
利用日志文件实现Hive用户操作行为还原
2019-11-12 02:01罗文华王志铭
中国刑警学院学报 2019年5期
罗文华 王志铭
(中国刑事警察学院网络犯罪侦查系 辽宁 沈阳 110035)
1 引言
随着移动设备的普及和互联网业务的创新发展,各行各业产生的数据日益增长并不断累积。这些海量数据的产生推动了高性能云平台的发展,而Hadoop是众多云框架中较成熟、使用较广的架构[1]。Hadoop使用数据仓库Hive存储海量的、非结构化的数据。运营人员可以通过Hive存储的海量数据挖掘出大量含有巨大价值的信息。因此在取证方面,针对Hive的取证工作至关重要,对于Hive取证工作的研究不仅可以遏制犯罪行为的继续,还能及时帮助企业、部门挽回无法估量的损失。
Hive与传统数据库[2]不论是在底层框架还是数据结构上都是大相径庭的,在取证方面唯一共通点就是都依赖系统日志及各种元数据。国内外在Hive取证工作尤其是用户操作行为还原方面的研究极少,因此本文通过分析HDFS元数据、Hive日志及Hadoop系统服务输出日志,构建Hive各层之间的逻辑关系,实现依据具体线索信息减少取证工作量,并通过多维证据的相互印证提高证明效力。
2 Hive存储逻辑关系
Hive整体的系统构架在运营层面来看可以分为元数据库和数据库两部分,但在用户行为还原角度可以分为用户层、文件层和物理层。具体结构如图1所示。
用户层即用户进行Hive操作直接对应的层面。首先用户通过接口将操作发送给命令解释模块driver,driver会将命令进行解释,然后交由文件层处理。元数据库单独存放于metastore中,由传统关系型数据库进行管理,通常为mysql,而数据就存储于Hive数据仓库中。在用户操作期间会在Hive日志中详细记录。文件层Hadoop将用户层driver模块解释的命令分解成多个任务发送给Hadoop的从节点DataNode,并将数据存储于Hadoop的分布式文件系统HDFS中,而HDFS的元数据fsimage与edit负责进行文件的管理和记录。物理层即搭建Hadoop框架为基础的底层Linux操作系统及其文件系统,HDFS架构基于特定的节点结构,主要包括NameNode和DataNode。HDFS通过块的方式存储文件,对应到底层Linux文件系统就是经过名称编号大小相同的文件。图2表示用户操作行为引起Hive3层文件变化的过程及记录变化的日志或元数据。
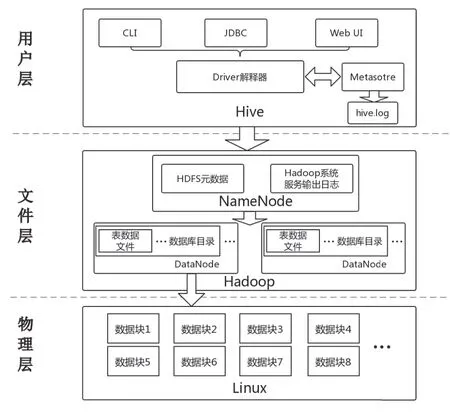
图1 Hive系统构架图
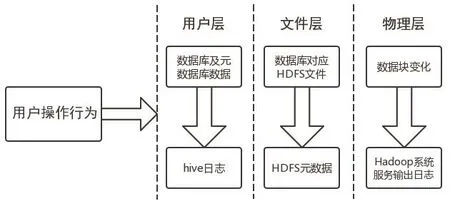
图2 用户操作行为对应的文件变化
要进行用户操作行为还原,就必须通过构建用户层、文件层及物理层的逻辑关系,以准确地识别用户操作行为涉及的逻辑文件和块,取证人员可通过3层逻辑关系进行有针对性的数据恢复和证据固定。
2.1 用户层与文件层的逻辑关系
建立用户层与文件层的逻辑关系,即如何通过用户操作行为找到操作所影响的文件层面的文件。用户的操作会导致HDFS文件属性的变化,并被Hive日志和元数据记录。因此用户层与文件层逻辑关系的建立可分为通过Hive日志获取相关数据库的HDFS路径信息和通过元数据库获取相关数据库的HDFS路径两种方法。
(1)通过Hive日志获取数据库线索。因不同平台环境下的Hive日志设置不同[3],取证人员可以通过Hive根目录conf目录下的属性文件hive-log4j2.properties来查看Hive日志的存放路径。文件具体内容如表1所示。

表1 hive-log4j2.properties主要内容
