
改进tiny-yolo的车辆检测算法∗
2019-12-27 06:32何姣姣张永平常志国姚拓中
计算机与数字工程 2019年12期
刘 肯 何姣姣 张永平 常志国 姚拓中
(1.长安大学信息工程学院 西安 710064)(2.宁波工程学院 宁波 315211)
1 引言
随着经济的飞速发展,汽车的数目在近几年内飞速骤增,方便了人们出行的同时,引发的问题也是接连不断,堵车、交通事故、不遵守交通规则等,迫切需要一种方法对车辆进行实时的检测和识别,从而缓解和减少以上存在的问题。传统的目标检测方法中,Seki等将背景差分应用于动态车辆的检测[1];Stauffer等提出了一种具有自适应的背景更新法[2];Koller等又将3D模型应用车辆跟踪和检测[3],用来提高识别率。以上的方法都是基于传统的算法。近几年随着深度学习的兴起,目标检测和分类进入一个新的阶段。与传统的特征提取算法不同,卷积神经网络对目标的几何变换,形变,光照具有一定的不变性,有效克服车辆外观多变带来的识别困难。2013年R-CNN[4]将传统的机器学习和深度学习结合起来,提出选择性搜索(Selective Search)[5]等经典算法,在 VOC2007[6]测试集上的map(平均预测精度)被提升到了48%,2014年通过修改网络结构又将map提升到66%。之后出现的网络 SPP-net[7],Fast R-CNN[8],Faster R-CNN[9],YOLO[10],SDD[11]等都是对目标检测网络的优化。其中Faster R-CNN将检测和分类模块都放在同一个深度学习框架之下,就检测准确率相比其他目标检测算法要高,但是随之带来的缺点是速度慢,YOLO 算法的网络设计策略延续了 GooGleNet[12]的核心思想,实现端对端网络的目标检测,发挥了速度快的优势,但是其精度有所下降。本文选取的框架为tiny-yolo,tiny-yolo网络是传统的端对端型网络,所以存在对特征没有完全利用,导致检测精度下降,尤其是对小目标检测。本文通过对其网络结构增加修改,提高了对小目标的检测精度和漏检率。
