
基于ZYNQ和CNN模型的服装识别系统①
2019-11-15 07:06熊伟,黄鲁
计算机系统应用 2019年11期
熊 伟,黄 鲁
(中国科学技术大学 信息科学技术学院,合肥 230027)
基于机器视觉的服装识别主要分为两大类,其一是采用人工提取特征进行识别,列如基于轮廓傅里叶描述子特征的svm 分类法[1],其二是基于深度学习的方法,列如基于残差的优化卷积神经网络服装分类算法[2].虽然深度学习的方法可以大大减少开发难度和周期,但是由于网络模型太大,FPGA 因有限的片上资源无法放下大型网络.针对这个问题,可以通过剪枝[3],低精度权值[4]等方法压缩模型,从而适应FPGA 有限的片上资源.
本文采用CNN 模型对视频流中的服装进行识别.该系统在ZYNQ 开发板上进行开发与验证,利用ZYNQ器件的软硬件协同的处理能力,对计算任务进行软硬件划分,在ARM 端完成图像采集、预处理和显示,FPGA端利用Verilog 语言设计卷积神经网络的硬件IP.采用AXI 总线实现片内通信,提出权重数据的重加载结构.可以根据不同应用场景选择合适网络模型重新训练,只需要在ARM 端传送已经训练好的权重数据而无需修改硬件.
1 卷积神经网络软件架构设计
1.1 CNN 模型搭建
本设计采用一种类似VGG[5]的一种自定义神经网络为基础,命名为Mini-VGGNet.如图1所示,基本结构与VGG 网络十分类似,该网络结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3×3)和最大池化尺寸(2×2).通过不断加深网络结构来提升性能.每一层卷积或全连接层后面都使用易于在硬件上实现的Relu 激活函数.

图1 网络模型结构
由于传统卷积神经网络的90%的参数都集中在全连接层,这里在第6 层卷积后面加入global_max_pooling[6]而不是普通的池化,使得7×7 大小的特征图直接变为1×1,大大减少了全连接层的参数.使得可以利用FPGA 的片上内存即可储存所有的权重参数.最后在全连接层后面加上Softmax 函数,实现11 个分类,第11 分类为未知类.
模型的时间复杂度即运算次数,可用FLOPS (FLOating-Point operationS)衡量,也就是浮点运算次数.公式如下:
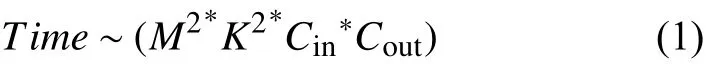
其中,M是每个卷积核输出特征图的尺寸.K是每个卷积核的尺寸.Cin是每个卷积核的输入通道数.Cout是本卷积层具有的输出通道数.由表1,可以看出90%以上的运算都集中在卷积层.
综上该网络架构的特点是:
(1) 只使用3×3 的卷积层堆叠在一起来增加深度.
(2) 使用最大池化来减小数组大小.
(3) 网络末端全连接层在Softmax 分类器之前.
(4) 卷积核都是8 的倍数,方便卷积核的并行化.
1.2 CNN 模型训练结果和参数定点化处理
根据本设计提出的网络结构,通过使用TensorFlow深度学习库来进行整体网络结构搭建,最终可以对fashion-minist[7]数据集实现92.39%的准确率.对比多份对该数据集提交的测试模型[8].由表2可以看出,Mini-VGGNet 仅使用了大约20 K 的参数,没有复杂的预处理操作就能达到相对较高的识别率.

表1 各层参数量
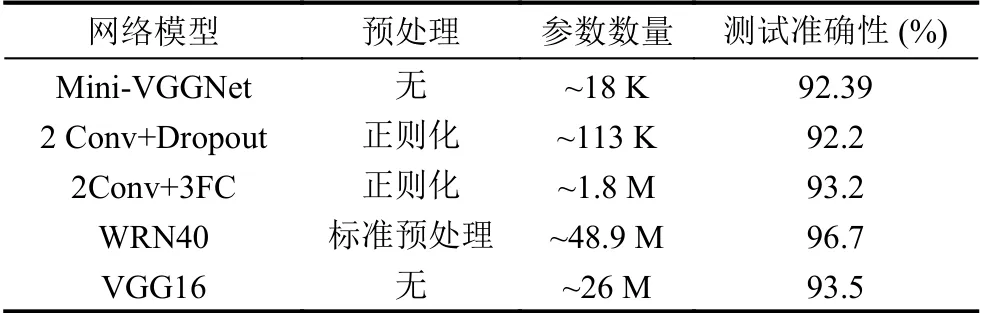
表2 不同测试模型
由于CPU 平台训练使用的是浮点数,所以需要对网络权重定点化处理.通过在软件端对比不同权重位宽对应的准确率,在FPGA 上使用11 bit 来进行定点化处理而不损失精度.在PC 端将权重定点化,按照网络模型的顺序将权重参数保存为头文件,通过ARM 将权重加载到PL 端的CNN IP 中去.
2 卷积神经网络硬件设计及实现
2.1 软硬件协同开发系统
本设计提出的服装系统发挥了ARM+FPGA[9-12]的软硬件协处理能力,将运算量巨大的CNN 放在FPGA端,充分发挥FPGA 并行运算能力.如图2所示,该系统在ARM 端实现摄像头的视频采集和前景分割,FPGA 端实现CNN 算法的硬件加速以及HDMI 的高清显示.

