
基于深度置信网络的时间序列预测
2019-11-21 05:17佘佳丽刘艳珍
深圳大学学报(理工版) 2019年6期
杨 珺,佘佳丽,刘艳珍
1) 江西农业大学软件学院,江西南昌330045 ;2)南昌工学院电气与信息工程学院,江西南昌330099
在信息爆炸时代,人们通常把与时间关联的数据序列称为时间序列.时间序列是将某种统计指标的数值按时间前后顺序排列所形成的数列[1].迄今为止,时间序列数据正在生活的各个领域以倍速海量产生.比如交通序列数据,相应时间对应的交通流量,用有效方法对某重要路段未来的某时段的交通流量的预测[2],可有效调节路段交通拥挤和堵塞问题.再比如在商业经济中,对于观测到的每一时刻的股票利率、价格、开盘价、闭盘价和销量等的时间序列数据,随时间的推移呈海量式增长,对股票的预测[3]具有实用价值.
除了通过从统计学角度来考虑时间序列问题外,人工神经网络(artificial neural network, ANN)作为一种非线性方法,也在各个领域得到了广泛应用.ANN模型被用于非线性时间序列分析和预测分析中.杨祎玥等[4]使用深度循环神经网络结合小波变换方法,建立基于小波变换的深度循环神经网络的水文时间序列预测模型(wavelet analysis and deep recurrent neural network, WA-DRNN),并成功应用到高度非线性的水文时间序列中.YONG等[5]使用深度神经网络设计股票市场交易模拟系统来进行股市预测.HUANG等[6]研究了一种提取车内噪声特征的特征融合过程,提出了一种改进的使用连续限制玻尔兹曼机(continuous restricted Boltzmann machine, CRBM)对连续数据进行建模的深度置信网络(deep belief network, DBN).吴润泽等[7]提出一种基于栈式自编码神经网络的深度学习预测方法,并用于电网短期负荷预测中.传统的DBN存在梯度弥散、局部最小值问题、非线性时间序列预测的长期预测性能不佳和高维序列数据复杂度高等问题,为此,本研究提出时序深度置信网络(timing deep belief network, T-DBN)模型,通过改进贪婪预训练方法和重构误差,改进了DBN的预测精度.
1 三种神经网络
1.1 BP神经网络
BP(back propagation)神经网络[8]是目前应用最广的神经网络,是一种按照误差逆向传播算法训练的多层前馈神经网络.BP网络具有输入层、隐藏层和输出层,即在输入层与输出层之间增加若干层神经元作为隐含单元,隐含单元不可见,但改变隐含单元状态会影响输入数据与输出数据之间的关系,每层可有若干个节点(典型的3层BP神经网络结构图可扫描论文末页右下角二维码查看图S1).BP神经网络包含信息的正向传递和误差的反向传播这两个主要过程.从本质上讲,BP算法就是以网络误差的平方作为目标函数,使用梯度下降法来计算目标函数的最小值.
1.2 长短期记忆(long short-term memory,LSTM)
在众多递归神经网络(recurrent neural network,RNN)[9]的变体中,LSTM模型弥补了RNN 的梯度消失和梯度爆炸、长期记忆能力不足等问题,使得循环神经网络能够真正有效地利用长距离的时序信息.LSTM网络的设计就是为了解决长时依赖(long-term dependencies)这个问题,而循环神经网络被成功应用的关键就是LSTM. 在很多的长时时序任务上,采用LSTM结构的循环神经网络比标准的循环神经网络表现更好.
1.3 DBN
DBN是由多个受限波尔兹曼机(restricted Boltzmann machine, RBM)堆叠外加一个分类层或回归层组合而成的深度网络[10-11].其结构包含贪婪的前向学习过程和梯度下降的反向微调机制,使模型收敛到临近最优值的最优点,从而达到最佳的模型训练(DBN结构图请扫描论文末页右下角二维码查看图S2).
