
基于软件圈复杂度相关的不完美排错可靠性增长模型*
2019-11-28 03:09李耀敏
舰船电子工程 2019年11期
张 峰 费 琪 李耀敏
(1.91404部队 秦皇岛 066000)(2.江苏自动化研究所 连云港 222061)(3.中船重工集团第722研究所 武汉 430205)
1 引言
随着社会的发展,产品变得越来越智能,部分硬件已被软件完全代替,软件在当今社会发展中所占比重已远远超越硬件,且在产品事故率统计中,失效事件绝大多数都是由软件失效引起的,故软件的质量在人们生活中已变得越来越重要,软件可靠性直接影响着软件质量和开发成本[1~3],软件可靠性评测的关键是构建软件可靠性模型,因此建立科学合理的评测模型便成为软件评测中的关键问题。
1970年Goel和Okumoto首次使用非齐次泊松过程(Non-Homogeneous Poisson Process,NHPP)描述软件可靠性模型,G-O模型[3]。此后在此模型的基础上,提出 了 很 多 新模型[4~15],包括 Delayed S-shaped 模 型[9]、Weibull-TEF 模 型[10]和 变型 S型-TEF模型[8]。通过对这些模型进行分析,存在如下缺陷:
1)在建立可靠性模型时未与软件圈复杂度进行关联,不同等级的圈复杂度对应软件的复杂程度不同,测试人员对此进行检测时,检测效率会不同,开发人员对相应问题进行排错时,排错率及错误引入率也会不同;
2)在进行可靠性建模时,不能同时引入故障检测率、错误排除率、错误引入率。
软件圈复杂度(Cyclomatic Complexity)是一种代码复杂度的衡量标准,在1976年由Thomas J.McCabe,Sr.提出[11]。在软件测试的概念里,圈复杂度用来衡量一个模块判定结构的复杂程度,数量上表现为线性无关的路径条数,即合理的预防错误所需测试的最少路径条数。圈复杂度大说明程序代码可能质量低且难于测试和维护,根据经验,程序的可能错误和高的圈复杂度有着很大关系。
