独立,而是具有一定的连接关系,同时网络节点自身也包含特定的属性信息。日常生活中的社交网络(微博)、问答社区(知乎)、生活服务类网站(大众点评)、论文引用关系网络等包含了大量文本信息,下文中将此种网络简称为文本信息网络。在文本信息网络中,文本信息以标签、正文、描述以及其他元数据形式广泛存在,给网络提供了大量可利用的语义信息。例如论文引用关系网络中,论文作为网络节点并以引用关系作边,节点还包含相关文本信息。网络数据的这些特性,给大规模或复杂网络数据研究带来了挑战。
网络表示学习(network embedding或network representation learning)目的是学习网络节点的低维空间向量表示,降低存储、计算成本,提升并行能力,使传统机器学习算法能够在大规模数据中得到应用[1]。因此,近年涌现出许多相关研究,其研究成果在链接预测[2]、社团发现[3]、节点分类[4]、相似度计算[5]、网络可视化[6]等应用场景广泛应用。大部分已有网络表示学习算法基于网络本身特征进行表示学习,例如DeepWalk[7]、Node2Vec[8]、Line[9]等刻画结构特征的模型;以及针对文本信息网络,在DeepWalk[7]基础上引入文本特征的TADW[10],引入互注意力机制,并在部分文本信息网络公开数据集中得到了目前最优结果的CANE[11]。文本信息网络表示现有方法从网络本身文本特征出发,由于网络文本分布与自然语言文本分布差异,会产生一定程度的语义残缺或语义漂移,这种情况在数据集规模受限情况下更为明显。
直觉上,为模型引入越多外部知识,模型的表示容量越高,模型结果越能够刻画更多网络特征;而预训练的分布式词向量正是针对文本相关任务的外部语义知识。随着词向量应用的普及,存在许多以通用语料训练得到的词向量资源,其中包含了大量语义信息。利用这部分已有语义资源增强文本信息网络的表示是本文研究的目标。
1 相关工作
网络表示学习早期技术以图表示(graph embedding)、降维方法为主。包括multidimensional scaling (MDS)[12]、IsoMap[13]、局部线性表示 LLE[1]以及Laplacian Eigenmap[14]。这类算法的计算复杂度偏高,不适合在大规模网络中应用。
随着近年网络表示学习发展,大量可以应用在大规模网络中的算法相继提出。对于文本信息网络,主要分为如下2类:
1)只考虑结构特征的网络表示学习方法