Hive日志会在达到系统设定的阈值后自动保存成名为“property.hive.log.file+日期”的旧Hive日志文件,并生成名为“property.hive.log.file”的新Hive日志,其中包含了大量用户操作的时间信息、具体操作内容及系统自动输出的记录。Hive日志中包含用户所有操作命令、过程及系统反馈等信息,取证人员可以将“command”作为关键字进行用户操作所有命令的检索(生产环境需要数据清洗) ,也可以将“create”作为关键字检索创建表的记录。在用户命令中就包括数据表的名称、创建时间及操作涉及到的HDFS路径等信息。在时间信息中mtime参数极为关键,只要进行了数据表内数据的增删改操作,都会使此表在HDFS中的mtime发生变化,因此mtime是逻辑关系建立的关键之一。Hive日志中的时间以太平洋时间的形式记录,而在HDFS的元数据中以时间戳的形式保存。关于日志中的HDFS路径信息极为详细,但是不排除日志被清除的可能,因此还有必要通过Hive元数据库提取HDFS路径信息。
(2)通过元数据库建立逻辑关系。Hive元数据是存储在 Hive 中的数据的描述信息。Hive将元数据存储在数据库中,默认使用derby维护,但只能实现单用户模式,而且存储目录不固定,不方便管理。因此在生产环境中是以Mysql来管理元数据库数据的。元数据库中共有53个表,但涉及用户层与文件层逻辑关系建立仅需要DBS、TBLS和SDS 3个表所存的数据进行结合,这也提高了通过元数据库建立用户层与文件层逻辑关系的可行性。
在串联DBS、TBLS和SDS时应以TBLS为核心,因为TBLS中的DB_ID、SD_ID可以分别串联表DBS与SDS。整个逻辑关系建立及后期数据块识别过程中涉及DBS、TBLS和SDS内字段如表2所示。其中包括表创建时间、数据输入输出格式等字段。
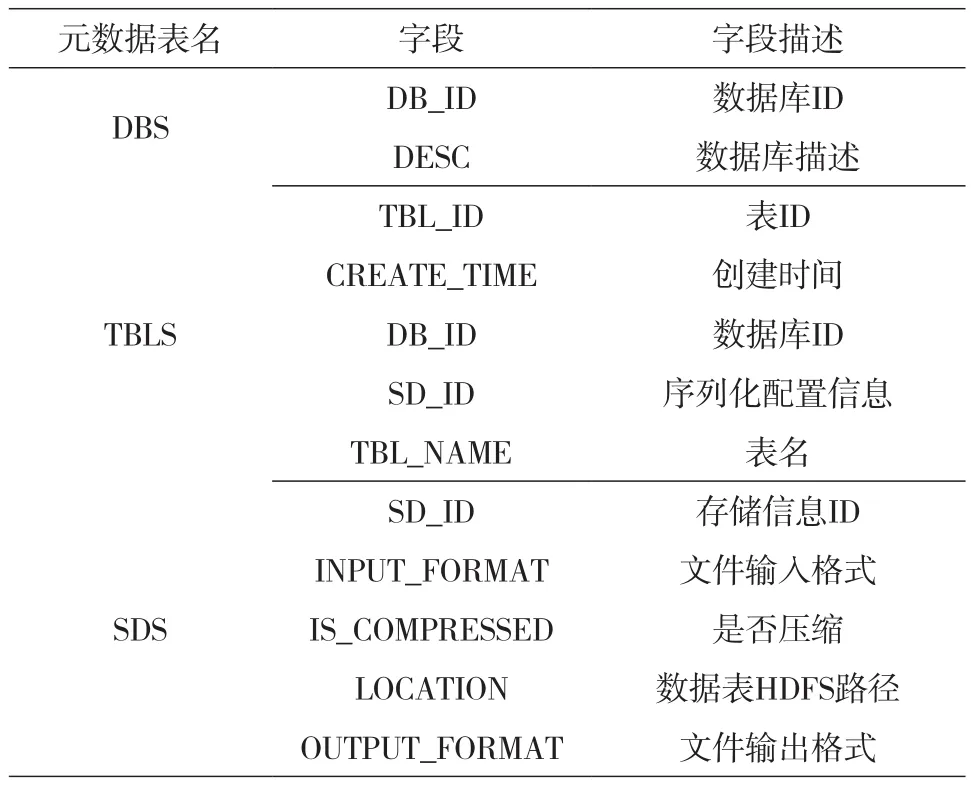
表2 元数据表关键字段及描述
构建用户层与文件层的逻辑关系除了通过Hive日志和Hive元数据库以外,还可以通过HQL中的desc命令及Hadoop的Web管理页面通过文件浏览的方式查询,但这些方式都是基于Hive元数据和HDFS元数据进行查询的,故在此不做详解。
2.2 文件层与物理层的逻辑关系
建立文件层与物理层的逻辑关系,即通过HDFS路径找到HDFS存储文件对应在物理层的文件块block的ID。除了之前提到的Hadoop的管理Web页面可以直接获取相关内容以外,还可以使用Hadoop命令达到同样目的,但归根结底还是HDFS元数据文件edit和fsimage中内容的可视化。通过Hadoop命令行的方式可以将HDFS路径(HDFS_dir)下所有文件对应的block全部列举出来,具体命令格式hdfsfsckHDFS_dir-files-block。HDFS是依据元数据进行管理的,没有edit和fsimage整个HDFS也是无法使用的,因此最根本的逻辑关系建立的途径依然是通过解析HDFS元数据edit与fsimage。
(1)通过HDFS元数据建立HDFS文件与block逻辑关系。edit日志对HDFS的每次修改进行连续记录。为每个修改分配唯一的、单调增加的事务ID。在给定时间间隔内启动Hadoop或触发检查点时,NameNode会将最新的fsimage与edit日志之后记录的所有事务合并,以创建新的事务并删除过期的fsimage。edit日志保存了自最后一次检查点之后所有针对HDFS文件系统的所有更新操作。如创建文件、重命名文件、移动文件、删除目录等。
