
多特征融合的标签传播算法∗
2019-12-27 06:31生佳根严长春
计算机与数字工程 2019年12期
秦 强 生佳根 严长春
(江苏科技大学计算机学院 镇江 212000)
1 引言
随着微博等社交网站[1]的规模不断变大,单个的用户希望能够快速准确高效地找到与自身体兴趣相关一致的共同的爱好的用户、群体,这样用户之间可以交流,从而生出更多的启迪和共鸣。然而面对海量的信息,仅仅通过搜索是无法精确及时地发现志同道合的朋友,因此需要通过挖掘微博网络中用户信息,找出兴趣相投的用户社区。因此对于社交网络而言,通过社区发现技术可以挖掘用户潜在的兴趣社区,研究用户社区的关系结构,对兴趣推荐[2],广告准确投放[3]等方面有重要意义。常用的社区发现算法,例如CPM[4]算法时间复杂度高,计算复杂的,不适用于社交网络的社区发现;又如基于层次聚类[5~6]的算法需要事先确定社区的个数,也不适用于社交网络的社区发现。标签传播算法[7](LPA)算法时间复杂度低、不需要预先设置社区个数、计算过程简单,在处理大型复杂网络时,具有较高的效率的特点,所以被广泛的运用到社区发现的分析研究中。但该算法存在些不稳定性和随机性,主要表现在节点标签更新的顺序,以及标签传播过程中存在较大的随机性,通过一些改进,就可以避免原始算法这些缺点,例如:未考虑到相邻节点在网络结构中的相似性,以及节点与节点之间的内容相似性。SimRank[8]算法为度量节点在网络结构中的相似度,主题模型[9]可以度量节点内容上的主题分布。受此启发,本章从节点相似度角度出发,在标签传播算法基础上,运用SimRank算法度量网络结构中节点间相似度,同时结合节点内容的主题分布的相似性改进传播策略,来降低实验结果的随机性。
2 背景知识介绍
2.1 LDA主题模型
主题模型是当今在文本处理领域比较经典一种生成式概率模型。该模型主要思想是:一篇文档可由若干个主题以某种概率分布形式表示,而每一个主题则可由若干个词以某种概率分布形式表示,文档和词之间通过主题相互关联。LDA生成过程如图1所示。

图1 LDA概率图模型
图1中双圆圈部分表示可观察变量,单圆圈部分表示不可观察变量,箭头表示两个变量之间存在条件概率依赖,方框表示重复采样,方框当中的大写字母表示采样次数。M表示文档的数目,同时也表示反复采样M次,来生成M篇文档;Nm表示第m文档中词的数目,同时也表示反复采样Nm次,来生成第m篇文档中的Nm个词;K表示主题的数目;wm,n表示第m文档中的第n词;zm,n表示词 wm,n所属的主题表示为文档主题分布θ的共轭先验分布;表示主题词分布,β表示为主题词分布∅的共轭先验分布。
以第m篇文档为例,LDA的生成过程如下:
1)首先根据泊松分布来生成文档中的Nm个词;
4)对文档下的每个单词 wm,n,n=1,2,…,Nm:
(1)从第m篇文档的文档主题多项式概率分布中采样,生成一个主题2,…,K};
(2)从主题为zm,n的主题单词多项式概率分布中采样,生成一个词{w1,w2,…,wv}。
5)上述操作就是主题模型的生成过程。
LDA模型求解就是对LDA的参数进行推理的过程,常用Gibbs采样[10]求解,该方法根据给定的最优化目标函数,最终得到对目标参数的估计值。
2.2 SimRank算法
2002年Jeh G等对PageRank算法加以扩展,提出了SimRank算法,算法通过分析网络中网络的全局性特征,来计算节点相似性。2010年Lizorkin D等[11]对SimRank计算过程提出了改进,使得计算时间大大缩短。2014年尹坤[12]等运用SimRank计算百度百科词条与词条之间的语义相似度。2015年王春磊[13]等提出一种可异步执行的大规模Sim⁃Rank算法。如今SimRank已被应用于生物科学、社会网络[14]等众多领域。
定义有向图G=(V,E),其中V为图中的节点集合,E为图中边的集合,边代表两个节点之间的关系,对于图中的任意一个节点a,用I(a)表示指向它的边所对应的顶点集合,|I(a)|表示顶点集合所包含顶点的个数。该算法主要思想是,网络中两个节点的相似度,依赖于网络中其两个邻接节点集合相似度。对于图中任意两个顶点a和顶点b,s(a,b)表示顶点a与顶点b的相似度,则SimRank计算两顶点间相似度 s(a,b)的式(1)如下,其中 C∈(0,1)为衰减因子,通常为一个常数。

