
面向不平衡文本情感分类的三支决策特征选择方法
2019-12-23 07:19万志超胡峰邓维斌
计算机应用 2019年11期
关键词:特征选择
万志超 胡峰 邓维斌


摘 要:传统的特征选择方法在面对不平衡文本情感倾向性分类时会有很大的局限性,这种局限性主要体现在特征维数过高、特征过于稀疏和特征分布不平衡,这会使得分类的准确度大幅度下降。根据不平衡文本情感特征分布的特点,结合三支决策的思想,提出了一种面向不平衡文本情感分类的三支决策特征选择方法(TWDFS)。该方法将两种有监督特征选择方法相结合,将选择出的特征词进一步筛选,使得最终选择出的特征词同时满足类间离散度最大和类内离散度最小的特点,有效地减少了特征词的数量,降低了特征维度;此外,通过组合正负类情感特征,缓解了情感特征的不平衡性,有效提高了不平衡样本中少数类情感的分类效果。在COAE2013中文微博非平衡数据集等多个数据集上的实验结果表明,所提的特征选择算法TWDFS可以有效提高不平衡文本情感分类的准确度。
关键词:不平衡文本;特征选择;情感分类;有监督;三支决策
中图分类号:TP391.1
文献标志码:A
Feature selection method for imbalanced text
sentiment classification based on threeway decisions
WAN Zhichao1*, HU Feng1,2, DENG Weibin2
1.College of Computer Science and Technology, Chongqing University of Posts and Telecommunications, Chongqing 400065, China;
2.Chongqing Key Laboratory of Computational Intelligence(Chongqing University of Posts and Telecommunications), Chongqing 400065, China
Abstract:
Traditional feature selection methods have great limitations in the imbalanced text sentiment tendency classification, which are mainly reflected in the high feature dimension, the sparse characteristics, and the imbalanced feature distribution, making the reduction of classification accuracy. According to the distribution of emotional features of imbalanced texts, a ThreeWay DecisionsFeature Selection algorithm (TWDFS) was proposed for imbalanced text sentiment classification based on threeway decisions. In order to reduce the number of feature words and reduce the feature dimension, two supervised feature selection methods were combined, and the feature words selected were further filtered in order to make them satisfy the characteristics of the maximum betweenclass scatter degree and the minimum withinclass scatter degree. In addition, the imbalance of sentiment features was decreased and the classification accuracy of minority sentiment was effectively improved by combining positive and negative sentiment features. The experimental results on COAE2013 Chinese microblog imbalanced datasets and other datasets show that the proposed feature selection algorithm TWDFS can effectively improve the accuracy of imbalanced text sentiment classification.
