
基于融合特征的视频关键帧提取方法①
2019-11-15 07:07张晓宇张云华
计算机系统应用 2019年11期
张晓宇,张云华
(浙江理工大学 信息学院,杭州 310018)
引言
随着5G 技术的普及,各种网络视频数量将会迎来进一步的增长,由此对视频的分类、检测、识别也必将被更广泛的应用.当前视频分类等研究通常是对视频帧的特征进行分析,然而视频由于自身原因通常会存在大量冗余帧,如果对所有帧进行特征分析,必然会对速度和效率有极大的影响,而用关键帧可以大大降低视频帧的冗余问题.
当前对关键帧的提取方法是基于图像的传统手工特征,如纹理特征、形状特征等,但这种提取方法通常只提取视频帧的相邻帧之间的关系从而忽略了距离较远帧的前后运动特征的依赖分析,出现漏帧的现象.因此有学者采用运动特征来提取关键帧,如通过分析视频帧的光流场进而根据运动场的变化提取运动特征,虽然相对颜色等特征,这种方法提高了准确度但光流场特征的提取通常比较复杂.本文选取并融合了图像的颜色特征和图像目标的形状特征作为传统手工特征.
在1989年Yann LeCun 初次提出“卷积”的概念,并构建应用于图像分类的卷积神经网络模型LeNet.在ILSVRC-2012 比赛中,Krizhevsky 等人设计出深度卷积网络模型AlexNet[1],将图像分类错误率从26.2%降到了15.3%,识别准确度远高于其他方法,这促进卷积神经网络在视觉图像领域得到快速的发展,发展至今,其在图像方面显示出了更优秀的表现.因此本文使用卷积神经网络提取特征向量作为视频帧的深度特征,然后选择合适的图像相似度度量方法计算图像间相似性.
基于以上思想,本文主要有以下3 个方面工作:(1)相对以往固定阈值的方法,本文采用自适应阈值,动态获取视频的关键帧数量;(2)分别提取深度特征与手工特征并计算相似度,融合两者相似度提取关键帧;(3)对比3 种视频关键帧提取方法实验数据,验证本文算法的有效性.
1 相关研究
早期对关键帧的提取大多是基于图像的底层特征,主要包含图像颜色特征、图像纹理特征、图像形状特征等[2].对于颜色特征的提取方法通常利用RGB 空间的颜色直方图、HSV 空间的颜色直方图、颜色聚合向量等[3];对纹理特征的提取方法通常利用LBP 方法、马尔可夫随机场模型法、灰度共生矩阵等;对形状特征的方法通常利用几何参数法、傅里叶形状描述法、小波描述子等.现有的特征提取方法大部分都是基于一种或多种特征的融合,但图像的底层特征通常提取有限,无法获取图片高级特征,虽然目前提取的效果不错,但仍有待提高.
随着深度网络结果的发展,人们发现对于视频类的图像分析,用卷积神经网络通过二维卷积核对视频帧进行滑动卷积操作,如图1所示,对视频帧底层特征进行抽象提取并组合,最终可获得视频帧更深层次特征的抽象描述.然而单个二维卷积核不能很好提取视频帧时间特性,所以文献[4]提出3D 卷积神经网络(3D Convolutional Neural Networks),如图2所示.3DCNN 对相邻的3 张视频帧用3 个二维卷积核卷积,并将卷积的结果相加,从而提取了某种时间的相关性,因此对特征的描述更为充分.
图1 2D 卷积

图2 3D 卷积
2 基于融合特征的关键帧提取方法
本文的底层手工特征由将颜色直方图特征和方向梯度直方图表示,深度特征通过3D 卷积神经网络提取,最后将深度特征向量相似度和手工特征向量相似度进行加权融合的方法进行相似度计算,最后得到视频的关键帧.整体结构流程如图3所示.

图3 整体结构图
2.1 视频帧手工特征的提取
HSV (Hue,Saturation,Value)[5]颜色空间的概念是Smith AR 于1978年初次提出的,其中H表示色相,S表示饱和度,V表示明度.色相H表示色彩属性,范围区间[0°,360°],其中0°表示红色,120°表示绿色,240°表示蓝色[6],整体呈为环形,色调随着角度的变化而变化.饱和度S表示颜色的深浅,取值区间为0%~100%,一般认为S值越高,颜色就越深,S取0 时为灰度图像.明度V表示色彩的明暗程度,范围区间也是0%~100%,随V值的增大,色彩逐渐变暗.HSV 颜色空间模型是RGB 颜色空间的另一种表示方式,但HSV 颜色空间模型相对来说更为直观,所以实际应用中更为广泛.视频帧为RGB 表示,本文要从视频帧中提取颜色特征需要将视频帧转换为HSV 表示,如图4所示.

