
基于卷积神经网络的无人机遥感农作物分类
2019-12-06 03:04汪传建赵庆展马永建任媛媛
农业机械学报 2019年11期
汪传建 赵庆展 马永建 任媛媛
(1.石河子大学信息科学与技术学院, 石河子 832000; 2.兵团空间信息工程技术研究中心, 石河子 832000)
0 引言
农作物识别是农业现代化的初始阶段和重要环节[1]。快速准确地获取作物种植类别、有效估算作物结构类型及空间分布信息,可为作物普查、产量预测和灾害评估等工作提供技术支撑,也是政府部门制订农业政策的重要依据[2]。新疆地域辽阔、资源丰富,是国家重要的农作物生产基地,但其生态环境比较脆弱,农业生产面临干旱、风沙、严寒等多种灾害威胁,及时有效地获取该地区农作物种植信息,对保证新疆粮食生产安全、促进农业可持续发展具有重要意义。

图1 研究区主要地物物候信息Fig.1 Main phenological information of study area
目前,国内外多采用长时间序列卫星数据,结合农作物植被指数时间变化特征,提取作物时序生长曲线,从而实现农作物精细分类[3-4]。随着遥感技术的不断发展,遥感影像的空间分辨率越来越高,蕴含的地物信息更加丰富。高分辨率遥感的应用为缩短观测周期、充分利用纹理形状信息进行农作物精细分类提供了良好的数据支持。如陈杰等[5]利用QuickBird影像采用面向对象方法分别对农田和树种进行分类;田振坤等[6]利用无人机影像结合NDVI数据对小麦进行快速识别;EDDY等[7]利用高分辨率遥感影像成功提取油菜、豌豆和杂草分布信息。但空间分辨率的提升也给后续影像解译带来了挑战[8-10]。以往基于像素特征的分类方法如马氏距离法、最近邻分类法等难以有效提取影像中目标特征,导致错分和椒盐现象[11]。传统浅层学习算法如支持向量机(SVM)、随机森林(RF)等,虽然对简单特征有着较好的提取效果,但处理过程只经过较少层次的非线性变换组合,对影像中复杂特征的提取效果较差[12-14],随着遥感影像数据量的增加,浅层模型也难以满足影像处理需求。深度学习的兴起为该问题提供了有效解决途径,它是一种包含多个隐含层的感知器,可将样本在原空间的特征变换到新的特征空间,自动学习并得到层次化的特征表示,进而提升分类的准确性[15]。近年来,深度学习在遥感影像中的应用研究多集中于大型地物目标识别,如飞机、轮船、房屋等信息的提取[16-19],针对农业方面的应用较少,特别是针对高分辨率遥感影像中农作物精细分类的研究鲜有报道。