Key words:
imbalanced text; feature selection; sentiment classification; supervised; threeway decisions
0 引言
不平衡文本情感傾向性分析在自然语言处理领域是一个热点研究问题,目前主要的研究方法分为文本采样算法的改进和特征选择算法的优化两种。
在中文文本采样算法的改进方面,赵立东[1]针对非平衡中文文本情感分类进行数据层面的改进,提出了基于聚类的下采样算法(Clusterbased Undersampling Algorithm, CUA)和类边界区域的裁剪(Boundary Region Cutting, BRC)的混合采样算法;田锋等[2]利用目标数据集和源数据集的共性特征,提出面向目标数据集实例迁移的数据层面采样方法,缓解交互文本的非平衡问题;王中卿[3]提出了一种基于样本集成的采样方法,在基于聚类的欠采样框架下利用中心向量平滑解决不平衡情感分类的问题。
在特征选择算法改进方面,王杰等[4]提出一种新的双边Fisher特征选择算法TSF(TwoSided Fisher feature selection),通过组合正相关和负相关特征,缓解了特征的不平衡分布;Wasikowski等[5]提出了FAST(Feature Assessment Sliding Thresholds)特征选择算法,在样本数较少的不平衡文本情感倾向性分析中表现较好,但是该算法需要对每一个特征训练一个分类器,大幅增加了算法的复杂度,不适应大规模数据集的应用;Yin等[6]提出了一种基于类别分解的特征选择算法,同时还提出了一种基于Hellinger距离的特征选择方法,在非平衡文本情感倾向性分类中取得了较好的分类准确度。
上述研究方法都只是从某一个方面对特征选择算法进行改进,只考虑有监督算法或者半监督算法单方面的不足,导致选择出来的特征不论是类间离散度还是类内聚集度效果都较差;同时单方面考虑特征词对不平衡文本情感倾向性分类的影响,不能有效缓解特征的高维性和特征的不平衡分布,最终使得情感分类的准确率不理想。
三支决策是一种更一般的、更有效的决策和信息处理模式。三支决策采用不承诺的决策选项,引入两个评价函数α和β将整体C划分为三个部分,然后基于这三个部分进行处理[7]。在处理实际应用问题时,会灵活强调这三个部分中的一个或两个,从而避免了错误接受或者错误拒绝造成的损失。基于三支决策这种有效的处理模式,本文结合三支决策的思想,将两个有监督的特征选择算法作为两个评价函数,利用三支决策的划分处理模式筛选出类间离散度和类内聚集度效果更好的特征词,从而降低不平衡文本情感倾向性分析中的特征的维度和不平衡度。
1 相关概念
1.1 中文文本预处理
针对中文文本的自然语言处理研究首先要进行的就是文本预处理,因为中文文本不能像英文文本那样可以用简单的空格和标点符号完成分词;其次,中文文本的编码是Unicode,还需要对编码进行处理;最后,中文文本中存在很多对情感倾向性分类没有作用的词和标点符号,需要进一步处理。
中文文本预处理主要是对中文文本进行分词、编码和去停用词。本文采用的是LTP(Language Technology Platform)分词器[8]对中文文本进行分词处理,并在分词过程中使用哈尔滨工业大学停用词表来过滤文本中的无效词和部分标点符号。
1.2 文本特征选择方法
在中文文本向量空间模型中,表示文本的特征项可以选择字、词、短语作为特征,所对应的特征空间维数过高。为了过滤掉一些对文本分类贡献极低的特征词,特征降维的主要方法有特征选择和特征抽取两种:特征选择是根据某一个特征词t对类别C的贡献度,从原始特征集合中选择出一个子集;特征抽取主要考虑的是特征之间的语义相关性,以及特征的类间离散度和类内聚集度,从而实现对特征集合的压缩[9]。
中文文本特征选择算法分为有监督特征选择算法和无监督特征选择算法两类。无监督特征选择算法有:文档频 (Document Frequency, DF)[10]、绝对词频(Term Frequency, TF)[11]、词频逆文档频(Term FrequencyInverse Document Frequency, TFIDF)[12]等。有监督特征选择算法主要包括:信息增益(Information Gain, IG)法[13]、卡方统计量(CHIsquare statistics, CHI)[14]、互信息(Mutual Information, MI)法[15]等。
1.2.1 双向卡方统计量