Deepwalk[7]作为网络表示学习的经典算法,将自然语言处理中利用词共现信息进行建模的算法SkipGram[1]引入到网络表示学习任务中,通过随机游走构建节点上下文序列,并利用Hierarchical Softmax[2]的树形结构加速训练过程。LINE[8]主要利用预先设计的概率密度函数来表征图的一阶、二阶相似度,并引入负采样[1]、异步随机梯度下降(ASGD)[15]降低计算复杂度,实现适用于大规模网络节点表示的计算。Node2vec[9]对Deepwalk的随机游走策略进行了修改,通过在游走路径中增加权重项来控制深度(DFS)以及广度(BFS)优先的游走方式,使算法的图游走策略更有效率。GraRep[16]将k阶相似矩阵进行分解,并将得到的特征向量进行拼接得到最后的节点向量,以此来捕捉更高阶的相似度特征,但面临着计算量巨大的问题。网络结构的相似性主要体现在相似度计算上,其中一阶、二阶相似度是最普遍使用的特征,一般来说,模型中包含越多的高阶相似度特征,模型表现越好,但是相应计算量也会增大。
2)结合节点语义信息的网络表示学习方法
上述模型只考虑网络的结构特征信息,针对文本信息网络,Yang等[10]提出了text-associated Deep-Walk (TADW),将文本信息与DeepWalk算法进行了结合。Tu等[17]提出了max-margin DeepWalk(MMDW),利用SVM思想对DeepWalk在文本信息网络中的应用进行改进,Tu等[11]提出了上下文相关的网络表示学习模型CANE,针对不同上下文,利用互注意力机制,学习网络节点在不同上下文中的表示。
使用自身文本特征进行建模,受限于任务本身语料,容易产生语义偏差或残缺。在论文写作时所知,鲜见引入外部词向量辅助文本信息网络建模的研究。
2 语义漂移现象
如表1所示,采用Word2vec[1]对实验部分的Zhihu数据集[12]训练词向量,对由训练得到的词向量与外部词向量中的随机词的相似词进行了对比。在Zhihu数据集词表中随机抽取两个词 “电子乐”、“杭州”,根据余弦相似度分别在Zhihu词向量与外部词向量词表中找到前5个表示近似的词。可以看到,受限于数据集规模,Zhihu数据集的词模型表示能力有限,语义漂移明显。
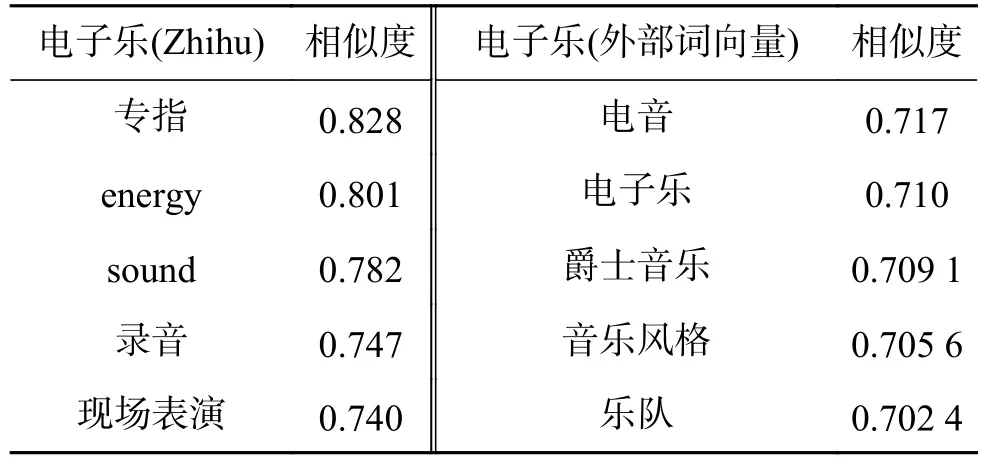
表1 “电子乐”相似词对比Table 1 “Dian Zi Yue” cosine similarity
