
使用Python分析网站招聘信息
2020-01-08 02:22申丽平
现代信息科技 2020年15期
关键词:爬虫

摘 要:Python语言使用起来灵活方便,很适合爬取网络数据并进行清洗及可视化。文章设计了一个Python爬虫程序,先获取到岳阳人才信息网的所有公开招聘信息,然后将信息保存到MongoDB数据库,再从数据库导出至Excel文件,再对Excel的数据使用正规表达式进行清选,最后使用Matplotlib模块以图像形式展现统计结果。数据统计基于薪酬、工作地点及学历要求等三个维度,可以帮助求职者对于该网站招聘信息的价值做一个粗略的估计。
关键词:Python;mongoDB;Excel;招聘信息;爬虫
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2020)15-0018-03
Abstract:Python language is flexible and convenient to use,which is very suitable for crawling network data and cleaning and visualization. This paper designs a Python crawler program,which first obtains all the open recruitment information of Yueyang talent information website,then the information is saved to mongoDB database,and then exported to Excel file from the database. The program uses the regular expression to clear the Excel data,and finally uses Matplotlib module to show the statistical results in the form of images. Data statistics are based on salary,workplace and education requirements,which can help job seekers to make a rough estimate of the value of the websites recruitment information.
Keywords:Python;mongoDB;Excel;recruitment information;crawler
0 引 言
使用Python語言编写程序,几行代码就可以把初步结构化的数据入库,而Java实现网络爬虫的代码要比Python多很多,而且实现要复杂得多;Python语言生态环境的Urllib、Requests、Beautifulsoup等模块可以轻松地构建一个基本的数据采集程序,而Java语言的爬虫库资源就要少得多[1]。关于Python语言的特点、网络爬虫的定义以及工作流程等等,张艳等人作出了清晰明白的解释[2]。基于多年的学习与工作经验,作者总结了多种数据爬取途径:对静态网页使用Request模块,对动态网页采用Selenium模块;简单的数据爬取使用Python无框架代码,复杂或大型的数据爬取使用Scrapy技术框架。该文结合Requests模块采用Python无框架代码制作了一个针对岳阳人才信息网(http://www.yyrcxx.com)的爬虫程序。
1 数据爬取设计
爬虫总体的设计如图1所示。首先在浏览器中打开岳阳人才信息网,查看源代码,分析其页面结构;然后编写Python无框架爬虫代码,下载其网页数据;再是对数据进行清洗,提取出有用的部分存储到MongoDB数据库;接着从数据库中的集合导出数据至Excel文档,对此文档的数据进行必要的整理;最后使用Jupyter Notebook编写代码调取Excel文档数据,实现读取、写入Excel以及清洗、统计与图表可视化操作。
1.1 页面跳转分析