卡方统计量(CHI)是一种表示特征词ti和类别Cj之间的相关联程度的特征选择算法,它的基础是假设特征词ti和类别Cj之间符合具有一阶自由度的x2分布[16],因此,特征词ti对类别Cj的卡方统计值越高,它与该类之间的相关性越大,携带的类别信息也就越多,反之则越少。特征词ti和类别Cj关系如表1所示。
表1中,ti表示含有特征词ti的文本;~ti表示不含有特征词ti的文本;Cj表示属于类别Cj的文本;~Cj表示不属于类别Cj的文本;Ai, j表示含有特征词ti且属于类别Cj的文档的数量;Bi, j表示含有特征詞ti,但不属于类别Cj的文档的数量;Ci, j表示文本中不含有特征词ti,但属于类别Cj的文档的数量;Di, j表示文本中不含有特征词ti且不属于类别Cj的文档的数量。可以看出Ai, j和Di, j表示特征词ti和类别Cj是正相关,Bi, j和Ci, j表示特征词ti和类别Cj是负相关。
特征词ti对类别Cj的CHI值为:
x2=
N×(Ai, j×Di, j-Bi, j×Ci, j)2(Ai, j+Bi, j)×(Ai, j+Ci, j)×(Bi, j+Di, j)×(Ci, j+Di, j)(1)
考虑到特征词ti和类别Cj之间存在正相关和负相关关系,以及在文本情感倾向性分析中,如果情感类别只有正、负两类,由于CHI值计算公式的分子会导致在正、负两类情感中都出现的特征词计算出来CHI值是相同的。本文对CHI特征选择算法进行改进,引入修正因子δ(ti),
δ(ti)=sgn(Ai, j×Di, j-Bi, j×Ci, j)=
1,Ai, j×Di, j-Bi, j×Ci, j>0
0,Ai, j×Di, j-Bi, j×Ci, j=0
-1,Ai, j×Di, j-Bi, j×Ci, j<0 (2)
δ(ti)值的正负性和改进后的特征词ti和类别Cj之间的正负相关关系形同,引入修正因子后δ(ti)的双向卡方统计量(Twosided CHI, TCHI)为:
定义2 对于划分到边界域BNDSetCj中的特征词,需要进行进一步判别,以便挑选出对情感倾向类别贡献较高的特征词,即选择出使得文本类间离散度最大,同时类内离散度最小的特征,对情感倾向类别CP特征判别率FCP(tk)定义为:
FCP(tk)=(E(tk|CP)-∑N≠PE(tk|CN))2D(tk|CP)+∑N≠PD(tk|CN)(8)
其中:(E(tk|CP)-∑N≠PE(tk|CN))2表示类间离散度,D(tk|CP)+∑N≠PD(tk|CN)表示類内离散度。
令dP,i(i=1,2,…,m)表示在P类情感倾向样本集中第i条文本;dN, j(N≠P, j=1,2,…,n)表示在N类情感倾向样本集中第j条文本,这里N类情感倾向样本集表示样本集中除P类情感以外的样本集。特征变量dP,i(tk)和dN, j(tk)定义如下:
dP,i(tk)=1, tkoccurs indP,i0, 其他 (9)
dN, j(tk)=1, tkoccurs indN, j0,其他 (10)
则:
E(tk|CP)=E1m∑mi=1dP,i(tk)(11)
E(tk|CN)=E1n∑nj=1dN, j(tk)(12)
D(tk|CP)=1m∑mi=1(dP,i(tk)-E(tk|CP))(13)
D(tk|CN)=1n∑nj=1(dN, j(tk)-E(tk|CN))(14)
通过对归类于边界域BNDSetCj中的特征词,进一步计算其特征判别率FCj(tk),这里FCj(tk)=FCP(tk),上面使用FCP(tk)为了方便公式表示。然后将计算所得值按由大到小排序,选择排序最大的前k个特征词作为对边界域BNDSetCj处理后情感倾向类别Cj新的特征词,记为FSetCj,则情感倾向类别Cj的最终特征词集合为TWDSetCj=POSSetCj+FSetCj。
定义3 TWDFS特征选择算法显示组合正向情感特征和负向情感特征,得到最终的特征集合TWDSet规则如下:
针对不平衡情感倾向性类别,每个情感类别Cj选择出的特征集合TWDSetCj,正类情感特征和负类情感特征可以进行显式的组合,假设从∑Mj=1TWDSetCj选择出k个特征,才有如下策略:
1)从正向情感类别TWDSetCPos中选择出kPos个正向类别情感特征。
2)从负向情感类别TWDSetCNeg中选择出kNeg=k-kPos个负向类别情感特征。
3)将上面两步得到的特征kPos和kNeg进行组合,其中正相关特征比例为ratio=kPos/kNeg。
4)调整ratio的大小,得到最佳的k个特征放入TWDSet。
2.2 算法描述
面向不平衡文本情感分类的三支决策特征选择算法(TWDFS)具体步骤如下。
1)对整个文本数据集进行LTP分词和去停用词等预处理,然后对文本集合进行划分,分为训练集和测试集。
2)引入两个评价函数,改进后的TCHI特征选择算法和MI特征选择算法,对训练集文本中每个情感倾向类别,分别进行这两个评价函数的特征选择操作,得到两个训练集文本特征集合,算法如下。