图4 RGB2HSV 示意图
根据式(1)对H、S、V三通道特征量化构造特征矢量

其中,Ls、LV分别为S通道和V通道的量化因子,量化比例为16:4:4.通过HSV 颜色空间的3 个通道颜色特征,可以得到每个通道上像素的分布,从而获取到每个像素值对应的光谱信息,将颜色空间进行颜色量化,得到视频帧的量化颜色直方图,如式(2)表示:
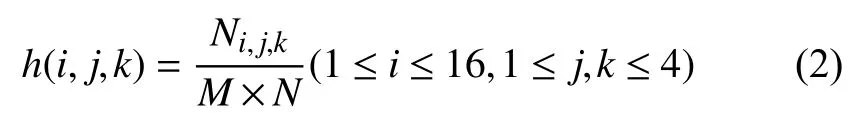
其中,Ni,j,k表示满足图像中H分量上第i个值、S分量上第j个值以及V分量上第k个值的像素点个数,M表示图像像素点总个数.
定义Hn(I) 和Hn+1(I) 分别是视频第n帧和第n+1 帧图像的颜色直方图,则两帧图像之间的相似度SHSV可以用两者之间的余弦距离D(Hn,Hn+1)近似表示,余弦计算公式如式(3)所示.余弦距离范围是0~1,值越小,则表示两帧图像越相似,反之表示差异越大.

颜色直方图不关心色彩所处的位置,对视频帧中由于光照变化带来的阴影干扰,抖动等有很好的区分去除能力,同时颜色直方图对背景的干扰也有很好的抑制作用,因此可以用来增强关键帧提取的抗噪性.
本文采用方向梯度直方图HOG (Histogram of Oriented Gradient)[7]来表征视频帧的目标对象形状特征.方向梯度直方图的重要思想是像素梯度或边缘的方向密度分布能够很好地表示图片中的目标形状.对梯度直方图的计算首先对图像进行标准化处理,之后用梯度算子[-1,0,1]及其转秩对视频帧分别进行卷积运算[8],从而得到x方向和y方向的梯度分量xGradient与yGradient.最后分别用式(4)、式(5)计算出像素点的梯度大小和方向.

式中,H(x,y),Gx(x,y),Gy(x,y)分别为输入的视频帧在像素点(x,y)处的像素值、水平方向梯度、垂直方向梯度[9].像素点(x,y)处的梯度幅值和梯度方向分用式(6)、式(7)所示:

将视频帧进一步划分为若干单元块,对单元块内若干cell 中每个像素点根据梯度方向做统计分析,得到以梯度方向为坐标轴的直方图[9],然后对cell 组成块并进行块内归一化,归一化公式如式(8)所示.将所有块的特征向量组合起来即可得到目标对象的特征向量.

