
基于LeNet-5模型的手写数字识别优化方法∗
2019-12-27 06:32汪雅琴夏春蕾戴曙光
计算机与数字工程 2019年12期
汪雅琴 夏春蕾 戴曙光
(上海理工大学光电信息与计算机工程学院 上海 200093)
1 引言
当今社会,人工智能得到快速发展,而模式识别作为人工智能的一个重要应用领域也得到了飞速发展,它利用计算机通过计算的方法根据样本的特征对样本进行分类,其中的光学字符识别技术受到广大研究学者的青睐。手写数字识别是光学字符识别技术的一个分支,主要研究如何利用电子计算机自动辨认人手写在纸上的阿拉伯数字。现阶段手写数字识别的主要研究方法有统计、聚类分析和神经网络。
最小距离分类算法是模式识别中较传统、简单的方法之一,但是对手写字体适应性不高[1]。K最近邻算法(KNN)是一种基于统计学的分类算法,最早于1968年由Cover和Hart提出,作为最简单的机器学习方法,理论上研究已比较成熟[2]。支持向量机(SVM)是由Corinna Cortes和Vapnik等于1995年首先提出的,该算法有很好的泛化能力与学习能力,以结构风险最小化为目标,所求得的解是全局最优解,克服“维数灾难”问题,大大增加效率[3]。BP(back propagation)神经网络是1986年由Rumel⁃hart和McCelland为首的科学家小组提出的,作为一种多层前馈网络,是在误差逆传播的基础上建立的[4],常与梯度下降法等最优化方法结合使用。BP神经网络算法是一种有监督的训练方法,且激活函数为非线性可导的[5]。以上这些传统的识别方法对复杂分类问题的数学函数表示能力以及网络的泛化能力有限,往往达不到高精度识别的要求[6]。卷积神经网络(CNN)最初由美国学者Cun等提出,是一种层与层之间局部连接的深度神经网络[7],需要经过信息的正反向传递。因为CNN的局部连接、权值共享及池化操作等特性,CNN可以有效降低网络的复杂度和减少训练参数的数目[8]。
近年来,由于神经网络具有推广能力、记忆力、非线性和自学习能力以及高速运算能力[9],所以卷积神经网络被广泛用于手写数字识别。LeNet-5模型作为一种典型的用来识别数字的卷积神经网络不断地被优化改进。本课题即在LeNet-5模型的基础上,利用MNIST字符库,通过改变样本训练方式,从而获得一种更高效准确的手写数字信息自动识别方法。
2 卷积神经网络
由美国学者Cun等提出的卷积神经网络(CNN)是一种深度前馈人工神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,在图像识别领域得到很好的应用。卷积神经网络的网络模型复杂度大大降低,网络训练更容易,多层的网络结构有更好的抽象表达能力,可以直接将图像作为网络输入,通过网络训练自动学习图像特征,从而避免了复杂的特征提取过程[10]。
2.1 卷积神经网络结构
典型的CNN由五部分组成:输入层、卷积层、下采样层(池化层)、全连接层以及输出层[11]。其中卷积层和下采样层会交替出现。如图1所示。
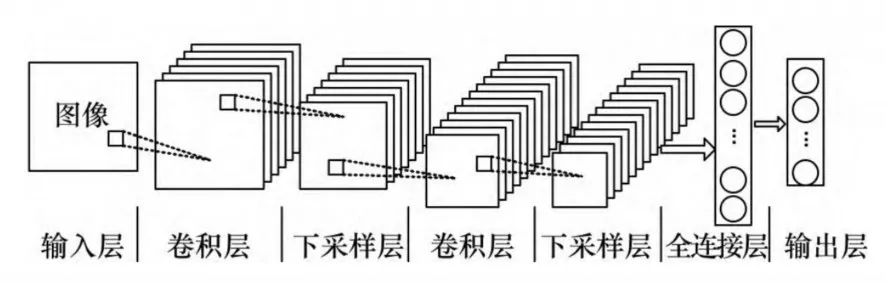
图1 卷积神经网络结构
卷积层也叫做特征提取层,主要作用是提取输入数据特征。提取的数据特征数量由卷积核的数量决定。卷积层就是用一个可训练的滤波器 fx去卷积一个输入的图像(第一层卷积是输入图像,之后的卷积层则为卷积特征图),然后加上一个偏置bx,得到卷积层Cx。卷积的结果经过激活函数映射后形成下一层的特征图[12]。
下采样层,也叫做池化层,主要目的是在保留有用信息的基础上减少数据处理量,加快训练网络的速度。同时,可以对特征图进行降维,在一定程度上保持数据的平移不变性,减少了网络中的参数数量和计算量[12]。下采样过程是将邻域的四个像素求和变为一个像素,然后与Wx+1加权bx+1,再加上偏置,然后通过一个sigmod激活函数,产生一个缩小四倍的特征映射图Sx+1。sigmod函数常作为激活函数使用是因为它能将每层的输出压缩到[0,1],使得最后的输出平均值一般趋于0。如图2所示。
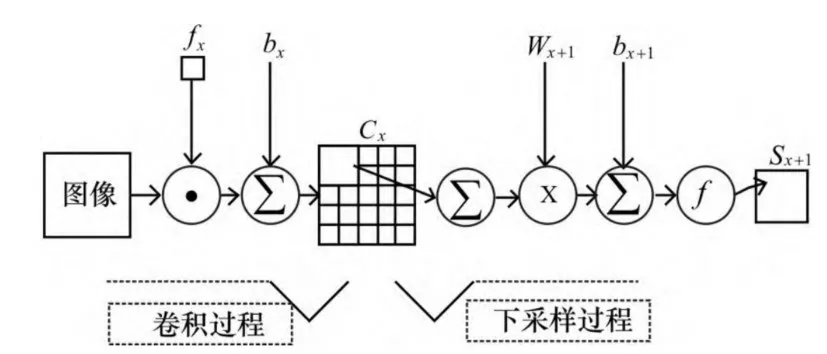
图2 卷积神经网络的卷积过程和下采样过程
2.2 LeNet-5模型结构
LeNet5模型是Yann LeCun教授于1998年提出来的,它把特征提取和识别结合起来,通过综合评价和学习,并在不断的反向传播过程中选择和优化这些特征,将特征提取变为一个自学习的过程,通过这种方法找到分类性能最优的特征[13]。它是第一个成功应用于数字识别问题的卷积神经网络。传统的LeNet-5模型的输入图像为归一化到大小为32×32的图像,除去输入层,由7层组成:卷积C1、C3、C5和下采样层S1、S4,以及全连层F6和输出层[14],如图3所示。每层都有可训练参数,共有60850个参数。对这些参数的训练需要消耗大量的时间,因此出现了改进后的模型结构。改进后的LeNet-5模型,如图4所示,参数减少到3966个,节省了大量的训练时间,使得学习过程更为高效。