2 tiny-yolo框架
tiny-yolo是 yolov2[13]的基础网络,但是相比于yolov2结构比较简单,运算复杂度比较低。网络是由9个卷积层和6个最大池化层交替组成的前向网络,导致信息在层与层传递时丢失,未能充分利用卷积层的特征信息,导致其检测精度的欠缺,尤其是对小目标的检测效果较差,经过多个卷积操作后,图像特征变得很小,很容易对远处的物体或者小目标造成漏检和误检。具体结构如图1所示。
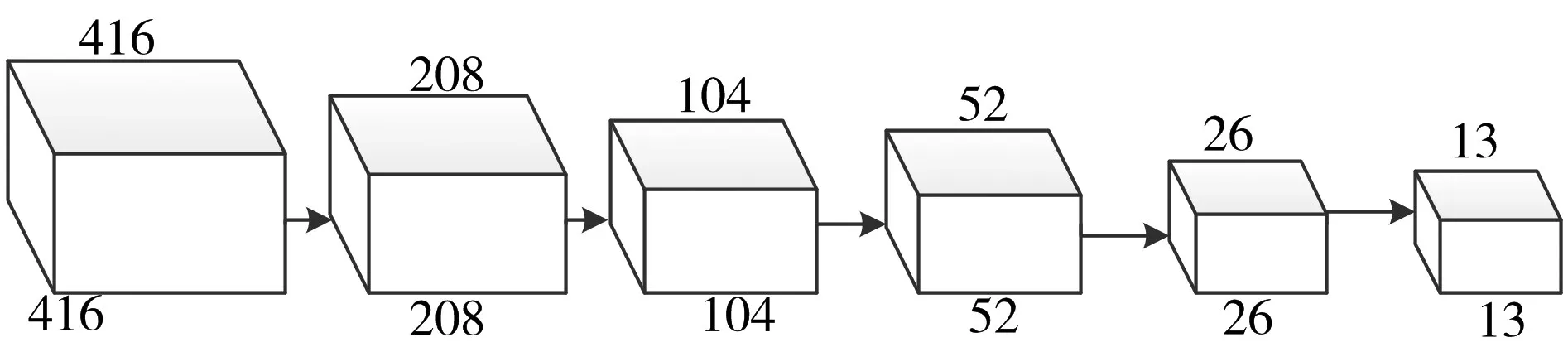
图1 tiny-yolo结构图
如表1 tiny-yolo的结构参数所示,从网络的输入到最后的输出,特征尺度下降了32倍,整体网络模型属于端对端型网络,中间造成很多特征损失。
3 数据预处理
3.1 数据来源
本文采用的数据集实际UA-DETRAC[14]数据集和自己用摄像机采集后,使用LabelImage进行标注。DETRAC数据集主要拍摄北京和天津的道路过街天桥,图片大小为960*540,包含多个角度的车辆照片。自己采集的数据为人行天桥采取的高清图片,分辨率为1920*1080。为了方便训练,本文将训练图片的大小统一为960*540。数据集分为(car)和背景两类。
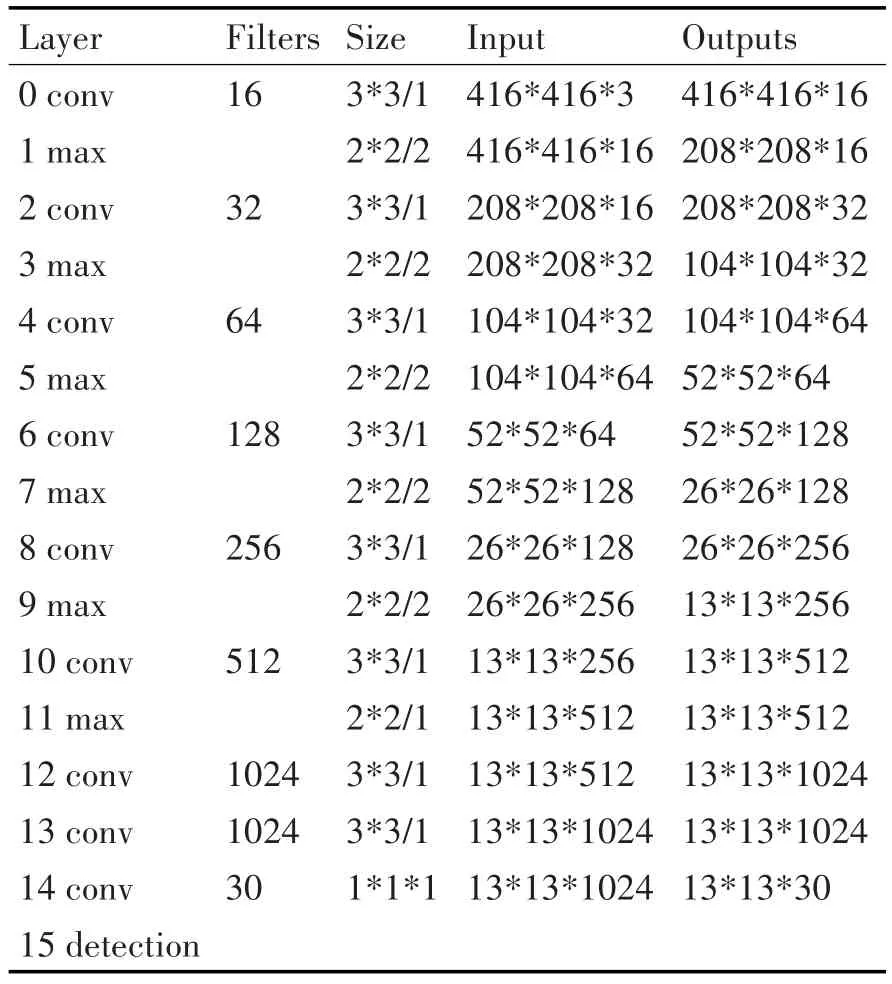
表1 tiny-yolo的参数
3.2 数据扩充
对于上面的训练集,本文把所有的图片和标签,制作成为VOC2007数据集格式,用以方便我们后面的训练和测试。在进行数据训练之前,对数据进行了如下的预处理。1)旋转角度;2)调整饱和度;3)调整曝光量;4)调整色调。由于车辆的形态比较多样化,为了可以使网络学习到更多的信息,本文采用以上四种方式对数据集进行丰富化,从而生成更多的训练样本。
3.3 K-means[15]聚类
