
基于深度学习的LSTM光伏预测
2020-01-03 01:21崔承刚邹宇航
上海电力大学学报 2019年6期
崔承刚, 邹宇航
(上海电力学院 自动化工程学院, 上海 200090)
近年来,光伏发电规模随着清洁能源的推广应用不断扩大。但由于光伏发电量随天气变化产生波动性,不利于电力系统的安全经济运行,使得光伏发电大规模并网遇到了阻碍[1]。准确地进行光伏出力预测是目前迫切需要解决的一大难题,也是可再生能源电力系统的研究热点之一。为提高光伏预测的精度,传统的算法一直在改进,新的算法也不断地被提出,主要可分为物理方法、统计方法和智能预测方法等几大类[2]。
物理方法是将光伏电池模型、逆变器模型以及光伏面板参数等整合起来进行建模预测。机理模型主要由太阳辐照方程和光电转化方程两大重要部分组成。由于物理方法存在受光伏组件影响较多的缺陷,同时光伏电站的地理信息和气象信息较难获取,所以导致模型的精确度无法满足要求,在实际工程运用中会产生较大误差[3-4]。
统计方法需要大量的历史数据作为输入,涉及概率统计和聚类等方法,主要包括分类回归、时间序列、模糊聚类等方法。统计方法的不足在于,光伏特征因素和光伏预测的函数关系很难直接从历史数据中提取,使得预测结果与实际存在较大偏差,因此在实际应用中很难得到普及[5-8]。
智能预测方法不同于传统的物理及统计方法,需要从大量气象、光伏数据中通过模型的自学习能力进行数据挖掘,寻找规律进行预测。目前,光伏预测已从传统的浅层神经网络向更深层次、更多维度方向发展。之前智能预测方法基于训练函数拟合能力,例如人工神经网络(Artificial Neural Network,ANN)[9]与支持向量机(Support Vector Machine,SVM)等。尽管此类方法在电力预测领域发挥了重要的作用,但同样存在长时间序列记忆能力没有得到解决、多特征多维度的数据无法清晰表达、预测精度不理想等问题。基于此,HINTON G E等人提出了深度学习算法,揭开了第一轮智能算法的探讨[10]。
2016年3月,经过深度学习算法训练的AlphaGo击败了人类围棋顶尖高手;2017年10月19日《自然》发表的一篇研究论文中指出:在无任何人类输入的条件下,AlphaGo Zero能够迅速自学围棋,并以100∶0的战绩击败“前辈”。自此掀起了深度学习算法的第二轮研究浪潮。目前,深度学习算法多领域的应用已初见成效,文字分析、图像处理、语音识别等方面都有突破性的创新[11]。在光伏预测领域,深度学习算法仍处在起步阶段。多参数优化、神经网络结构调整、局部最优等是算法改进道路上亟待解决的难题[12]。
1 模型的可行性分析
深度学习算法的多神经网络层为其应对多特征的数据提供了有利结构,而光伏预测的输入特征在时间尺度上的有序变化,其中包含了太阳辐射强度、温度、气压等诸多特征,两者的组合为光伏预测带来了新的可能。传统神经网络模型需要花费大量时间在数据预处理上,包括数据清洗筛选、查漏补缺以及对影响因素较小的特征项进行剔除。这些看似智能的预测方法,实则需要大量的人工干预,只能算作是半智能算法;而人为的特征筛选,无法找到各个特征之间内在的隐藏联系,从而造成了特征原始属性无法完整表达、错误估计特征量的潜在联系等问题。相对来说,深度学习算法模型因其具有深度结构,并且包含多层的隐层节点,可以更好地保留特征间的隐藏属性,使模型蕴含的信息能够完整表达。前期复杂的筛选工作由于模型的自学习能力得到有效简化,干扰因素在权重与偏置的调整下逐渐弱化,使得光伏预测研究真正走上了智能预测的道路。