Google公司的Chrome浏览器速度慢、界面简单,建立书签文件夹很方便,很多程序员都喜欢使用。在浏览器地址栏输入www.yyrcxx.com然后回车,即可打开岳阳人才信息网主页,在页面顶部导航栏点击“搜职位”,页面跳转到http://www.yyrcxx.com/jobs/,在打开的“职位”显示页面中部点击“搜索”按钮跳转到新的页面,这个新的页面底部包含有“首页”“上一页”“1”“2”“3”……“下一页”“尾页”等页面跳转按钮,其在地址栏显示的地址信息为http://www.xbhrw.com/jobs/jobs-list.php?key=&jobcategory=&trade=&citycategory=&wage=&jobtag=&education=&experience=&settr=&nature=&scale=&sort=&page=1,可以发现只有page项有非空值,其他参数的值都为空,即网址的参数中只有page参数有用。据此,可以把网址信息简化为http://www.xbhrw.com/jobs/jobs-list.php?page=1,使用简化后的网址输入到地址栏并按下回车键,发现页面正常打开。令page=2,发现第2页处于被选中状态,于是,得到页面跳转的规律:通过让page的数值每次加1,即可自动获取下一个页面的数据。由于岳阳人才信息网所列出的招聘信息并不多,截止作者抓取数据时只有29页,这里不用设置任何筛选条件,可直接获取网站的所有招聘信息。
1.2 数据存取设计
招聘数据整齐而有规律,这里采用非关系型数据库MongoDB来存储数据。首先,从MongoDB官网下载安装文件,将之安装到D盘(OS:Windows 7),使用命令在MongoDB命令行中新建数据库jobs,并在jobs数据库中新建数据表yyrcxx(在MongoDB中被称为集合yyrcxx),在爬虫下载器程序中使用语句client = pymongo.MongoClient('localhost', 27017)建立一个连接client,在程序中使用client[‘jobs]获取jobs数据库,使用client[‘jobs][‘yyrcxx]获取yyrcxx集合(即关系型数据库中的数据表)。
1.3 伪装浏览器
HTTP协议是请求/响应模式,浏览器的Request Headers有一个重要的属性就是User-Agent,在设计爬虫程序时一定要设置User-Agent。在Chrome浏览器的地址栏输入chrome: //version然后回车,在打开的页面中找到“用户代理”行,复制后面的User-Agent值。
1.4 页面数据提取
使用Python 3进行网络数据采集时,基于连接的稳定性考虑,一般不使用较为老旧的urllib.request模块,而是使用更为方便的Requests模块[3]。
这里,爬取岳阳人才网数据时,使用for n in range(1, 30)控制页面的跳转,range()函数的参数是左闭右开区间,这里的30不被包含,所以共有29页。页面定位使用语句baseUrl = 'http://www.yyrcxx.com/jobs/jobs-list.php?page=' + str(n);获取页面使用语句strhtml = requests.get(url, headers=headers),其中headers是一个字典,里面仅设置了属性User-Agent。对获取的页面数据strhtml,使用BeautifulSoup进行解析,采用lxml选项分析页面结构,对应代码:soup = BeautifulSoup(strhtml.text, 'lxml'),然后使用soup对象的select()方法和find()方法进一步定位具体元素。比如语句company = item.find('div').find('div', class_='list-item item2 f-left').find('a').get_text(),表示在item页面元素下面尋找第一个div标记元素,再在这第一个div标记元素下找到一个div标记元素,其class属性的值至少包含有list-item、item2、f-left这三个值,再到当前div元素的下面寻找第一个a标记元素,然后取得这个a标记元素的文本。
1.5 实验过程
硬件配置:CPU为Intel Core i5-4200M@2.50 GHz,Memory 12 GB。软件配置:Windows 7 64 Bit,Anaconda 3下的Python 3.6.6,MongoDB shell version v4.0.13,PyCharm 2018.1。实验步骤:第1步,进入MongoDB的安装位置MongoDB文件夹,运行bin\mongod --dbpath data,其中data是程序员在MongoDB文件夹新建的用于保存数据的子文件夹;第2步,打开PyCharm,安装MongoDB插件,在PyCharm的Mongo Explorer点击“Connect to this server”按钮,连接MongoDB数据库;第3步,运行爬虫主程序,下载网页数据并存储到MongoDB数据库;第4步,编写Python文件从MongoDB导出数据表内容到CSV文本文件;第5步,使用Windows系统自带的记事本打开导出的CSV文件,并另存为ANSI编码格式的同名文件;第6步,编写Python代码从CSV文件加载数据并导出Excel文件。
