
基于BP神经网络的深层感知器预测模型∗
2019-12-27 06:31周晓辉
计算机与数字工程 2019年12期
陈 通 周晓辉
(西安邮电大学计算机学院 西安 710061)
1 引言
作为衡量政府财力的重要指标之一,财政收入预测一直都是专家学者们研究的热点[1~2]。目前常用的预测方法有回归分析法、时间序列分析法、灰色预测法和神经网络法等[3~4]。财政收入数据及其相关影响因素数据的变化往往具有随机性和非线性变化的特点,并且它们之间也具有非常复杂的非线性相关关系。目前,许多学者运用组合预测模型来进行预测研究。如范敏等运用灰色预测和常规BP(Back Propagation)神经网络组合模型对地方财政收入进行了预测,提高了预测准确度[5];方博等利用基于时间序列的ARMA模型与常规BP神经网络相结合,通过实验证明了组合预测模型比单一预测模型能够获得更准确的结果[6]。
不过以上研究运用的组合预测模型所使用的常规BP神经网络的BP算法存在收敛速度缓慢、学习精确度不高和局部极小等缺点。本文采用基于深度学习思想的深层神经网络(Deep Neural Net⁃work,DNN),深层感知器(Deep Multi-layer Percep⁃tron,DMLP)模型来解决常规BP神经网络的一些缺陷,建立基于BP神经网络的DMLP财政收入预测模型,并以西安市财政收入及其影响因素统计数据对深层感知器模型进行检验,通过实验验证对比常规BP神经网络预测模型,来论证深层感知器预测模型的预测准确度和实用性。
2 BP神经网络模型
2.1 BP的神经网络结构
反向传播(Back Propagation,BP)算法的特点是利用输出误差来估计输出层的直接引导层误差,然后用该误差估计上一层的误差。在所有的反向传播层之后,我们得到所有其他的误差估计。这样,输出层的错误通过网络的输入层与输入传输的相反方向传递。这里以典型的3层BP神经网络为例,来描述标准的BP算法。图1所示的是一个有3个输入节点,5个隐藏节点,1个输出节点的一个3层BP神经网络。

图1 三层BP神经网络
BP算法的学习过程包括两个过程,即信号的前向传播和误差的反向传播。正向传播时,输入信号经过隐藏层的处理后,传向输出层。若输出层节点未能得到期望的输出,则转入误差的逆向传播阶段,将输出误差按某种子形式,通过隐藏层向输入层返回,并传递给隐藏层5个节点与输入层x1,x2,x3这3个输入节点,从而获得各层神经元的参考误差以此作为修改各神经元权值的依据。这种信号正向传播与误差逆向传播的各层权矩阵的修改过程,是反复进行的。权值不断修改的过程,就是神经网络学习,即训练过程。此过程一直进行到网络输出的误差逐渐减少到可接受的程度或达到设定的学习次数为止。
2.2 BP神经网络的学习训练过程
BP神经网络的学习算法基于δ学习规则,目标函数采用。

算法开始后,给定学习次数上限,初始化学习次数为0,对权值和阈值赋予小的随机数,一般在[-1,1]之间。输入样本数据,网络正向传播,得到隐藏层与输出层的值。比较输出层的值与教师信号值的误差,用误差函数E来判断误差是否小于误差上限,如不小于误差上限,则对隐藏层和输出层权值和阈值进行更新,更新的算法基于δ学习规则。更新权值和阈值后,再次将样本数据作为输入,得到隐藏层与输出层的值,计算误差E是否小于上限,学习训练次数是否达到指定的值,如果达到,则学习结束。
3 DMLP模型
3.1 DMLP的神经网络结构设计
依据 Delalleau和 Bengio的观点[7],常规 BP神经网络都使用不超过三层的结构,在解决实际的复杂应用问题时,由于自身的局限性往往出现表达能力不足的情况。从而,难以达到理想的预测效果。在神经元数大致相同的情况下,深层网络通常比浅层网络函数表达力更强。不过精确预测隐含层所需要的神经元数量和神经网络所需要的层数,至今仍然存在理论上还没有解决的问题[8]。
由以上依据、实际经验和财政收入预测问题的特点,本文选用了DNN中的判别模型DMLP。如图2所示,DMLP采用四层网络结构,隐藏层H1和H2的神经元数量为输入层X的1.5倍~2倍左右,输入层X和输出层Y的神经元数量由具体问题来确定。