人工提取特征属于浅层结构学习,不具有普及性;而深度学习算法则将光伏预测的特征进行深层次提取学习,并在神经网络中进行复杂的特征变换,即使在不同地区、不同时间也能捕捉到深层特征与隐藏信息,使其在不同情形下能有相同预测效果[13]。循环神经网络(Recurrent Neural Network,RNN)作为深度学习中处理和预测序列数据的良好模型,在各个领域都得到大量应用;而长短时记忆网络(Long-Short-Term Memory,LSTM)作为RNN的一个重要结构,在序列数据的长期记忆方面表现更为良好;在光伏预测中,辐照度、风速、温度、大气压力等都是随时间变化的序列数据,理论上利用LSTM进行光伏预测切实可行。
2 基于深度学习的网络模型
得益于人工神经网络的研究,深度学习模拟神经元运作方式对数据进行表征学习,通过多隐藏层之间的联系建立起多层感知器的学习结构,简单的数据形式在神经网络的作用下通过升维、降维获得了高层特征,数据表达方式也得到了更新[14]。
2.1 LSTM模型
作为RNN中的一个重要结构,LSTM通过小模块的连接建立时间递归神经网络,将时间序列中的延迟事件保存下来,并在后续训练中进行提取。为了使子模块保存长期记忆,LSTM引进了核心结构“遗忘门”和“输入门”。遗忘门可以让循环神经网络遗忘无用的信息,输入门可以输入补充最新的记忆,两者的密切配合决定了信息的遗忘与保留[15]。
通过刻意的设计,LSTM将遗忘门层、输入门层、更新门层以及输出门层组合成为交互的层,解决了长期依赖问题。LSTM的这些“门”结构组合处理器被称为cell。当输入进入cell中后,根据判定规则决定信息的遗忘或保留。简单的一进二出的工作原理,在反复运算下解决了神经网络中存在已久的长序依赖问题。此外,LSTM具有较高的普适性和灵活性。cell间的结构使得模型具有较长时间的记忆功能,且使误差传递没有衰减,当前信息即使在长时间后的训练中也能得到保存,并对当前状态进行调整。
LSTM具体结构如图1所示。图1中,xt为t时刻输入;Ht-1为t-1时刻LSTM的输出;Ct-1为t-1时刻单元状态输出;Ht为t时刻输出;Ct为t时刻单元状态输出;ht为t时刻的信息保留;tanh为双切正切函数,使输入值的取值范围为[-1,1]。在特征相差明显时,表现出良好效果并在循环过程中会不断扩大特征效果。

图1 LSTM内部结构
2.2 LSTM训练的核心思路
为了设计与结构相适应的训练算法,反向传播算法(Back Propagation Through Time,BPTT)因其梯度回传特性被引入训练之中,从而使误差在cell间传递时保证了数据的完整性。输入误差在当前cell中得到保存,继续朝更前一个时间状态进行反向传播。图2展示了两个cell间反向传播算法的具体流程。

图2 反向传播算法运算流程