本文采用深度学习的方法,针对传统农作物精细分类过程中影像时间序列长、高分辨率影像信息利用不足、类内像元差异导致椒盐噪声等问题,选取新疆维吾尔自治区沙湾县蘑菇湖村为研究区,通过无人机获取农作物遥感数据,将卷积神经网络应用到典型农作物精细分类中,分析网络参数调整、光谱特征组合对农作物分类精度的影响,探讨卷积神经网络在农作物精细分类中的适用性及优化流程,以期为农作物精细分类提供新的思路。
1 实验数据与方法
1.1 研究区概况
研究区位于新疆维吾尔自治区沙湾县蘑菇湖村(85°51′49.44″E,44°25′26.61″N),该地区气候干燥,光热资源丰富,适合棉花、玉米、西葫芦等农作物的生长。区域内主要地物物候周期如图1所示,表现为棉花播种时间为4月上旬,生长周期较长,为8个月左右,玉米播种时间为5月下旬至6月上旬,生长周期较短,为3个月左右,西葫芦在7月达到成熟期。
1.2 实验数据获取
野外调查数据采集时间为2018年7月9—15日,根据实验区规模分3个样区进行采样,利用GPS标注样区内农作物类型及位置,共获取231块大田信息。实验选用复合翼无人机为飞行平台,该无人机翼展2 m,机身长度3 m,续航时间可达120 min。成像设备搭载索尼RX0和Micro MCA12 Snap多光谱相机,其中索尼RX0具有24 mm主距,CCD尺寸为2.75 μm,整体尺寸59 mm×40.5 mm×29.8 mm。多光谱相机具有12个可选波段,前5个波段位于可见光区域,波段6、7位于植被反射光谱曲线的红边区域,最后5个波段位于近红外区域,整机质量1.3 kg,尺寸为9.34 cm×6.3 cm×4.6 cm。设计飞行高度400 m,航速20 m/s,航向重叠率65%,旁向重叠率70%,经两个架次飞行,获取典型农作物遥感影像面积约867 hm2,可见光数据空间分辨率达0.05 m,多光谱数据空间分辨率为10 m,包含棉花、西葫芦、玉米等多种地物信息。研究区位置如图2所示。

图2 研究区位置示意图Fig.2 Location of study area
1.3 实验数据预处理
根据飞行中采用的RTK/PPK定位技术,对飞行记录数据进行解算,得到每幅影像精确位置,将影像数据与位置信息同时导入Pix4D进行拼接,得到研究区正射影像。参照人工调查数据,在正射影像中对已标明地物类型的地块进行感兴趣区选取。本文共选取感兴趣区域5 000处,地物类型包括棉花、西葫芦、玉米和其他,将选取的感兴趣区统一保存为.mat格式文件,经样本集制作软件处理,生成实验样本数据。通过数据预处理,本文共获取3通道农作物训练样本41 600个,样本尺寸为255像素×255像素,受研究区作物分布影响,各类样本数量有少许差别,其中棉花样本11 600个,西葫芦样本10 600个,玉米样本8 600个,其他地物样本10 800个。
1.4 典型农作物光谱特性分析