fsimage维护命名空间的结构和文件的属性。例如所有权、访问权限、时间戳和分配的块等。HDFS支持逻辑上由inode表示的文件层次结构。fsimage维护着HDFS整个目录树,HDFS文件的元数据通过inode存储在fsimage中[4]。fsimage与edit需转换为XML格式可查看,XML形式的fsimage文件结构如图3所示。
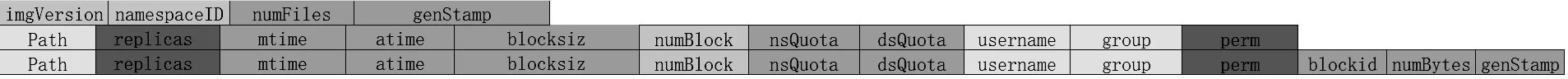
图3 fsimage元文件结构
在fsimage的Path中包含标签inode、id、type和name,其中name即文件名。在blockid中包含标签block、id,其中id就是block的id。取证人员在获取HDFS路径线索只有通过文件名在多个fsimage中检索,即可找到block的id,之前提到过的mtime在此也可起到block筛选的作用,大幅度减少取证人员的工作量。
(2)通过Hadoop系统服务输出日志验证。在以Hadoop框架为基础的云环境中的日志多种多样,总体上可分为两大类,即Hadoop系统服务输出日志和Mapreduce输出日志[5]。
Hadoop系统服务输出的日志默认存放路径为${HADOOP_HOME}/logs目录下,默认文件后缀为“log”;当日志达到系统设定的阈值后将会切割出新的文件,切割出的文件名格式为“XXX.log.num”,后边的num数字越大,表示日志保存时间越早。系统默认保存近20个日志。日志的格式为一行一条,依次描述为日期、时间、类别、相关类和提示信息。其中类别“INFO BlockStateChange”表示文件逻辑块状态的变化,与操作行为密切相关,是验证文件层与物理层的关键信息。
取证人员在通过建立3层的逻辑关系后最终可以在HDFS元数据中获取到block的id,在使用Hadoop系统服务输出日志中需要使用到的信息为mtime与block的id,验证过程分为两步进行。第一步是将HDFS元数据中的mtime转为太平洋时间在Hadoop系统服务输出日志中检索,将block的id设为关键字进行检索。第二步为比对第一步的两项检索结果,看是否存在重合。若存在则说明数据块缺失在修改时间有所变化,验证在Hive日志中检索出的内容,若无重合或未检索到相关内容,则说明Hive日志或Hadoop系统服务输出日志可能存在缺失、丢失等灾难情况。
3 Hive数据存储格式及特征
通过实现3层逻辑关系的建立,取证人员最终可以实现用户操作行为记录在文件层面的还原,整个过程最终指向用户操作行为对应的HDFS文件在Linux的文件系统上存储的数据块block,但仍未具体到数据块存储的数据,故仍需进行数据块存储格式及特征的分析和识别。
3.1 Hive的5种数据存储格式
Hive本身不提供数据存储格式。其可以利用其他存储数据的格式,存储格式有5种:TextFile、SequenceFile、RCFile、ORCFile和Parquet。其中TextFile和SequenceFile为行式存储,Parquet为列式存储,RCFile及改进版本的ORCFile为行列式存储。行式存储跟传统关系型数据库一样,将数据记录分条存储。列式存储则是将数据按列分割后加入识别标记进行存储,可以实现跨越式查询。行列式存储则是综合以上两种方案,按行分割并按列存储。针对以上多种数据存储格式进行恢复数据块的识别,对于后期数据记录的提取具有决定性的作用。Hive存储格式的具体特点如表3所示。

表3 Hive存储格式及特点
因为Hive是文本批处理系统,在向Hive中导入数据的格式多种多样,比如数据源可能是二进制格式或文本等,而Hive不需要特定的数据格式,而是利用hadoop本身InputFormat API来从各种数据源获取数据,并使用OutputFormat API将数据存储为不同的数据格式。所以针对不同的数据源或存储成不同的数据格式只需不同的InputFormat和Outputformat类即可实现。在本文2 Hive存储逻辑关系章中已提到通过元数据库SDS可以查询到数据库数据输入输出的参数,这里不再详述。
