
基于迁移学习的暴恐音频判别方法①
2019-11-15 07:07胡鑫旭何小海熊淑华王正勇
计算机系统应用 2019年11期
胡鑫旭,周 欣,何小海,熊淑华,王正勇
(四川大学 电子信息学院,成都 610065)
随着近年来互联网与电影行业的快速发展,网络上包含的音视频信息与日俱增,为用户所共享的音视频中不乏包含有暴力恐怖音视频,这些暴恐音视频将产生不良的网络环境,对缺乏判断力的未成年人产生负面影响.针对此现象,通常由人工进行审查,审核通过以后才可进入网络,但由于网络上的音视频信息丰富,并且每日还会产生海量的音视频,所以这种做法不仅耗时耗力,而且影响了信息的传播速度.因此,自动检测与判别网络上传播的暴恐音视频成为近年来的一个研究热点.
通常情况下,对网络暴力元素的判别可以使用视频或音频特征,也可以两者相结合,由于音频在处理速度上较快于视频处理速度,对于实时性要求比较高的场景,使用音频特征的判别更具优势,所以基于音频信息的暴恐场景判别研究是极有必要的.
目前暴恐音频场景判别任务主要基于传统的机器学习算法,采用SVM 分类器或KNN 分类器.2006年,Theodoros Giannakopoulos 使用SVM 来检测暴力音频,提取音频的能量熵、短时平均过零率、短时能量、频谱衰减值等特征,训练集和测试集各为10 分钟的视频数据,最后达到14.5%的分类错误率[1].文献[2]同样使用SVM 分类器方法,在由15 部电影组成的MediaEval VSD 数据集上截取枪声、爆炸声等暴力片段,随机采样15 部电影中的非暴力部分,得到70.2%的分类准确率.但由于SVM 模型在训练数据较多的时候,需要计算的核矩阵大小也会增大,将会使训练效率降低,而较少的训练数据又限制了判别效果.2008年,Aggelos Pikrakis 使用KNN 分类器检测音频中的枪声,提取了MFCC、STFT 声谱图、色彩特征、熵、语谱图等特征,从30 部电影中截取5000 个音频片段进行检测,准确率为64.55%[3].可见采用传统方法进行的暴力音频场景判别效果都不尽人意.
2006年,Hinton 教授首次提出深度学习的概念,从此深度学习技术在图像、视频、语音、文本等领域得到了广泛应用.文献[2]搭建了基于深度神经网络的暴力音频分类系统,在暴力与非暴力音频各为30 分钟的训练集上训练,达到了77.38%的分类准确率.梁嘉欣等人针对传统方法忽略时序信息的问题,提出了一种基于张量模型的暴力音频检测方法,最终得到了89.6%的准确率[4].可见采用了深度学习方法的判别率往往相比于传统机器学习方法有一定提升,因此本文将卷积神经网络(Convolutional Neural Network,CNN)应用于暴恐音频场景的判别中.
由于数据集的限制,将深度学习用于暴恐音频判别的研究不多.针对判别网络上传播的一段只有背景信息的音频是否属于暴恐音频的应用背景,需要含有场景背景信息丰富并且包含暴恐元素的一段持续性音频序列,然而目前国内外并没有相关领域的公开音频数据集,于是本文从网上和电影中截取音频片段组成暴恐音频库,但暴恐音频来源受限并且数量较少,而CNN 往往需要希望有足够多的数据训练,性能才好,在数据集过小的情况下效果不佳.于是本文将迁移学习技术引入暴恐音频的判别中.
1 基于迁移学习的暴恐音频判别方法
迁移学习的核心是利用已有的知识,去解决不同但相关领域的问题[5].考虑到本文属于有监督到有监督的类型,于是采用fine-tune 的迁移学习方法.Fine-tune基于一个预训练好的模型,采用相同的网络结构,使用不同于预训练好模型的数据,根据所要完成任务的要求,调整输出,在预训练好的模型参数上进行再训练,是一种解决小数据库训练的方法[6].
图1为本文基于迁移学习的暴恐音频判别方法的总体框图,主要包括提取音频对数梅尔频谱特征、在源音频数据上预训练网络得到预训练模型、在目标音频数据上进行fine-tune 二次训练.具体为:将TUT 音频数据集作为源音频数据,提取音频对数梅尔频谱特征后,预训练网络得到预训练模型,然后将暴恐音频库作为目标音频数据,提取对数梅尔频谱特征后在预训练模型上继续训练得到最终的模型,最后在测试音频上运用最终得到的模型进行暴恐音频判别.此外,为提取更多的特征,在fine-tune 以后的网络结构中添加辅助网络,并将辅助网络部分的输出特征与输入特征聚合在一起共同输入分类层,更有效地利用暴恐音频中的信息.
1.1 对数梅尔频谱特征的提取
音频特征的提取主要有3 种方式:时域特征、频域特征及倒谱域特征的提取.时域特征通常是指短时平均过零率、短时能量、能量熵等,时域特征具有简单但不够丰富的特点;频域特征是指傅里叶频谱、滤波器组等.相比于时域特征,频域特征具有对外界环境更好的感知特性,但是频域特征无法得到频率分布随时间变化的状态,所以本文采用的是音频的倒谱域特征,典型代表是对数梅尔频谱特征[7],将一维的音频信号映射为时间-频域的二维信号[8],提取过程如图2所示.