实验数据采集时间为7月下旬,在该时间段内,棉花处于花铃期,玉米处于穗期,西葫芦处于结瓜期,此时3种农作物均已完成叶片发育,具有典型的绿色植物光谱反射特征,3种农作物光谱反射曲线如图3所示。
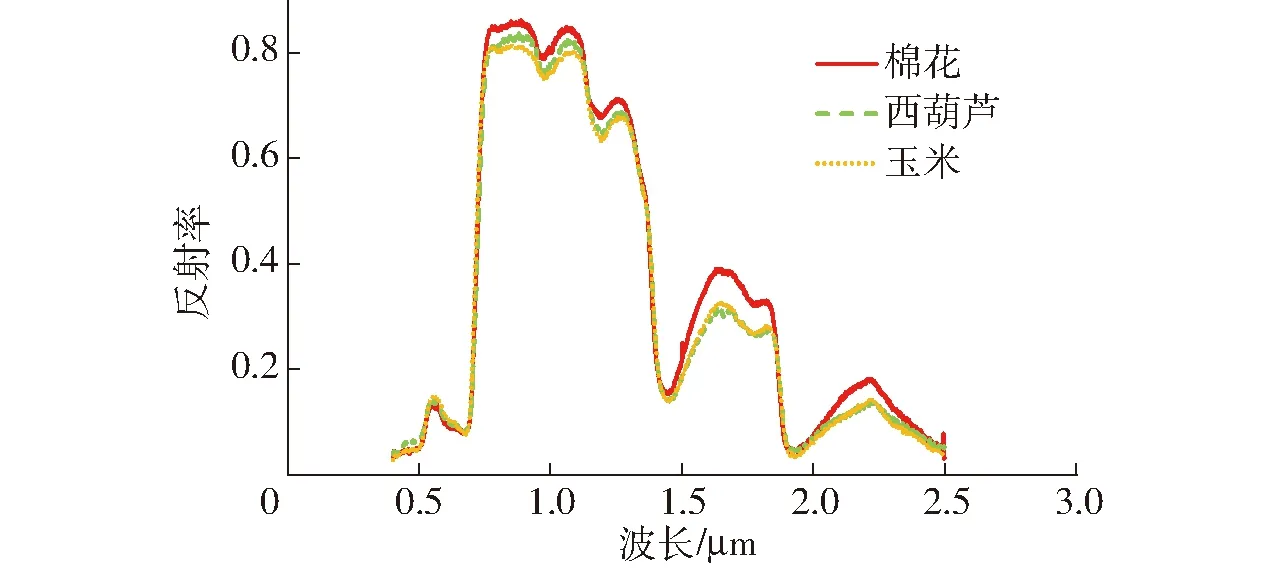
图3 典型农作物光谱曲线Fig.3 Typical crop spectrum curves
在可见光波段,3种农作物统一呈现出“低-高-低”的光谱反射率趋势,这是由于叶片内各种色素对光谱波段的吸收所致。在可见光与近红外波段之间,反射率急剧上升,形成“红边”现象。随着波长进一步增加至0.93 μm波段附近,光谱特性受叶子内部构造影响,多子叶植被相比单子叶植被具有更高的反射率(棉花高达0.85)。
从光谱分析可以看出,在可见光波段3种农作物有着相同的光谱反射趋势,反射率同样较为相近,最低值0.05出现在蓝光波段,最高值出现在绿光波段,可达0.15。观察整个光谱反射率曲线并结合已获取的遥感数据,考虑到近红外波段3种农作物反射率的细微差异,计算3类地物归一化植被指数(NDVI)并观察其区别,计算公式为
(1)
式中NDVI——归一化植被指数
ρnir——近红外波段反射率
ρred——红光波段反射率
NDVI能够增强遥感影像中的植被响应能力,是目前已有的40多种植被指数中应用最广泛的一种[20]。去除计算结果异常值,取置信度为2,统计3类地物NDVI特征值和对应的像素百分比,结果如表1和图4所示。
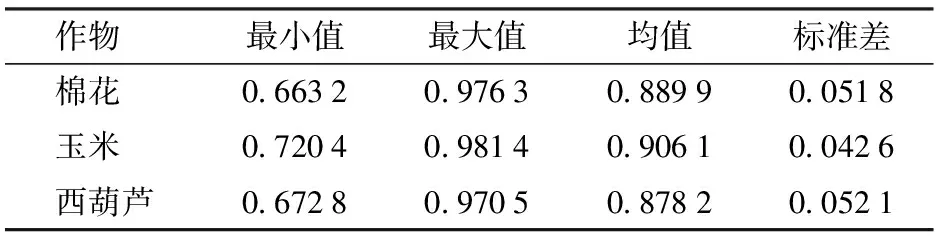
表1 NDVI统计特征值Tab.1 NDVI statistical eigenvalues

图4 典型农作物NDVI统计分布图Fig.4 Statistical distribution of typical crop NDVI
结果显示,棉花、玉米、西葫芦3种农作物的NDVI都很高,均值分别为0.889 9、0.906 1、0.878 2,同时分布较为集中,标准差分别为0.051 8、0.042 6、0.052 1,NDVI特征统计曲线相互重叠交错。即使通过简单的主成分分析(PCA)方法将特征纬度降至3维,也很难寻找一个平面区分3种典型农作物。PCA特征下的3种农作物散点图如图5所示。为了更好地识别3种农作物,可以借助深度学习方法,利用卷积神经网络提取影像中不同农作物包含的复杂特征,并利用这些特征解决分类问题。
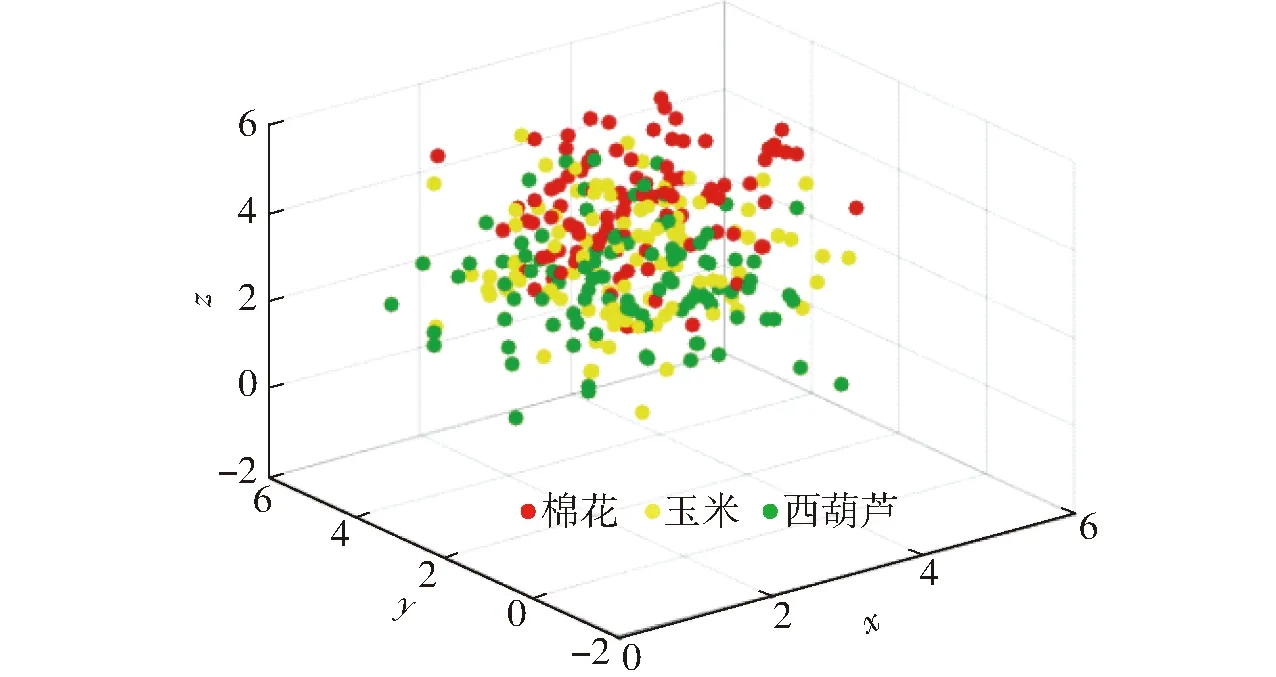
图5 PCA特征下典型农作物散点图Fig.5 Scatter plot of typical crops under PCA characteristics
1.5 卷积神经网络模型的搭建