从图2可以看出,误差回传到输入输出门和一个cell的输入之后,继续传递并对当前cell中的各个部分权值进行修改,获得了更好的训练效果。
3 基于LSTM的光伏预测模型建立
3.1 输入数据预处理
光伏预测的难点之一在于前期的数据处理,光伏电站的信息采集系统的稳定运行对预测过程影响巨大。数据不完整、缺失以及数据质量差是预测中首先要解决的问题。常用的数据修正方法是复杂度较低的K近邻补全算法,即选取集中缺失数据的k个完整最近邻数据来进行补缺。序列数据最大特征就是相邻数据间具有相似性。若有某一段数据缺失,根据其前后数据的连贯性,选择辅助变量,找到最邻近的k个样本,求取平均值来替代缺失值。
首先,利用欧式距离法判断远近,公式为
(1)
式中:Xi={xi1,xi2,xi3,…,xim}——第i个样本点的前m维数据;
Xj={xj1,xj2,xj3,…,xjm}——第j个样本点的前m维数据;
xir——第i个样本点的第r维属性;
xjr——第j个样本点的第r维属性。
在进行上述判断后将序列归一化,控制样本数据在[0,1]的变化范围内。公式为
(2)
式中:yi——归一化后的输出值;
xi——输入值;
max(x)——此数组最大值;
min(x)——此数组最小值。
3.2 输入输出量的选择
在对输入数据进行预处理后,如何选择合适的输入量及标签来使用神经网络进行训练,是建立负荷预测模型中最为关键的一步。光伏预测中影响因素很多,物理预测方法要求选取最为关键的因素作为输入量。利用深度学习的方式进行预测,可有效避免数据筛选这项工作。此外,由于LSTM网络特性,在训练中对权重影响较小的特征项,会在迭代中逐步被遗忘。具体输入特征如图3所示。其中:xt为t时刻输入,it为t时刻输入门状态,ot为t时刻输出门状态,ft为t时刻遗忘门状态,ct为t时刻cell当前状态,ht为t时刻输出。

图3 输入特征量
3.3 LSTM模型参数及相关函数选择
LSTM模型主要由5个参数进行约束,包括神经网络层层数、步长、训练块大小、学习率、输入输出变量维数。神经网络层层数确定了网络的基本结构,步长则表示每次训练的跨度,训练块大小决定输入的大小,学习率表示训练速率,输入输出变量维数则确定了网络训练的输入输出之间的关系。
本文所用数据每天采样点数在80~150;多次实验后,以40个历史数据作为一个batch用于预测,每个历史数据具有39个特征值,所以输入层维度为40×39,输出层采用单输出LSTM的预测模型,维数为1;隐藏层数目的多少决定了模型的拟合能力,层数太少拟合效果差,反之则会增加训练成本,需要根据数据大小进行动态调整。
3.3.1 激活函数
目前,训练RNN最有效的算法是反向传播算法。简而言之,LSTM网络通过反向传播,以减少代价为导向,调整各项参数。采用梯度下降算法,沿梯度下降方向调整神经元之间的连接权重w和每个神经元本身的偏置b,公式为
(3)
(4)
式中:C——代价;
a——输出值;
y——实际值;
z——神经元的输入;
x——样本;
σ——激活函数。
若要训练收敛较快,则选用的激活函数梯度就越大。
激活函数选取不当,会造成梯度消失:当数值接近于正向∞,求导之后就更小,约等于零,偏导为零。Sigmid会发生梯度消失,很少采用;Tanh同样会梯度消失;ReLu相对较好,不仅避免了梯度消失的问题,而且起到了降维作用。
