
Web架构驱动的石油工业知识挖掘系统①
2019-11-15 07:07耿祖琨张卫山王志超
计算机系统应用 2019年11期
耿祖琨,张卫山,王志超,李 博
1(中国石油大学(华东)计算机与通信工程学院,青岛 266580)
2(东营市人力资源和社会保障局,东营 257091)
3(东营市勘察测绘院,东营 257000)
随着国家智能制造的大规模发展,石油行业不断创新发展,其工业设备也越来越复杂,传感器、摄像头等的广泛部署使得石油工业设备的运行状态得到有效监控,由此也产生了大规模的工业数据.石油工业大数据[1,2]的采集、处理、存储、分析和利用的价值不断提升,为指导石油探测、开采和企业改革发展的推进提供了重要依据.目前已经包含抽油机井基本状态信息、地质数据、勘探数据以及生产数据等等,现有的采油相关数据类别已达600 多种,而且相关数据每时每刻不在产生、交互、传回,石油大数据呈现爆发增长、海量集聚的特点.
随着数字油田以及智慧油田建设的不断深入,不同应用系统的数据结构呈现多样化发展,从原先单一数据结构转变为多维化、多元化结构,数据之间的显性与潜在的分布关系也越来越模糊.如何将海量的抽油机井状态数据、地质数据以及工作生产数据进行数据预处理、特征选择并进行关联性分析,以找寻对油气开采有利的生成信息,是指导项目实际生产、提升油气产量、降低产量递减速率、提升剩余油开采几率的重要数据依据.
与此同时,如何对石油大数据进行快速、及时的数据挖掘与知识发现,传统的单机服务器,需要利用现有的分布式集群以及快速通用的计算引擎,同时,需要现有石油工程以及采油工程等相关学科专业知识与通用算法,而且需要建立石油工业大数据仓库进行辅助存储,提高平台读写速度以及提升平台执行计算能力.
由此,石油大数据分析与数据挖掘技术二者结合成为趋势[3],通过石油工业大数据分析得到的结果可以辅助企业制定出符合工业发展的策略,并能依据石油工业大数据进行生产状况的及时调整,以促进国内整体石油工业水平的提升.
1 系统概述
目前大数据挖掘算法已经被应用到油气开采相关领域,但是相对油田行业众多技术人员而言,不仅对数据挖掘算法难以掌握,而且如何编码实现数据采集、存储、调用以及执行和可视化,和搭建大数据集群也是其中的难点.与此同时,各类大数据平台层出不穷,基于Python 的Orange 有较好的可视化编程工具和强大的Python 脚本,基于Java 的KNIME 集成了基础机器学习组件与数据挖掘算法等等.
如何将石油工业大数据与数据挖掘技术相结合[4-7],并且与具备可控算法流程的大数据分析平台相融合[8-11]是当前石油工业数据分析领域需要探索的问题.
尽管各种工具都有其优势,但是针对石油领域的知识挖掘系统而言,如下主要问题需要解决:
(1)针对数据采集过程中如何支持多种数据结构的并支持一键选择本地数据源导入到大数据仓库的数据采集操作模块问题;
(2)针对大数据处理过程中,如何选择大数据仓库中的数据源构建不同的数据集问题;
(3)在大数据分析工作流程的创建过程中,选择单数据集条件下的,如何通过简单的拖拉拽等操作创建单一算法模型或多个算法模型的数据分析处理流程问题;
(4)无法通过系统将数据源、数据集或者大数据分析结果进行二维图形或者三维图形的可视化展示.
针对当前石油领域的知识挖掘系统存在未能实现具有可控大数据完整分析工作流程界面的以及大数据信息可视化等问题,在本文中,提出了一个Web 架构驱动的石油工业知识挖掘系统,来解决此类问题,包括如下两个部分:
(1)可控工作流程的知识挖掘系统:该系统在选择需要进行分析的数据集后,支持用户采用拖拽操作快速完成数据建模,支持单数据源单模型算法构建、支持单数据源多模型算法构建,用户提交数据分析流程后,系统在大数据分析后台执行模型组建、数据处理、数据分析以及分析结果存储.
(2)自助式数据挖掘:该系统提供可视化操作的流程创建和丰富的图表展示分析结果,比如:表格、柱状图、雷达图、折线图、散点图等等,实现灵活、多样的数据分析,从而可快速发现数据中的规律.
在本节中,将介绍石油工业知识挖掘系统架构,主要包含以下4 大部分:数据采集层、数据处理层、数据服务层、自助式可视化层.以图1所示将分别介绍各个模块.
(1)数据采集层
石油大数据采集层包含3 部分:数据采集服务器、数据存储服务器和FTP 服务器集群.