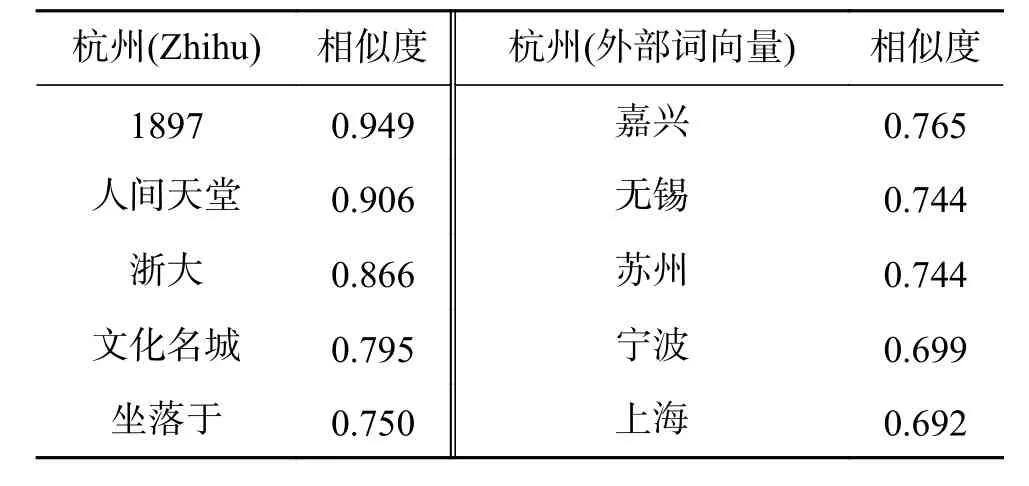
表2 “杭州”相似词对比Table 2 “Hang zhou” cosine similarity
3 问题定义与描述
沿用LINE[9]中的信息网络定义,文本信息网络定义如下:
定义1 文本信息网络
定义2 引入外部词向量的文本信息网络
定义3 节点特征空间表示
定义4 结构相似度
一阶相似度 一阶相似度通过当前节点与相邻节点间的联通关系,描述了网络在一跳范围内的结构特征。对节点、,若节点间没有边相连,则一阶相似度为0。若存在边,一阶相似度即为边权重。
二阶相似度 二阶相似度衡量了当前节点与相距两跳的邻居节点间的结构相似程度。记为节点与其他所有点之间的一阶相似度。、的二阶相似度为、的相似度,该相似度可以通过余弦相似度等相似度度量方式进行衡量,若、没有一跳公共邻居节点,则二阶相似度为0。
基于外部词向量的文本信息网络表示学习目的是对给定文本信息网络,在融合结构特征与语义特征的特征空间中,学习网络节点的低维向量表示,使表示结果包含网络结构特征、网络本身文本特征以及外部文本特征。出于计算复杂度考虑,本文只使用一阶、二阶相似度对结构特征进行建模,语义特征使用词向量信息进行建模。
4 基于外部词向量的文本信息网络表示学习模型NE-EWV
文本信息网络建模过程中涉及到两个向量特征空间:语义特征空间、结构特征空间。受限于任务本身语料规模与词分布,文本信息网络建模得到的语义特征空间表示与实际语义会产生一定程度偏差。本文引入外部词向量作为先验知识辅助建模过程,可以扩展语义特征空间表示容量,修正部分语义误差。故NE-EWV主要解决2个问题,一是引入外部词向量信息对语义特征进行扩充;其次是学习融合结构特征、语义特征的表示结果。
4.1 NE-EWV模型基本架构
NE-EWV分为3个部分,NE-EWV1在语义特征空间中引入结构特征约束,得到语义特征空间中包含部分结构特征约束的节点表示。NEEWV2在结构特征空间中引入语义特征约束,得到结构特征空间中包含部分语义特征约束的节点表示。NE-EWV3表示结果由上述2步得到的节点表示融合得到,本文采用2种融合方式:1)简单将2个向量表示进行连接,得到节点表示,其中代表向量拼接操作;2)基于自编码器的融合模型。
4.2 结构约束的语义特征空间表示模型NEEWV1