3.3.2 损失函数设计
损失函数(loss function)动态表达了训练过程中预测值f(x)与真实值Y的误差变化过程,用L(Y,f(x))表示,模型的好坏与损失函数密切相关。模型的结构风险函数θ*由经验风险项和正则项两部分组成,损失函数作为经验风险的核心部分起着至关重要的作用。公式为
(5)
式中:θ——经验风险函数;
N——迭代次数。
损失函数度量的是预测值与真实值之间的差异,通常写作L(y_,y),y_代表预测值,y代表真实值。目标函数可以看作是优化目标,优化模型的最终目标是使目标函数最大或者最小。代价函数类似于目标函数,区别在于:代价函数可以包含一些约束条件如正则项,以准确率作为最终的评测指标,而损失函数仅仅表达了训练过程中的误差变化。
3.3.3 隐藏层的确定
在确定神经网络模型的输入输出及隐藏层层数的参数后,即可搭建神经网络基本架构。在其他条件不变的情况下,隐藏层选取得越多,网络数据处理能力和学习训练能力更好;但神经元的增加,带来的是模型复杂程度的增加,若深度学习平台没有很好的硬件支撑,训练速度将会变得十分缓慢。隐藏层节点的选取主要依靠经验,在对模型进行无数次调参后,确定最优参数。新模型一般会选用经验公式并配合试凑法进行隐藏层层数的选定,经验公式为
(6)
式中:l——隐含层节点数;
m——输出层节点数;
n——输入层节点数;
c——调节常数,取1~10。
光伏发电功率的预测模型输入层节点数为39,输出层节点数为1,则根据式(6)可初步确定出隐含层节点数在6~10之间。
3.3.4 预测效果评估
光伏发电系统在夜间无法运行,发电功率为零。由于采用平均绝对误差(Mean Absolute Error,MAE)或者标准差(Standard Deviation,SD)会导致某些误差无法计算,所以选用均方根误差(Root Mean Square Error,RMSE)进行讨论,公式为
(7)
式中:εRMSE——模型控制绝对误差的性能;
n——预测验证数据个数;
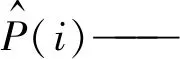
p(i)——风电功率的实际值;
i——预测点序列编号;
Cap,i——输出序列最大值。
4 算例分析
本文采用美国佛罗里达州Cocoa地区某光伏电站发电数据。该地区位于西五区,北纬28.39°,西经80.46°,海拔高度为12 m。光伏组件采用施耐德Micro03036,光伏面板倾斜率为28.5°,光伏模块方位角为180°,时间为2011年1月21日至2012年3月4日,采样周期为5 min,共计39 040条数据。由于一年中太阳日出日落的时间不同,所以每天采样的时间点也不同,加上采集器的数据丢失,每天的时间点在80~150不等。常规的神经网络对数据清洗要求很高,数据质量对实验结果的误差影响很大。本文对数据只进行了初步的筛选,数据空缺采用K邻补全法进行了填补,这是智能算法的优势之一。在大数据的支撑下,一方面缺失或者采集错误的数据占比非常小,另一方面算法本身对数据不好的特征项会相应的减少其影响因子。这些都使得LSTM对数据的依赖仅仅体现在数量上。
4.1 预测过程