卷积神经网络凭借其多层卷积、权值共享、旋转位移不变性等特点,在影像分类、地物识别等任务中均取得较好效果[10]。CNN所提取的深层复杂特征往往能够有效描述影像中不同类别之间的差异,快速准确地完成分类任务[14]。根据已有的模型经验,针对无人机高分辨率遥感影像光谱信息较少、形状纹理信息丰富的特点,采用深层卷积结构,设计适用于农作物识别的网络模型,该模型整体框架如图6所示。

图6 典型农作物识别网络整体结构图Fig.6 Overall structure of typical crop identification network
整个网络共7层,包含5层卷积层和2层全连接层。模型各部分参数设置如下:
(1)输入部分。输入数据为1.3节中制作的可见光样本数据,尺寸为255像素×255像素,标有地物类型标签,便于模型进行训练识别。
(2)卷积层。卷积层与ReLU激活函数层相结合实现去线性化,在部分卷积层后附加池化层,用以减少全连接层参数,防止过拟合问题[16]。模型初始卷积核参数如表2所示。

表2 网络初始卷积核参数设置Tab.2 Setting of initial convolution kernel parameters of network
在卷积层运算过程中,输入与输出数据关系为
(2)
式中y——卷积输出数据尺寸,像素
x——卷积输入数据尺寸,像素
nj——卷积核尺寸,像素
sj——卷积步长
nc——池化尺寸,像素
sc——池化步长
p——对输入数据进行四边填充的规模
(3)全连接层。全连接层具有与上层输出相同规模的滤波器(6×6×256),每个滤波器生成一个运算结果,经drop运算后输出。
(4)其他参数。采用随机梯度下降法训练网络,使用一个均值为0、标准差为0.01的高斯分布初始化每一层的权重。第2、4、5个卷积层以及全连接层的神经元偏差初始化为1,该初始化可提供带正输入的ReLU函数来加速学习的初级阶段,其余层则初始化为0。
1.6 光谱特征及模型参数选择
网络参数的选择对模型训练效率和最终分类精度起着重要作用,只有选择合适的参数才能使模型更高效地完成特征提取。根据经验,分别从光谱和网络结构层面进行参数选取,探寻卷积神经网络在农作物精细分类中的优化过程。保持模型结构不变,学习率以及批次的设置对训练过程有着较大的影响。一个理想的学习率可促进模型收敛,相反则会造成训练震荡甚至直接导致目标函数损失值“爆炸”[10]。合适的批次可确保模型对梯度向量的精确估计,保证以最快的速度下降到局部极小值。本文设置的学习率为0.1、0.01、0.001,对应的读取批次为64、100、128。