1.3.1 RBM
RBM是玻尔兹曼机(Bolzman machine, BM)的一种变形[12].一个RBM结构通常是由可见层和隐藏层两层神经元组成.隐藏层和可见层之间有对称连接,层内无连接(RBM网络结构图请扫描论文末页右下角二维码查看图S3).对比散度(contrastive divergence, CD)算法[13]令RBM的训练更简单.
RBM与BM的不同之处在于前者的可见层和隐层之间是独立的,层间全连接,层内无连接.在RBM基本模型中, 设v为可见层, 层内节点vi∈[0, 1],h为隐含层, 层内单元hj∈[0, 1],a和b分别是可见层和隐含层的偏置,ai为可见层第i个单元到隐含层的偏置,bj为隐含层第j个单元到可见层的偏置,w是可见层和隐层之间的权重矩阵, 其元素wij是可见层第i个单元和隐含层第j个单元的连接权重系数.网络通过能量函数E(v,h)为每个可能的可见的矢量对分配一个概率,则(v,h)的联合概率分布为
(1)
其中,Z为配分函数.为确保该函数分布是标准化的,可通过对所有可能的可见和隐藏向量对求和得到,即
(2)
其中,E(v,h)为RBM的能量函数,
(3)
RBM模型的最终目的是学习出参数θ={w,a,b}, 用以拟合给定的训练数据.给定训练样本{v1,v2, …,vn}, 经过训练RBM,调整参数θ并拟合训练样本,由相应RBM表示的概率分布尽可能大地与训练数据的经验分布相符合.一般采用最大似然估计的方法对网络参数进行估计.
1.3.2 CRBM
CRBM 在 RBM 基础上增加了两种连接:一是前n时刻可观测层与当前时刻可观测层之间的自回归连接;二是前n时刻可观测层与当前时刻隐含层之间的连接.
RBM可看作是增加了可观测层的前n时刻数据固定额外输入的RBM,由此增加了前n时刻与当前时刻的时间关联.虽然输入有所增加,但CRBM并不比RBM计算更复杂,在给定可观测层和前n时刻可观测层的数据后,隐含层的激活概率是可以确定的;同样,在给定隐含层和前n时刻可观测层的数据后,可观测层的激活状态之间是条件独立的.
2 T-DBN
2.1 T-DBN
本研究提出如图1的T-DBN模型.目前关于深度网络结构的选取尚无完善的理论依据,多数情况下3层比两层的重构误差更大[14-15],本研究为确定最优网络结构也采用文献[14]方法进行实验.结果发现,第3层即使使用很大的节点数,重构误差也比第2层的大,说明第3层是一个干扰层.因此,T-DBN是把接近时序序列的两个相邻的隐层组成一个RBM,即一个输入层和相邻隐层组成RBM1,隐层1和隐层2组成CRBM1,以此类推,隐层2和隐层3组成CRBM2.在T-DBN模型预训练阶段,使用贪婪学习的预训练方法,利用梯度修正并行回火(gradient fixing parallel tempering, GFPT)算法来训练.因为GFPT算法较CD和并行回火算法(parallel tempering, PT)等方法可大幅减小采样梯度和真实梯度之间的误差,提升RMB网络的训练效果[16].学习率设置为参数变化量值的1/1 000.基于重构误差理论来考究DBN模型的层数,确定网络深度.在反向微调阶段,利用BFGS拟牛顿法,通过反向微调模型内部参数,确保了模型的预测精确度.顶层输出模型使用softmax回归方法,将提取的特征映射到输出层,防止输出时出现收敛过拟合,最后输出预测值.