在训练网络时,需要预设候选框的初始大小和个数,通过预选框的不断调整,使其最终接近我们标注的真实框,容易加快网络收敛的速度,提高车辆的定位精度。K-means聚类使采用欧氏距离来衡量两点之间的距离。本文对预选框宽高与单位网格长度之比进行聚类。IOU(intersec⁃tion-over-union)[16]反应的是预选框和真实框差异的重要参数,IOU值越大,代表两者之间的差异就越小,距离也就越近。聚类的目标函数为

公式中N代表聚类的类别,M代表聚类的样本集大小,Box[N]代表聚类得到的预测框宽和高,Truth[M]代表的是真实框的宽和高。
4 改进网络结构
tiny-yolo是由9个卷积层和6个最大池化层交替组成的前向网络,整体网络结构属于端对端型。由于含有较多的最大池化层,后面的卷积层会造成很多的特征丢失。从而影响最终的检测。我们通过添加上采样层,与前面卷积层的特征进行融合,提高网络对目标的特征学习。在进行实验时,我们采用两种可行性方法验证,如图2所示中的输出1和2两种输出,1方式是对13*13的大小的卷积层进行2*反卷积操作,然后和上一特征层26*26对应像素相加,进行特征融合,最后将融合后的特征进行卷积操作,目的是将最后的尺度归一成13*13大小。2方式是将13*13大小的卷积层进行两次反卷积操作,然后和前面特征层52*52对应像素相加,再进行步长为2的卷积操作,为了提高最后的定位精度,本文添加一条横向连线(即将上一步卷积操作后的特征和26*26的特征层进行融合),最后同样的将最终的特征尺度归一化到13*13大小,进行最后的预测。
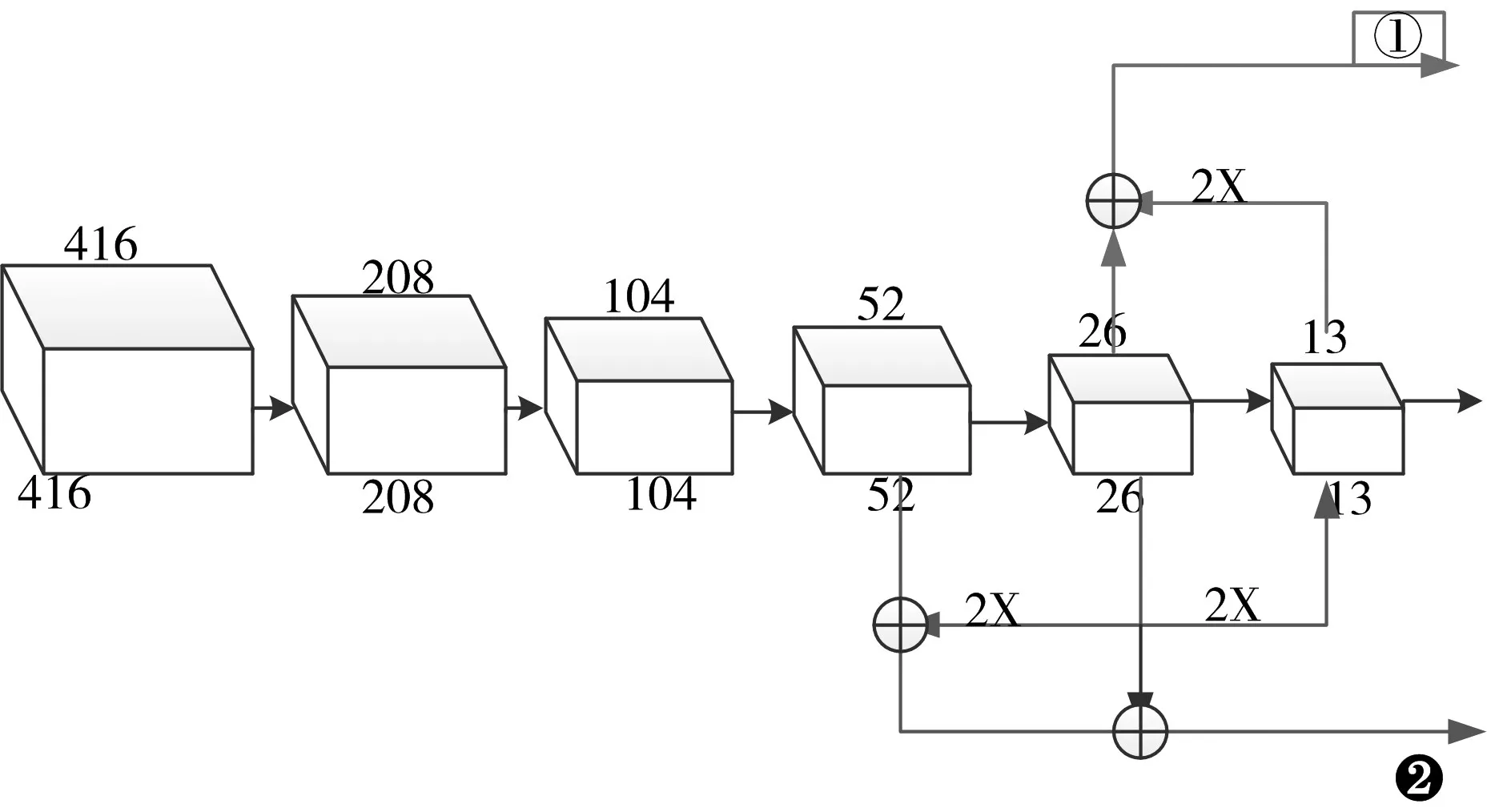
图2 改进后的tiny-yolo结果
在以上特征融合时,为了避免特征融合后出现的重叠影响,需要在每一次像素叠加后,进行1*1大小的卷积操作,以消除特征融合带来的负面影响。
5 实验
5.1 实验平台
实验主要在PC端完成的,PC的主要配置:win⁃dows7 64 位 ,CPU(i5-8600),GPU(NVIDIA GTX-1080 8G显存)和16G内存,实验使用darknet框架。