本文对Cocoa地区某一光伏电站进行建模。首先,对光伏发电系统的发电原理进行研究,并对光伏发电输出功率的影响因素进行分析;其次,在综合考虑物理方法及统计方法的基础上,利用深度学习算法进行预测,取得最优功率预测模型;最后,对预测得到的数据与实测数据进行对比分析。模型计算流程图如图4所示。

图4 模型运算流程
(1) 首先研究光伏发电技术的原理,熟悉光伏发电系统的构成和运行方式。太阳辐照度、温度、风速、云团等相关天气条件是影响光伏发电的主要因素,通过分析光伏电站的历史发电数据及气象数据,最终确定影响输出功率的主要影响因素和次要影响因素。
(2) 39 000条数据中,取前35 000条作为训练集,后4 000条作为测试集。经预处理后,将水平面辐射和NWP气象数据(温度、湿度、气溶胶浓度和云量等相关天气条件)、发电站的逆变器、电池等硬件的数据信息(电池温度,伏安特性等)作为特征输入,并将光伏电站的历史实测发电量作为输出,代入LSTM深度神经网络中,对区域内光伏电站进行功率预测训练,建立相应的深度学习模型。
(3) 在建立深度学习模型后,选取测试集中某一天作为对照样本。假设这一天共采集了n条数据,那么需要向前一天借m条(m为训练集大小,即训练块大小)数据;以a+m条(其中0≤a≤n-1,a∈Z)为一个训练块,建立连续n个初始输入矩阵,具体为
对应输出矩阵为
模型内部运行流程如下。
每个LSTM包含了3个输入,即上一时刻的单元状态、上一时刻LSTM的输出和当前时刻输入。遗忘门用来计算哪些信息需要忘记,通过ReLu函数处理后变为0~∞的值,数值大小表示保留程度(0表示全部忘记),于是有
ft=σ(Wf·[ht-1,xt]+bf)
式中:ft——ReLu损失函数;
Wf,bf——遗忘门的偏置项。
若输入层维度、隐藏层维度、状态维度分别为dx,dh,dc,得到Wf=dc(dh+dx)。
输入门引入两部分新的信息到cell中,第一部分为需保存信息,即
it=σ(Wi·[ht-1,xt]+bi)
第二部分为产生的新信息,即
两部分信息的组合获得一个新记忆。当前状态由遗忘门输入、前一个cell状态及上输入门组成,公式为
输出门通过ReLu函数计算输出信息,再与当前单元状态值计算得到
ot=σ(Wo·[ht-1,xt]+bo)
ht=ottanh(ct)
4.2 超参数影响分析
隐藏层表示模型含有的LSTM层数。隐藏层数越多,函数能够更加准确拟合。但层数过多会造成训练量急速上升,影响训练速度。不同隐藏层层数训练效果对比如表1所示。经多次尝试,最优训练参数确定隐藏层层数为10时,此时均方根误差可以达到0.001级别,明显好于9层、11层一个数量级。

表1 不同隐藏层层数训练效果对比
训练块大小表示输入矩阵的大小。在神经网络训练过程中,合理范围内增大训练块大小,可以让内存利用更加有效。同时,跑完一次全数据集所需的迭代次数减少,这也意味着处理速度会得到有效的提升。训练块大小越大,下降方向可以更加容易地确定,训练震荡会稳定在合理范围内;但若盲目增大训练块大小,内存容量会被迅速占用,造成数据溢出,程序崩溃。不同训练块大小训练效果对比如表2所示。由表2可知,当训练块大小在50左右时,训练效果最好。