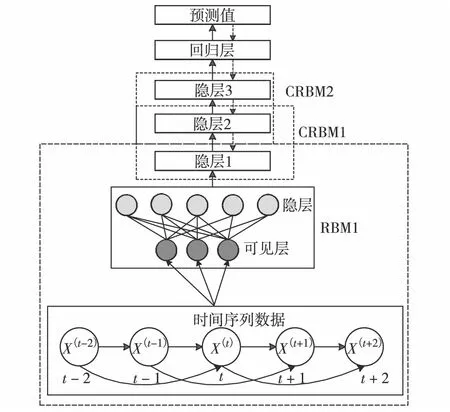
图1 T-DBN模型Fig.1 T-DBN model
2.2 T-DBN训练过程
DBN模型的训练过程包括无监督的逐层预训练(pre-training)和有监督的微调(fine-tuning)两个步骤.每层 RBM自底向上地提取输入数据,再通过各层RBM的训练,最后在回归层使用BP算法,将最后一层 RBM 的输出信息作为BP网络的输入数据,得到输出结果.预训练是自下而上的过程,反向微调是自上而下的过程,前者旨在大范围内找到模型的最优解区域,并搭建模型的主体结构,后者则在缩小的范围内找到最优解.在DBN模型中,BP网络的随机初始值易陷入局部最小值,且收敛速度慢,通过堆叠 RBM 网络,每层RBM都被优化,再传回回归层的BP网络,有效解决了该问题.
在对T-DBN模型进行整体训练时,首先要对输入节点数、网络层数、输出类别数量和最大迭代次数等参数进行初始化,再进入T-DBN的无监督预训练阶段,并在预训练到达最大层数时结束预训练.然后,使用BFGS法对模型进行反向微调,直至迭代次数最大,则DBN训练结束.(有关T-DBN训练流程图请扫描论文末页右下角二维码查看图S4).DBN的参数是在相邻两层之间进行调整,而T-DBN的是对整个模型所有层进行调整.
2.3 T-DBN 预训练
本研究采用GFPT算法作为RBM预训练的主要方法.使用改进的贪婪学习算法,可在相邻的两层之间将数据从可视层映射到隐层,再利用GFPT算法重构隐层数据回可视层.计算误差的同时调整内部参数.逐层训练RBM最终完成DBN的预训练.
图2是改进的贪婪预训练算法伪代码.

输入:训练数据 S={x1, x2, …, xt},网络层数L输出:模型参数θL={wL, aL, bL},初始化 θ={w, a, b},使用随机函数产生初始值1) For l={1, 2, …, L}, do2)While 没达到最大迭代次数或误差不满足条件3) H0(xt)←xt 4) for k∈{1, 2, …, L-1 }, do5) aj(xt)=bj+wjhj-1(xt) 6) hj(xt)=φ(aj(xt)) 7) 将hi-1(xt)输入GFPT算法8) 根据GFPT算法更新参数wij, ai, bj9) end10) end
图2 改进的贪婪预训练算法伪代码
Fig.2 Improved greedy pre-trainingalgorithm pseudocode
2.4 T-DBN反向微调
传统DBN的反向微调是采用BP算法,本研究采用拟牛顿法BFGS算法替代传统使用的BP算法进行DBN反向微调(全局微调流程图请扫描论文末页右下角二维码查看图S5).通过反向调整,误差自顶向下传播,有效提高了T-DBN模型的精度.在微调阶段使用softmax代替传统的logistic算法,避免了输出数据出现收敛过拟合的情况.若采用随机初始化参数方法,随着逐层训练,误差会逐层扩大,可能导致训练失败.RBM的训练精度随着深度增加而提高[15].经过预训练和反向微调的深度置信网络,可克服直接训练深度神经网络时易出现局部最优的问题.
3 运用分析
3.1 江西省农机总动力预测
农业机械总动力(以下简称农机总动力),指主要用于农、林、牧和渔业的各种动力机械的动力总和[17],这些动力来自牧业机械、林业机械、渔业机械、收获机械、农用运输机械、耕作机械、排灌机械、植物保护机械和其他农业机械.农机总动力是衡量区域农业机械化水平的主要指标,利用现有数据预测中国江西省2016—2020年的农机总动力,可为政府部门制定农业机械化发展规划及农机生产企业指定产品结构调整方案提供重要参考数据.
3.1.1 实验数据
表1列举了江西省1998—2015年农业机械总动力的数据[18].