3.2 ORCFile
ORCFile在Hive使用的5种数据存储格式中是具有最高压缩比和效率的,除特殊情况需要使用到Parquet以外,生产环境中ORCFile一直占据主导地位,因此本文特别针对ORCFile存储格式、存储方式及存储特征进行一定程度的分析,以便取证人员在进行后期数据记录提取时方便展开工作。
ORCFile是RCFile经过一些优化后的高效存储格式,其提供一种高效的方法来存储Hive数据。ORCFile克服Hive了其他数据存储格式的种种缺陷,提高了Hive的读写及处理数据的性能。ORCFile格式较RCFile减少了Namenode负载,同时还支持复杂数据类型、存储索引数据,支持脱离扫描标记进行文件分割等优点。
ORCFile是以二进制方式存储的,故无法直接读取,一个ORCFile包含多个stripe,每一个stripe包含多条记录,这些记录按列进行独立存储。同时ORCFile为自解析,包含许多元数据。ORCFile的文件结构如图4所示。
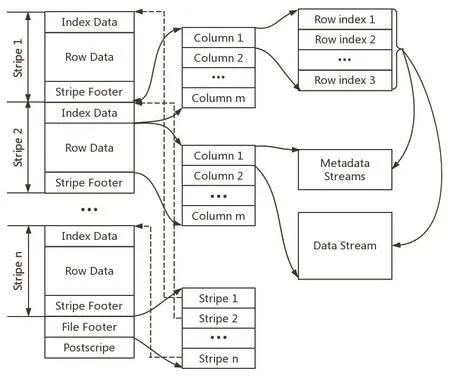
图4 ORCFile文件结构
(1)文件级元数据:包括文件的描述信息PostScript、文件meta信息(包括整个文件的统计信息)、所有stripe的信息和文件schema信息。
(2)stripe:一组行形成一个stripe,每次读取文件是以行组为单位的,一般为HDFS的块大小,其保存了每一列的索引和数据。其具体组成如下:①IndexData保存的是每一列的最大值和最小值,以及每一列所在的行。②row_index包括了该行的偏移量及改行的长度,正是因为row_index使得在读取数据时可以跳到正确的压缩块位置。例如:Stream:column 0 section ROW_INDEX start:3 length 11,Stream:column 1 section ROW_INDEX start: 14 length 28。③RowData保存的实际数据。④StripeFooterstream的位置信息。
(3)row group:索引的最小单位,一个stripe中包含多个row group,默认为10000个值组成。
(4)stream:一个stream表示文件中一段有效的数据,包括索引和数据两类。索引stream保存每一个row group的位置和统计信息,数据stream包括多种类型的数据,具体需要哪几种是由该列类型和编码方式决定。
Hive中提供了更详细的查看ORCFile元数据的工具 orcfiledump,orcfiledump将元数据以json格式返回,通过这些元数据可以帮助取证人员在后期数据记录提取的过程中所需要的关键信息,只有获取了这些关键信息,取证人员才可以进一步挖掘恢复数据块中的数据,重构数据结构并填充数据,以可视化形式将数据记录输出[6]。
4 Hive用户操作行为记录还原方法
基于日志文件的Hadoop数据仓库Hive用户操作行为还原方法的最大特点在于将Hive分为3层架构,并通过建立用户层、文件层和物理层之间的逻辑关系实现用户操作行为的还原。在建立逻辑关系过程中实现了多条途径一种效果的线索获取方式,可以针对线索信息进行印证以提高可信度。
4.1 Metastore信息提取
(1)使用提供的用户名/密码或远程访问Metastore服务器,并采取与国家授时中心等标准时间源的对时操作。