图2 系统框架图
PS 部分主要包括基于Petalinux 工具的嵌入式Linux 系统的构建以及交叉编译器的搭建,OpenCV 视觉库和QT 库的移植.PL 部分主要包括CNN IP 的编写和封装,HDMI 视频显示驱动.
2.2 Linux 下BRAM 驱动设计
在FPGA 上使用CNN 识别算法之前,需要将ARM端预处理的图片加载进来,众所周知,AXI DMA 是PS 与PL 之间高速传输的方法,由于数据量并不是很多,而且PL 与PS 之间传输地址不连续且长度不规则的数据,此时AXI DMA 便不再适用了.权衡之下,本系统基于BRAM 的方式,来进行PS 和PL 之间的数据交互.
当需要根据不同实际情况需要重新训练网络,必须经常改变权值,因此提出权重加载结构.在将它们发送到FPGA 层之前,ZYNQ 系统的DDR 内存将会保存权重.PS 通过AXI 总线把权重发给PL 端的BRAM,CNN IP 从BRAM 里面加载需要的权重数据.由于需要在Linux 下完成,因此需要移植AXI_BRAM 驱动,根据Vivado 工程的地址信息,更改设备树以将BRAM内存范围添加到内存节点并添加保留的内存节点,以便内核不使用内存,但会将内存映射到内核内存中.设备树添加如下:
memory {
device_type="memory";
reg=<0x0 0x40008000>;
};
reserved-memory {
ranges;
reserved {
reg=<0x40000000 0x8000>;
};
这样就可以在用户空间可以使用/dev/mem 去访问物理地址(0x40000000)大小为8 K 的BRAM,不修改内核.建立内存映射函数如下:
BRAM64_vptr=(u64*)mmap(NULL,BRAM_size,PROT_READ|PROT_WRITE,MAP_SHARED,fd,BRAM_pbase);
2.3 PS 端图像分割研究操作
由于摄像头采集的图像容易受光线干扰,而训练集的图像背景全是0,这样带来的后果就是网络仅对数据集比较友好,而面对实际情况就会出现相对较大的误差.这里采取两种办法来解决这个问题,