图1 石油工业知识挖掘系统架构
原始数据(如采油领域相关文本数据、A1/A2 等数据库中存储的数据以及HDFS 存储的数据)视为存储在各个FTP 服务器中,通过数据采集服务器,将来自不同数据源的数据进行结构化和非结构化构建[12],数据集成后统一存储到数据存储服务器中.采用Hive 搭建数据仓库.同时,HBase[13]作为面向列存储的数据库,不仅可以存储结构化数据,而且弥补了Hive[14]在分析查询和实时查询的不足.并且,将非结构化数据存储在HDFS 中[15],由此,数据采集层完成了数据分析的重要底层部分-数据源和数据集存储.
系统的用户数据信息以及提供模型搭建流程等系统信息存储在结构数据库MariaDB 数据库中,它有着更好的子查询优化与线程池等优势.
(2)数据处理层
石油工业知识挖掘系统以Hadoop 生态系统[16]作为底层基础,系统将数据采集层中的历史数据存储于HBase 与HDFS 中,数据集数据存储于Hive 数据仓库中,通过数据流处理与批处理提供更快的速度给MapReduce,进而快速得到数据计算视图.在此,Spark[17]平台提供内存计算服务,Yarn 提供分布式计算框架,Storm 提供流计算服务与批处理服务.数据挖掘模块由Spark 平台和Hadoop 平台搭建,通过连接应用服务器的建模方案和动态算法库的算法信息,进行数据集引用、模型搭建和数据分析,可以提供数据解析、数据过滤、数据特征变化、数据统计分析以及校验转换等等数据预处理操作.
(3)数据服务层
由于数据处理层的处理结果需提供给应用服务器供用户查询,系统提供基于内存计算的Redis 数据库作为数据缓存区,提供查询数据分析结果与数据执行结果.它基于内存执行缓存存储,不仅可以提升数据查询效率,而且,支持数据持久化操作,支持异步操作将内存中的数据写到硬盘中,且不中断服务.所以,Redis[18]数据库提升了系统公共缓存能力,降低了系统存储数据库的负载.
数据仓库提供给用户允许有较低延时查询数据的服务,包含大数据量的数据集查询与历史数据分析结果查询等等.
以上保证系统不仅可提供实时查询当前任务处理结果,而且可提供有延迟的历史任务处理过程与结果.
(4)自助式可视化服务层
石油工业知识挖掘系统提供了自助式可视化层作为用户访问的窗口,有以下几个功能:
1)提交数据集至数据采集层
该数据集管理模块为用户提供多种数据源提交模式,用户可根据数据源格式选择提交模式,系统将数据源导入到数据采集服务器中,进行结构化数据与非结构化数据转换并进行数据集成,将分别存储到Hive、HBase 与HDFS 中.
2)拖拽操作完成快速数据建模
数据建模模块在用户选择数据集后通过应用服务器向动态算法库模块发送请求,服务器提供给用户数据建模模块,展示数据预处理、数据集成、数据挖掘算法等等各种算法,用户采用拖拽方式将算法拖到编辑区,用户按照要求输入算法不定项的参数,并选择连接新的算法,以此循环至模型搭建完成.
3)应用服务器将模型转至数据处理层
应用服务器将数据集ID 以及模型信息转至数据处理层,数据处理层在各个组成部分配合下,根据数据集ID 导入数据源并执行数据模型流程.
4)数据处理层完成数据建模与数据分析
数据处理层根据数据集与模型信息,调用动态算法库中算法jar 文件,并进行基于Spark 平台的分布式数据分析.
5)数据服务层将数据转至应用服务层
数据服务层将处理结果与之前数据集信息和模型信息回执到数据服务层,数据服务层进行快速缓存存储[18],准备提供结果给应用服务器.
6)跳转至分析服务界面
应用服务器从数据服务层获取实时分析结果与延时数据信息,通过可视化展示分析数据结果,并依据结果进行知识发现.
7) HTML5 图标展示
系统提供了多种图形化技术,帮助来理解数据间的关键性联系,指导以最便捷有效的途径找到问题的最可能的解决办法.它融合了图形、表格等多种可视化技术来处理多维数据,使得数据所表现出的特性、类别、模式和关联性等信息一目了然,在结果输出时可方便快捷的进行多种统计结果演示,支持散点图、分布图、折线图、饼图等.
2 实验分析
为了验证系统的有效性,通过研究抽油机井采油系统效率影响因素[19-21]的关联性的实验进行分析[22].包含数据集选定、模型构建、模型执行以及结果可视化展示四个过程.