本文依据圈复杂度的值将此划分为三个等级低、中、高,针对不同等级的圈复杂度对应的代码状况、可测性、维护成本、对测试人员测试能力要求及开发人员对问题的排错能力如表1所示。
2 基于软件圈复杂度相关的不完美排错可靠性增长模型建立
在构建基于软件的不完美排错非齐次泊松过程可靠性模型时,需做如下假设:
1)软件执行的任务剖面与可靠性测试时所执行的剖面相同;
2)测试人员在任意时间序列内发现的问题是相互独立互不相关的;
3)在时刻 t发现的错误累计数 [M(t),t≥0]是一个随时间变化独立增长的过程,M(t)为服从期望函数 f(t)的泊松分布(备注:低圈复杂度、中圈复杂度及高圈复杂度分别服从期望函数为 f1(t)、f2(t)及 f3(t)的Poisson分布);
4)在时间间隔 (t,t+Δt)内,故障检测率 c(t)定义为:时间间隔(t,t+Δt)内检测到故障总数的期望值与软件剩余未发现故障数的比例,满足0<c(t)<1的条件,不同圈复杂度软件模块对应的故障检测率也不同,故进一步对不同圈复杂度软件模块的故障检测率c(t)做如下详细分解。

表1 圈复杂度对应划分表
(1)针对低圈复杂度的软件模块,对测试人员能力要求低,每个测试人员检测出故障的概率相似,故假设故障检测率为常量,即:c1(t)=c;
(2)针对圈复杂度为中及高的软件模块,记故障检测率分别为c2(t)及c3(t),不同测试人员故障检测率不同,经验丰富、测试人员学习能力越高、对软件越熟悉的人对应的故障检测率也越高。