表2 不同训练块大小训练效果对比
步长表示每次训练移动的长度。步长移动距离越短,搜索过程中越不会错过最优解,但代价是花费大量时间,收敛缓慢,容易陷入局部最优。步长过长,每次偏移过大,会造成永远都找不到真正的最小值。对于深度越高的神经网络,“平滑区”会越来越多,局部最小点也会越来越多。没有合适的算法,很容易陷入某个局部最小值里去。不同步长训练效果对比如表3所示。由表3可以看出,步长持续增大,训练结果反而越差,这也意味着步长存在最适区间,超过或者低于这个区间,对训练结果都会有极大影响。

表3 不同步长训练效果对比
学习率表示模型的训练速度。不同的学习率,模型的效果相差甚远。一般而言,学习率可先从一个较大的值开始,如0.1,这样可以实现快速调试。学习率太大会造成损失爆炸,太小损失又会训练无反应,选择一个合适的学习率可以更快的让训练达到稳态。不同学习率训练效果对比如表4所示。通过表4可以发现,随着学习率的提高,预测精度也随之提高。
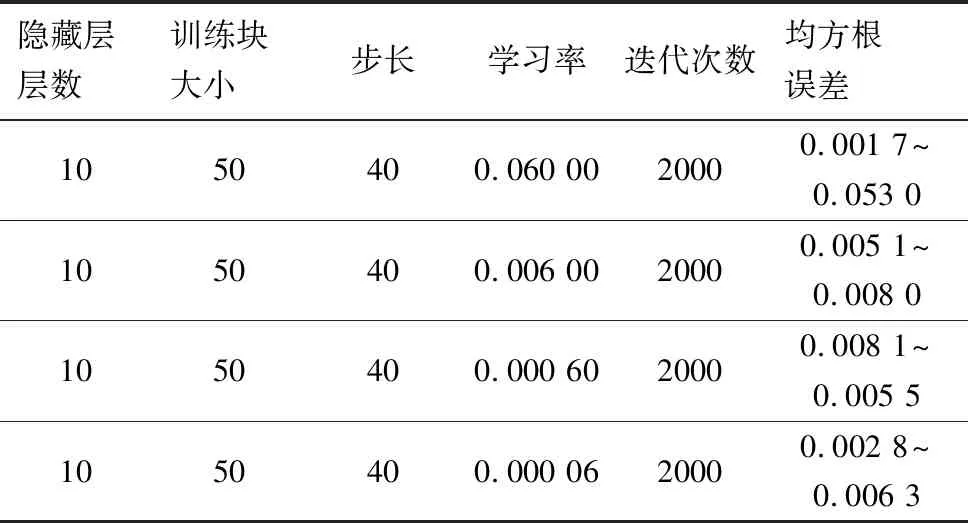
表4 不同学习率训练效果对比
不同学习率训练损失对比如图5所示。由图5可知,学习率太低,训练过程震荡明显。随着学习率的提高,训练损失趋于稳定,达到0.000 6时已符合训练目的。学习率为0.06时,两种天气训练输出与最优解如图6所示。

图5 训练损失对比
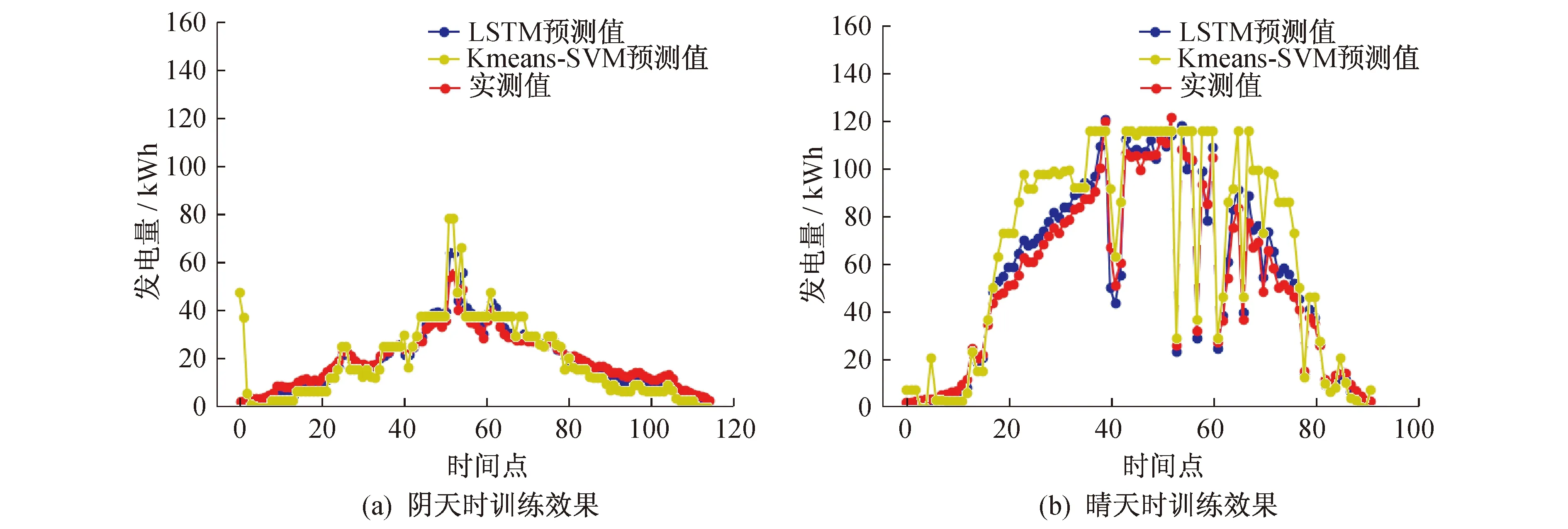
图6 训练效果对比
经过一系列对参数的调整发现,当训练块大小为50,隐藏层层数为10,步长为40,学习率为0.000 6,迭代次数为2 000次时,可获得相对最优预测模型。
4.3 对照算法
4.3.1 Kmeans-SVM对照算法
VAPNIK V N等人在1995年就提出了支持向量机(Support Vector Machine,SVM)算法,随后,VAPNIK V N将不敏感损失函数ε引入,使得算法扩展到解决非线性回归问题[16]。具体如下。
对于给定样本集dataset={(x1,y1)(x2,y2),…,(xn,yn)},xi∈Rd为输入值,yi∈R为目标值,i=1,2,3,…,n。其中Rd为d维的实数集。通过线性回归函数f(x)=wT+b来拟合样本(xi,yi),采用ε不敏感损失函数,可得
|y-f(x)|ε=

(8)

s.t.f(xi)-yi≤ε+ξi
(9)
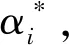
(10)
由于自身的局限性,仅利用SVM算法解决复杂的预测问题远远不够。为了提高预测算法的精度,本文采用Kmeans算法对输入特征量进行聚类。其目的就是寻找K个质心来最小化平方误差。将样本集划分成K个簇,簇的质心Ci的均值向量为
(11)
4.3.2 Kmeans-SVM模型结构
Kmeans-SVM 预测模型框架如图7所示。基于对光伏发电功率影响因素的分析,选出以下4个参数作为训练样本:光伏组件输出的直流电流I,直流电压U,组件温度T,发电功率P。

图7 KmeansSVM预测模型框架