算法1 根据两个三支决策评价函数TCHI和MI,对训练集文本每个情感倾向类别Cj分别生成两个特征集合TCHISetCj和MISetCj。
输入 经过文本预处理后的训练集TrainSet,三支决策评价函数TCHI从每个情感倾向类别筛选出的特征数k1,三支决策评价函数MI从每个情感倾向类别筛选出的特征数k2。
输出 TCHISetCj,MISetCj。
程序前
1)
初始化。
CHI选择出的特征候选集合:TCHISetCj=;
MI选择出的特征候选集合:MISetCj=。
2)
对TrainSet中情感倾向类别Cj的每一条文本,根据式(3)计算每条文本中每个特征词的特征权值,只保留特征权值大于0的特征词,然后从中选择最大的前k1个特征词,将它们放入候选集合TCHISetCj中。
3)
对TrainSet中情感倾向类别Cj的每一条文本,根据式(4)计算每条文本中每个特征词的特征权值,只保留特征权值大于0的特征词,然后从中选择最大的前k2个特征词,将它们放入候选集合MISetCj中。
4)
return TCHISetCj,MISetCj。
程序后
3)由算法1对每个情感倾向类别Cj都生成了两个特征集合,然后采用三支决策特征选择算法对特征进一步筛选,选择出对类别贡献较大的特征集合。算法如下:
算法2 基于三支决策的特征选择算法。
输入 TCHISetCj,MISetCj,从每个情感倾向边界域BNDSetCj中筛选出的特征数k3;
输出 三支决策特征集合TWDSet。
程序前
1)
初始化:
三支决策正域特征集合:POSSetCj=
三支决策边界域特征集合: BNDSetCj=
满足特征判别率的特征集合:FSetCj=
最终的特征集合:TWDSetCj=
2)
根据定义1确定三支决策特征选择中的正域集合
tk∈SetCj,iftk∈TCHISetCjandtk∈MISetCj
tk∈POSSetCj
将满足条件的特征词放入POSSetCj中
3)
根据定义1确定三支决策特征选择中的边界域集合
tk∈SetCj
if(tk∈TCHISetCjbuttkMISetCj)or(tk∈MISetCjbuttkTCHISetCj)
将满足条件的特征词放入BNDSetCj中
4)
对边界域BNDSetCj中的特征词进行处理:
对边界域BNDSetCj中的特征词根据定义2计算特征判别率F(tk),选择特征判别率最大的k3个特征词作为边界域的处理结果,存入FSetCj中。
5)
将每个情感倾向类别Cj的正域集合POSSetCj和边界域处理后的集合FSetCj合并,作为该类文本的最终特征存入TWDSetCj中。
6)
根据定义3,将每个情感类别Cj得到的TWDSetCj进行显式组合,最终得到三支决策特征集合TWDSet。
7)return TWDSet
程序后
4)根据算法2得到三支决策最终特征集合TWDSet,对训练集文本和测试集文本利用情感词典和情感权值规则,生成训练集文本情感词向量和测试集文本情感词向量。
5)对训练集文本词向量利用Logistics机器学习模型进行训练,然后对测试集文本词向量进行预测,最终输出其情感倾向性类别。
综上,面向不平衡文本情感分类的三支决策特征选择算法整体流程如图3所示。
3 实验设计和分析
3.1 数据集
本文实验所使用的语料库为COAE2013中文“蒙牛”微博测试数据,中文情感分析语料库,包含酒店、服装、水果、平板、洗发水5个领域的评价数据,从中组合正负类样本数量构成不平衡文本情感语料集。所有数据的详细信息如表2所示。
表2分别列出了6个数据集中正向情感和负向情感的样本数和特征数,并计算了二者之间的倾斜度,可以看出这6组数据不仅存在样本数量的不平衡,也存在特征的不平衡。
3.2 评估方法
本文使用采用经典的准确率P(Precision),召回率R(Recall)和F1评价指标,对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例(True Positive, TP)、假正例(False Positive, FP)、真反例(True Negative, TN)和假反例(False Negative, FN)四种情形,令TP、FP、TN和FN分别表示其对应的样例数。计算公式如下:
P=TP/(TP+FP)(15)
R=TP/(TP+FN)(16)
F1=(2×P×R)/(P+R)(17)
其中:TP表示预测情感为正向情感同时实际情感也是正向情感的文本数;FP表示预测情感为正向情感但实际情感是负向情感的文本数;FN表示预测情感为负向情感但实际情感是正向情感的文本数;TN表示预测情感为负向情感同时实际情感也是负向情感的文本数。
3.3 实验方案
本文设计了2个实验来验证TWDFS特征选择算法的有效性。
实验1 验证TWDFS算法的特征降维效果,和TWDFS降低正向情感特征和负向情感特征在数量上倾斜度的能力。