(2)依据Metastore服务器中的Hive多个配置文件获取Hive日志存放路径、连接元数据库的用户名和密码、HDFS路径、驱动、Remote方式等。若取证环境使用Remote,还应提取Mysql服务器地址及端口信息。
(3)访问在步骤(2)中获取的Hive日志存放路径,若事先掌握时间线索可以对多个Hive日志文件进行筛选。若Hive日志数据量较大应进行数据清洗,只保留用户操作的相关记录,若事先掌握时间线索可以对日志内容进行筛选。若发现日志文件缺失或丢失,应立即进行HDFS数据恢复。
(4)针对在步骤(3)筛选出的用户操作相关记录设定关键字检索包含HDFS路径的相关记录并整理。
(5)连接元数据库,通过将元数据表DBS、TBLS、SDS中的基于字段DB_ID、SD_ID进行合并,构建完整的数据表与HDFS的关系,将结果与步骤(4)得到的结果进行比对和验证。若有具体表的需求,可在步骤(4)(5)获取的信息中检索。
4.2 Namenode信息提取
(1)使用提供的用户名/密码现场或远程访问管理者主机,并采取与国家授时中心等标准时间源的对时操作。
(2)依Namenode中的文件系统的配置文件内容构建平台环境拓扑结构,确定各节点IP地址。并且获取HDFS元数据在集群中的实际存储路径。
(3)将HDFS元数据导出为XML格式,并将整个Metastore信息获取过程中获取到的需要检索的时间线索、HDFS路径线索及HDFS文件名线索分别设为关键字在XMLl中检索,获取数据id、修改时间和数据表文件名。若不存在,则说明文件已经被删除,应立即进行DataNode节点上的HDFS数据恢复[7]。
(4)将步骤(3)中获取到的block_id与mtime分别设为关键字在Hadoop系统服务输出日志中进行检索,获取指定block自存在以后的被操作过的所有记录,并比对结果检查是否有重合。若有重合则验证Hadoop系统服务输出日志中的内容。若检索无果,说明Hadoop系统服务输出日志缺失、丢失或被清理,应立即进行HDFS数据恢复。
4.3 Datanode信息获取
(1)依据从Namenode信息获取中构建的拓扑结构图和HDFS路径信息找到目标Datanode的IP地址,使用提供的用户名/密码现场或远程访问Datanode,并采取与国家授时中心等标准时间源的对时操作。
(2)将Datanode中对应block_id的数据块以只读方式导入至取证环境中。若无此block,则应进行HDFS数据恢复,并使用二进制编辑器查看block的头部,确定block使用的数据存储格式以及压缩方式。
4.4 数据记录查看
(1)在线索信息较为精准,数据量较少的情况下,TextFile、SequenceFile可以直接通过Hadoop系统命令进行明文输出。其他3种数据存储格式则可以使用元数据重构数据结构后进行查看。若存在压缩,则应针对相应的数据格式压缩方式进行对应的解压。
(2)在线索信息较模糊,数据量较多的情况下,可以通过将数据重新导入至集群取证环境中,通过集群的高运算能力进行对应数据记录查看操作。
5 实验验证
5.1 实验环境
为验证Hive用户操作行为还原方法,通过VMwareWorkstation搭建了以Hadoop框架为基础的伪分布虚拟机作为实验环境。主机配置为:Intel(R) Core(TM) i7-7660U CPU @ 2.50GHz 2.50Ghz;237GB硬盘驱动;操作系统,Windows10专业版 64-bit。虚拟机配置为:Intel(R) Core(TM) i7-7660U CPU @ 2.50GHz 2.50Ghz;20GB硬盘驱动;操作系统,Ubuntu17.04 64-bit;内存:2GB。Hadoop配置:Hadoop-2.8.1;块大小:128MB。