5)在时间间隔 (t,t+Δt)内,排错率 p(t)定义为:时间间隔(t,t+Δt)内开发人员排除的错误数与单位时间内测试人员期望发现的故障数成正比,满足0<p(t)≤1的条件,不同圈复杂度软件模块对应的故障排除率也不同,故进一步对不同圈复杂度软件模块的故障排错率 p(t)做如下详细分解。
(1)针对低圈复杂度及中圈复杂度的软件模块,记排错率分别为 p1(t),因软件较简单,故开发人员为完美排错,可将所有错误都排除,即排错率为p1(t)=1;
(2)针对中圈复杂度及高圈复杂度的软件模块,记排错率为 p2(t)及 p3(t),因软件特别复杂,开发人员在排错时很难将所有错误排除,即满足0<p2(t)<1,0<p3(t)<1的条件。
6)在时间间隔 (t,t+Δt)内,错误引入率 y(t)的变化定义为:时间间隔(t,t+Δt)内预估错误总数的变化与单位时间内开发人员排除的错误数成正比,满足0≤y(t)<1的条件,不同圈复杂度软件模块对应的错误引入率也不同,故进一步对不同圈复杂度软件模块的错误引入率y(t)做如下详细分解:
(1)针对低圈复杂度软件模块,记错误引入率为 y1(t),因软件简单,故开发人员排错时相对容易,对排错是完美排错,即错误引入率为y1(t)=0;
(2)针对中圈复杂度的软件模块,记错误引入率为y2(t),软件相对复杂,开发人员排错时为非完美排错,但针对已排除的错误,不会引入新的错误,即错误引入率为y2(t)=0;
(3)针对高圈复杂度的的软件模块,记错误引入率为 y3(t),因软件特别复杂,开发人员为非完美排错,排错过程中会引入新问题,即满足0<y3(t)<1的条件。
依据上述6个假设,可以针对不同圈复杂度的软件模块进行可靠性建模,上述前3个假设为NHPP可靠性模型的统一假设,后3个假设是与软件圈复杂度相关联的可靠性模型建模假设。