图1 总体框图
本文产生对数梅尔频谱图的参数为:音频信号的采样率为44.1 kHz,预加重系数为0.97,采用汉明窗进行分帧,快速傅里叶变换(Fast Fourier Transform,FFT)窗口长度为50 ms,相邻窗之间的距离为20 ms,每帧包含2205 个采样点,梅尔滤波器的个数为200,图3展示了含有枪声的暴恐音频(a)与正常音频(b)的声音波形图与梅尔频谱图.

图2 提取音频对数梅尔频谱特征流程

图3 音频波形图与梅尔频谱图
梅尔频谱图的垂直轴表示频率,水平轴表示时间,颜色表示每个时间点各个频率位置处的声音的强度,图3(c)中梅尔频谱图的3 到4.2 s 显示的是出现枪声的梅尔频谱图,与其他未出现枪声的时间段梅尔频谱图有明显差异,由图3可见,含有暴恐元素音频的频率与强度在整个时间轴上分布不均匀,而正常音频的梅尔频谱图在整个时间轴上频率与强度分布基本均匀.提取特征后,将其转换为分贝标度,以便于计算.
使用频谱图的好处是把现在的音频分类问题变成了一个图像分类问题,将每个wav 文件转换成二维自变量(时间-频率)的频谱图,每个频谱图存储在与其类别相对应的文件夹中.一个10 s 长的音频,采样率为44.1 kHz,共有44.1 kHz×10 s=441 000 个点,分帧过后,因为帧移为20 ms,即帧移为882(44.1 kHz×0.02 s=882)个采样点,所以维度为500 列(441 000/882=500),行为梅尔滤波器个数.最终将每个10 s 长的音频转化为数组形式,维度为200 行、500 列.
1.2 预训练网络
在提取音频梅尔频谱特征后,将每段音频输入卷积神经网络进行预训练,本文在文献[7]的基础上搭建预训练网络,预训练网络结构如图4.

图4 预训练网络结构
值得注意的是为了减少神经网络参数与避免过拟合,采用全局平均池化层(Global Average Pooling,GAP)替代全连接层,搭建的预训练网络结构参数如表1所示.

表1 CNN 模型预训练网络参数表
将上述预训练神经网络在TUT 数据集上进行实验,该数据集包含公共汽车站场景类、超市场景类等15 个场景类,训练集中每类场景包含234 个音频,训练后的模型作为暴恐音频判别的预训练模型.
1.3 基于迁移学习的暴恐音频场景判别方法
由于TUT 数据集并不包含暴恐音频类,因此,需要对预训练模型进行迁移学习,保留预训练模型权重与网络结构,调整模型输出,在自建的暴恐音频库上继续训练,最终搭建的暴恐音频判别的卷积神经网络结构如图5.
考虑到1.2 节得到的预训练模型已经从TUT 数据集中习得了很多音频低层次特征,因此只需在预训练模型上做简单权重调整,所以微调部分迭代次数由600 改为300,学习速率由0.01 改为0.001,模型参数如表2所示.
2 改进的CNN-fine-tune 暴恐音频判别方法
因为在卷积神经网络中,最终任务的高级特征往往由网络后端习得,网络前端习得的只是低层次特征[9].为提取更多的高级特征,形成多级特征提取器,本文以CNN 模型作为基础网络,在截断的基础网络的末尾追加了几个特征层,这部分称为辅助结构.但如果只是简单地增加深度,会导致梯度弥散或梯度爆炸,所以新添辅助结构部分采用了一种类似于残差网络的结构,如图6所示.

图5 CNN-fine-tune 网络结构

表2 CNN-fine-tune 网络参数表

图6 添加辅助网络结构
辅助网络部分采用3 个连续的滤波器大小为1×50、1×1、1×1 的卷积层,最后一个1×1 的卷积层为了改变特征图通道数,使得经过3 次非线性激活函数计算,增强了对于复杂程度和非线性程度的表达能力和泛化能力.将这一部分得到的特征图与输入特征图聚合在一起,共同输入分类层:
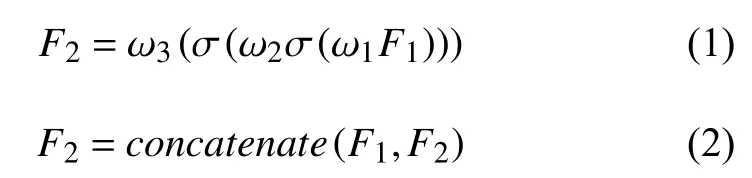
其中,式(1)中F1是基础网络的输出,也是辅助网络的输入,F2是辅助网络的输出,σ 为激活函数,ωi(i=1,2,3)为辅助结构中3 个卷积层权重,采用均匀分布初始化权重.式(2)意为采用keras 中concatenate函数,实现了原始CNN 网络特征图与辅助网络特征图的数据叠加.下面说明引入辅助网络的原理[10].
假设on是 网络第n层 的输出特征图,in是n层的输入也是第n-1层的输出,每一层输出特征图的计算公式如下:

辅助网络跨越多层,将输入通过恒等映射转换成输出,此时每一层的梯度计算公式如下:
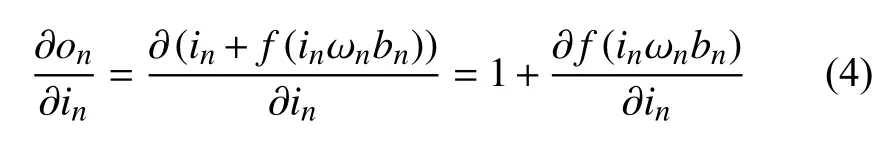
由式(4)可见在网络中加入辅助网络,可以使得梯度在反向传播时永远大于或等于1,这样就不会影响深层网络的训练.
3 实验结果与分析
本文是在Ubuntu16.04 系统下,基于Keras 深度学习框架,以theano 作为后端进行网络模型的构建和训练,实验采用NVIDIA GTX960 显卡进行加速.
预训练网络部分使用TUT 数据集,迁移学习网络部分训练与测试数据集组成如下:从Youtube 中下载了网友录制的一些恐怖袭击现场音频,同时也选取了少部分电影中的暴恐镜头音频,根据枪声、尖叫声、爆炸声、警报声、打斗声等截取音频.正常音频包括综艺节目片段、电影片段与生活场景音频,包含了笑声、说话声、鼓掌声、音乐声等.建立的数据集共699个音频片段,由于音频段时长各异,制作数据集时统一将尺寸设定为每个音频10 s,其中正常音频片段348 个,250 个正常音频用于训练,98 个正常音频用于测试,暴恐音频片段351 个,250 个暴恐音频用于训练,101 个暴恐音频用于测试.音频库分布如表3.
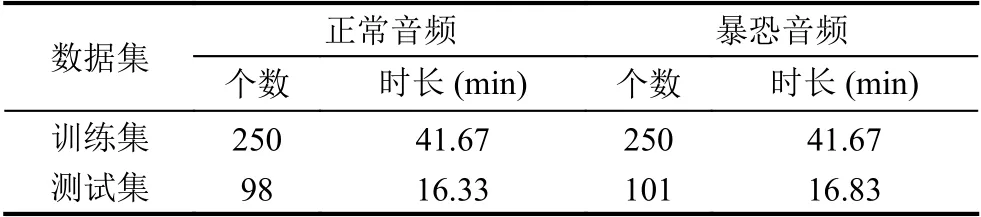
表3 音频分布表
本文研究的对象是一个二分类任务,各种类别样本数量相当,不需要考虑样本类别不平衡问题,性能指标采用准确率(Accuracy,Acc).Acc的计算过程如公式所示:

其中,Nt表示每类预测正确的样本数量,Nall表示每类总样本数量.
利用最终得到的暴恐音频判别模型在测试集的199 个音频片段上进行测试,得到未使用迁移学习与使用迁移学习,以及未改进CNN 与改进CNN 后得到的判别效果分别如表4所示,同时使用传统SVM 分类器进行比较.

表4 实验结果
由实验一结果与实验二结果对比可得,传统机器学习方法对于暴恐音频的判别不如深度学习方法.实验二和实验三对比可得,使用fine-tune 的迁移学习方法比未使用迁移学习的方法提升了6.93%的暴恐音频判别率和1.02%的正常音频判别率,平均判别率提升了3.97%.同时,实验四表明叠加辅助网络结构后对于暴恐音频和正常音频的判别率都有所提高,平均判别率相比于未添加辅助网络的提高了1.01%,可见叠加的辅助网络有助于得到更加可靠的特征提取效果.
4 结论
本文在判别网络上传播的一段音频是否属于暴恐音频的应用背景下,首先在公开的TUT 音频数据集上进行预训练得到预训练模型,然后利用fine-tune 的迁移学习方法将预训练模型与网络结构引入暴恐音频的判别中,在训练数据较少的情况下,也得到了不错的判别率,为提取更多的特征,在fine-tune 以后的网络添加了一种类似于残差网络的结构,进一步提高了音频判别率.
猜你喜欢
防爆电机(2022年3期)2022-06-17
莫愁(2020年7期)2020-03-17
红领巾·探索(2019年2期)2019-04-19
畅谈(2018年17期)2018-10-28
通信产业报(2018年40期)2018-01-22
移动通信(2017年3期)2017-03-13
科学与财富(2016年15期)2016-11-24
科技视界(2016年18期)2016-11-03
软科学(2014年8期)2015-01-20
阅读(2014年11期)2014-11-07