实验采用FPGrowth 算法[23]进行影响抽油机井采油系统效率影响因素的关联性分析.抽油机井系统效率不仅反映当前抽油机的采油质量与效益,而且综合反映了油田的技术水平和装备水平,因此研究抽油机井系统效率提升是提高油田工作质量的重要方向.
操作步骤如下:通过选择华北油田2016-2017年抽油机井某区块某单口采油井生产数据的本地数据源进行数据源导入,实现将本地数据源转入到HDFS 和HBase 的大数据仓库中.选定该生产数据集后,针对该数据集进行数据预处理,首先进行筛选5 个有用列,包含日产液(t)、泵深(m)、动液面(m)、冲程(m)、冲次(n/min);其次针对数据集中的缺失值通过取该条数据集前5 个和后5 个数据的平均值进行数据填充;针对严重离群的数据进行该列均值填充法进行修正;最后,为了消除各特征的量纲影响,进行各个因素的标准化处理,对各列数据进行零中心归一化操作,将数据归一到同一数量级.数据清洗完成后,执行FPGrowth 算法对每个项进行挖掘,在界面设置算法支持度为0.62,可得到各个因素因素对抽油杆机采油系统效率的影响程度,即可得到整个频繁项集.流程创建提交完成后,大数据分析后台进行基于Spark 平台的分布式数据分析,分析完成后,数据结果存储于Hive 数据仓库仓库中,用户通过查看该数据流程分析调取最终数据分析结果并进行可视化展示.流程如图2所示,以此得到各个影响因素对抽油机井采油系统效率的关联程度,如图3所示.饼图效果图如图4所示.
通过石油工业知识挖掘系统分析的抽油机井采油系统效率与影响因素的关联性分析,华北油田的专家与工程师根据经验对结果满意,为接下来的抽油机井采油系统效率预测奠定了良好的基础.

图3 FPGrowth 算法关联性分析结果图
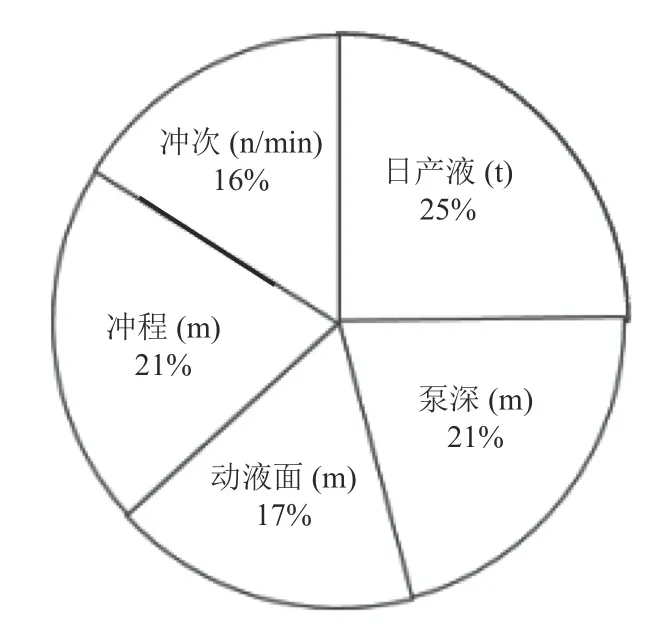
图4 FPGrowth 算法关联性分析结果饼图
3 总结
本文提出了一种Web 架构驱动的石油工业知识挖掘系统,用于以石油工业数据为基础,结合采油工程数据挖掘领域相关算法和大数据平台进行知识挖掘.包含了可控工作流程的知识挖掘系统,实现了通过简单的拖拽操作完成模型构建并进行数据分析;包含了自助式数据挖掘模块,通过可视化操作流程与丰富图表展示结果,帮助用户发现数据中的规律.用户可以直接忽略大数据底层搭建与编辑大数据算法等工作,直接通过本系统进行数据收集、数据提取、模型建模、模型执行以及结果可视化展示,目前已经在华北油田部署并运行超过1年,为该单位的石油大数据知识挖掘发挥了重要作用,通过发现石油大数据之间显性与隐性关系,指导实际项目生产,已经成为该单位提升油气产量、降低产量递减速率、提升剩余油开采几率和尽可能解决储采失衡问题的重要数据支撑与理论依据.
猜你喜欢
科教新报(2020年21期)2020-06-05
科技视界(2018年29期)2018-12-28
电脑爱好者(2018年14期)2018-08-05
科学与财富(2016年32期)2017-03-04
电脑知识与技术(2016年8期)2016-05-19
科教导刊·电子版(2016年6期)2016-04-19
现代经济信息(2016年3期)2016-03-24
电脑爱好者(2015年20期)2015-09-10
全国新书目(2014年7期)2014-09-19
能源(2014年8期)2014-08-25
