
EMD-LSSVM模型预测高炉煤气产生量
2020-01-07 02:45李志刚
网络安全技术与应用 2020年1期
◆张 鑫 李志刚
EMD-LSSVM模型预测高炉煤气产生量
◆张 鑫1李志刚2
(1.华北理工大学电气工程学院 河北 063210;2.华北理工大学信息工程学院 河北 063210)
钢铁企业实际生产中产生海量数据,在数据中隐藏着潜在的规律,针对高炉煤气产生量波动频繁,传统的预测算法精度低误差大的问题,本文通过对数据进行经验模态分解,建立一种EMD和LSSVM相结合的预测模型。首先将原始数据运用EMD方法分解成多个IMF分量和Res分量,对每个分量单独建立LSSVM预测模型,最后将各个分量的预测结果进行叠加重构得到最终的预测结果。本文所提出的方法,对某钢铁企业的实际生产中数据进行预测实验,结果表明,EMD-LSSVM算法确实可以提高预测的精度。
高炉煤气预测;SVM;LSSVM;EMD;灰色关联度;BP网络
1 引言
高炉煤气(BFG)不仅仅是在炼铁过程中重要的副产物而且也是重要的二次能源,其回收利用率影响着生产的成本和环境污染程度,对企业有着重要的经济和环保意义[1]。生产中的煤气过剩或者煤气紧缺现象很容易导致设备熄火进而影响用户生产。煤气产生量大于煤气调度量会导致BFG放散到大气中,势必对环境造成污染[2]。因此在钢铁生产过程中,为了配合各个环节对高炉煤气的需求,要实时把握高炉煤气的发生量和趋势。炼铁的过程发生着复杂的化学反应,因而影响高炉煤气发生量的因素复杂,其中掺杂着周期波动和随机扰动和噪声,实际采集到的高炉煤气数据具有非线性的特点往往难以准确预测[3]。
相关学者对BFG产生量的预测进行了大量的研究。刘颖等人为改进传统的EMD存在只能靠经验方法确定结构的缺陷,提出了改进的高斯过程回声网络[4]。张琦等人通过加入灰色关联度分析从而提高了BP网络的预测精度[5]。孙雪莹提出了一种自适应遗忘因子的极限学习机[6]。
本文根据高炉煤气发生量的非线性特点,采用LSSVM非线性预测模型。为了达到提高预测精度从而减小误差的目的,为此本文采取EMD和LSSVM相结合的方法。
2 相关理论
2.1 最小支持向量机
SVM在处理小样本问题时具有优良的估计能力,但是对过拟合问题不敏感。Suykens等对SVM进行改进,提出了最小二成支持向量机(LSSVM)[7]。由于SVM中的损失函数不敏感,LSSSVM在其基础上采用误差的二次平方项将其代替,约束条件也由不等式变成等式,把原本的二次规划问题巧妙的转化为求解线性方程组,求解速度和收敛精度从而得到提高,在函数逼近和分类等领域得到应用[8-9]。LSSVM原理如下:

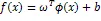
根据结构风险最小化理论,此线性回归问题可表示为一个等式约束问题。LSSVM目标函数为:


通过拉格朗日乘子法得到如下拉格朗日函数:
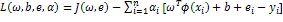
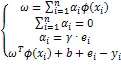
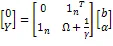
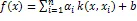
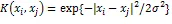
2.2 经验模态分解
经验模态分解(EMD)是1998年由黄锷等人提出的一种针对非线性、非平稳信号的分解算法,将信号分解成不同频率的IMF分量和剩余分量,IMF需要满足的两个条件:(1)在整个数据序列中,极值点的数量(包括极大值点和极小值点)与零点的数量必须相等,或是最多相差不过1个。(2)在任一时间点上,信号局部极大值确定的上包络线和局部极小值确定的下包络线的均值为零。其算法步骤如下:
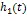
最终信号成为个基本模式分量和余量的和:
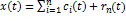
因为每个IMF分量代表一个特征尺度的数据序列,实际上是将分解为各种不同特征波动序列的叠加过程[10]。
2.3 EMD-LSSVM组合模型
EMD作为一种处理信号的方法,它不需要先选择基函数,能够根据信号的特点生成合适的表示函数,从而很好地表示信号的局部特征;LSSVM能够找到模型复杂性和学习能力的最佳折中,具有全局唯一最优解,泛化能力强。结合这两个方法的特点,首先找出对高炉煤气产生量关系大的因素,然后运用EMD将原始数据序列分解成若干相对平稳的IMF分量和残余分量Res,将信号中存在的不同尺度波动或趋势逐级分解出来。针对各IMF分量分别建立LSSVM预测模型进行预测,最后将每个LSSVM模型的预测结果进行叠加,从而得到最终的高炉煤气发生量,流程如图1。
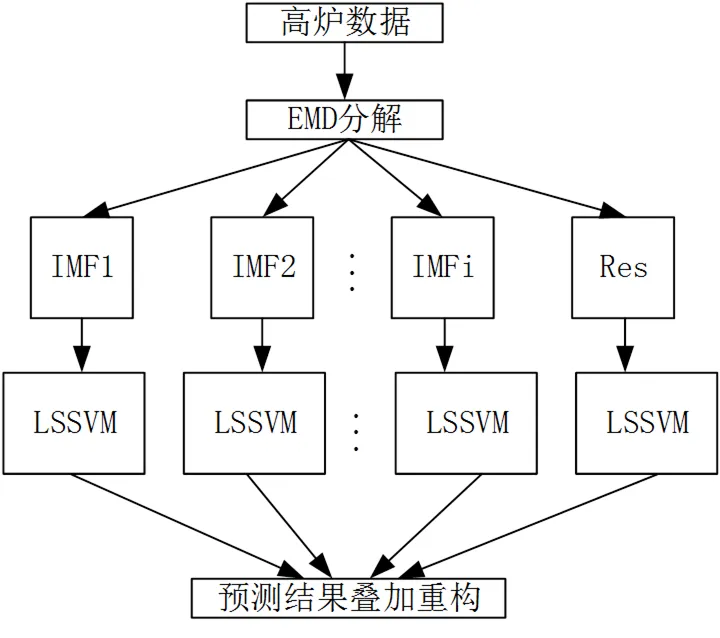
图1 EMD-LSSVM预测模型
3 算例分析
以唐山某钢铁企业为例,使用2017年7月至10月的高炉生产中每2s采集一次而形成的数据集。
3.1 数据预处理
(1)异常数据处理
来自实际生产的数据,往往存在噪声高的现象,为了降低噪声的影响,找到并剔除数据中的异常值,本文采用箱线图分析的方法,而对于缺失的数据采用插值法来进行填补。
(2)数据归一化
不同类型数据的数据区间差异过大会严重影响到不同数据间的关联性度,为消除这方面干扰,同时提高计算的速度和预测精度,本文采用Min-Max标准化方法将采集到的所有数据都约束在区间[0,1]之中。