5.2 实验过程
整个实验过程参考本文4 Hive用户操作行为记录还原方法章节进行,因实验环境搭建为伪分布式结构,因此方法中的构建拓扑结构及使用Remote连接Metestore并未在实验过程中体现。整个用户操作行为还原方法可参考图5。
(1) 数据准备。首先在Linux本地存放一个text数据文件“info.txt“,其次进入shell通过命令创建数据库“myhive”,创建存储格式为TextFile的数据表“info”,并将info.txt的内容导入数据库中,最后将id为29的数据记录删除。
(2)MetaStore信息提取。首先访问Hadoop配置文件目录并查看配置文件“hive-log4j2.properties”的内容,在其中找到Hive日志存放路径进行访问,将日志目录下的所有日志导出至取证环境中并依次用编辑器打开。通过检索“createtableinfo”找到创建表info时的日志记录内容,可以获取到数据表的创建时间,数据格式及结构描述。在此条记录位置向下检索HDFS路径信息找到info表存储路径为“hdfs://localhost:9000/user/hive/warehouse/myhive.db/info”。与此同时还在日志中检索到涉及修改表info的日志记录,通过此条记录说明用户在太平洋时间2019-02-21 19:05:51运行命令将info表中id为29的记录删除。其次查看配置文件hivesite.xml并找到标签<name>对应内容为“javax.jdo.option.ConnectionPassword”和“javax.jdo.option.ConnectionUserName”的<property>标签,并分别获取两个标签下对应标签<value>的值,即登陆负责管理元数据的Mysql数据库的登陆用户名与密码。并在<name>标签内容为“javax.jdo.option.ConnectionURL”的标签<property>下提取到标签<value>值,即登陆元数据库的地址。因此使用用户名和密码连接Mysql数据库地址,并使用查询命令将元数据表DBS、TBLS、SDS中的基于字段DB_ID、SD_ID进行信息合并,最终获得数据表info对应的HDFS路径信息与在Hive日志中获取的内容相同,说明内容准确无误。
(3)Namenode信息提取。因实验环境为伪分布式,Hadoop的Namenode、Datanode及Hive的Metastore都在一台虚拟机中,故省略通过用户名/密码访问及拓扑结构构建等步骤。
首先访问Namenode存放配置文件的目录并打开hdfs-site.xml,获取内容如图6所示。
可知HDFS元数据存放目录为“/usr/local/Hadoop/hdfs/name”,访问此目录并将fsimage文件通过HDFS命令转换为XML文件并使用编辑器打开,因在Metastore中获取的HDFS路径中包含文件名,故在fsimage.xml中检索“<name>info</name>”,找到HDFS目录info对应的相关记录如图7所示。

图7 fsimage中关于数据表info的内容
说明info文件确实存在于HDFS文件系统中,且修改时间转换为太平洋时间为2019-02-21 19:05:55,在Hive日志检索时曾检测到删除id为29记录的命令运行时间为2019-02-21 19:05:51,而文件的修改时间为2019-02-21 19:05:55,经查询hive日志发现系统在2019-02-21 19:05:51运行删除记录命令并在2019-02-21 19:05:55完成命令执行过程,且info表在之后并无数据增删改的过程。
