
一种灵活的精度可控的可搜索对称加密方案
2020-01-09 03:39李西明陶汝裕黄欣沂
计算机研究与发展 2020年1期
李西明 陶汝裕 粟 晨 黄 琼 黄欣沂
1(华南农业大学数学与信息学院 广州 510642)2(福建师范大学数学与信息学院 福州 350117)
随着云计算的快速发展,数据外包在数据存储市场的应用也越来越广泛.通常情况下,用户会选择将数据外包给云服务器存储,同时又不公开数据.为了保护数据和隐私,数据拥有者会先选择加密数据,然后将加密数据上传到云端.然而当用户搜索关键词获得了一系列包含关键词的文档都太大时并且用户只想查询这些文档中的一部分内容时,检索就显得十分麻烦,例如在线DNA测序等.最简单的解决方法是将所有加密文档下载到客户端解密并检索.但是,这不仅会造成巨大的网络开销,还会带来不必要的计算成本.如果服务器不可信,那么用户数据的安全性就很难得到保护.因此,可搜索的对称加密方案(searchable symmetric encryption, SSE)迅速成为研究者们研究的热点.
关键词搜索技术通常分为精确关键词搜索和模糊关键词搜索.但是目前精确关键词搜索存在很大的问题.当用户描述不准确或输入错误时,精确关键词搜索可能无法找到用户真正需要的文件.因为模糊搜索技术的引入可以灵活地找到与用户输入的搜索词相关的文件,所以模糊关键词搜索技术迅速发展了起来.但是由于数据是以密文形式存储的,因此明文中使用的模糊搜索方法不能直接应用于密文搜索.从而模糊可搜索的加密机制是研究者重点研究的方向之一.
1 相关工作
近年来,研究人员针对不同的问题提出了许多可搜索的对称加密方案(SSE).Popa等人[1]在2011年SOSP会议上首次提出CryptDB,它可以在加密文本上执行搜索操作,如MySQL中的LIKE等操作,并且提供了很好的安全性保证.陈萍等人[2]首次提出了可以在密文上执行所有SQL语句的CryptDB系统.CryptDB是以第三方中间代理人的形式来对数据库提供安全高效的加密和解密方案.其主要核心分为3个模块:加密策略、洋葱加密模型和密钥链管理模块.但CryptDB存在着一些明显的缺陷,例如,当前的同态加密只支持整数型运算不支持浮点型运算、不能做到对原始数据库不作任何修改.在文献[3]中汪海伟等人提出一个可搜索数据库加密系统,解决了传统的加密数据库无法在保证数据安全性的同时实现执行复杂的SQL语句并解决了文献[1]中的缺陷.Cash等人提出了一种针对不同数据库规模的安全有效的数据处理方案[4],特别是对于大型数据库,它可以高效并秘密地搜索具有数百亿记录-关键词对的加密的服务器数据库.文献[4]的基本构造方案支持单个关键词搜索,并提供渐近优化的服务器索引大小、完全并行的搜索和最小的泄露,同时其所有方案和优化都被证明是安全的,并且泄露给不可信服务器的信息被精确地量化.
一方面可搜索加密方案[1-4]侧重于解决密文数据库存储以及查询的问题.另一方面在密文文本中搜索实现文本文件的可搜索加密技术也是当下研究的热点.当服务器返回许多文档到本地时,用户无法将每个匹配了关键词的文档都下载到客户端以确定哪些文档是需要的,尤其是查询结果中存在许多大型文档时.这个问题是通常的SSE所不能解决的.此时子串可搜索对称加密成为必要手段.在文献[5]中Faber为了支持子串查询需要构建重叠k-gram的索引,但是这个方案需要大量的存储开销来存储所有的k-gram,这显然是不现实的.Chase等人在文献[6]中使用后缀树来构建搜索框架.相比之下,后缀树的数据结构没有固定的大小,最多达2n个节点,每个节点存储其边、父节点和子节点的信息,从而增加了存储需求.
传统的精确关键词加密搜索是不能容忍任何的拼写错误,否则将返回错误的结果,这显然不能满足用户的需求.Hu等人通过使用通配符来构建模糊关键词集的方法来实现加密搜索[7].Zhou等人使用了编辑距离(edit distance)来设计加密搜索方案[8],通过保存与关键词在一定编辑距离内的所有单词来缓解这种情况.虽然Zhou等人的这种方法可以实现对关键词的模糊搜索,但是需要的存储开销较大并且最终得到的搜索结果中存在大量的弱相关性文档从而导致计算开销和网络开销的增加.Zhang等人提出一种高效的模糊关键词集构建方法[9],它是基于gram来构建模糊关键词集,达到了较好的效果.