SimRank算法通常采用迭代计算的方式来计算相似度,第k次迭代后顶点a和顶点b的相似度用sk(a,b)表示,同时k+1次顶点相似度值可通过k次顶点相似度值计算得到,式(2)如下:

其中迭代初始状态如式(3):

当k趋近于无穷大时,就得到顶点间的相似度limk→αsk(a,b)=s(a,b)。通常需要设置一个阈值ε,用来表示精确度,当算法迭代后达到精确度就停止迭代。第k次迭代后,生产的相似度矩阵为Sk,最终算法停止迭代的条件为‖Sk+1-Sk‖≤ε。文献[11]中分析了迭代次数与精度值的关系,并给出了相关式(4),即第k次迭代后的相似度sk(a,b)与实际相似度s(a,b)的关系,这样就可以依据精度值 ε,预先计算出需要迭代的次数k=[lg ε/lg C-1]。

2.3 标签传播算法
标签传播核心思想是:首先给网络中每个的节点分配一个唯一的标签,代表着当前节点所属社区的标签,然后统计与当前节点相连节点的标签分别出现的个数,将标签个数最大的标签赋予给当前节点,多次迭代之后,网络中每个节点的标签达到稳定,此时拥有相同标签的节点就组成为一个社区。更新操作的规则如式(5):

其中li为等待更新目标节点i的标签;N(vi)为节点vi的邻接节点的集合;k为邻接节点中一个节点;lk为节点k的标签;δ(lk,l)表示克罗内克函数,其输入变量为两个整数,当两个整数相等时,函数输出值为1,否则输出值为0。该公式的最优解为节点v邻接节点中标签数量最多的标签。
具体的算法步骤如下:
1)初始化:将网络中的所有节点都分配一个标签,在具体算法中一般把节点的ID作为标签分配给这个节点,代表了该节点所属的社区的编号;
2)更新标签:对网络中所有的节点进行标签的更新。标签更新规则为,统计标签在邻接节点中出现的频率,并将当前节点的标签更新为频率数最大的标签。如果出现频率数最大的标签有好多个,则随机从出现频率数最大的标签中选择一个标签更新为该节点的标签;
3)重复执行上述操作,直到达到算法停止条件;
4)社区划分:统计各个节点的标签,具有相同的标签的节点就处于同一个社区。
该算法在对每个节点分配标签时间复杂度为O(n),每次迭代传播耗时O(m),所以总的时间复杂度为O(m+n)。但是一般情况下,该算法需要迭代多次才能使节点的标签趋于稳定,但是即使多次迭代,时间复杂度仍然是线性的。该算法时间复杂度非常小,适用于大型网络。
3 本文算法
若以G(V,E)表示社区网络,其中,V表示社区节点组成的集合,E代表节点之间的各种关联。对于任意的社区节点vi∈V,li表示其标签,θi表示社区节点vi内容上的主题分布,n代表网络节点数,m代表网络边数。
在传统标签传播算法中,节点在更新其标签时,该节点的每个邻居的重要性同等重要,由此导致节点在更新其标签时,同类型标签的数量成为唯一的衡量标准。受此启发,本文在预测节点标签时,既考虑节点间在网络拓扑图中的相似性,也考虑节点内容的相似性,相似度越高,其影响力越强,权重也越大;在标签更新过程中,节点的标签不再是由邻接节点中标签的数量唯一确定,而是由邻接节点的标签的加权和来决定。
首先考虑邻接节点与当前节点在网络拓扑图中的相似性。运用SimRank算法,可以得出在网络结构图G中节点结构相似度公式ssim(vi,vj),通过计算求得任意网络结构中两个节点结构相似度,从而得到相似度矩阵SSIMn*n。
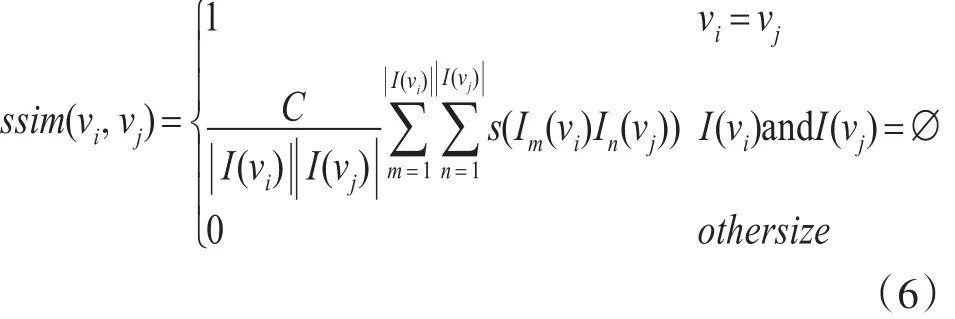
同时传统标签传播算法,往往忽略了网络中节点内容的相似性,节点内容相似度越高,其标签传播能力越强。本文通过主题模型对节点的文本内容进行建模,得到网络中节点vi内容的主题分布θi,从而节点之间的内容相似度,可以通过计算节点主题分布之间相似度来获得。KL散度[15]是计算任意两个概率分布p、q之间相异度的重要指标,如式(7)所示。