图3 传统的LeNet-5模型结构

图4 改进后的LeNet-5模型结构
改进后的LeNet-5模型以大小为28×28的手写数字图片作为输入,C1和C3是卷积层,S2和S4是下采样层,F5是全连接层。与传统模型对比可知,改进后的模型在第二次卷积和下采样的过程中减少了卷积核的数量,同时去掉了一个全连接层。
2.3 算法实现
卷积神经网络是一种有监督的学习训练。学习过程包括两个方面:误差的逆行传播和信号的正向传播。样本从输入到输出的过程就是信号的正向传播。若输出层得到的结果与理想结果存在差异,就会进入误差的反向传播过程。这两个过程的最终目的都是为了更新权值,提高识别率。
整个算法的实现可以根据学习过程相应地分为两个过程。首先是信号的正向传播过程,又可以细分为卷积过程和下采样过程。用l表示当前层,那么当前层的输出可以表示为

其中ul=WlXl-1+bl。
式中,ul表示当前层的输入,Wl表示当前层特征图的权值(卷积核),Xl-1表示前一层的输出,bl表示当前层的的偏置(基),f表示激活函数。
若当前层为卷积层,则第 j个神经元的输出表达式为

式中,Mj表示第 j个神经元输入特征图的集合,是上一层第i个神经元的输入,表示上一层第i个神经元和当前层第 j个神经元间的权重,表示第 j个神经元上加的偏置。
若当前层为下采样层,则第 j个神经元的输出表达式为
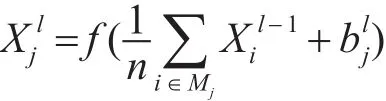
式中,n表示卷积层到采样层窗口的大小,一般选用2×2的窗口,则使特征图大小缩小四倍。
然后是误差的逆向传播过程。常使用平方误差代价函数,是针对C类问题N个样本而言的,即最后输出为C维数据:
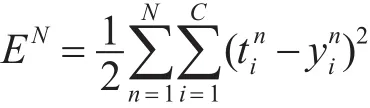
因为全部训练集的误差就是每个训练样本误差的总和,所以只需要对单个样本进行误差分析即可。单个样本经由网络产生的误差用代价函数表示为
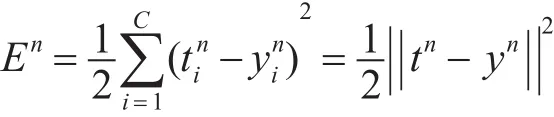
逆向传播回来的误差可以看作是每个神经元的基的灵敏度,计算公式如下:

式中,“◦”表示每个元素相乘。
最后,利用delta(即δ)规则对每个神经元进行权值更新。即利用梯度下降的方法,将代价函数对网络中参数求偏导,乘以负的学习率,对参数进行更新,最终使代价函数达到极小值[11]。权值和基更新变化量的表达式如下所示:

3 实验结果及分析
3.1 实验训练样本选择
本次实验使用的数据集是MNIST字符库,如图5所示。MNIST字符库具有60000张训练集以及10000张测试集,图片的像素都为 28*28[15]。

图5 MNIST字符库部分样本
3.2 实验结果及分析
常规训练时采用每次输入固定数量的训练样本,在固定时间内,迭代一定的次数。每次迭代都会完成前向过程,错误反向传导过程,以及权值更新过程,从而得到更加准确的权重和偏置。如果每批训练输入样本数量分别为10,20,50,则一次迭代对应耗时分别为 275s~285s,230s~240s,180s~190s。当每次训练样本数量不变时,测试错误率随着迭代次数的增加而降低,即识别率在不断提高,但是这种变化越来越不明显。如表1和图6所示。
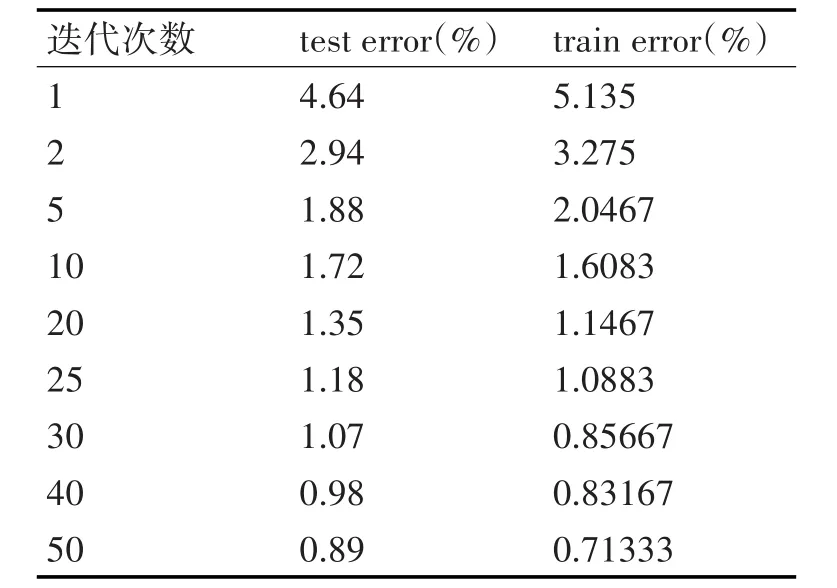
表1 每批输入10个样本,不同迭代次数的测试错误率