2 数据统计
此次实验抓取了岳阳人才信息网自2018年4月4日至2020年6月15日14时的在线可见数据(经分析,该网站不定期会删减一些数据),共计569条岗位招聘需求信息。根据求职者的主要参考项目如薪酬、工作地、学历要求等,使用Python的可视化技术做成饼图。为了方便代码输出,数据统计及可视化操作皆通过启动Jupyter Notebook命令在浏览器(实验采用Google Chrome 78.0.3904.108 64位版本)中查看。通过引入matplotlib.pyplot模块实现数据的可视化,对于饼图中的汉字,使用matplotlib.rcParams['font.sans-serif']=['SimHei']解决汉字乱码现象。
2.1 薪酬数据统计及可视化
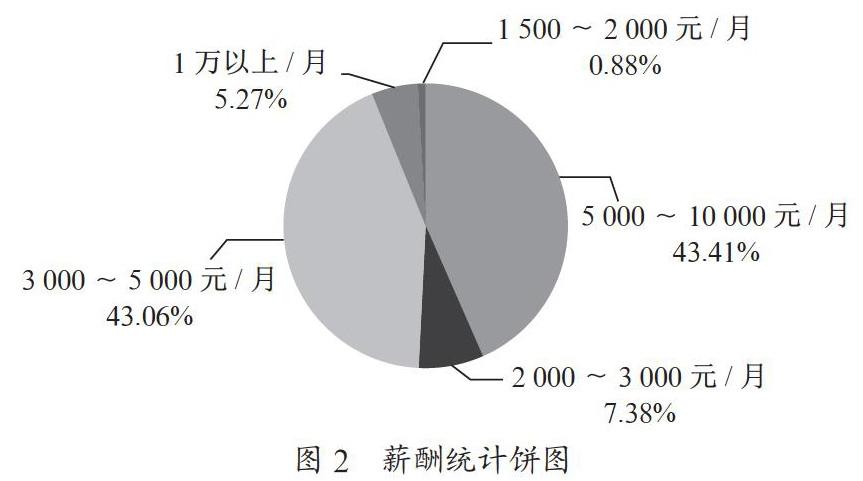
xlrd模块用于Excel文件的读取,将之前从MongoDB中导出到Excel的文件,再次加载到Python中,通过from collections import Counter引入Counter计数模块,再使用counts = (dict)(Counter(pay))把pay列表先转为Counter对象,再变为字典对象,最终得到字典数据{'5000~10000元/月': 247, '2000~3000元/月': 42, '3000~5000元/月': 245, '1万以上/月': 30, '1500~2000元/月': 5},合计569条数据,如图2所示。
'1500~2000元/月'占比0.88%,'2000~3000元/月'占比7.38%,'3000~5000元/月'占比43.06%,'5000~10000元/月'占比43.41%, '1万以上/月'占比5.27%。数据表明,5000元以上月工资占比48.68%,3 000元以上的月工资合计占比91.74%,3 000元以下的月工资则只有8.26%。
2.2 工作地点统计
工作地点的统计方式与薪酬数据统计相同,最终获得字典数据:{'岳阳市': 33, '经济技术开发区': 9, '岳阳市/经济技术开发区': 33, '湖南省/岳阳楼区': 1, '岳阳市/岳阳楼区': 88, '岳阳楼区': 25, '湖南省/岳阳市': 112, '岳阳市/南湖新区': 10, '岳阳市/平江县': 2, '岳阳市/华容县': 4, '岳阳市/岳阳县': 2, '岳阳市/君山区': 2, '岳阳市/云溪区': 14, '岳阳市/临湘市': 4, '岳阳市/城陵矶新港区': 32, '岳阳市/汨罗市': 19, '临湘市': 2, '汨罗市': 8, '湖南省/长沙市': 24, '湖南省': 133, '天津市/塘沽区': 1, '湖北省/咸宁市': 1, '福建省/厦门市': 1, '四川省': 1, '云南省': 1, '黑龙江省/绥化市': 1, '河南省': 1, '福建省/泉州市': 1, '湖北省/武汉市': 2, '广东省/深圳市': 2}。
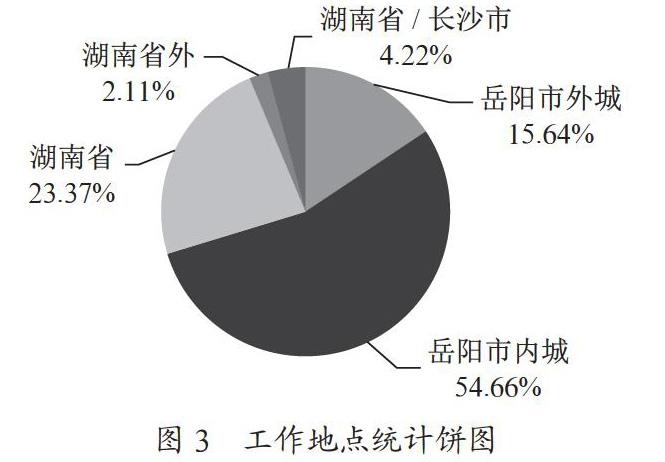
在此字典基础上根据距离远近进一步归纳,将其合并为5类:{'岳阳市外城': 89, '岳阳市内城': 311, '湖南省': 133, '湖南省外': 12, '湖南省/长沙市': 24},其中'岳阳市内城'包括:{'经济技术开发区', '湖南省/岳阳市', '岳阳市', '岳阳市/岳阳楼区', '岳阳市/经济技术开发区', '岳阳市/南湖新区', '岳阳楼区', '湖南省/岳阳楼区'},'岳阳市外城'包括:{'岳阳市/临湘市', '临湘市', '岳阳市/君山区', '岳阳市/云溪区', '岳阳市/汨罗市', '汨罗市', '岳阳市/岳陽县', '岳阳市/平江县', '岳阳市/华容县', '岳阳市/城陵矶新港区'}。根据该数据绘制的饼图如图3所示。