5.2 训练
在进行前期的数据增强后,开始训练,在实验中,我们设定总共迭代的次数max-batches为40000次,每一次从训练集中抽取8张图片,初始学习率为0.001,采取steps decay(即迭代次数超过一定的数值,学习率将变为之前的0.1倍),为了加快网络收敛,在进行卷积操作之后进行batchnormal操作。为了训练模型能够进行更好的泛化,文中所有的实验都进行多尺度训练(即对输入的图片进行任意尺度的缩放和增放)。
5.3 评价指标
根据性能要求的不同,目标检测有很多的研究指标,比如检测精度,定位准确率,检测效率,查全率等。本文主要比较检测精度和查全率这两个指标。

公式中TP代表检测为正样本,实际上也是正样本,FN代表检测为负样本,但实际上是正样本,FP代表检测为正样本,实际上是负样本。
5.4 实验结果
为了验证算法可行性,本文进行了六组对照实验,并且分别在阈值为0.25和0.50的条件下对验证集进行测试,实验结果如表2和表3所示。
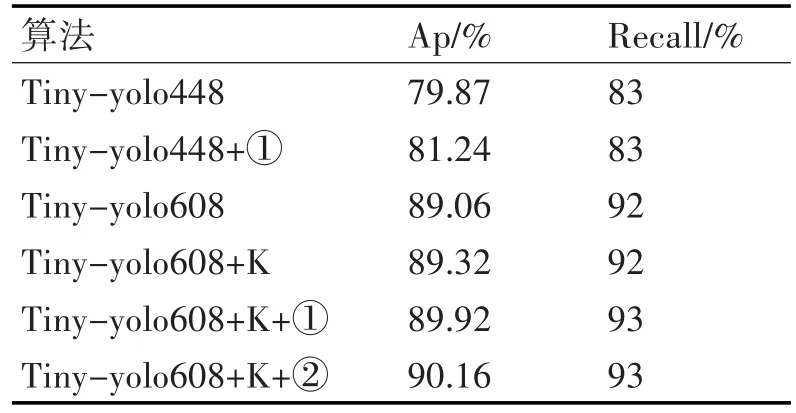
表2 0.25阈值结果
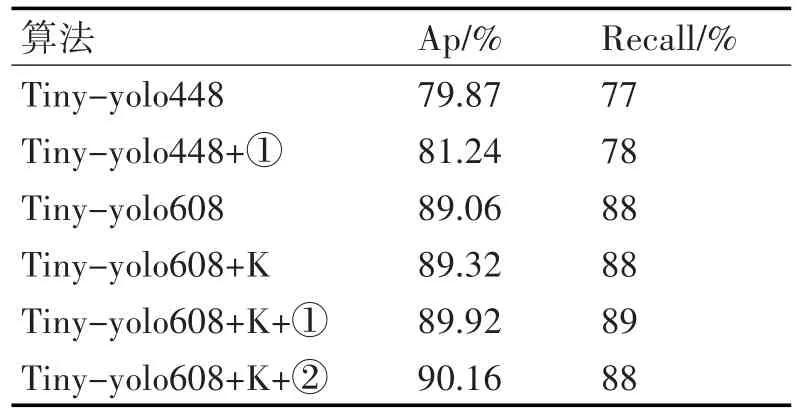
表3 0.50阈值结果
如表2~3所示,对于每一种算法,本文分别选取阈值为0.25和0.50进行结果分析。其中tiny-yo⁃lo448表示在将测试图片送进网络时,将图片大小resize成448*448大小,网络最后输出的特征为13*13;Tiny-yolo448+①表示在网络输入尺寸为448*448的尺寸,同时使用图2中的①结构对网络进行修改;Tiny-yolo608代表将测试图片大小resize成608*608大小输入网络,网络最后的输出特征为19*19;Tiny-yolo608+K表示先前对预选框进行聚类;其他算法类似上面所述,应用图2中的①②结构对网络进行改进。