节点在语义特征空间中的表示受当前节点文本影响,即节点的语义可以看作是节点文本中数个关键词的语义组合,本文为简化起见,对节点文本语义表示采用线性加权,得到结果作为节点的语义表示。在实验章节第5节,对NE-EWV1的可视化结果做了分析。
NE-EWV1以节点文本词向量的线性加权作为节点在语义特征空间中的表示
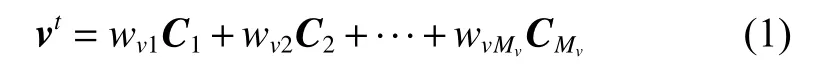
将表示限制在语义特征空间后,沿用LINE对于结构特征损失函数定义引入结构特征约束,将问题转化为最优化问题求解。其中,对于节点u,v,一阶相似度损失函数定义为
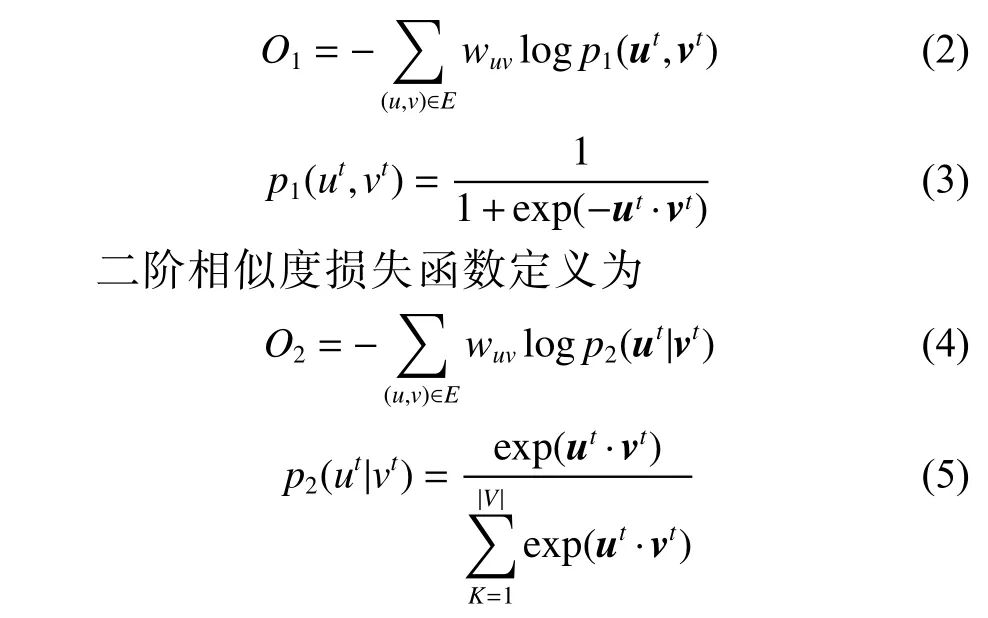
对于表示结果,沿用LINE[9]中对于一阶、二阶相似度的处理。由于一阶相似度只能应用于无向图,对于有向图,以二阶相似度作为结构特征的约束进行计算。对于无向图,由一阶相似度损失函数得到节点表示记为,二阶相似度损失函数得到节点表示记为,通过向量拼接得到最后的语义特征空间表示。
4.3 结构约束的语义特征空间表示模型NE-EWV2
为了引入语义约束,将词看做特殊的网络节点,以词向量相似度做权重边,扩展原网络。考虑到模型计算量,对每个节点在外部词向量中的节点文本,首先通过采样得到节点文本的子集,表 示 出现在外部词向量以及节点文本中的词集合;对每个,依次与V中其余节点文本的采样子集中每个词做边,词向量的余弦相似度作为边的权重。对于有向图,,
完成扩展网络后,接下来在结构特征空间中与4.2节处理相同,沿用LINE[9]中对损失函数的定义。将文本中的词与网络中的节点统一到结构特征空间中进行计算,得到节点语义约束下的结构特征空间表示。
4.4 表示融合模型NE-EWV3
NE-EWV1、NE-EWV2在不同程度上都包含了语义特征信息以及结构特征信息,但建模过程侧重不同,其表示结果属于不同特征空间。总的来说,NE-EWV1、NE-EWV2描述了同一网络在不同视角下的网络表示,对其表示结果做非线性变化映射到同一向量空间中,其表示应当相对接近,并可互为补充。因此文本提出NE-EWV3对NE-EWV1、NE-EWV2表示结果进行融合。
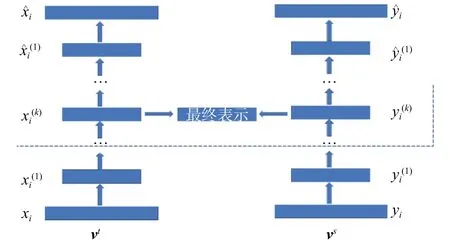
图1 基于自编码器的表示融合模型Fig. 1 Feature fusion representation model based on aligned auto-encoder