从1.4节的分析可以看出,3种农作物在可见光波段的反射率极为相近,很难根据反射率曲线将3种农作物区分开。在ENVI中使用波谱工具发现,3种农作物在不同波段内的像素亮度(DN)有少许差别,如图7所示。
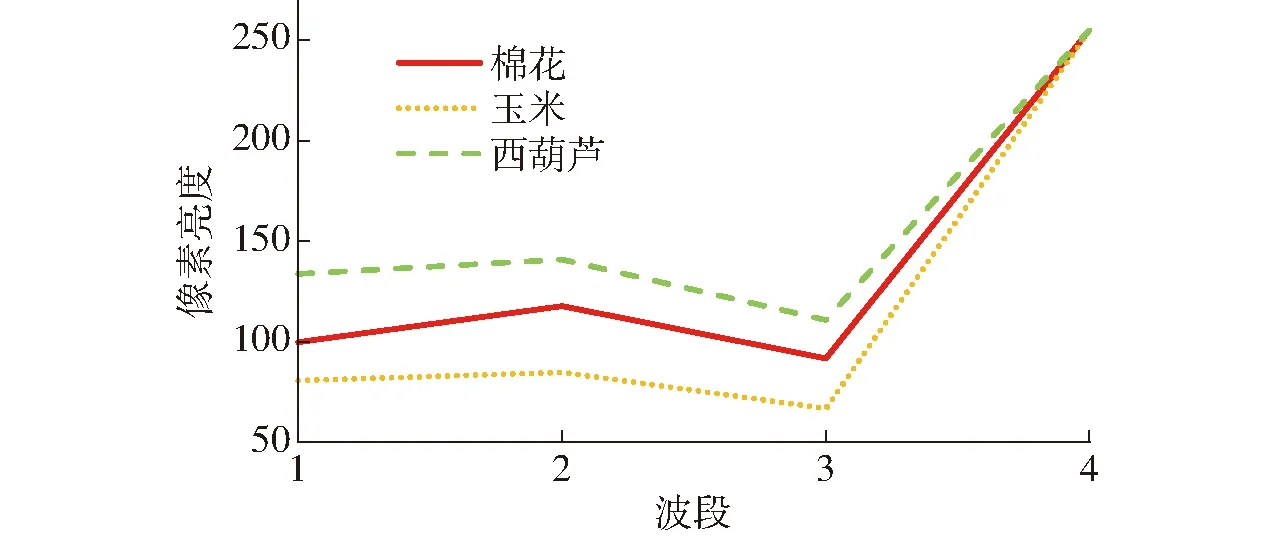
图7 典型农作物波段差异图Fig.7 Diagram of typical crop band difference
由图7可以看出,像素亮度由大到小依次为西葫芦、棉花、玉米,蓝光波段下3种农作物像素亮度之差最为明显,随着波长增加差异逐渐减小。考虑3种农作物在不同波段的差异关系,在原训练数据基础上,选取不同波段组合构成新的训练样本,分析波段信息变化对模型识别效果的影响。波段组合信息如表3所示。 表中R、B、G分别表示红光、蓝光、绿光波段。
在模型中,大卷积核具有较大的感受野,本层的一个像素代表前一层更多的信息,但会造成细节的遗漏;小卷积核与之相反,却无法很好地表示稀疏数据特征[21-22]。结合本文实验数据具有密度大、特征少、差异性小的特点,设计11、9、7共3类卷积核模型,探究小卷积核在细微特征提取中的优势。卷积核设置如表4所示。

表3 波段组合信息Tab.3 Band combination information
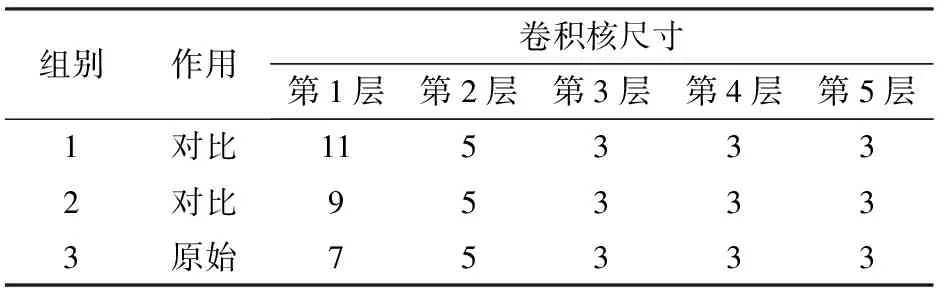
表4 卷积核对比组设置Tab.4 Settings of convolution kernel comparison group
2 结果分析与讨论
2.1 模型分类精度分析
使用样本数据对卷积神经网络模型进行训练,得到不同参数下模型分类精度的变化曲线,如图8所示。
从图8可以看出,不同参数的选取对模型识别效果有不同的影响:

图8 不同参数下模型分类精度变化曲线Fig.8 Classification accuracy curves of learning rate and read batch adjustment group
(1)农作物分类模型收敛速度主要受学习率影响。对典型农作物样本进行训练识别时,小学习率(0.001)获得的收敛效果不如大学习率(0.1),收敛后的识别精度依然不如大学习率。这是由于小学习率虽然可以在训练初始阶段避免振荡,但由于步长太小而陷入了局部最优。使用较大的学习率,只要避免出现网络训练振荡,就可在快速收敛的同时避免陷入局部最优。读取批次的选择对模型收敛速度影响较小,但会对网络模型的稳定性产生影响。本文中,当读取批次选择为64时,即使网络模型在趋于平稳之后,局部仍有较大的起伏,而读取批次为100、128的网络模型在趋于平稳之后的分类精度起伏变化较小。