本文提出了一种基于Leontiadis等人[10]的灵活精度可控的可搜索对称加密方案(flexible accuracy-controllable searchable symmetric encryption, FASSE),FASSE方案支持灵活精度可控的加密搜索并且节省了大量的存储开销.FASSE考虑使用Leontiadis的方案为底层框架主要是因为其基于后缀数组的索引设计,其所允许的最佳存储成本是O(n),且在大小为n的字符串中具有小的隐藏因子.
相比许多基于关键词集查询的SSE方案,本文方案在4个方面有提高:
1) FASSE方案允许动态发出可变大小的子字符串查询,而无需事先定义固定的查询大小.
2) FASSE方案通过搜索加密的文档摘要的FM索引(abstract FM index),即AFM索引,解决了传统的基于关键词集查询的SSE方案中可能会由于关键词集创建的不友好从而导致没有在关键词集中查到任何记录的问题;FM索引的结构和使用详见第2节.
3) FASSE方案通过一次命中搜索、增强搜索和过滤搜索这3种搜索方法解决了在基于关键词集合查询的SSE中用户得到许多低相关性文档的问题.
4) 为了提升搜索的实用性,FASSE方案通过调节在模糊搜索中的一些参数实现了灵活搜索精度可控的模糊增强搜索.
2 预备知识
2.1 BWT数据转换算法
Burrows Wheeler Transform(BWT)转换[11]将原始文本数据转换为一个相似的文本,转换后使得相同的字符位置连续或者相邻,经过BWT操作之后的文本数据可以使用其他编码技术如Move-to-front transform和游程编码进行文本压缩.
BWT有4个主要步骤:
1) 在原始字符串S=“banana”的末尾添加一个‘$’字符,令S=“banana$”;
2) 字符串S循环向左旋转n次得到矩阵W′;
3) 按字典顺序排列矩阵的每一行字符串以获得新的矩阵W;
4) 分别取矩阵W的第1列和最后1列,并将它们定义为F和L列,把L列作为BWT(S)的结果.
算法1给出了BWT转换的具体描述.值得注意的是BWT中有一个十分重要的属性就是第i次出现在F列中的字符x是对应于第i次出现在L列中的字符x,Burrows和Wheeler在文献[11]中给出了证明.
算法1.BWT转换算法.
输入:字符串S;
输出:转换结果矩阵W.
l=S.length()+1;
S.append(‘$’);
i=0;
charW′[l][l];
S往左旋转l次,每次的结果保存在W′的第i行中;