图6 不同迭代次数的测试错误率
在图6中,我们绘制了每次训练样本数量分别为10,20,50时,识别率与迭代次数的关系。可以看出当每次训练样本数量不变时,随着迭代次数的增加,一开始测试错误率下降的较快,但是迭代次数超过20次以后,下降的速度明显减缓。
针对以上实验结果,如果采用混合样本训练方法,则能够在相同时间内,得到更高的识别率。在一次训练过程中采用了三种不同的每批训练输入样本数量。当它们以不同的迭代次数组合时,会得到不同的识别率。在计算训练时间时,我们取每批训练输入样本数量所需的最小时间,即当每批训练输入样本数量分别10,20,50,则一次迭代对应耗时分别为275s,230s,180s。如表2所示。
将表2中训练时间分成6段,可以得到表3。
在比较每个训练时间段中的组合时,首要考虑因素是识别率,因为时间段只间隔了不到一分钟,可以忽略不计。从表3中,我们可以得到组合○15存在着更明显的优势。
4 结语
本文在优化后的LeNet-5模型的基础上,改进样本训练方式。原本采用的单一样本训练方式,在迭代次数达到一定值后,手写数字识别率的提高不再明显。针对这一缺陷,混合对样本进行训练,即在一次训练的过程中利用不同的每批训练样本数量,使得在同等的时间内,获得更低的测试错误率,即更高的识别率。通过实验结果可知,这种训练方式是可行的,且在一定程度上提高了识别率,达到了预期效果。
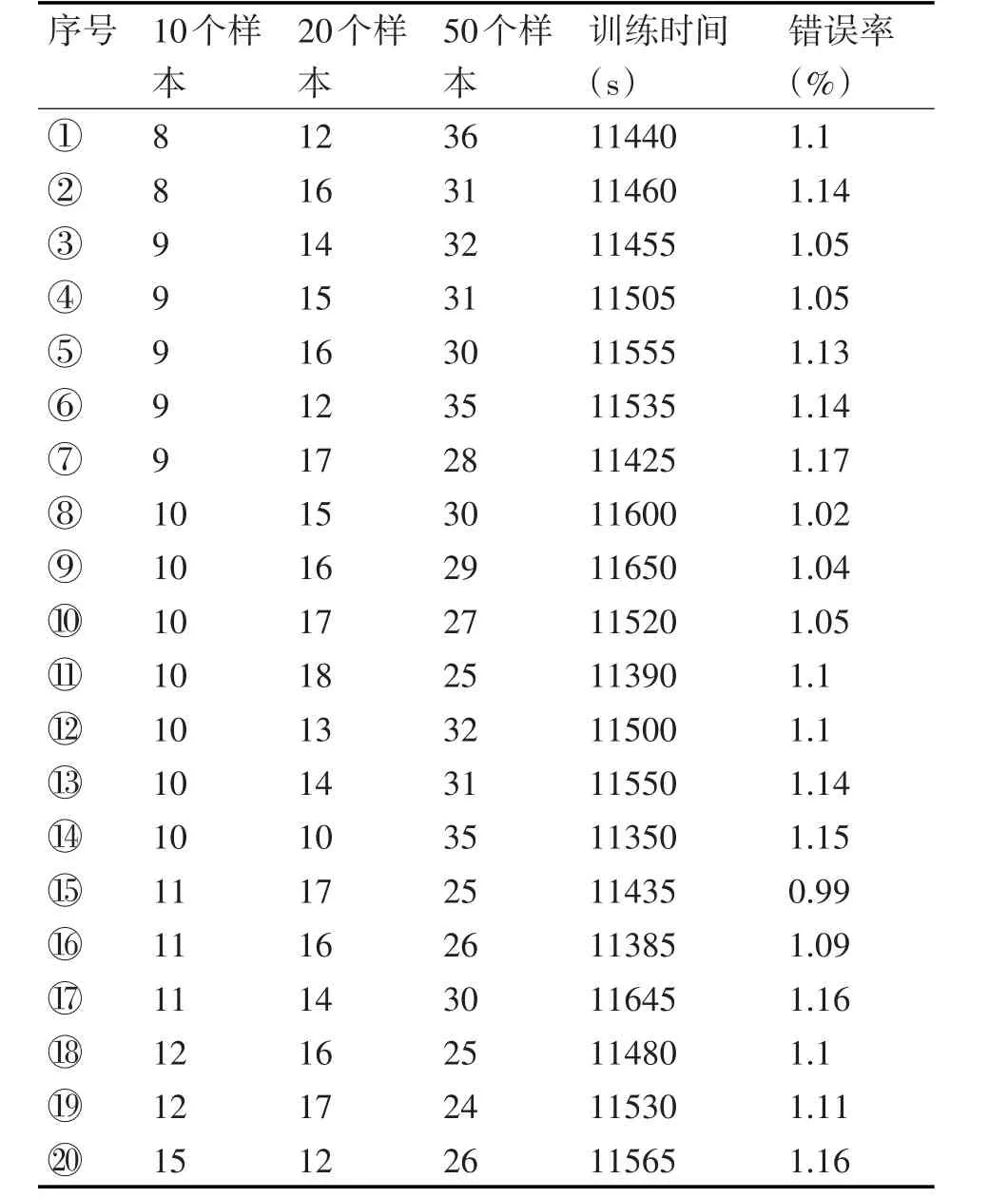
表2 三种每批训练输入样本数量的不同迭代次数组合

表3 不同时间段的训练时间对应的迭代次数组
猜你喜欢
电子产品世界(2021年8期)2021-01-16
科技创新与应用(2020年6期)2020-02-29
中国计算机报(2019年49期)2019-02-07
中国新闻周刊(2017年36期)2017-10-21
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
创新时代(2016年8期)2016-10-21