实验2 将本文提出的TWDFS特征选择算法和其他特征选择算法进行比较实验。
3.4 实验结果
实验1 三支决策评价函数TCHI从每个情感倾向类别筛选出的特征数k1,和MI分别从每个情感倾向类别筛选出的特征数k2,在本实验中选择k=k1=k2。根据定义3显式组合正类情感特征和负类情感特征比例ratio。TWDFS算法中,k和ratio对实验结果产生影响,并选择各个特征维度下最优的ratio。表3列出“蒙牛”数据在各个维度下F1值结果。
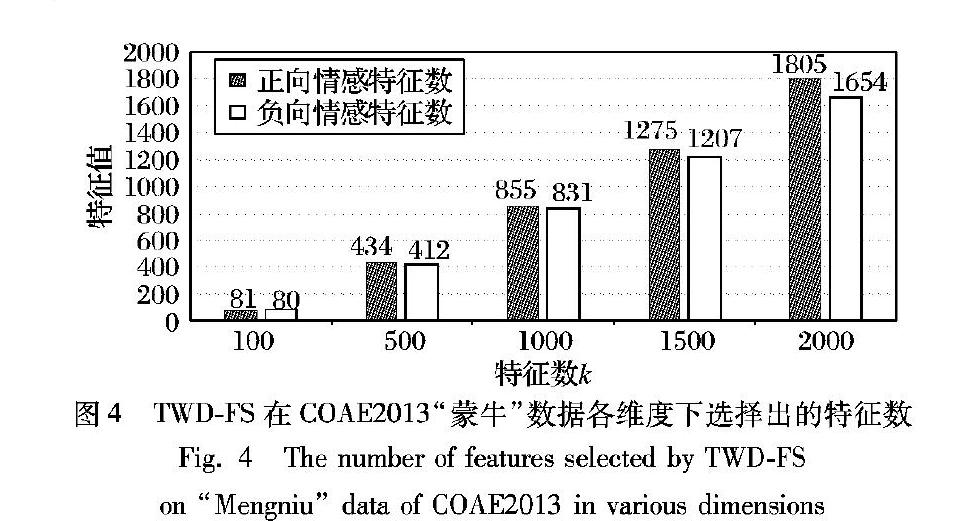
根据表3可以得出,TWDFS算法只使用正向情感特征(ratio=1)和只使用负向情感特征(ratio=0),在各个维度上F1值不能取得最优,在“蒙牛”数据各维度下的F1值在ratio值为0.4或0.5取得最大值,即在平衡正负类情感特征数量时F1值到最优。这时还需要考虑特征数量对实验结果的影响,才能使TWDFS方法的实验结果达到最优。图4表示对不同的特征数k,TWDFS算法F1值大时,最终选择出的正向情感特征数和负向情感特征数的信息。
由表3和图4可以得到,TWDFS在“蒙牛”数据中,三支决策评价函数TCHI和MI分别从每个情感倾向类别筛选出的1-500个特征词时,文本情感倾向性分类F1值达到最高。此时的总特征数仅为2-500维,这和数据集刚开始的数万维特征比较得到了大幅度的下降,同时正向特征和负向特征在数量上的倾斜度得到了很大的改善。
实验2 为了验证提出的TWDFS特征选择算法的有效性和优越性,将其分别和王杰[4]提出的双边Fisher特征选择算法(TwoSided Fisher, TSF),姚海英[20]提出的改进的卡方统计量(Improved CHI Square, ICHI),李燕等[21]提出的基于Lasso的互信息(MI)特征选择算法(LassoMI),张越兵等[22]提出的语句级增强情感特征选择算法(Sentencelevel Sentiment Strengthing, SSS),传統的信息增益(Information Gain, IG)特征选择算法这五种算法进行对比实验,最终通过十则交叉验证取平均结果。
图5表示了TWDFS特征选择算法和其他5种特征选择算法在“蒙牛”数据上F1值结果。可以看出,本文提出的TWDFS特征选择算法相较于其他五种特征选择算法在各项指标上有一定的优势,和传统的信息增益特征选择算法IG相比,优势比较突出。
從表4中可以看出,在进行对比实验的6个领域的数据集中,本文提出的TWDFS特征选择算法相较于其他改进的特征选择算法,在准确率、召回率和F1值个指标上有一定的优势;和传统特征选择算法相比尤为突出。其中平板、水果和洗发水这三个领域的情感倾向性分类结果提升较为明显,各指标均提升了3%~6%;蒙牛、酒店和服装这个三个领域情感倾向性分类结果提升较小,各指标均提升了1.5%~3%。通过分析可以得出,提升较高的三个领域的数据集,它们的样本和特征倾斜度较高,也就是正向情感类别和负向情感类别的文本和特征数量的差距较大,本文提出的TWDFS特征选择算法可以有效地缓解正负类样本和特征的倾斜度。这也充分证明了本文提出的TWDFS特征选择算法在降低特征维度,缓解样本和特征倾斜度的同时,能够有效提高情感倾向性分类的准确度。
4 结语
本文针对不平衡文本情感特征分布的特点,结合三支决策的思想,提出了一种面向不平衡文本情感分类的三支决策特征选择算法TWDFS。有效地将两种有监督特征选择算法的优势结合在一起,更加全面和充分地考虑了特征词对某一个情感倾向类别的贡献度,使得最终选择出的特征词在文本中的类间离散度达到最大,和类内离散度达到最小,具有最佳的情感类别代表度,
同时通过显式组合正负类情感特征数量,进一步降低特征的不平衡度。实验结果证明,本文提出的TWDFS特征选择算法能够有效降低特征维度、文本和特征的倾斜度,同时还能提高情感倾向性分类的准确度。相较于其他特征选择算法,当文本和特征的倾斜度较高时,情感倾向性分类效果提升更加明显;但是本实验仅考虑了两个有监督评价函数筛选出的特征词,对于两者均未选中的特征词直接过滤掉了,这会导致部分文本信息的缺失,
并且本文在特征选择阶段,将具有情感倾向的特征词和一般的特征词同等看待,并未考虑具有情感倾向的特征词对情感类别有更高的贡献度。接下来的研究将重点考虑具有情感倾向的特征词在情感类别中的代表度,同时考虑利用采样算法进一步降低文本和特征的倾斜度,以提高情感倾向性分类的准确度。
参考文献 (References)
[1]赵立东. 面向文本情感分类的非平衡数据采样方法研究[D]. 太原: 山西大学, 2013. (ZHAO L D. Research on imbalanced data sampling methods for text sentiment classification[D]. Taiyuan: Shanxi University, 2013.)