5.5 结果分析
从上面的结果可以看出,当对测试图片resize为448*448网络而言,通过添加①网络后,查准率相比较之前的网络提升了1.37%,查全率几乎不受影响;对于同样的训练集,网络输入大小从448*448变大为608*608之后,查准率增加了9.19%,查全率提高了9%,说明了网络对大尺寸的图片比较敏感;在输入尺寸为608*608网络通过重新聚类后,总体查准率提升了0.3%;重新集合本文的①②结构后,查准率分别提升了0.86%,1.1%,说明语义和分辨率的结合越丰富,越有利于网络的学习。对于不同阈值,从表2和表3可以看出,具有相同的查准率,上表结果表明阈值越小,查全率越高。图3~6是部分检测结果图,图7为tiny-yolo608+K+②的loss损失曲线图,其中横坐标表示迭代次数,纵坐标表示loss大小。

图3 正面密集车辆

图4 夜间车辆

图5 十字路口车辆(分散)

图6 十字路口车辆(密集)
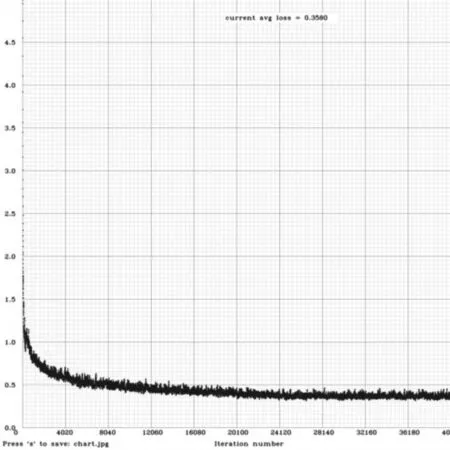
图7 tiny-yolo608+K+2损失曲线
6 结语
本文通过对tiny-yolo网络进行重新聚类和添加反卷积操作,并且与改进之前的网络进行对比实验,结果表明,对于端对端结构的网络,通过添加反卷积操作可以提高网络的检测精度,尤其是对于小目标,但是实验发现,由于网络对小目标变得敏感,但是对于大物体的敏感程度降低,导致网络对大物体的识别率降低。下一步工作尝试自适应网络大小对物体进行识别,平衡网络对大小目标的敏感程度。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
环球时报(2022-03-09)2022-03-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
小太阳画报(2018年3期)2018-05-14
阅读与作文(小学低年级版)(2016年12期)2016-12-22