(2)模型分类精度和稳定性受样本包含波段信息影响。波段间的差异及波段信息的增加可为网络提供更多的特征选择从而提升网络对农作物样本的分类精度。由光谱分析可知,在可见光波段中,3种农作物蓝光波段亮度差异最为明显,红绿波段次之,当样本只包含蓝光波段时,训练的网络模型具有一定的分类精度,但识别效果不稳定,包含红绿波段的样本对模型稳定性效果略有提升,分类精度却不如蓝光波段样本,使用3波段样本训练完成的网络可更加有效地进行作物识别,同时具有更稳定的识别效果。
(3)小卷积核在农作物样本特征提取中更具优势。大卷积核进行一次卷积运算涵盖的区域大,对稀疏特征表示效果较好,小卷积核与之相反。本文识别地物类型主要为农作物,在遥感影像中呈密集分布状态。在模型中使用大卷积核(11×11)进行农作物特征提取,训练次数达到2 000步以后仍存在模型识别效果不稳定的现象,而当卷积核降低至小尺寸(7×7)时,训练次数在1 200步时就取得了稳定的训练效果,并且具有较高的分类精度。
为进一步探索本文方法在农作物精细分类中的适用性,将本文方法(CNN)与支持向量机(SVM)、浅层反向传播神经网络(BP)进行对比实验。其中SVM选取径向基函数作为核函数,采用基于交叉验证的网格搜寻法确定惩罚因子C和核函数参数γ。BP神经网络隐含层数为1层,采用3-50-4的网络结构,学习率设为0.1,训练次数为2 000。以总体分类精度和Kappa系数作为评价指标。为验证卷积神经网络的稳定性,重复3次实验,不同方法的总体分类精度对比如表5所示。
可以看出,本文方法在总体分类精度(OA)和Kappa系数两种评价方式下均取得最好结果,BP次之,SVM分类效果最差。其原因在于,SVM通过核函数进行非线性分类,当处理小规模样本时效果较好,在处理如遥感影像大规模数据时,效果稍差,对类间差异小的非线性问题,核函数的选择更加困难。CNN作为一种深层网络结构,可以获得更本质的特征,适应区分样本之间细微的差异,从而能更好地发

表5 不同农作物识别方法对比实验结果Tab.5 Experimental results of crop recognition by different methods
掘农作物之间差异规律,提高分类精度。
2.2 讨论

图9 研究区典型农作物分类结果Fig.9 Typical crop classification results in study area
使用本文方法对农作物进行识别,根据结果绘制研究区内主要农作物的空间分布,如图9所示。利用野外调查数据作为地物类型验证标准,均匀选取各类地物共38 400处作为测试样本,计算典型农作物分类混淆矩阵,实现分类结果定量评价,结果如表6所示。
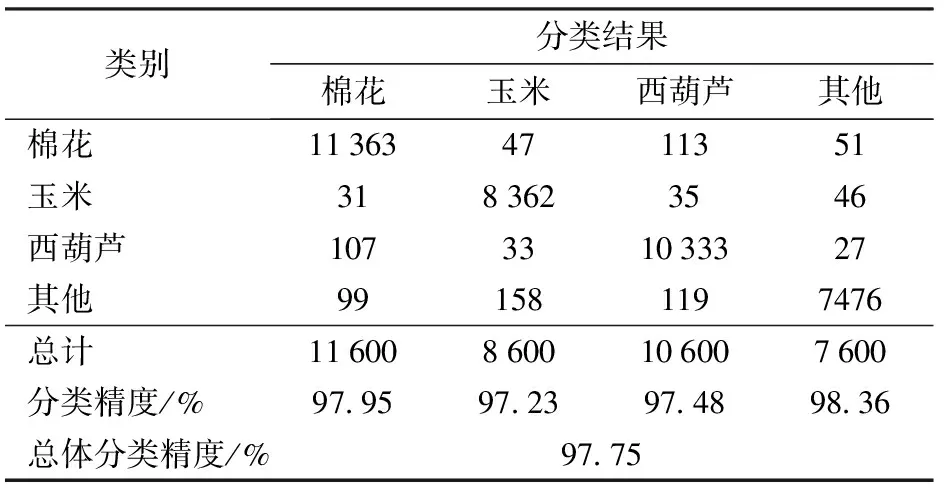