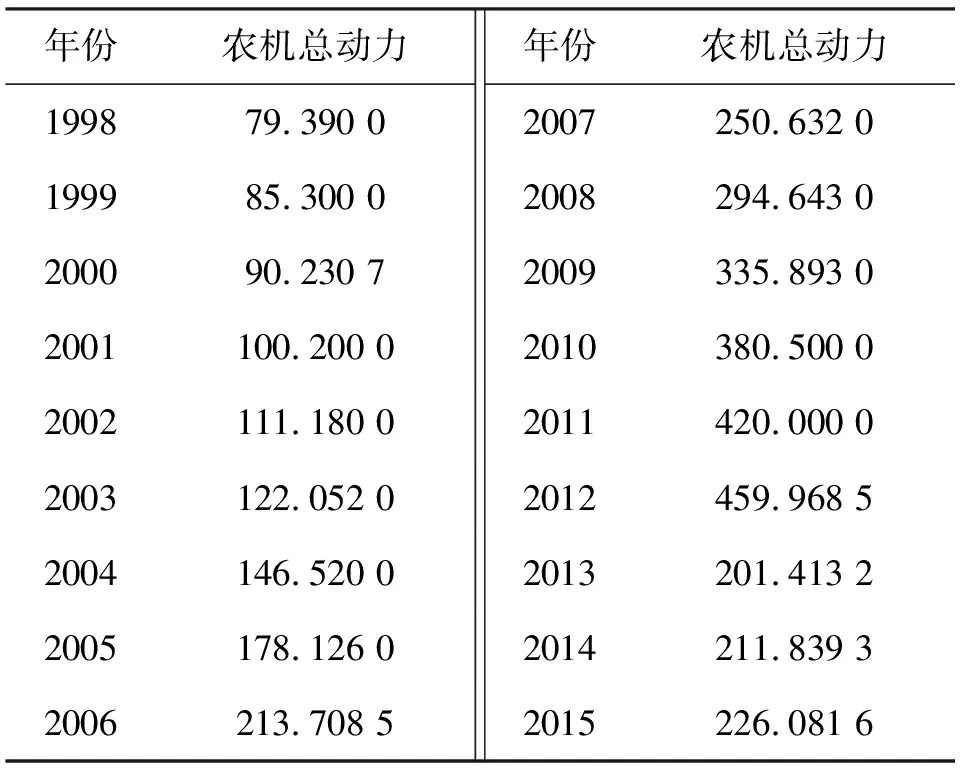
表1 江西省1998—2015年农业机械总动力
3.1.2 预测方法及流程
现有农机总动力预测方法主要有两类:① 建立农机总动力的时间序列预测模型,采用灰色预测、BP 神经网络[19]、模糊神经网络、支持向量机(support vector machine, SVM)和组合预测模型等方法;② 建立回归模型,选取影响农机总动力增长的因素,使用回归模型建立农机总动力与影响因素的关系模型,进而对农机总动力进行预测.本研究使用基于相空间重构和BP神经网络相结合的预测方法.
时间序列的相空间重构理论就是通过一维时间序列{x(i)}的不同延迟时间τ来构建d维的相空间矢量y(i)=(x(i), …,x(i+(d-1)τ)). 其中, 1≤i≤n-(d-1)τ.
江西省农机总动力数据是每个年份对应的数据,本研究取τ=1 年,d=3, 即选取顺序序列连续3年的农机总动力数据来预测第4年的数据.图3是农机总动力预测方法步骤描述图.

1) 对江西省农机总动力数据进行归一化预处理:xi′=a+(b-a)xi-xminxmax-xmin, i=1, 2, …, n. 其中,xi是输入样本数据; xi′是归一化后的数据; n是样本数. 2) 根据相空间重构理论确定输入样本维数d=3;3) 根据2)中的m选择神经网络输入层结点个数,构造出BP神经网络预测模型;4) 划分训练集和测试集.从原始数据中选择部分训练数据作为训练集输入到网络完成训练,直到训练达到要求为止,记录训练完成时的网络参数,若不符合训练目标,则返回3);选择测试样本输入,得到第一个预测点值,然后将第1点的预测值加入原数据集,预测第2点;依此类推,逐步生成预测结果.