一种是将USB 采集的真实图像也加入到Mini-VGG Net 网络进行训练,这里一共拍摄了50×10=500 张,640×480 的真实图片,利用Python 进行预处理,这里仅仅就是利用双线性插值法resize 到28×28 大小.
另一种因为采集的图片是640×480,然后在ARM上对图片进行缩放加背景分离(为了还原和训练集的图片差不多),grabCut 算法在ARM 端比较耗时,为了满足实时性要求,即处理时间不能超过33 ms,因此系统采用先将图像缩放到56×56 大小,然后进行背景分离算法,再缩放到28×28,最后进行形态学操作,滤波输出28×28 的图片.
分割流程如图3所示,即640×480->56×56->grabCut->28×28.最后再将CNN_28×28 的图片送给CNN IP 来计算.
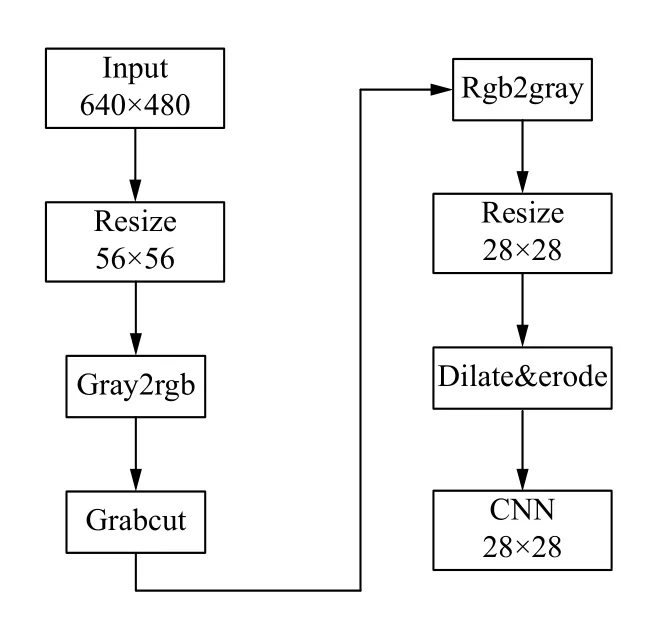
图3 背景分割流程图
2.4 PL-PS 数据加载结构设计
由于本系统的权重和图像数据都通过ARM 传给FPGA,图4为ARM 和FPGA 之间的数据加载结构图.ARM 在DDR 中按顺序保存指定层的权重.ARM 向FPGA 发送指定层的索引号、权重数量和需要在DDR中读取权重的地址.PS 通过M_AXI_GP 口向BRAM地址依次存入32 bit (仅使用低11 bit) 的权重数据.PS 每向BRAM 写完数据后通过AXI GPIO 给出一个上升沿信号.PL 捕获上升沿后立即将PS 写入的32 位数据读出,并写入CNN IP 的database 模块.同理,图像数据加载也是如此工作.
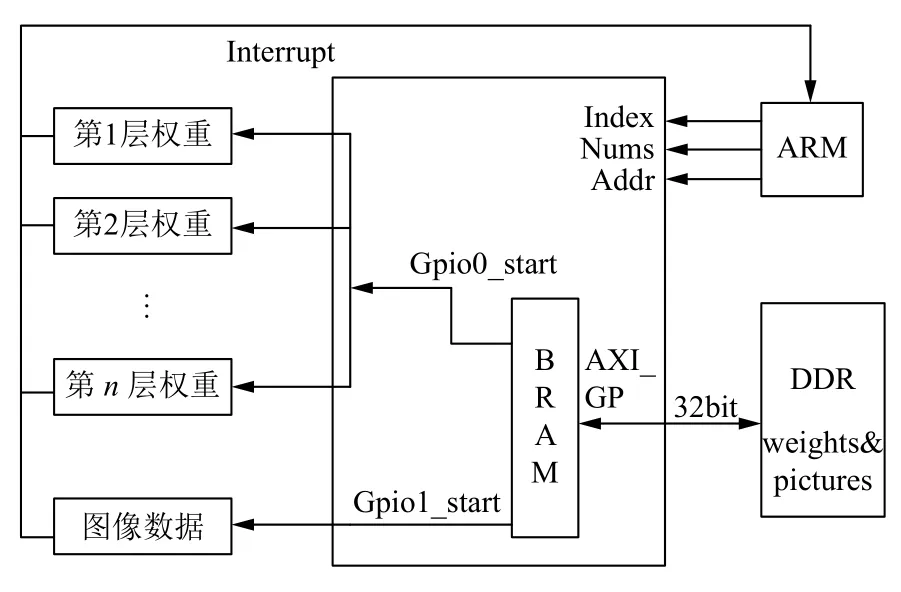
图4 PL-PS 数据加载结构图
通过Vivado 的ila(逻辑分析仪)抓取的波形如图5所示.可以看出,该模块能够正常的把784 个图像数据写入database 模块,并且拉低CNN IP 的启动信号(低电平有效).