2.1 不完美排错NHPP可靠性一般模型建立
依据基于软件圈复杂度相关的不完美排错可靠性增长模型假设4)、5)、6)可得如下不完美排错NHPP可靠性增长的一般模型方程组:
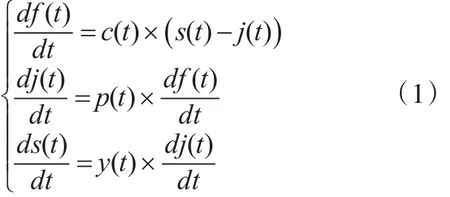
备注:f(t)为期望故障数,c(t)为测试人员对软件的故障检测率,s(t)为软件中预期故障总数,j(t)为已解决错误数,p(t)为开发人员在排除错误时的错误排除率,y(t)为非完美排错时的错误引入率。
2.2 低圈复杂度软件模块的NHPP可靠性模型建立
依据方程(1)及可靠性模型假设4)、5)、6)可得针对低圈复杂度软件模块的NHPP可靠性模型为
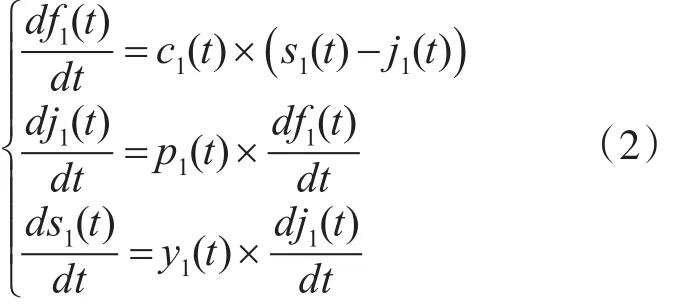
基于上述针对低圈复杂度,软件测试人员对错误的检测率及开发人员对错误的排错率分析得出如下条件:
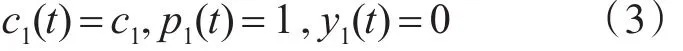
由方程(2)和(3)可得低圈复杂度软件模块的期望故障数为
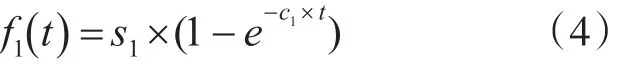
其中s1为初始时刻预期的软件故障数,c1表示测试人员的排错率。
2.3 中圈复杂度软件模块的NHPP可靠性模型建立
依据方程(1)及可靠性模型假设4)、5)、6)可得针对中圈复杂度软件模块的NHPP可靠性模型为

基于上述针对中圈复杂度,软件测试人员对错误的检测率及开发人员对错误的排错率分析得出如下条件:
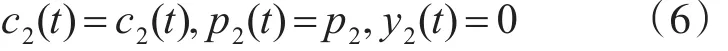
其中 p2满足0<p2<1的条件。
测试人员对中圈复杂度的故障检测率随着对软件产品的熟悉,故障检测率会提升,当学习到一定程度,故障检测率便会稳定下来,符合S型变化曲线,此块关于故障检测率本文用Logistic曲线来描述测试人员对故障的检测能力。