图3 农机总动力预测方法步骤描述图
Fig.3 Stepwise description chart offorecasting method for agriculturalmachinery total power
实验选取顺序序列连续3年的农机总动力数据来预测第4年的农机总动力数据,所以采用3-20-40-1型网络模型结构,训练5×104次,训练的目标精度定为1×10-5,学习速率α=0.01,网络传递函数采用tansig函数,训练函数采用traingdx函数.把3层BP神经网络以同样的条件训练的结果作为基线(baselines).
3.1.3 预测结果及评价
网络预测的预测值、真实值和基线值的分布比较结果如图4.
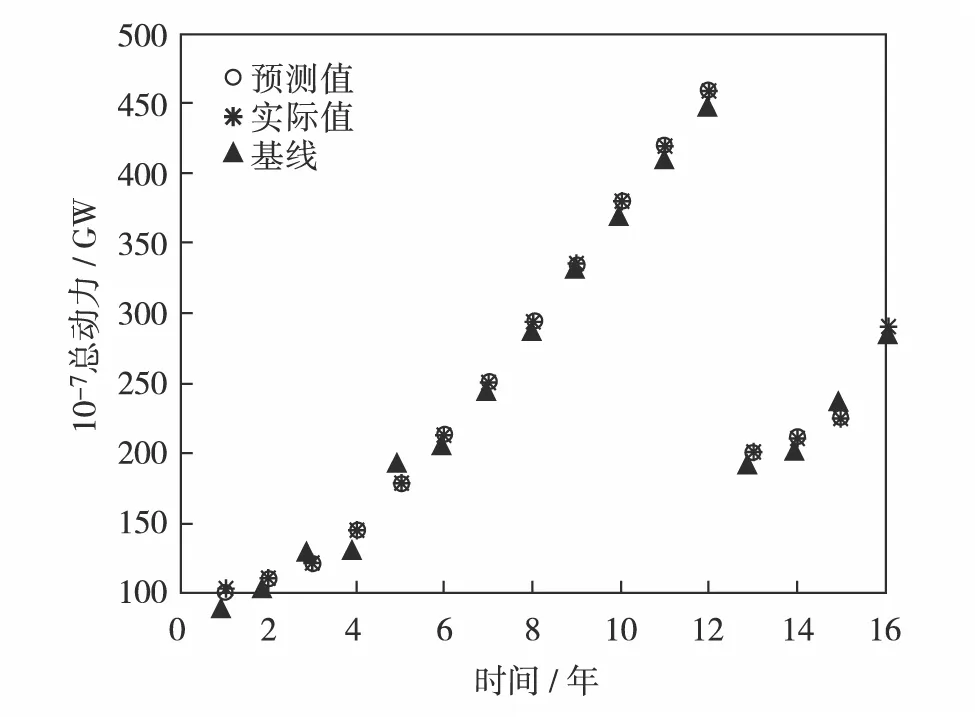
图4 预测值和真实值对比图Fig.4 Comparison between the predicted and the real values
使用4层BP神经网络进行预测得出2016—2020年江西省农机总动力依次为289.73、318.65、387.54、412.89和458.56 GW.
采用均方误差(mean square error, MSE)作为评价指标,其值为
(5)
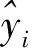
3.2 股票预测
股票是投资者的主要投资手段之一,但它是一个高度非线性的动态系统,其变化受到多方面的影响.研究股票序列价格预测不仅对投资者有很大的市场利益,也有很大的实际应用意义.MATTHEW等[20]提出人工神经网络在预测股票价格方面比其他模型更适合,至此,反馈神经网络、径向基神经网络等经典的基于神经网络的方法被应用到股票预测领域.
3.2.1 实验数据
影响股票价格趋势预测的因素很多,并且大多具有高非线性.本研究从同花顺软件中提取1990-12-20—2018-03-30时间段内,上证指数(股票代码:000001)每日的开盘价、最高价、最低价、收盘价和成交量信息作为股票价格的数据特征,来分析这些信息对股票价格的反应趋势.共提取到6 671条的每日股价信息,表头信息包括日期、开盘价、收盘价、最高价、最低价、成交量等信息.因此,针对DBN和T-DBN模型,输入特征包括开盘价、收盘价、最高价、最低价和成交量,输出特征为某支股票的预测最高价.