(4)Datanode信息提取及数据记录查询。要提取Datanode中的数据块就必须获取具体表所存储block的id号并进行检索。在进行Namenode信息提取时已在fsimage中获取到目录info的相关记录,而在此条记录位置向下顺延即可找到在HDFS目录info下面所存储的数据表数据文件的相关记录。据此在fsimage中info目录的相关记录下找到数据块记录,在记录标签<id>中获得info表的数据文件000000_0的block_id为“1073741868”,加上数据块编号前缀即可组成在物理层对应的数据块名称为“blk_1073741868”。因为每个数据表的数据文件默认命名规则是一样的,因此存在多表同块名的情况,若一表多块或需获取多表数据块都需通过fsiamge中的inode结构,而通过WEBUI则简化了这一过程。
通过浏览器访问Namenode的IP地址与端口号50070组成的URL,在文件浏览页面菜单可以直接获取HDFS文件对应的数据块信息,其原理即通过解析HDFS元数据文件中的inode等信息直接将块信息可视化显示出来。图8即数据表info对应的数据块信息。
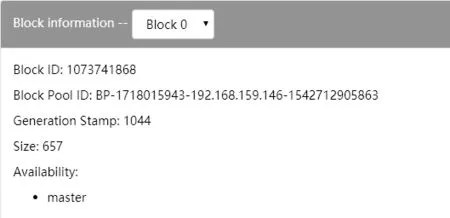
图8 WEBUI查询数据块id
通过Hadoop配置文件获取到Namenode节点的Hadoop系统服务输出日志的目录并用编辑器打开。直接搜索块名“blk_1073741868”发现有且仅有一条时间为“2019-02-21 19:05:53”表示块分配(allocate)的记录,在Namenode信息获取过程中曾得知在时间“2019-02-21 19:05:51”至“19:05:55”期间为执行删除id为29的数据记录的命令,而因为Hive一次写入多次读取的特性,删除数据记录的方式为将数据记录全部提取并重新写入,因此必然会导致数据块的变化,而新数据块“blk_1073741868”则分配给不包含id为29的数据记录。因此Hadoop系统服务输出日志中的内容也正印证了从Metastore与Datanode中获取信息的正确性。通过结合配置文件最终找到数据块存放目录,并将数据块提取至实验环境中。因为实验中使用的数据存储格式为TextFile,因此可以直接将数据块使用任何文本编辑器打开即可查看其中的所有数据记录。
6 结语
在大数据时代Hadoop框架的适用范围不断扩大,Hive作为Hadoop框架的数据仓库存储数据价值极大,为适应国内外对于在Hive取证尤其是用户操作行为还原方面的需求,本文以Hive为研究核心,将Hive分为用户层、文件层与物理层,通过分析各种日志及HDFS元数据提出了针对Hive用户操作行为的还原方法,同时在方法设计中考虑到证据链的完整性,通过多种方法互相印证的方式提高证明效力,并通过实验证明方法的可行性。本文将继续完善用户操作行为还原方法,针对多种数据存储格式的数据记录提取展开研究,使用户操作行为还原方法更好的贴近实战。
猜你喜欢
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
党员生活·下(2020年3期)2020-04-20
党员生活·下(2020年2期)2020-04-20
党员生活(2020年2期)2020-04-17
科学与财富(2019年27期)2019-10-25
电子制作(2019年14期)2019-08-20
铁道通信信号(2018年10期)2018-12-06
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