其中a为测试人员对中圈复杂度软件模块的初始故障检测率,b为测试人员学习能力的尺度。满足如下条件:0<a<1,b>0,依据方程(5)、(6)、(7)可得中圈复杂度软件模块的期望故障数为
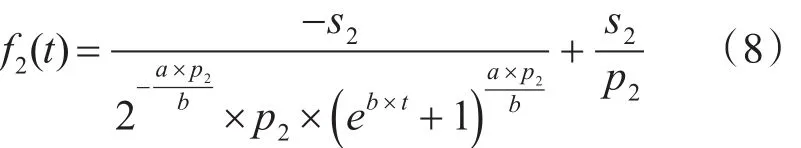
其中s2表示初始时刻预期的软件故障总数。
2.4 高圈复杂度软件模块的NHPP可靠性模型建立
依据方程(1)及可靠性模型假设4)、5)、6)可得针对高圈复杂度软件模块的NHPP可靠性模型为
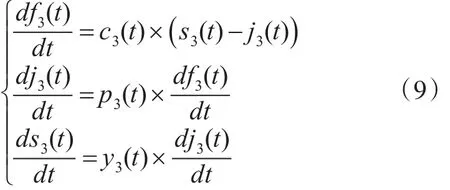
基于上述针对高圈复杂度的软件模块,软件测试人员对错误的检测率及开发人员对错误的排错率、错误引入率分析得出如下条件:
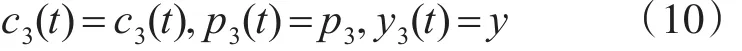
其中 p3、y满足0<p3<1、0<y<1的条件。
c3(t)在此借用中圈复杂度的模型,用Logistic增长模型来描述测试人员的能力。

其中m为测试人员对高圈复杂度软件模块的初始故障检测率,n为测试人员学习能力的尺度。满足如下条件:0<m<1,n>0,依据方程(9)、(10)、(11)可得高圈复杂度软件模块的期望故障数为
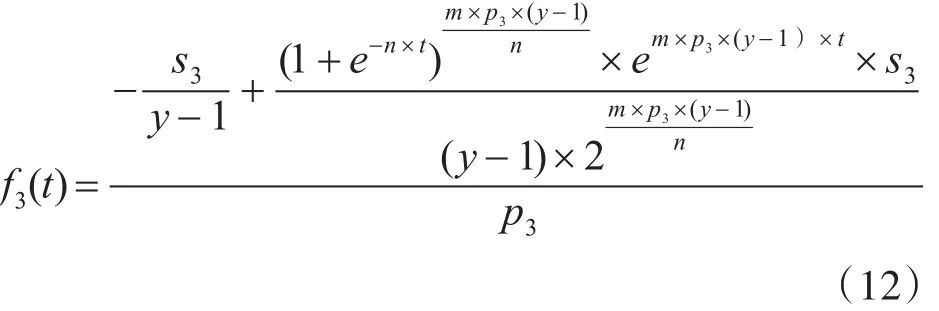
备注:s3表示初始时刻预期的软件故障总数。
由此本文分别求得了低圈复杂度、中圈复杂度、高圈复杂度软件模块的期望故障数,任一软件的期望故障数为
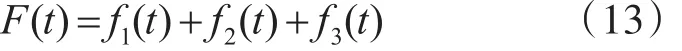
3 最大似然估计及模型求解