本文将KL散度运用于度量节点内容相似度,即节点上内容的主题分布越接近,相似度值越高。因此对上述KL散度加以改造,并用于计算节点的内容相似度,如式(8)所示。

其中θi表示节点vi上内容的主题分布,θj表示节点vj上内容的主题分布。
最后综合节点内容相似度和节点结构相似度,可以得到节点vi,vj的相似度,如式(9)所示。

本文从节点结构和内容相似度角度出发,结合SimRank算法和主题模型,提出了多特征融合的标签传播算法,算法在更新标签时,为邻接节点的标签赋予不同的权重,最终节点的标签由对应标签权重的加权和来决定,具体式(10)如下所示。

其中sin(vj,vi)为节点vj与节点vi的相似度。
算法的具体步骤如下:
1)初始化:设置网络中的标签数为主题模型的主题数,节点的标签为节点上用户的最大概率主题;
2)更新标签:对网络中所有的节点进行标签的更新。标签更新规则为:计算各个标签在邻接节点集合中出现次数的加权和,选择加权和最大的标签作为该节点新的标签,如式(10)所示;
3)停止条件:多次迭代计算后,直到达到算法停止条件;
4)社区划分:统计各个节点的标签,具有相同的标签的节点就处于同一个社区。
4 实验结果及分析
为评估本章所提多特征融合的标签传播算法的有效性,结合新浪API的编写的分布式爬虫程序,从新浪微博上爬取了800个用户,202042条微博记录,在此基础上通过用户的好友关系构建用户社交网络,并与标准的标签传播算法进行了比较实验。
实验过程中,初始社区个数为主题模型的主题个数设置,网络节点的初始标签为网络节点上用户主题分布的最大值所对应的主题,也就是用户的兴趣标签。
实验采用模块度作为衡量算法好坏的指标。模块度[16]衡量的是网络节点分布在完全随机下的结构分布情况与检测得到的社团结构分布之间的差异情况,差值越大,说明得到的结果越不随机化,说明社团检测结果越有效,其式(11)如下:
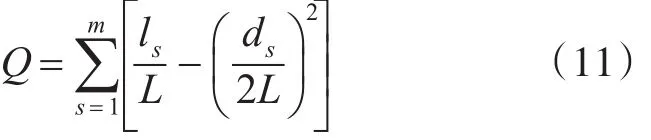
其中,m为算法检测的整个社区个数;L为网络结构中边的总连接个数;ls为社区内部边的连接个数;ds为社团中所有节点的度的总和。
实验分别从算法的检测社区的精度和算法的稳定性两方面进行验证,算法精度方面采用模块度均值进行比较;算法稳定性方面模块度的方差进行比较。本次实验分别在两种算法上运行10次。实验结果如图2所示。

图2 算法对比图
图2可以看出,本章提出的融合多特征标签传播算法在模块度均值方面,明显高于传统的标签传播算法;在模块度方差方面,低于传统的标签传播算法。实验表明本文提出的多特征融合标签传播算法在算法的精度和稳定性上都有所提升。
5 结语
本文充分考虑在标签传播的过程中,节点与节点之间结构和内容的相似度对标签传播影响,首先利用SimRank算法计算标签的结构相似度,其次运用主题模型得到节点上内容的主题分布,以此来计算节点内容的相似度,最后融合两类信息的相似度,用以改进标签的传播策略。该算法弱化了结构不相同、内容不相似的节点对标签传播的影响,同时加强结构相同、内容相似的节点对标签传播的影响,从而有效地促进社团形成。实验证明,本文所提出的算法比原有的标签传播算法有着较好的准确性和稳定性。
猜你喜欢
客联(2022年3期)2022-05-31
中等数学(2021年9期)2021-11-22
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
小学生学习指导(中年级)(2018年9期)2018-09-07
海峡姐妹(2018年3期)2018-05-09
电脑爱好者(2017年7期)2017-05-06
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