自编码器主要包括编码和解码2个过程,编码过程将输入映射到目标向量空间中,解码过程将目标向量空间中的表示还原到原输入向量空间中,要使目标向量空间的表示有效,需要解码过程中重建到输入向量空间中的表示与输入表示尽可能一致。
NE-EWV3(AutoEncoder)采用了对称的自编码器结构,学习、在目标特征空间中的表示结果。模型左右计算流程一致,这里以左侧为例进行说明。左侧自编码器的目的是将节点在语义特征空间中的表示进行非线性变换。模型左侧初始输入为节点在语义特征空间中的表示,编码阶段,通过下式得到压缩表示:
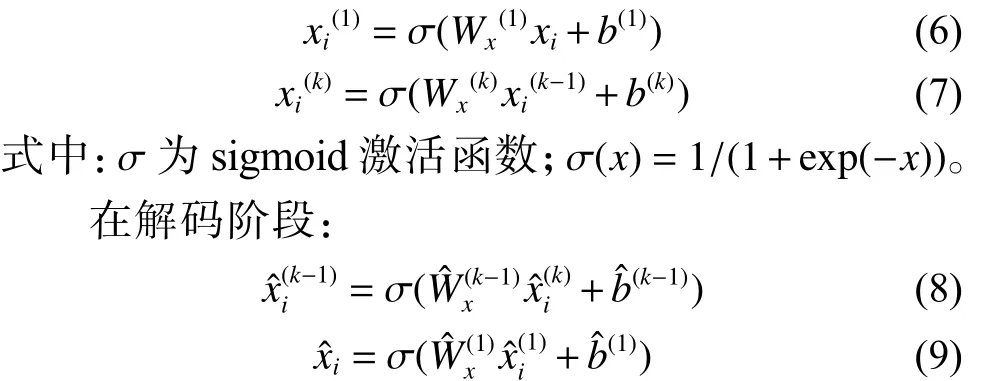
最终NE-EWV3(AutoEncoder)定义损失函数为,、、为控制损失项权重的超参数。最终节点表示,由2个压缩表示拼接得到。
4.5 模型优化
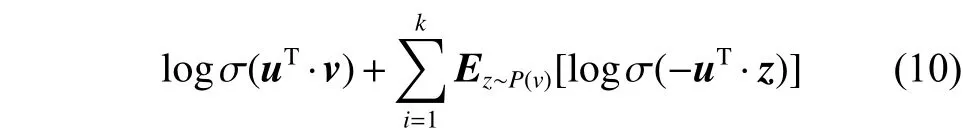
5 实验
5.1 实验数据
实验包括了现实网络中的中文、英文数据集。对于中文测试数据,外部词向量使用微信公众号中800万篇文章预先训练得到的词向量(https://spaces.ac.cn/archives/4304),词表大小35万,维度256维。英文使用了Google发布的在新闻语料中训练得到的词向量(https://code.google.com/archive/p/word2vec),词表大小300万,维度300维。其中,Zhihu为中文数据集,Cora、HepTh为英文数据集。
HepTh数据集:HEP-TH (high energy physics theory)是arXiv发布的公开论文引用网络,随机抽取其中10 740篇包含概述的论文,以论文概述作为节点文本信息,以引用关系对节点之间做边。
Zhihu(知乎)数据集:知乎是国内的问答社区网站,本文使用CANE[12]公开的知乎数据集,其中包含10 000个爬取的用户作为节点,以用户关注话题的描述文本作为节点文本信息。
数据集统计信息列在表3,在外部词向量的未登录词统计列在表4。
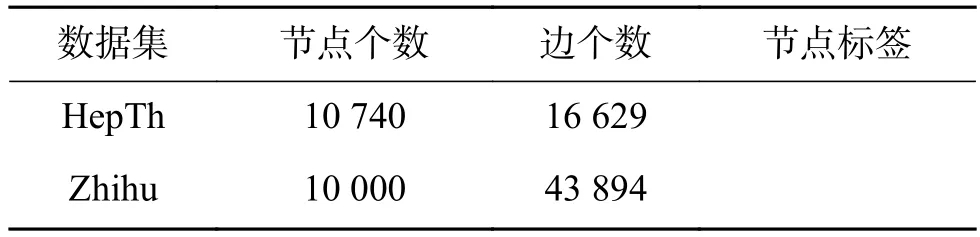
表3 测试数据集统计Table 3 Dataset statics
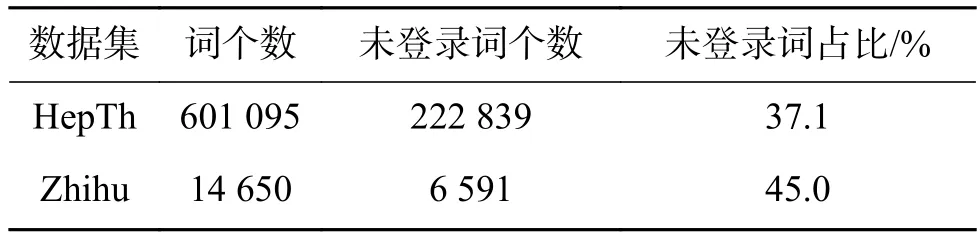
表4 数据集未登录词统计Table 4 OVW statics