图2 四层DMLP神经网络
3.2 神经元激活函数的选取
神经元是神经网络操作的基本信息处理单位。一个神经元对输入信号 X=[x1,x2,…xm]T的输出为 y=f(u)。其中加权求和的值,wi表示权重(模型参数),b表示偏差,f(·)表示激活函数。
2010年,Glorot和Bengio等提出在深度学习模型某些问题的应用中,使用简单、速度快的近似生物神经激活函数Softplus和ReLU替代常规的Sig⁃moid函数,在使用BP算法时可以提高训练速度,减轻梯度下降(Gradient Descent,GD)算法训练深层网络时的梯度消失问题[9]。
在图2当中隐藏层H1的神经元采用非线性的Softplus函数激活用来提高DMLP的解释表达能力,隐藏层H2的神经元采用线性的ReLU函数激活使得DMLP学习周期大大缩短,提高模型的综合学习速率和效率。Softplus、ReLU和Sigmoid的函数公式分别表示如下。

3.3 模型的学习训练方法
本模型用于预测问题,采用基于δ学习规则的BP算法,这是一种有指导的学习算法。与常规BP神经网络的BP算法略有不同,对目标函数取得最小值的权重和偏差的计算采用自适应矩估计(Adaptive Moment Estimation,Adam)算法[10]来替代常规的GD算法,克服其易陷入局部最小值的缺点。
根据图2,设输入层X与隐藏层H1的权重为WH1,偏差为bH1;隐藏层H1与隐藏层H2的权重为WH2,偏差为bH2;隐藏层H2与输出层Y的权重为WY,偏差为 bY。
当正向传递时,各层神经元的输出满足如下公式。
当反向传播时,目标函数采用均方误差(Mean Squared Error,MSE),定义如下。

其中w为所有权重集合向量,b为所有偏差集合向量,N为训练样本的个数,Yk为第k个训练样本的期望值向量,Ŷk为第k个训练样本所预测的值向量。如果loss(w,b)接近于0,表示Yk接近输出预测值向量Ŷk,即学习效果很好。为找到满足要求的w和b,采用Adam算法。该算法利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam算法的优点主要在于经过偏差校正后,每一次迭代学习率都有一个确定范围,使得参数比较平稳。根据文献[9],该算法用于深度学习问题最好的参数默认值可设置为α=0.001,β1=0.9,β2=0.999 ,ε=10-8。 f(θ)为随机目标函数,与loss(w,b)相对应,θ为参数向量,与w和b相对应;gt为 f(θ)的一阶梯度;mt为一阶矩估计向量,初值为0;vt为二阶矩估计向量,初值为0;m̂t,v̂t是对mt,vt的校正;t为时间步。当θt收敛时,模型训练完成,学习结束。其算法流程如下所示。
Whileθtnot converged do