式中,V表示包含给定块的统计直方图信息的未归一化向量,δ为趋于零的常数,‖V‖2为v的2-范数.假定第i帧整体特征向量用Vi表示,第i+1 帧用Vi+1表示,则两帧的相似度SHOG可根据向量夹角余弦值表示,值越接近1 则方向越吻合,两帧的相似度也越高,余弦值的计算如式(9)所示.
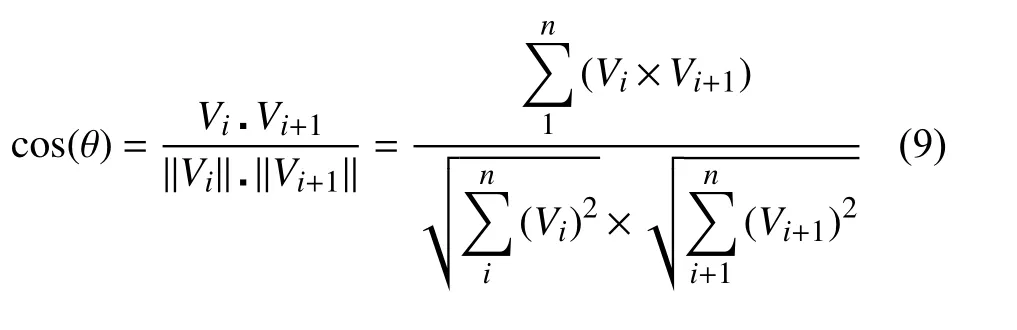
2.2 视频帧深度特征的提取
3D-CNN 结构由一个硬连接线层、3 个卷积层、2 个下采样层,1 个全连接层组成[4].本文提出用3DCNN 来提取视频帧的深度特征,计算其相似度,并与传统手工提取特征计算的相似度进行加权融合,进而根据融合相似度提取出视频的关键帧.对于深度特征,首先取视频中连续帧作为3D-CNN 的输入,经过第一层硬连线(hardwired)层编码获得视频帧的灰度、梯度以及光流特征信息,其中梯度描述视频帧的边缘分布,光流描述目标的运动趋向,然后将梯度信息和光流信息作为下一层卷积层的输入进行后续识别处理.在像素值(x,y)处,提取的特征单位值用Vijxyz表示,i表示层数,j表示特征图序号,单位值计算方法如式(10)所示.
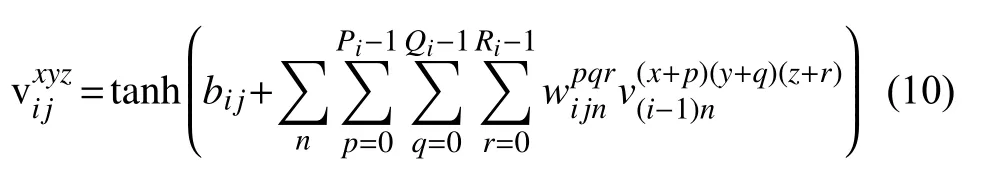
其中,bij表示特征图的偏置值,Wijnpqr是连接第n个特征图的核第(p,q,r) 的值,Pi和Qi表示核的高和宽,Ri表示卷积核在时间维度的大小.
通过多次卷积核卷积和下采样后,3D-CNN 将输入的连续视频帧转换为特征向量表示,这里,我们去掉原网络结构中最后的全连接层,选择最后一个卷积层的feature map 作为要提取的n帧特征向量Gdf.
由于深度卷积采样到的特征具有高维度的特性,因此本文使用哈希 (Hashing) 算法处理图像的深度特征.哈希算法将高维数据编码为一组二进制代码,并能维持图像或视频高维数据的元相似性[10].本文在卷积层后加入了Hash 层,用Sigmoid 函数作为卷积网络的激活函数[11],将特征值限制在0~1 之间,构造特征的Hash 码,最后通过Hash 码计算视频帧的Hamming 距离,Hamming 距离越小则表示视频帧的相似度Sdf就越高.假设两帧的Hash 码分别为α、β,则Hamming 距离D定义如式(11)所示.

2.3 基于深度特征与手工特征融合的关键帧提取
基于传统手工特征和深度特征的关键帧提取分为两步,首先使用传统手工方法提取出视频帧的手工特征,然后用3D-CNN 提取视频的深度特征,由于两者特征维度的不同,所以分别计算两者的相似度.首先根据2.1 节计算手工特征颜色直方图和方向梯度直方图特征的余弦距离得到传统手工特征的相似度SHSV和SHOG,然后根据2.2 节通过哈希算法计算得到深度特征的哈希码,并通过Hamming 距离得到深度特征的相似度Sdf,最后融合两种特征的相似度作为提取视频关键帧的依据.
特征融合方法分为拼接融合、加权融合、基于系数特征表示理论的特征融合、基于贝叶斯理论融合等.由于手工特征和深度特征有维度差异,本文选择加权融合方式,将两者相似度进行融合.首先对两者相似度根据权重大小做加权处理,然后线性融合传统特征和深度特征相似度,避免了手工特征与深度特征的维度差异,最后通过融合后的相似度根据阈值提取关键帧.相似度S计算方法如式(12)所示:

式中,α、μ、β分别为手工特征和深度特征的权重因子,比例采用1∶1∶2.在相似度计算时为了使关键帧的数目根据视频内容自动调整阈值,本文使用自适应阈值的方法设置相似度的阈值.