[2]田锋, 兰田, CHAO KuoMing, 等. 领域实例迁移的交互文本非平衡情感分类方法[J]. 西安交通大学学报, 2015, 49(4):67-72. (TIAN F, LAN T, CHAO KM, et al. An unbalanced emotion classification method foe interactive texts based on multipledomain instance transfer[J]. Journal of Xian Jiaotong University, 2015, 49(4):67-72.)
[3]王中卿. 基于不平衡数据的情感分类方法研究[D]. 苏州: 苏州大学,2012. (WANG Z Q. Research on sentiment classification basedupon imbalanced data[D]. Soochow: Soochow University, 2012.)
[4]王杰, 李德玉, 王素格. 面向非平衡文本情感分类的TSF特征选择方法[J]. 计算机科学, 2016, 43(10):206-210. (WANG J, LI D Y, WANG S G. TSF feature selection method for imbalanced text sentiment classification[J]. Computer Science, 2016, 43(10):206-210.)
[5]WASIKOWSKI M, CHEN X. Combating the small sample class imbalance problem using feature selection[J]. IEEE Transactions on Knowledge & Data Engineering, 2010, 22(10):1388-1400.
[6]YIN L, GE Y, XIAO K. et al. Feature selection for highdimensional imbalanced data[J]. Neurocomputing, 2013, 105(4):3-11.
[7]YU H, WANG X, WANG G. A semisupervised threeway clustering framework for multiview data[C]// IJCRS 2017: International Joint Conference on Rough Sets. Berlin: Springer, 2017: 313-325.
[8]张梅山,邓知龙,车万翔,等.统计与词典相结合的领域自适应中文分词[J].中文信息学报, 2012, 26(2):8-12. (ZHANG M S, DENG Z L, CHE W X,et al. Combining statistical model and dictionary for domain adaption of Chinese word segmentation[J]. Journal of Chinese Information Processing, 2012, 26(2):8-12.)
[9]史庆伟, 从世源, 唐晓亮. LSI_LDA:一种混合特征降维方法[J]. 计算机应用研究, 2017, 34(8):2269-2273.(SHI Q W, CONG S Y, TANG X L. LSI_LDA: mixture method for feature dimensionality reduction[J]. Application Research of Computers, 2017, 34(8):2269-2273.)
[10]AL SHAMSI F, AUNG Z. Automatic patent classification by a threephase model with document frequency matrix and boosted tree[C]// Proceedings of the 2016 5th International Conference on Electronic Devices, Systems and Applications. Piscataway: IEEE, 2016: 1-4.
[11]IBRAHIM O A S, LANDASILVA D. Term frequency with average term occurrences for textual information retrieval[J]. Soft Computing, 2016, 20(8):3045-3061.