图5 图像数据加载
2.5 CNN IP 设计
在系统框架中核心就是CNN IP 的设计.如图6所示,这个CNN 加速IP 在开始信号(start)的上升沿到来时开始工作.ARM 通过AXI 总线,将数据写入到CNN IP 的database 中,databae 存放CNN 需要的图像数据还有权重参数.通信是加速器的主要约束条件,在CNN 的整个前向计算过程中,数据吞吐量不断上升,对于大的特征图基本上都是传到片外内存中去,而DDR 数据交互时间对帧率的影响特别大.而本设计由于大大减少了网络结构和参数,优化feature map 数据的存储方式,使得所有数据可以存放在BRAM 中,避免了和DDR 之间数据交互,只需要在片上操作.这里需要两块片上RAM (0~28×28×8 和28×28×8+1~28×28×16) 来储存卷积计算的中间特征图.卷积模块从mem0 读取数据而计算结果写到mem1,接着下次就从mem1 读取数据而计算结果写到mem0,利用乒乓操作实现流水线,提高了数据吞吐率.流水化的设计可以提高加速器中的计算单元利用率.

图6 CNN IP 框架图
卷积层计算时整个网络的核心计算单元,图7是单个处理单元的结构图,该结构是由9 个乘法器和8 个加法器构成,本文利用im2col 操作和移位寄存器将图像和权重数据拼接成两个99 bit 的数据矩阵,单时钟周期可以对3×3 的特征图计算输出一个特征图.而权重数据复用可以降低带宽提高计算效率.特征数据由一个卷积窗口不断在特征图上滑动生成.
由于CNN 网络模型的卷积核都是8 的倍数,如图8所示,这里最高可以配置为8 个卷积单元同时工作,以更多的资源来换取运算时间.所以本设计能够实现单时钟周期72 次MAC(乘累加),工作在100 M 的频率下,峰值运算速率最高可达7.2 GMAC/s.与普通的嵌入式设备相比,计算效率具有显著的提高,极大地提高了数据带宽和传输速率.

图7 卷积处理单元(PE)
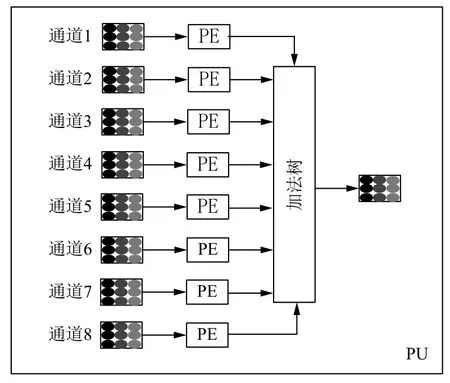
图8 卷积块处理单元(并行度为8)
卷积处理单元(PE)同样可以用来全连接层的计算,在全连接层,每一个神经元都与上一层相连接,网络的最后一层是32 个神经元,每8 个为一组,所以卷积处理单元在这里仅仅使用了8 个乘法器.迭代4 次,得到11 个输出.
本文采用Softmax 函数作为分类器输出,Softmax的公式如式(2)所示.

在布置前项传播时,我们不需要进行指数操作,指数在硬件上实施代价太大,而且没有必要,我们只需要找到11 个值中最大的那一个就可以,所以只需要一个比较器即可.
整个流程通过状态机来调度CNN 各个模块的运算.
3 实验分析
本文实验使用Xilinx 公司的Vivado 进行硬件开发和modelsim 来进行软件仿真.FPGA 使用ZYNQ 7000 系列AX7020 开发板.芯片为xc7z020clg400-2,该芯片拥有53 200 个LUT,106 400 个FF,140 个BRAM 36 KB (4.9 M),220 个DSP 资源,完全满足系统实验要求,将开发板和USB 摄像头还有HDMI 显示器连接,实验平台如图9所示.

图9 硬件开发平台图
3.1 数据集测试
将fashion-minist 数据集存放到DDR (8 GB)中去,该数据集一共有60 000 张训练图片和10 000 张测试图片,大小为28×28×1,在实验前在PC 上利用Python将10 000 张测试集数据转成二进制.ARM 通过BRAM把数据加载到CNN 中,计算完成触发中断,在中断里面对错误率进行统计,对比PC 机上利用Python 处理结果,如表3,可以发现在FPGA 上,准确率几乎没有下降.
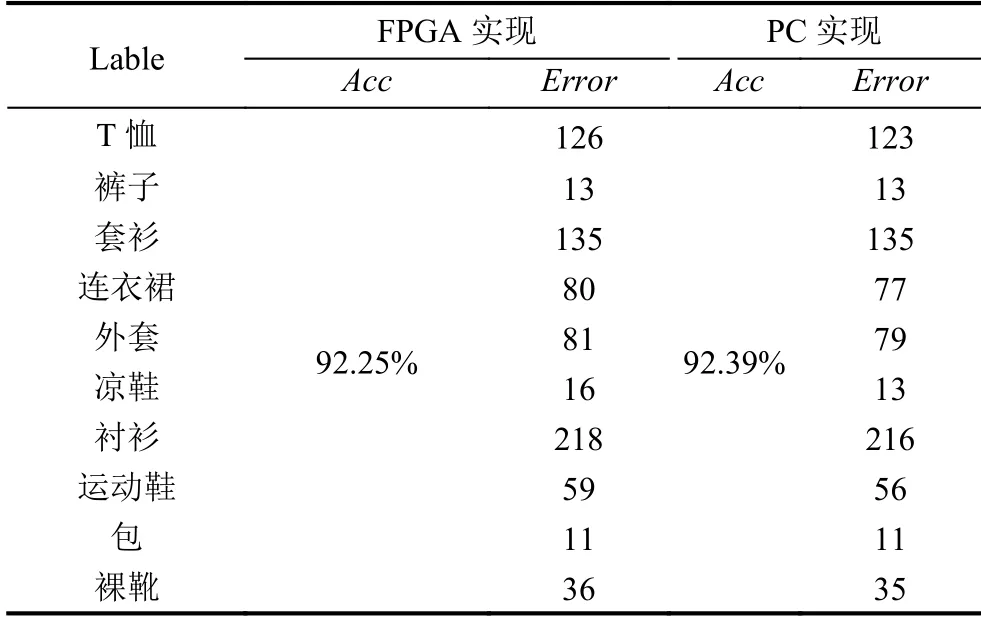
表3 测试集结果
3.2 实际图片测试
对电商网站上真实的图片进行测试,部分测试结果如图10所示,成功完成图像采集、预处理和识别结果的显示.