式(13)中,ε为相似度阈值,n为总的视频帧数量,fi表示当前帧,τ为域值的自适应调节因子.本文总体算法步骤如下所示:

Begin将视频分割为视频帧集F {f1,f2,f3,…,fn};定义空的关键帧集合KF{};输入融合后的视频级相似度集S{s1,s2,…,sn};For i=1:n;If (相似度S>阈值ε) Then 将fi+1 放入关键帧集KF{}Else i++;End if End for i输出采集到的视频关键帧集合KF{kf1,kf2,…}End
3 实验及分析
在本节中,为验证本文算法的有效性,本文使用Xshell远程工具在服务器上搭建PyTorch深度学习框架,使用python3.6进行实验及其相关分析.为了度量不同方法的实验结果,本文分别使用查准率、查全率、F1度量来评估算法的性能[3],公式如式(14)所示.
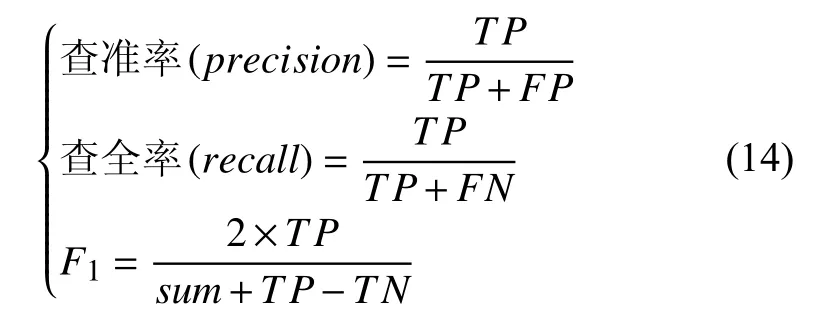
其中,TP表示真正例,FN表示假反例,FP表示假正例,TN表示真反例,F1是基于查准率和查全率的调和平均分数.
本文实验视频集从公开视频项目Open Video Project[12]网站上下载得到,下载的视频集共分为5 类,其中记录片、教育、历史、公共服务各选4 个视频,并随机从Youtube 网站另外选择4 个视频,共20 个视频构成实验数据集.为验证算法的有效性,本文选择两种常用方法进行对比实验,一种是基于帧间差分[13]的方法,一种是基于感知哈希算法[14]的方法.实验从5 类视频集中各选择一个代表视频进行实验,3 种算法提取的结果统计情况如表1所示,其中Video3 的可视化效果如图5-图7所示.

图5 基于帧差局部最大值提取结果

图6 基于感知Hash 匹配提取结果

图7 本文算法提取结果
Video3 是从长历史片中截取的一段,描述了生态学家研究云对麋鹿觅食的影响.从图5-图7可以看出基于感知哈希匹配相似度的方法提取效果最差,不仅存在冗余帧,而且存在大量漏检帧,基于帧差法的提取结果与本文结果数量相似,但本文提取的结果比帧差法提取结果更丰富,漏检帧更少.
表1中A表示基于帧差法提取算法,B表示基于感知Hash 相似度匹配算法,C表示本文算法.由表中数据可以看出3 种算法中,基于感知Hash 匹配相似度的算法F1值普遍偏小,基于帧差法的F1值与本文算法得到的F1值相比,本文算法在Video5 视频类型上与帧差提取算法有一定差距,这是因为Video5 视频整体色彩变化不明显,所以本文的手工提取特征部分提取效果稍差.但从整体来看,本文算法比帧差法和感知Hash 匹配法提取效果更好,准确率更高,冗余度更小,提取结果可以更全面的描述视频内容.

表1 对比实验统计结果
4 结束语
本文提出基于融合特征的视频关键帧提取的方法,充分利用了传统手工特征和深度特征的特点及优势.将提取到的视频图像的传统手工特征与基于深度神经网络提取的深度特征计算得到相似度并进行融合,以自适应阈值作为门限提取关键帧.通过对公共视频集进行实验,实验结果表明对关键帧提取有更为准确和全面的提高,与传统方式提取的方法相比,本文方法提取的特征更丰富,提高了视频关键帧的准确度并在冗余度方面也有良好的表现,对视频的分析研究具有重要的作用.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
现代计算机(2022年4期)2022-04-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
影像视觉(2018年12期)2018-11-29
软件导刊(2018年4期)2018-05-15
中学生数理化·高一版(2017年2期)2017-04-25
电脑知识与技术(2017年3期)2017-03-27
初中生世界·八年级(2017年3期)2017-03-24