4 预测验证及对比实验分析过程
4.1 预测模型
利用由Python编写基于TensorFlow的深度学习库Keras搭建四层DMLP(5-10-10-1)深层神经网络[11],结合灰色模型预测结果同常规BP神经网络做对比实验并进行验证分析。
四层DMLP的Keras配置参数分别为:输入层输入维数(input_dim)为5,输出维数(output_dim)为10;第一隐藏层激活函数(Activation)为softplus,input_dim为10,output_dim为10;第二隐藏层Acti⁃vation为relu,input_dim为10,output_dim为10;输出层input_dim为10,output_dim为1;目标函数(loss)为mean_squared_error;梯度优化器(optimiz⁃ers)为 Adam;模型训练迭代次数(nb_epoch)为1000。
作为对比试验的BP神经网络[12]结构取5-10-1的网络结构。隐含层激活函数用Sigmoid激活,目标函数为MSE,梯度计算采用GD算法,模型训练迭代次数为1000。
4.2 实验数据
根据表1,把2004~2013年X1~X5的值作为输入样本,Y作为与之相对应的标签值,分别代入四层DMLP模型和三层常规BP神经网络模型进行训练。预测结果如表2所示,训练效果如图3和图4所示。
4.3 实验结果对比分析
由此可见,4层结构的DMLP神经网络模型预测值更接近真实值,准确度更高,其模型训练效果优于3层结构的标准BP神经网络模型。
由图3可以看出,BP神经网络模型在训练迭代大约200次时,其模型loss值才开始收敛。训练迭代1000次,训练完成,最后的loss值为0.00589。由图4可以看出,DMLP模型在训练迭代大约100次时,其模型loss值开始收敛。训练迭代1000次,训练完成,最后的loss值为0.00285。对比图3和图4,在横轴取相同的训练迭代次数,观察纵轴loss的取值,可以发现DMLP的loss值总小于BP神经网络的loss值。对比这两种模型的训练效果,可以看出,DMLP模型[13]学习精确度高,收敛速度快。
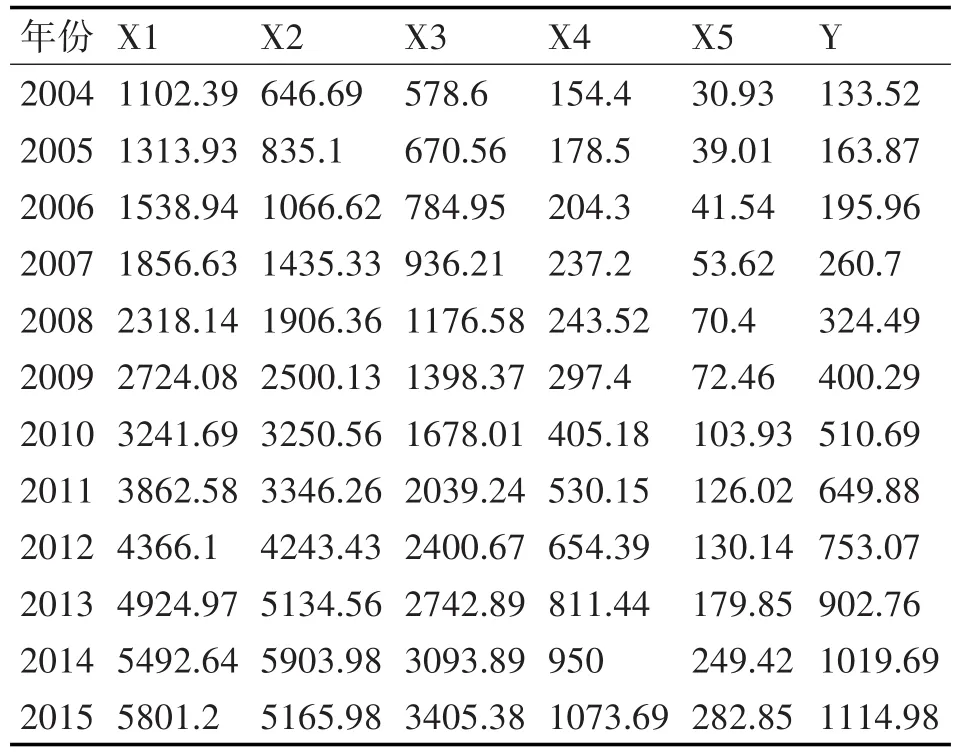
表1 西安市2004~2015财政收入相关统计数据

表2 财政收入组合预测模型的预测值与真实值对比

图3 BP神经网络训练效果

图4 DMLP训练效果
由图5可以看出,DMLP模型在学习训练大约100次时,其模型loss值开始收敛。训练学习10000次,训练完成后的loss值为1.5066×10-4。而标准BP神经网络模型在训练学习大约200次时,其模型loss值才开始收敛。训练学习10000次,训练完成后的loss值为1.3×10-3。同时在训练的过程中,DMLP的loss值一直小于BP神经网络的loss值。

图5 两种模型训练效果对比
由此可见,4层结构的DMLP神经网络模型比常规BP神经网络模型收敛速度快,其模型训练效果优于3层结构的标准BP神经网络模型。
综上所述,与常规BP神经网络模型相比,4层结构的DMLP神经网络模型收敛速度更快、精确度高,其模型训练效果优于3层结构的标准BP神经网络模型。
5 结语
本文在深度学习思想与财政收入预测模型[14~15]基础上,建立了基于BP神经网络的深层感知器预测模型。对比BP神经网络预测模型,深层感知器预测模型的使用增强了原始数据的精确度。通过与常规三层BP神经网络做对比实验,在四层DMLP模型隐藏层用Softplus和ReLU激活函数替代Sigmoid激活函数,在计算目标函数loss的最优参数时,使用Adam算法替代GD算法,提高了模型的学习精确度,加快了学习速率和收敛速度。此外,DMLP四层网络结构和Softplus激活函数的使用提高了模型的非线性拟合能力,提高了预测模型的预测准确度,使其预测结果更加接近于真实值,具有推广性和实用性。但是基于深度学习思想的神经网络模型在进行训练时,一些超参数的选择往往借助于经验,没有成熟的理论作支持,需要不断实验尝试。因此,还需要对深度学习理论做进一步的研究和学习,以便对所构建的组合模型[16~17]做进一步的改进和优化。
猜你喜欢
房地产导刊(2022年4期)2022-04-19
煤气与热力(2022年2期)2022-03-09
小资CHIC!ELEGANCE(2021年36期)2021-10-15
建材发展导向(2021年7期)2021-07-16
电子产品世界(2021年8期)2021-01-16
马克思主义哲学研究(2020年2期)2020-07-21
中国计算机报(2019年49期)2019-02-07
中国新闻周刊(2017年36期)2017-10-21
创新时代(2016年8期)2016-10-21
读写算·高年级(2015年12期)2015-12-12