'岳阳市内城'311个地点计数,占569个地点总数的比例为54.66%;'岳阳市外城'89个地点计数,占比15.64%。岳阳地区合计400个地点计数,共占比例为70.30%;'湖南省/长沙市'24个地点计数,占比4.22%;'湖南省'133个地点计数,占比23.37%。湖南省内合计557个地点计数,共占比例为97.89%;湖南省外,列表['天津市/塘沽区': 1, '湖北省/咸宁市': 1, '福建省/厦门市': 1, '四川省': 1, '云南省': 1, '黑龙江省/绥化市': 1, '河南省': 1, '福建省/泉州市': 1, '湖北省/武汉市': 2, '广东省/深圳市': 2],合计12个地点计数,占比2.11%。
2.3 学历要求统计
通过import re导入正则表达式,设置pattern = r'.*招聘人数:(.+)人.*' 清洗Excel文件eduRequ字段中“招聘人数:1人”字样文本内容,设置patt_edu = r'^学历要求:(.{2,5})\?\?\|\?\?'清洗eduRequ字段中“学历要求:大专??|??工作经验:3-5年”字样文本内容。最终得到edu_dict字典对象{'初中': 2690, '高中': 417, '中技/中专': 266, '中专': 132, '中技': 54, '大专': 515, '本科': 195, '硕士': 2},共计4 271个工作岗位。合并中技、中专学历为1个类别,得到饼图如图4所示。
计算可知,招聘学历要求中,初中文化占比62.98%;高中文化占比9.76%;列表['中技/中专': 266, '中专': 132, '中技': 54]合计452人,占比10.58%;大专文化占比12.06%;本科文化占比4.57%;硕士文化占比0.05%。可以看出,初等教育水平(仅包含初中)占比62.98%,大约2/3;中等教育水平(高中、中技及中专)占比20.34%,大约1/5;高等教育水平(大专、本科、硕士)占比16.68%,大约1/6。数据表明,岳阳人才信息网所发布的公开招聘信息对于学历的要求总体不高。
2.4 各学历平均工资
引入xlwt模块,可实现Excel文件的写入功能。在Excel中,首先将'3000~5000元/月'设为3 000,其他薪酬类似处理,将文字转为数字,得到工资字典:{'硕士': 10000, '本科': 4851, '大专 ': 4166, '中专/中技': 5459, '高中': 3654, '初中': 3904}。将每类学历的人数与薪酬相乘,累加后再求平均。最后综合各种可能性,可以单纯地就某一个方面进行预测(数学期望)。将各种学历的平均工资乘以其出现的比例(概率),可以给出任意一个求职者的薪酬估计:10 000×0.05% +4 851×4.57%+4 166×12.06%+5 459×10.58%+3 654×9.76%+3 904×62.98%=4 122.04(元)。
数据表明,中专/中技学历者5 459元的工资高于大专学历者4 166元的工资,初中学历者3 904元的工资高于高中学历者3 654元的工资。因此,该人才招聘市场劳动力供求方面,对中专、中技与初中学历者需求旺盛,从而佐证该地区劳动密集型、低端加工及商贸服务企业较多。
3 结 论
作者通过对岳阳人才网的招聘信息实施爬取实验,得到了薪酬、工作地点及学历这3个维度的分类统计数据,并区分各种学历计算出其平均工资以及该网站所有招聘岗位的薪酬期望。下一步可以开展的工作:一是选取更多维度对招聘信息进行统计分析;二是建立数学模型,使用人工神经网络的方法对该网站招聘信息进行统计分析和结果预测。
参考文献:
[1] 鸽子.为什么用Python实现网络爬虫而不用java [EB/OL].(2020-06-21).https://www.yisu.com/zixun/145468.html.
[2] 张艳,吴玉全.基于Python的网络数据爬虫程序设计 [J].电脑编程技巧与维护,2020(4):26-27.
[3] 黑羊的皇冠.Python爬虫基础之urllib与requests [EB/OL].(2018-03-09).https://www.jianshu.com/p/1efa672156d3.
作者简介:申丽平(1982—),男,汉族,湖南邵东人,讲师,硕士,主要研究方向:数据科学。
猜你喜欢
现代信息科技(2021年21期)2021-05-07
计算机与网络(2020年11期)2020-07-29
智能计算机与应用(2018年5期)2018-10-20
电脑知识与技术·经验技巧(2018年1期)2018-05-30