图10 服装识别实际运行结果
每种服装选取50 个样本,通过USB 摄像头对不同服装进行实时采集,利用OpenCV 进行预处理缩放到28×28 大小,再送到CNN IP 计算,并通过QT 显示.识别结果如表4,除了套衫是88%,其余种类识别率基本都达到90%以上.
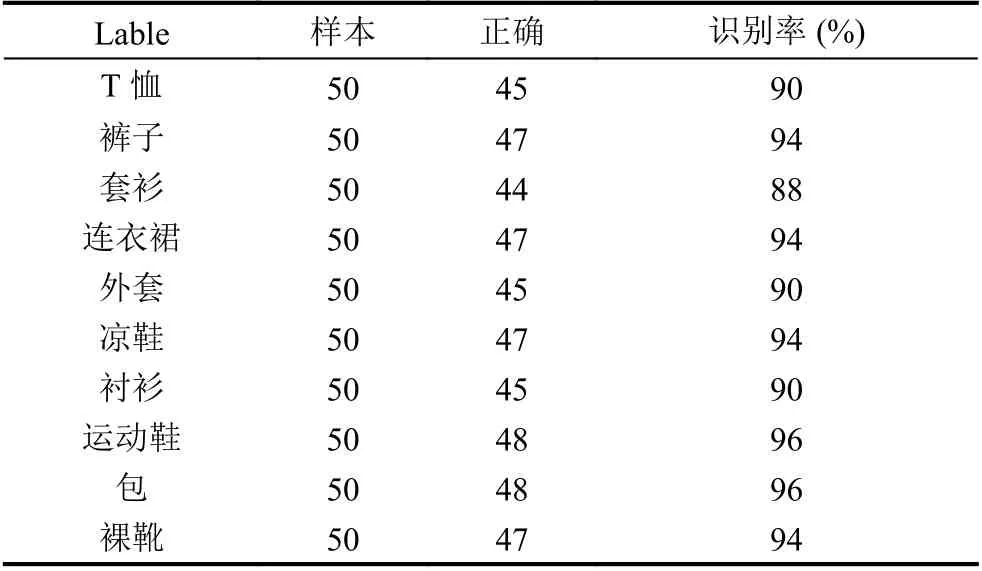
表4 真实图片测试准确率
最终FPGA 工作于100 Mhz 时钟频率下.表5列出了CNN IP 在配置为不同卷积块时的资源使用情况和计算速度.功耗由Vivado Power Report 获取.

表5 CNN IP 资源消耗以及功耗
由表5可以看出当卷积块为1 时,一副图片的识别需要9.094 ms,完全满足实时性的要求,DSP 资源消耗8%,BRAM 使用率达21%,在一些低成本的FPGA上可以实现,应用在加速物联网边缘设备机器学习推理的开发.在资源允许的情况下,最高可以实现卷积块为8 的并行度,识别一副图片仅需1.361 ms,DSP 资源消耗50%,BRAM 使用率达50%,速度提高了近5.68倍.在一些对时间要求非常高的场合,可以利用资源去换取时间.
4 结论与展望
本文提出一种基于ZYNQ 平台的服装识别系统.采用Verilog 设计服装识别CNN 的IP 核,留出信号接口,权重可加载,通用性好,便于移植,大大缩减了SOC的开发周期,对算法芯片化的施行也具有重要意义.
该系统采用软硬件协同的方式,成功移植Linux操作系统,利用OpenCV 和QT 将分割和识别结果通过HDMI 传输接口进行实时显示,达到有实时性好、界面友好,并且具有较高的识别率和较强的扩展性.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
心理学报(2022年5期)2022-05-16
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
当代陕西(2020年17期)2020-10-28
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