为了更好地预估不同圈复杂度的故障函数中的参数,采用最小误差平方和来计算:

其中k为测试阶段数,ti为i阶段软件累计运行时间,xi为第i阶段发现低圈复杂度软件模块的问题数,yi为第i阶段发现中圈复杂度软件模块的问题数,zi为第i阶段发现高圈复杂度软件模块的问题数,为获得低圈复杂度软件模块可靠性参数的最小误差平方和,SSE1分别对c1、s1求偏导,得如下方程组:

为获得中圈复杂度软件模块可靠性参数最小误差平方和,SSE2对s2、a、b、p2分别求偏导,得如下方程组:
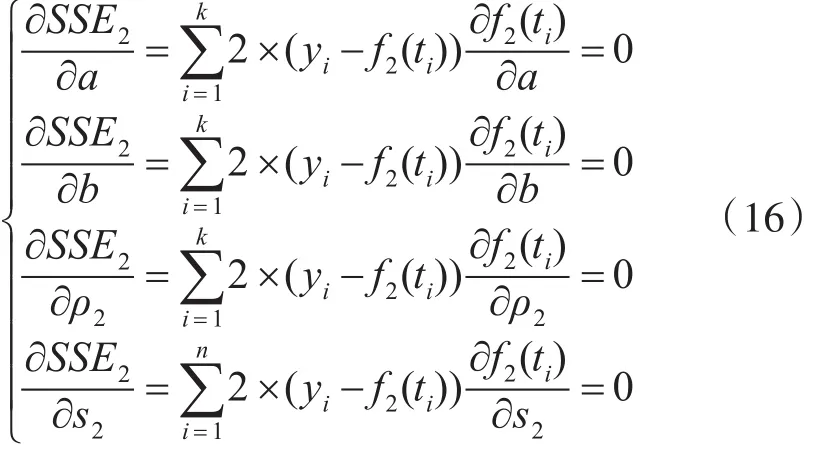
为获得高圈复杂度软件模块可靠性参数最小误差平方和,SSE3对s3、m、n、p3、y分别求偏导,得如下方程组:
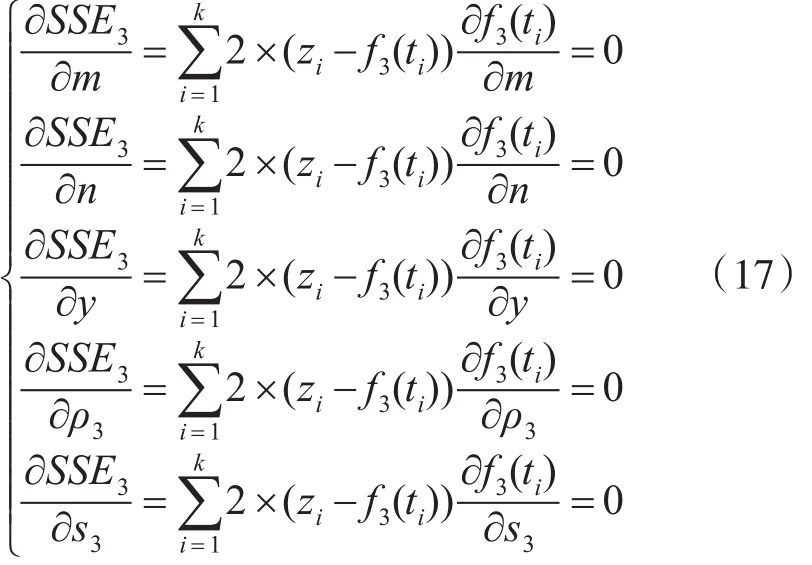
在 约 束 条 件 为 :0<c1<1 、0<s1<∞ 、0<s2<∞ 、0<s3<∞ 、0<a<1 、0<b<1 、0<m<1、0<n<1、0<ρ1<1、0<ρ2<1、0<ρ3<1、0<y<1条件下通过方程(15)、(16)、(17)即可求得参数s1、s2、s3、a、b、m、n、p1、p2、p3、y的值。
4 实验分析
为了证明本模型的有效性,并对新模型进行评估,引入某软件测评中心针对通信系统的测评数据进行评估,表2给出了问题的发布时间及问题所对应的软件模块的圈复杂度等级,测试团队从第1周开始测试直至第32周结束共发现问题总数为1264个,软件问题与检测时间、软件模块对应情况见表2~表5。
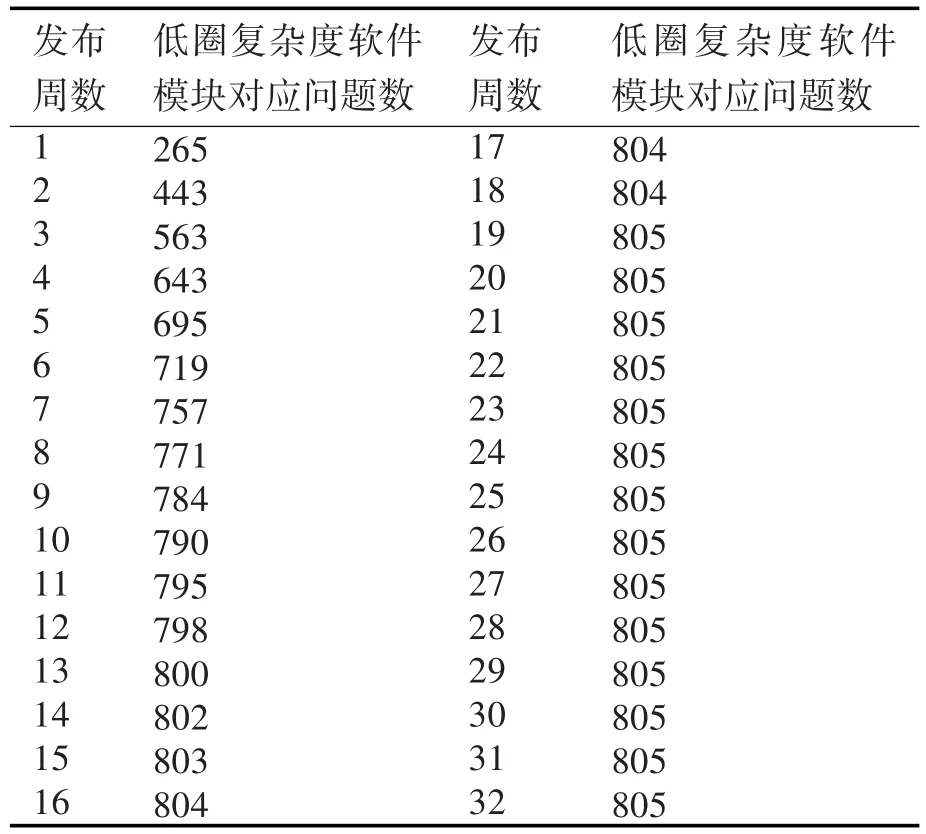
表2 低圈复杂度软件模块对应问题缺陷统计表

表3 中圈复杂度软件模块对应问题缺陷统计表