表6 研究区典型农作物分类混淆矩阵Tab.6 Constitutive matrix of typical crop classification in study area
总体来看,3类典型农作物均取得了较好的分类效果,总体分类精度为97.75%,且分类结果所反映的农作物种植结构与实际情况是一致的。研究区中,棉花占据了主体地位,地块连续、面积较大,西葫芦、玉米交错分布在棉田周围,在部分居民建筑用地区域,有小块农田分布,种植有玉米、棉花等农作物。
不同农作物间的分类情况存在微小差异:
(1)从表6可以看出,3种农作物的分类精度棉花最高,可达97.95%,西葫芦次之,为97.48%,玉米最低,为97.23%。在选取的研究区中,农作物种植规模不均匀,最终得到的各类农作物样本数量也不一致,其中,棉花包含11 600个训练样本,而玉米仅有8 600个训练样本。棉花种植面积广,制作的样本中包含更全面的棉花特征信息,而玉米可供选择的样本制作区域较少,样本代表性较低,因而最终获取的分类精度小于棉花。
(2)分类结果中,3类农作物有很大一部分样本被错分为其他类别,这是由于在大田边缘区域,播种不如大田中央紧凑,植株分布稀疏,露出裸地区域,与模型训练样本特性相差较大,导致网络在部分地块边缘处将农作物错分为其他类别。除去边缘区域,在地块中央植株密集处则几乎不存在错分情况。
3 结论
(1)利用卷积神经网络对农作物样本进行分类,总体分类精度为97.75%,其他类别分类精度可达98.36%。采用深度学习方法设计网络模型可有效提取遥感影像中的农作物信息,在对农作物精细分类过程中避免了云雨、光照等外界因素产生的影响,简化了分类过程中物候特征的提取与选择。
(2)模型参数的选取影响最终的分类精度。根据地物目标形态特点对遥感影像中的农作物进行识别,在避免产生振荡的前提下应选择较大学习率(本文为0.1),适当的读取批次(本文为128)可使模型获得更稳定的分类效果,使用小规模卷积核(本文为7×7)进行作物特征提取可获得稳定的分类效果和较高的精度。
(3)样本光谱特征的增加可提升模型的训练效果。在可见光波段中,蓝光波段对农作物分类效果影响最为明显,加入红光和绿光波段则更有利于网络模型对农作物样本的区分,但训练时间会相应增加。
猜你喜欢
今日农业(2022年16期)2022-11-09
今日农业(2022年15期)2022-09-20
今日农业(2022年13期)2022-09-15
航天返回与遥感(2022年2期)2022-05-12
今日农业(2021年16期)2021-11-26
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
电子制作(2018年2期)2018-04-18