该预测模型将当前时刻的I(t),U(t),T(t),P(t),t时刻上一时刻的I(t-1),U(t-1),T(t-1),P(t-1)作为训练集的输入特征,下一时刻的发电功率P(t+1)作为训练样本的目标,则当前时刻的训练样本可表示为[t,I(t),U(t),T(t),P(t)k,I(t-1),U(t-1),T(t-1),P(t-1),P(t+1)]。
该预测模型可表示为
P(t+1)=mod[t,I(t),U(t),T(t),P(t),
I(t-1),U(t-1),T(t-1),
P(t-1)]
(12)
以连续两个时刻的4个参数值作为样本特征,使用Kmeans算法把连续两个时刻光伏发电状态相近的样本归为一类,以时刻t为特征可使归为一类的样本尽量在相邻时段。该模型先基于Kmeans算法对样本集进行聚类分析,将样本集分成K个训练集(此处的K值通过经验法、试凑法确定),将与预测样本同类的训练样本输入SVM来预测下一时刻的发电功率。
4.3.3 Kmeans-SVM与LSTM模型对比
本文以美国佛罗里达州Cocoa地区某光伏电站实测数据为例,从历史数据样本中选取晴天(2011年7月5日)、雨天(2011年6月29日)两种典型天气类型作为训练测试集对Kmeans-SVM算法光伏发电功率预测模型进行训练,并将所得结果与LSTM算法模型预测得到的结果进行对比。图8展示了晴天与雨天两种情况下Kmeans-SVM预测值、LSTM算法预测值与实测值的对比曲线。尽管Kmeans-SVM算法经过了聚类处理,但结果表明LSTM算法模型的预测精度更为准确。
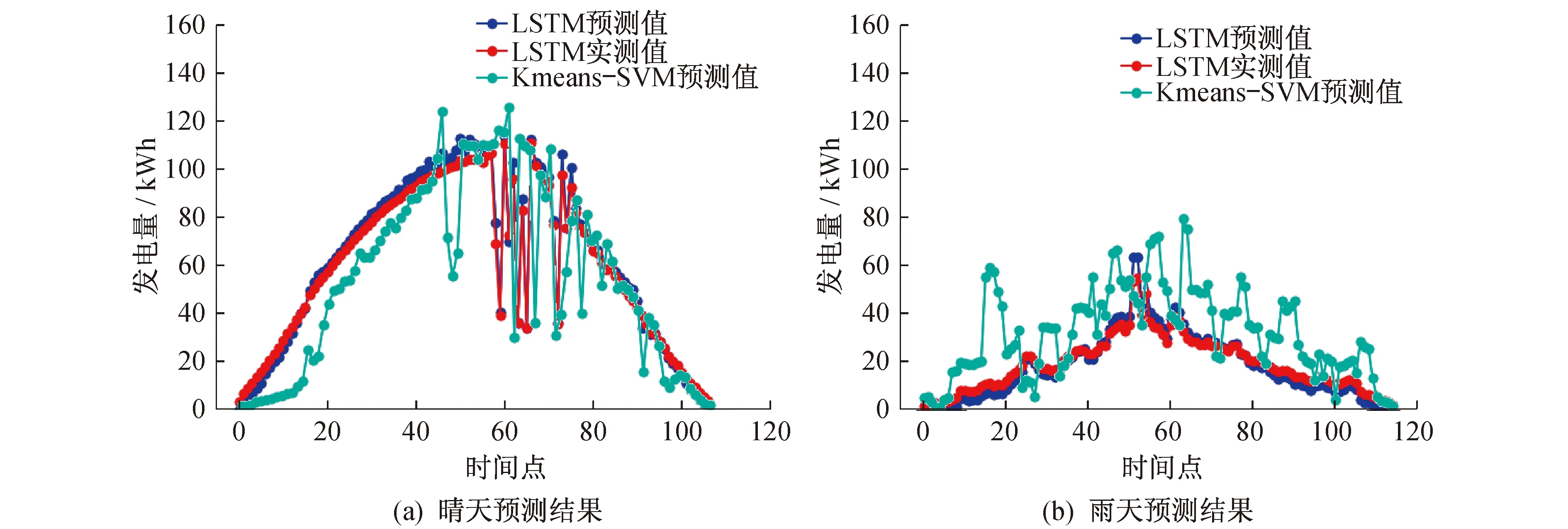
图8 两种天气预测结果对比
两种天气预测模型的误差统计结果如表5所示。由表5可知,Kmeans-SVM算法相较于LSTM算法预测模型两种天气预测误差分别提高了22倍和18倍。由此可见,即使拥有K-means算法的数据分类能力以及SVM算法的泛化能力,Kmeans-SVM光伏功率预测模型与LSTM模型相比,仍然有着巨大差距。Kmeans-SVM无需考虑数据的天气类别的情况,即可对训练样本进行聚类分析,但LSTM却拥有无需进行数据分类的处理方式。

表5 两种天气预测模型的误差统计
5 结 语
本文从光伏预测物理原理出发,分析了影响光伏预测的主要因素;在对时间序列数据进行分析后,基于LSTM的工作原理,证明LSTM神经网络对负荷预测的适用性;然后进行输入输出维度的选择,建立了基于LSTM的负荷预测模型。最后与Kmeans-SVM算法进行比较发现,LSTM模型直接省去前期复杂的数据筛选预处理过程,使得模型的局限性得到了极大的改善,证明了基于深度学习的LSTM神经网络的负荷预测模型具有更高的精确度和更好的适用性。
猜你喜欢
环球人物(2022年4期)2022-02-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
中学生数理化·高一版(2021年2期)2021-03-19
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
重型机械(2016年1期)2016-03-01
中国老区建设(2016年1期)2016-02-28
海军航空大学学报(2015年4期)2015-02-27