3.2.2 预 测
将上证指数股票数据训练样本分别输入DBN和T-DBN模型并进行训练,再将测试样本输入最终模型进行预测,通过比较两者预测的效果和准确率,借此评价这3个模型.实验中训练集和测试集的占比分别为85%和15%,上证指数股票数据共有6 671条数据,即将前5 670条数据作为训练集数据,将第5 800~6 671条数据作为测试集.
LSTM模型共迭代2 000次,设10个隐层单元,5个输入层和1个输出层神经元,α= 6×10-4. DBN模型采用4层5-20-20-1结构,用输入层和隐层构成第1个RBM,用隐层1和隐层2构成第2个RBM,另外一层进行逻辑回归的输出层,输入节点5个,两个隐层各20个节点,α=0.01, 最大预训练和反向微调次数为100. T-DBN模型采用5-20-20-15-1结构,用输入层和隐层构成RBM,用隐层1和隐层2构成第1个CRBM,用隐层2和隐层3构成第2个CRBM,另外一层进行分类回归softmax的输出层,设重构误差最大值为95%,隐含层3个,输入节点5个,第1个隐层节点数为20,第2个隐层节点数为20,第3个隐层节点数为15,输出层节点数为1,α=0.01, 最大预训练和反向微调次数皆为50.
将测试集数据分别输入到以上训练好的LSTM、DBN和T-DBN模型中,得到的股票数据真实值和预测结果(请扫描论文末页右下角二维码见图S7),两者基本吻合.
3.2.3 结果评价
使用预测正确率指标acc对模型进行评价,如式(6).预测正确率越大,表明模型的预测性能越好,对预测股票价格趋势越准确.
acc=n/len(test_predict)
(6)
其中,n为股票最高价的预测值与真实值的绝对值误差≤50的正确记录的个数; len(test_predict)为预测出的记录数量.
采用股票真实值和实验所得的预测值,分别计得LSTM、DBN和T-DBN模型的预测准确率为74.6%、77.9%和79.3%.对比3个预测模型在上证指数股票的预测准确率,T-DBN预测准确率明显高于LSTM和DBN.
结 语
采用时间序列预测方法研究主要是从针对线性序列的统计学方法上升到针对非线性序列的神经网络的方法.BP神经网络已被广泛应用,基于人工神经网络和支持向量机等浅层机器学习方法现已取得了较好的预测效果.但随着数据的复杂度提高,其长期预测能力不佳及易陷入局部最优等问题日益凸显.为此,针对时间序列预测问题引入深度神经网络,如RNN和基于RNN的各种变形模型(GRU和BPTT等).
本研究从深度神经网络的思路出发,提出时序深度置信模型T-DBN,使用贪婪学习和梯度修正并行回火采样处理输入特征值,适用于具有时间预测时序数据.以江西省农机总动力和上证指数时序数据作为输入特征值,通过实验讨论了该模型的深度和参数选取与优化,并与经典的深度学习模型LSTM和DBN进行对比.结果表明,对于农机总动力和上证指数的预测拟合度,T-DBN明显优于其他两种模型.未来我们将进一步研究模型参数的选取和优化,以及对其他类型时序数据拟合和预测效果.
猜你喜欢
四川农业与农机(2022年4期)2022-08-31
浙江大学学报(理学版)(2022年4期)2022-07-25
复旦学报(自然科学版)(2022年1期)2022-06-16
今日农业(2021年4期)2021-11-27
电子制作(2019年19期)2019-11-23
中国化肥信息(2019年5期)2019-06-25
人民珠江(2019年4期)2019-04-20
电子制作(2019年24期)2019-02-23
铁路计算机应用(2018年5期)2018-06-01
重型机械(2016年1期)2016-03-01