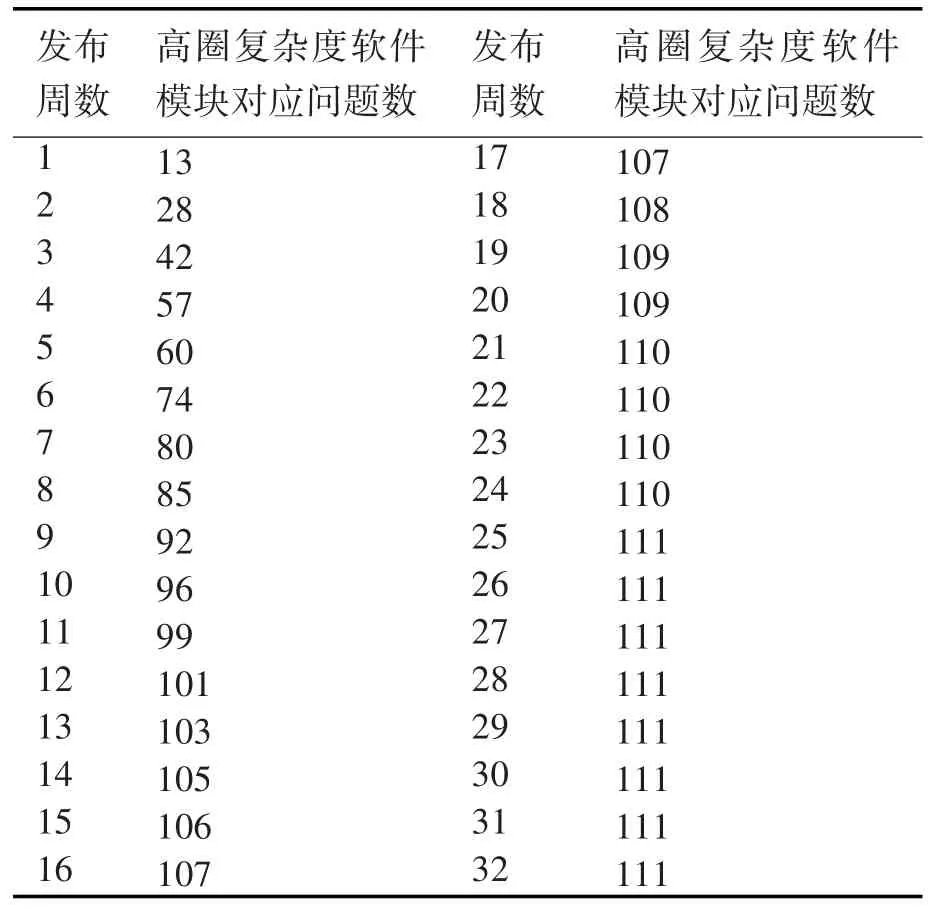
表4 高圈复杂度软件模块对应问题缺陷统计表
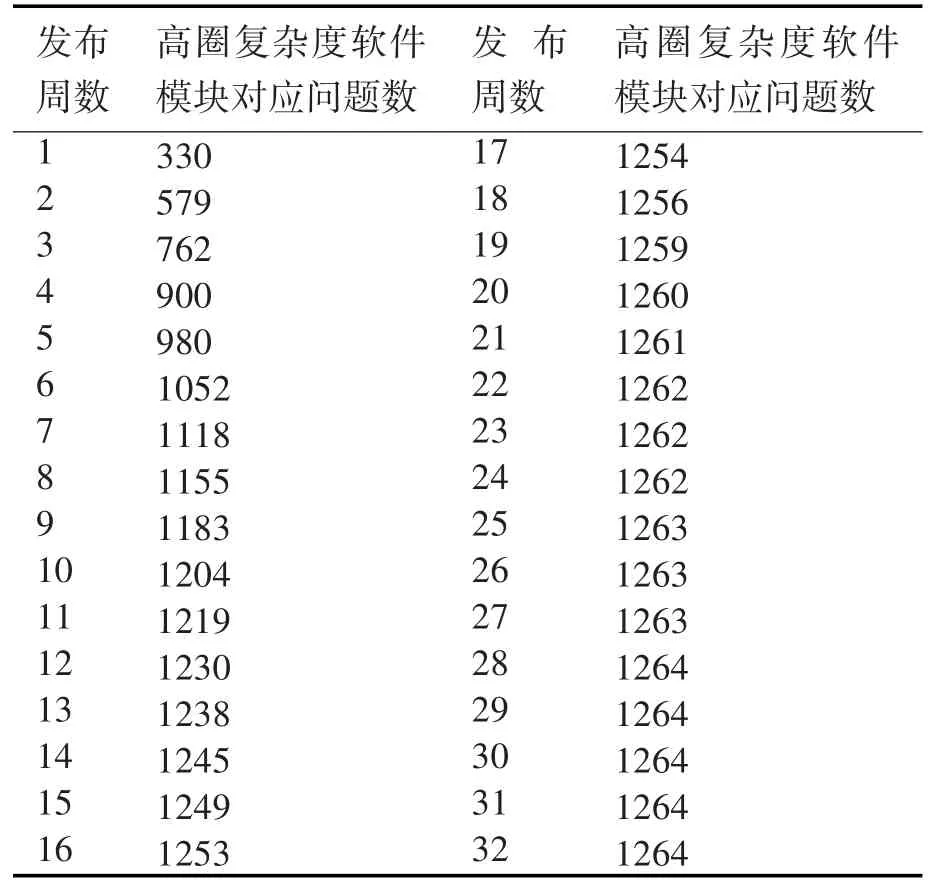
表5 软件对应问题缺陷统计表
针 对 表 2,由 方 程(15)可 求 得 s1=805,c1=0.398,将其代入方程(13)可得低圈复杂度的软件可靠性模型为
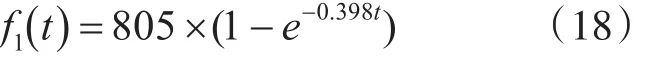
低圈复杂度故障拟合效果如图1所示。
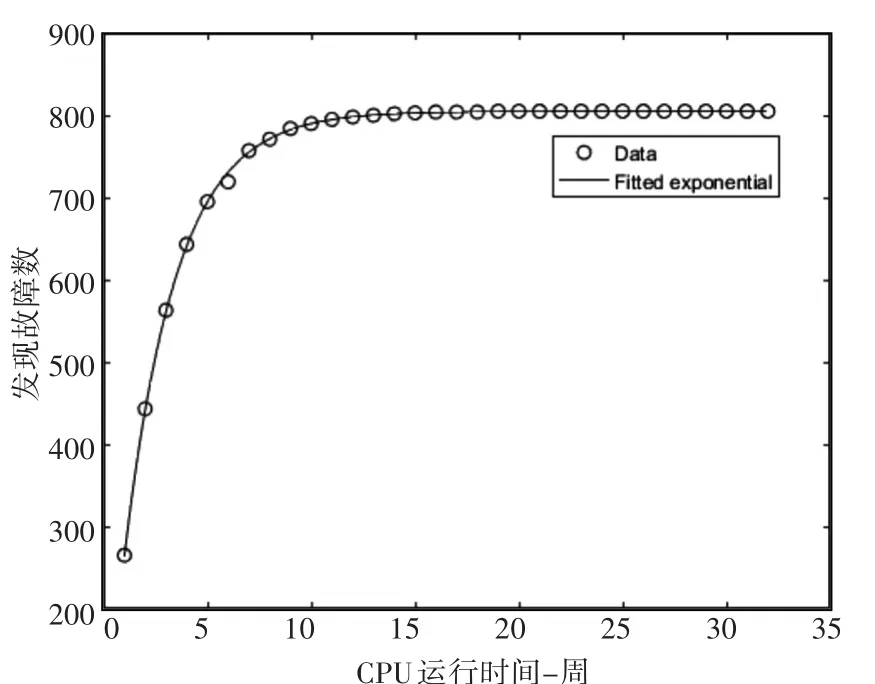
图1 低圈复杂度软件模块故障数量拟合图
针 对 表 3,由 方 程(16)可 求 得 :s2=267,p2=0.77,a=0.36,b=0.69,将其代入方程(8)可得中圈复杂度的软件可靠性模型为
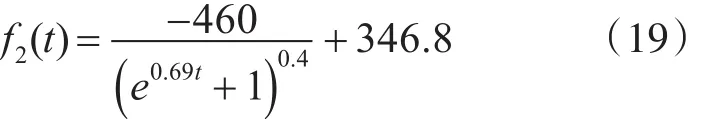
中圈复杂度故障拟合效果如图2所示。
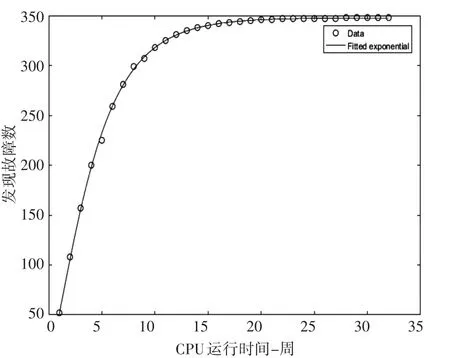
图2 中圈复杂度软件模块故障数量拟合图
针对表4,由方程(17)可求得 s3=67,p3=0.61,m=0.43,n=0.26,y=0.02,将其代入方程(12)可得高圈复杂度的软件可靠性模型为
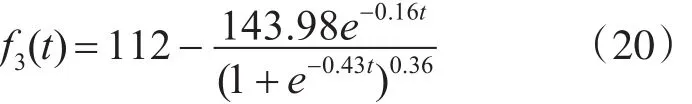
高圈复杂度故障拟合效果如图3所示。
由方程(13)、(18)、(19)、(20)可得基于圈复杂度的软件可靠性模型为
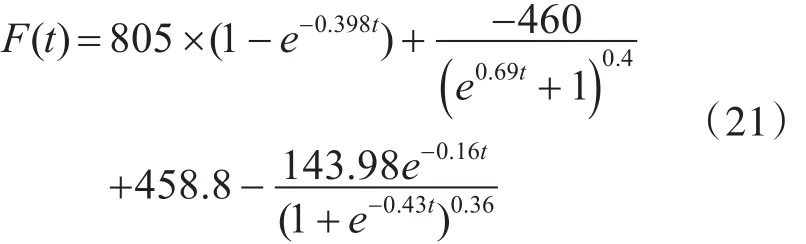
基于软件圈复杂度的故障拟合效果如图4所示。
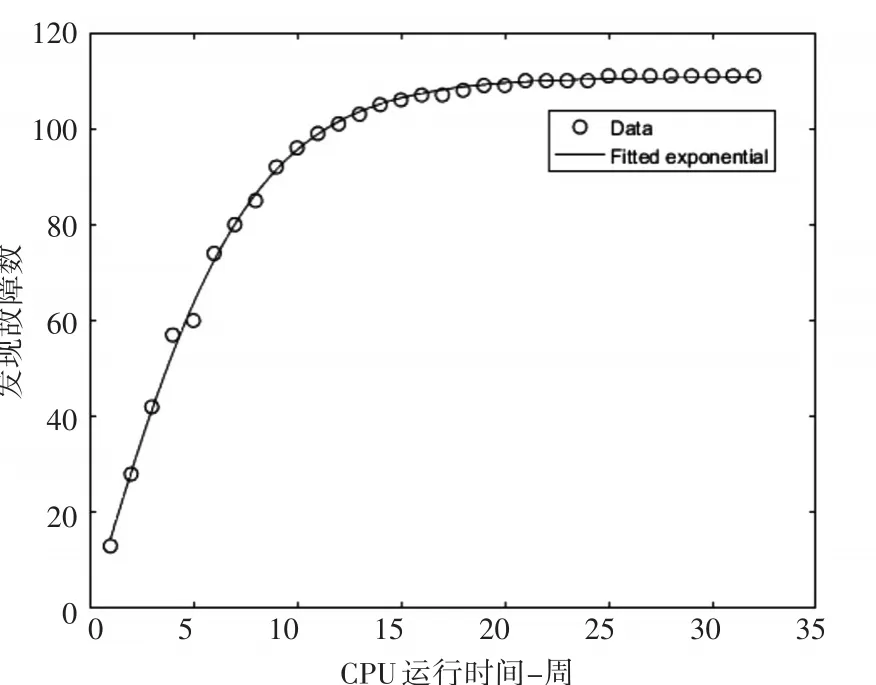