实验首先在数据集上对链接预测任务进行了实验,并在Cora数据集上对节点分类任务进行了实验。
5.2 基线方法
DeepWalk[8]是2014年提出的网络表示学习算法,主要利用随机游走构造节点上下文信息,并利用词向量算法中的SkipGram计算网络表示,Hierarchical Softmax进行计算优化,DeepWalk针对网络结构的二阶相似性进行建模。
LINE[9]利用预定义的概率密度函数对一阶以及二阶相似度进行了建模。为了尽可能体现LINE算法的性能,这里采用LINE算法的1st+2st的版本,即包含一阶相似度以及二阶相似度进行建模。
Node2vec[10]主要针对随机游走过程中的宽度优先以及深度优先做了优化,通过控制跳转概率参数p、q进一步扩展了DeepWalk算法。
CANE[12]算法主要利用互注意力机制以及卷积神经网络对文本进行建模,学习在不同上下文状态下节点的不同表示。
5.3 测试方法
由于本文模型引入了外部词向量,为了减少词向量维度变化可能造成的信息损失,基线模型得到的表示结果维度与词向量维度相同,本文模型除向量拼接外,表示维度与词向量维度相同。
对基线方法中的参数设置,采用grid search[20]进行选取。DeepWalk[8]每个节点开始的随机游走序列为10,游走长度80,skip-gram窗口为10。对涉及负采样的方法,负样本个数设置为。沿用CANE中的参数设置,对cora、Zhihu数据集设置、、;HepTh数据集设置、、,epoch个数设置为200。
NE-EWV1 epoch个数设置为50。NE-EWV2中首先采用TF-IDS模型计算关键词,保留关键词个数15,对于Zhihu、Cora数据集,设置、,对于HepTh数据集,设置、,epoch个数设置为50。NE-EWV3(AutoEncoder)损失函数中设置、、,epoch个数设置为200。
对链接预测问题,即根据表示结果还原网络的联通关系,采用AUC作为评价指标[21],AUC衡量了正确判定正样本与错误判定负样本的概率差异,AUC指标越大说明模型在二分类问题上表现越好。对节点分类问题,即根据表示结果对节点分类进行预测,采用准确率作为评价指标。
5.4 链接预测
在不同的数据集上针对链接预测任务进行了测试,测试方法是选取一定比例的边和以及这些边中节点的文本信息作为测试数据,以剩余数据作为测试集。如表5、6所示。
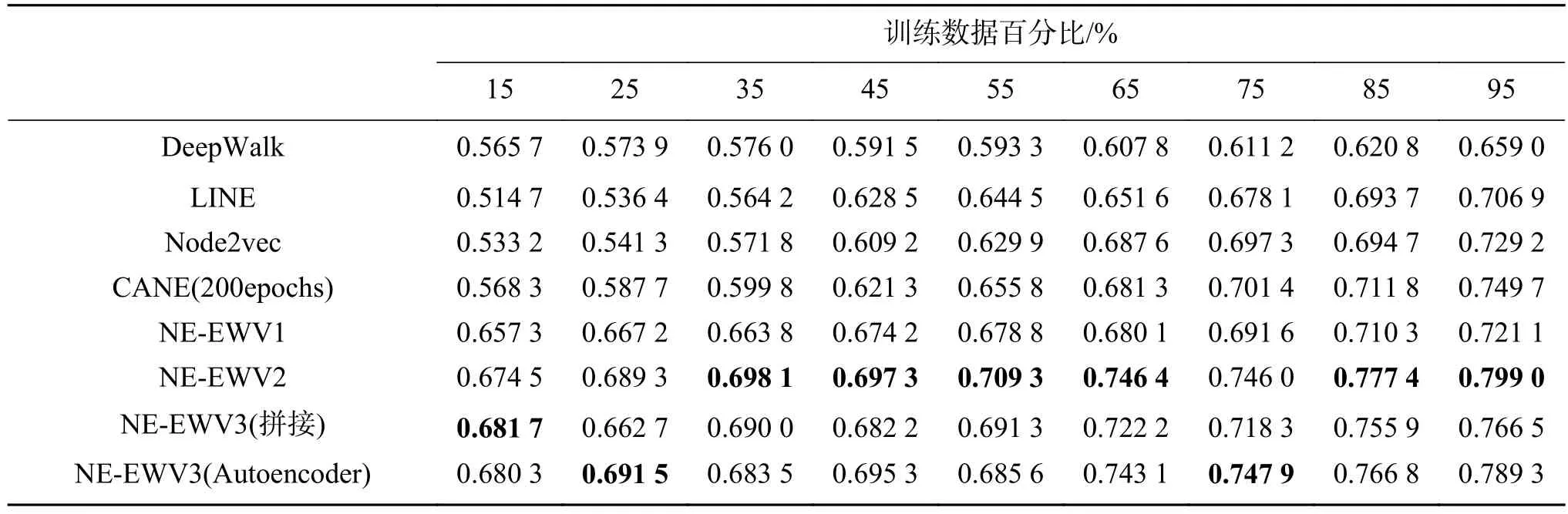