(3)训练集和测试集划分
在采集到的四个月数据中,将每月的前20天作为训练集,后10天的数据作为测试集。
3.2 特征提取
由于生产过程复杂,BFG产生量受很多因素影响,为了提高计算的速度和预测准确性,需要从采集到的多种数据中,找到最主要的影响因素。我们通过计算各个因素对高炉煤气产生量的灰色关联度,选取相关度高的影响因素进行下一步分析。本实验选取关联度大于0.6的影响因素作为预测的特征项,见表1。
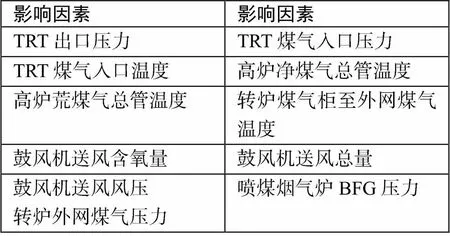
表1 高炉煤气产生量的相关影响因素
3.3 EMD分解
高炉煤气产生量非线性的特点,属于非平稳信号,采用EMD对其进行分解,将Res分量不满足IMF条件作为停止标准,得五个IMF分量和一个Res分量,如图2。
图2反映出了原始数据的周期性、随机性和趋势性,更好的观察出原始数据的特征。可以看出高炉煤气发生量数据IMF分量的波动性逐渐降低,代表了影响因素对高炉煤气发生量的周期变化和波动的影响,残差量表示了高炉煤气发生量在时间尺度上的变化趋势。IMF1和IMF2频率高,随机无序性更高,能看出外部的随机扰动对高炉煤气发生量影响较大。IMF3和IMF4显示出波动周期明显,比IMF1和IMF2平稳,但是波动周期性依然不够稳定。本文通过将高炉煤气数据进行EMD分解,通过各分量的特点,可以反映出数据的隐含变化信息和一些局部特点。
3.4 模型训练
将原始数据进行预处理后,用搭建好的模型进行训练,训练流程如图1所示,将高炉煤气发生量EMD分解后得到的IMF和Res分量分别进行LSSVM模型训练,模型的核函数选择径向基核函数,输入变量为通过灰色关联度分析得到的10个高炉煤气主要的影响因素,输出变量为1个,通过此方法得到的LSSVM模型对测试集进行预测,将对IMF分量和Res分量的预测结果进行叠加得到最终想要预测结果。
3.5 试验评价指标
本文选用均方根误差这种常用的预测模型评估指标对模型进行评估。公式如下:

3.6 实验结果分析
为了验证EMD-LSSVM的预测效果有更高的准确性,将其与LSSVM和BP网络预测的结果分别与真实结果进行比较,对比结果如图3。BP网络具有任意精度逼近复杂模型的能力,但学习速度慢,容易陷入局部极小值。通过图3中各个模型的预测结果和真实结果对比曲线可以直观地看出,BP网络预测效果不理想。LSSVM模型在波动较大的拐点处有严重的偏差。
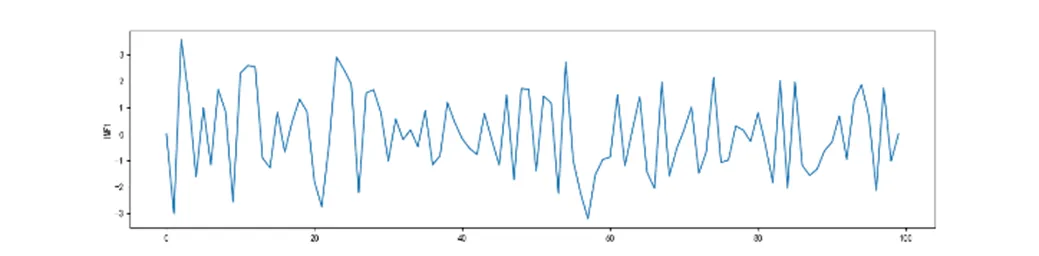
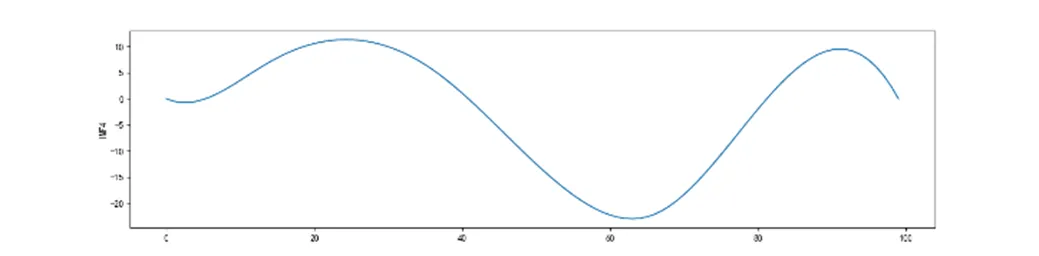

图3 预测值和实际值对比
选择的性能指标为均方根误差,计算三个模型的均方根误差,由表2可知,EMD-LSSVM模型得到的均方根误差为2.475;而单独使用LSSVM模型和BP网络模型得到的均方根误差分别为3.948和5.077,可以清楚看到LSSVM模型比BP模型有更好的效果,预测结果更接近真实值。LSSVM和EMD相结合比LSSVM模型的预测结果更进一步提高预测精度,预测的时间序列趋势也和实际吻合度高,可以看出通将数据进行EMD分解后确实可以提高LSSVM模型的性能。

表2 各模型均方根误差对比
4 结论
针对传统高炉煤气发生量预测精度低和预测误差较大的问题,使用了一种EMD-LSSVM组合预测模型。对采集到的工厂数据进行经验模态分解(EMD)方法,将原始数据分解成多个IMF分量和一个Res分量,用LSSVM方法对这些分量分别进行建模进行预测,再将各自的预测结果进行叠加,得到最终的预测结果。通过实验验证,EMD-LSSVM组合模型确实可以提高预测的精度,有比传统方法更好的效果,为高炉煤气发生量的预测提供了一个新方法和思路。
[1]张琦,李鸿亮,赵晓宇,贾辉.高炉煤气产生量与消耗量动态预测模型及应用[J].哈尔滨工业大学学报,2016,48(01):101-106.
[2]孟繁滨.钢厂高炉煤气受入量预测方法的研究[D].大连理工大学,2012.
[3]李红娟,王建军,王华,孟华.建立PNN-HP-ENN-LSSVM模型预测钢铁企业高炉煤气发生量[J].过程工程学报,2013,13(03):451-457.
[4]刘颖,赵珺,王伟,吴毅平,陈伟昌.基于数据的改进回声状态网络在高炉煤气发生量预测中的应用[J].自动化学报,2009,35(06):731-738.
[5]张琦,谷延良,提威,蔡九菊.钢铁企业高炉煤气供需预测模型及应用[J].东北大学学报(自然科学版),2010,31(12):1737-1740.
[6]孙雪莹,胡静涛,王卓,张吉龙.基于自适应遗忘因子极限学习机的高炉煤气预测[J].计算机测量与控制,2017,25(07):235-238.
[7]SUYKENS J A,VANDEWALLE J.Least squares support vector machine classifiers[J].Neural Processing Letters,1999,9(3):293-300.
[8]张永康,李春祥,郑晓芬,徐化喜.基于混合人工蜂群和人工鱼群优化的LSSVM脉动风速预测[J].振动与冲击,2017,36(15):203-209.
[9]顾清华,李梦然,闫宝霞.基于DE-BA-LSSVM的露天矿边坡稳定性预测[J].矿业研究与开发,2018,38(08):1-5.
[10]王妍鹏.基于数据的高炉煤气受入量的预测[D].天津工业大学,2017.
河北省自然科学基金资助项目(F2016209165)。
猜你喜欢
新疆钢铁(2021年1期)2021-10-14
红蜻蜓·中年级(2021年2期)2021-09-10
昆钢科技(2021年3期)2021-08-23
昆钢科技(2021年3期)2021-08-23
昆钢科技(2021年1期)2021-04-13
读者·校园版(2020年19期)2020-09-16
当代陕西(2019年19期)2019-11-23
当代工人(2019年18期)2019-11-11
智族GQ(2019年9期)2019-10-28
英美文学研究论丛(2018年1期)2018-08-16