图3 高圈复杂度软件模块故障数量拟合图
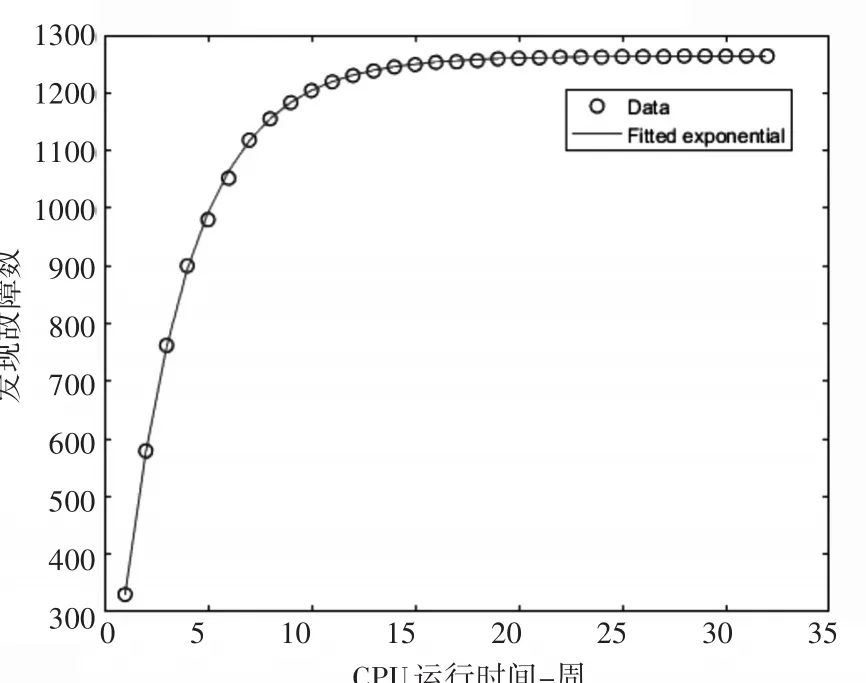
图4 基于软件圈复杂度模型的故障数量拟合图
通过MSE度量模型与G-O模型、Delayed S-shaped 模型、Inflected S-Shaped Model(ISS)模型、变型S型-TEF模型、Logistic-WE模型进行比较,比较结果见表6所示。

表6 MSE比较
通过以上实验分析,本文通过针对不同软件圈复杂度的特性进行分析,分别建模,更贴近实际,得到的可靠性模型拟合效果优于现有的模型。
5 结语
本文通过将软件圈复杂度划分为三个等级:普通、复杂、特别复杂。针对不同等级的圈复杂度,分别从代码状况、可测性、可维护性、对测试人员能力的要求、对开发人员能力的要求5维角度进行了充分分析,从而首次提出了基于软件圈复杂度相关的不完美排错可靠性增长模型。在进行可靠性模型建模的同时综合考虑了故障的检测率、故障排错率、排错时故障的引入率三大因素,更加切合实际,并通过实际测试数据对本模型进行应用,并与现有模型进行了比较,证明了本模型的优越性。
猜你喜欢
社会科学战线(2022年2期)2022-03-16
成都信息工程大学学报(2021年6期)2021-02-12
法制博览(2020年36期)2020-11-30
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
中国信息化周报(2019年18期)2019-06-09
电脑知识与技术(2017年31期)2017-12-11
婚姻与家庭·性情读本(2015年7期)2015-07-21
电脑爱好者(2015年6期)2015-04-03
计算机世界(2009年32期)2009-09-30