表5 Zhihu数据集的AUC指标(256维)Table 5 AUC values on Zhihu (256 dimensions)
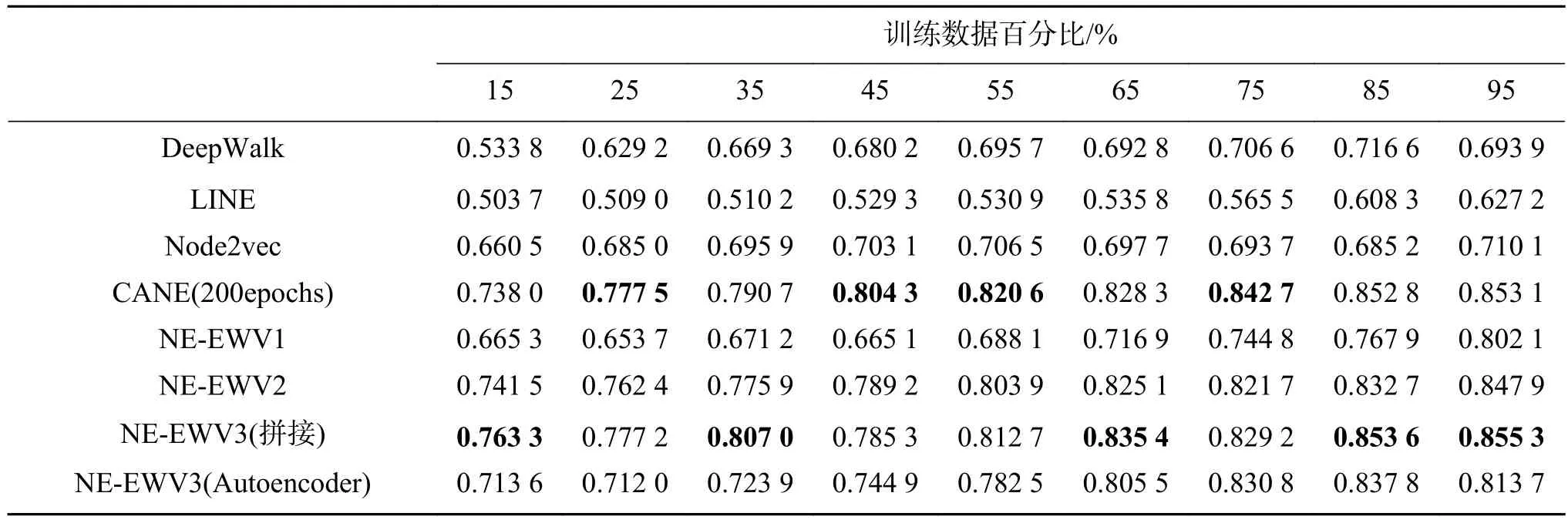
表6 HepTh数据集的AUC指标(300维)Table 6 AUC values on HepTh(256 dimensions)
1)在中文数据集中本文模型要优于其他基线模型,相比基线算法中AUC指标最好的CANE,AUC指标提高了5%~12%。在英文数据集HepTH中与性能最好的CANE基本相当。
2)本文使用了在领域无关的通用语料中训练得到的词向量,在Zhihu数据集中未登录词占比45.0%(Zhihu数据集中包含了话题描述,即包含了大量专有名词),在HepTh数据集中未登录词占比43.1%。说明本文方法对通用语料有较好适应性,通用文本语料能够提升某些特定领域的文本信息网络表示学习的表示能力。
综上所述,证明了本文模型能够学习到文本信息网络中的有效网络表示,能够有效捕捉网络本身的结构、语义信息,并在不同数据集以及外部词向量上证明了表示的有效性和鲁棒性。
6 结束语
本文提出了基于外部词向量的网络表示模型,将外部词向量引入到文本信息网络的网络表示学习过程中。模型包括3个部分:在语义特征空间中学习包含结构特征约束的表示,在结构特征空间学习语义特征约束的表示,以及表示融合部分。本文在现实网络数据集中,以链接预测实验,证明了本文模型可以学习到节点间链接关系的有效表示,而节点间的链接关系也构成了整个网络结构。
在未来的研究工作中,有如下研究方向:未登录词的表示,通用词向量在领域特定任务中往往面临着存在大量未登录词的问题,利用已知词对未登录词进行有效表示,直观上可以提升模型表示容量,从而提升网络表示能力。
猜你喜欢
天中学刊(2022年4期)2022-11-08
北京航空航天大学学报(2022年8期)2022-08-31
网络安全与数据管理(2022年1期)2022-08-29
天津医科大学学报(2021年3期)2021-07-21
有色金属加工(2020年6期)2020-12-17
大连民族大学学报(2020年2期)2020-06-16
开放教育研究(2020年2期)2020-03-31
天津音乐学院学报(2019年4期)2019-06-11
电子制作(2018年10期)2018-08-04
中国交通信息化(2017年12期)2017-06-06