[12]CHEN K, ZHANG Z, LONG J, et al. Turning from TFIDF to TFIGM for term weighting in text classification[J]. Expert Systems with Applications: an International Journal, 2016, 66(C):245-260.
[13]毛临川, 吴根秀, 吴恒, 等. 基于信息增益的最优组合因子Fisher判别法[J]. 计算机工程与应用, 2016, 52(19):94-96. (MAO L C, WU G X, WU H, et al. Optimal combination of factor Fisher discrimination method based on information gain[J]. Computer Engineering and Applications, 2016, 52(19):94-96.)
[14]李平, 戴月明, 王艳. 基于混合卡方统计量与逻辑回归的文本情感分析[J]. 计算机工程, 2017, 43(12):192-196. (LI P, DAI Y M, WANG Y. Text sentiment analysis based on hybrid chisquare statistic and logistics regression[J]. Computer Engineering, 2017, 43(12):192-196.)
[15]段宏湘, 张秋余, 张墨逸. 基于归一化互信息的FCBF特征选择算法[J]. 华中科技大学学报(自然科学版), 2017, 45(1):52-56.(DUAN H X, ZHANG Q Y, ZHANG M Y. FCBF algorithm based on normalized mutual information for feature selection[J]. Journal of Huazhong University of Science and Technology (Natural Science Edition), 2017, 45(1):52-56.)
[16]張辉宜, 谢业名, 袁志祥, 等. 一种基于概率的卡方特征选择方法[J]. 计算机工程, 2016, 42(8):194-198.(ZHANG H Y, XIE Y M, YUAN Z X, et al. A method of CHIsquare feature selection based on probability[J]. Computer Engineering, 2016, 42(8):194-198.)
[17]王晨曦, 林耀进, 刘景华, 等. 基于最近邻互信息的特征选择算法[J]. 计算机工程与应用, 2016, 52(18):74-78. (WANG C X, LIN Y J, LIU J H, et al. Feature selection algorithm based on nearestneighbor mutual information[J]. Computer Engineering and Applications, 2016, 52(18):74-78.)
[18]吴金源, 冀俊忠, 赵学武, 等. 基于特征选择技术的情感词权重计算[J]. 北京工业大学学报, 2016, 42(1):142-151. (WU J Y, JI J Z, ZHAO X W, et al. Weight calculation of emotional word based on feature selection technique[J]. Journal of Beijing University of Technology, 2016, 42(1):142-151.)
[19]YAO Y. The superiority of threeway decisions in probabilistic rough set models[J]. Information Sciences, 2011, 181(6):1080-1096.
[20]姚海英. 中文文本分類中卡方统计特征选择方法和TFIDF权重计算方法的研究[D].长春: 吉林大学, 2016. (YAO H Y. Research on chisquare statistic feature selection method and TFIDF feature weighting method for chinese text classification[D]. Changchun: Jilin University, 2016.)
[21]李燕, 卫志华, 徐凯. 基于Lasso算法的中文情感混合特征选择方法研究[J]. 计算机科学, 2018, 45(1):39-46. (LI Y, WEI Z H, XU K. Hybrid feature selection method of chinese emotional characteristics based on Lasso algorithm[J]. Computer Science, 2018, 45(1):39-46.)
[22]张越兵,苗夺谦,张志飞.基于三支决策的多粒度文本情感分类模型[J].计算机科学, 2017, 44(12):188-193. (ZHANG Y B, MIAO D Q, ZHANG Z F. Multigranularity text sentiment classification model based on threeway decisions[J]. Computer Science, 2017, 44(12):188-193.)
This work is partially supported by the National Key Research and Development Program of China (2018YFC0832100, 2018YFC0832102), the National Natural Science Foundation of China (61751312, 61533020, 61309014), the Chongqing Research Program of Basic Research and Frontier Technology (cstc2017jcyjAX0408).
WAN Zhichao, born in 1995, M. S. candidate. His research interests include nature language processing, machine learning.
HU Feng, born in 1978, Ph. D., professor. His research interests include rough set, data mining.
DENG Weibin, born in 1978, Ph. D., professor. His research interests include decision making under uncertainty.
猜你喜欢
计算技术与自动化(2022年2期)2022-07-04
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
计算机时代(2016年9期)2016-10-28
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
计算技术与自动化(2015年4期)2016-03-25
湖南师范大学学报·自然科学版(2015年4期)2016-03-01
现代电子技术(2015年12期)2015-06-15