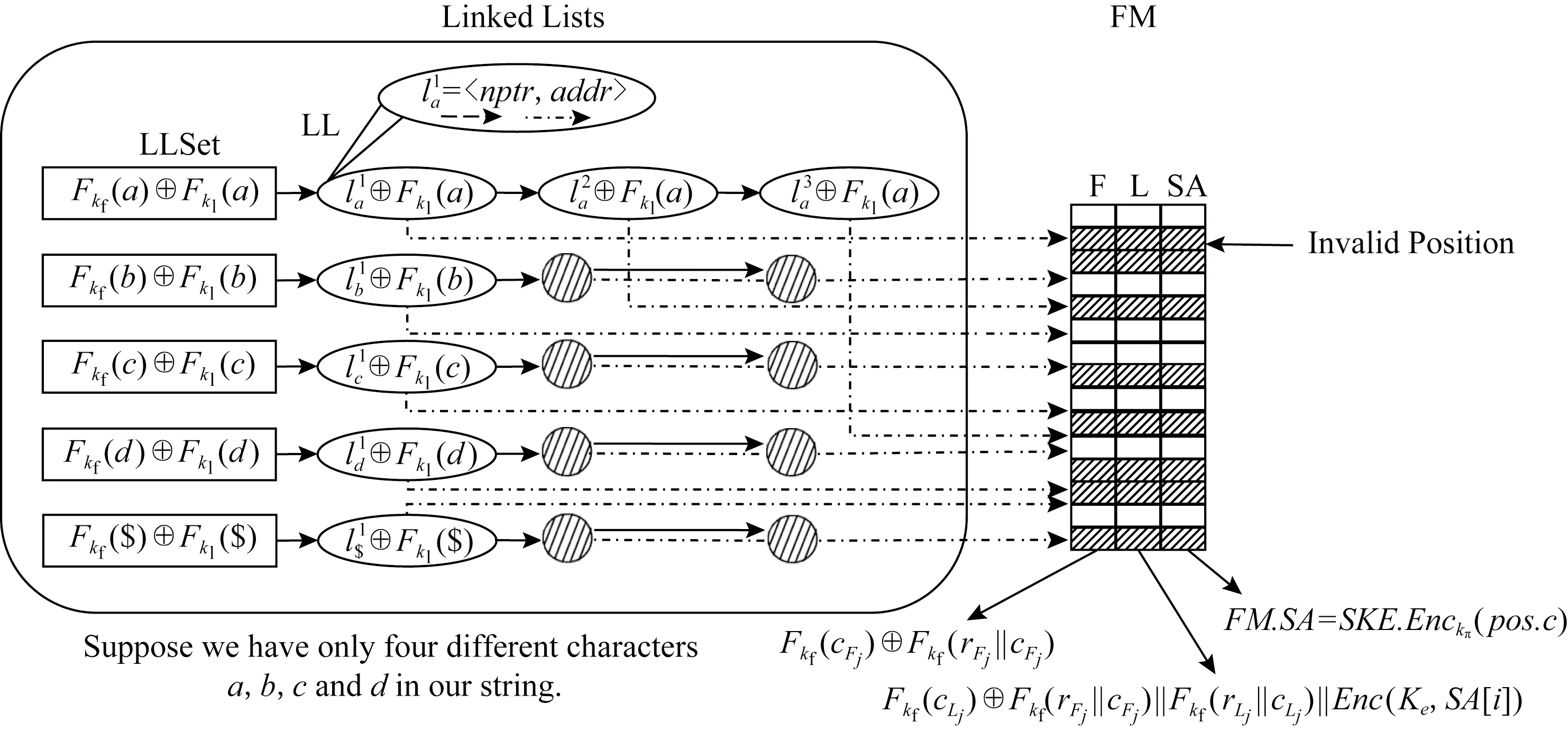
whilei W′[i++]=rotate(S,i); 将矩阵W′的每一行按照字典顺序重新排列最终得到W; end while returnW=SortedW′. 字符串S的长度为n,那么S的后缀是suffix[i]=S[i,…,n-1].字符串S=“banana”,那么字符串S的后缀suffix[i]={“banana”,“anana”,“nana”,“ana”,“na”,“a”}.后缀数组SA是字符串S所有后缀按照字典顺序排序后,每个后缀对应于S中的位置的数组.S的后缀数组是SA[i]={5,3,1,0,4,2}.通常计算后缀数组SA的效率都比较低.例如朴素暴力穷举算法的时间复杂度为O(n2logn),它把字符串所有的后缀全部都计算出来后依次去排序最终得到后缀数组SA,这种方法的效率是十分低效的.倍增法[12]的时间复杂度为O(nlogn),它是基于基数排序思想去计算后缀数组SA的.虽然倍增法已经极大地缩短了计算后缀数组SA的时间,但是相对于在一个线性时间复杂度O(n)下快速计算后缀数组SA的算法,倍增法就失去了优势.Sanders等人提供了一个非常有效的skew算法[13].skew算法是根据原始字符串S的所有后缀的位置pos递归地将其分成3组:posmodh{1,2,3},最后合并结果求出后缀数组SA. LF映射[11]是通过BWT(S)后得到矩阵W中的F列字符串和L列字符串多次反复迭代最终恢复原始字符串S的过程.它等同于在原始字符串S中搜索子字符串T,其中S=T.LF映射如算法2所示. 算法2.LF映射算法. 输入:矩阵第1列F、矩阵最后1列L; 输出:原始字符串S. D=0; i=0; 执行算法1得到转换结果矩阵W; 判断W的第F列和第L行; 在F列中查找排名等于r的L[i]的位置; whileL[i]≠‘$’ do D.push(L[i]); r=rank(L[i]);*L[i]在L列中的排名* i=find(F[L[i]],r); end while whileD≠‘0’ do S=S+D.POP; end while returnS. 然而,实际上方案可以通过SubLF映射来部分恢复原始字符串S从而达到实现子串匹配的目的.它等同于在原始字符串S中搜索子字符串T,其中S≠T.这也是搜索子字符串的重要手段.SubLF映射的具体步骤如算法3所示. 算法3.SubLF映射算法. 输入:矩阵第1列F、矩阵最后1列L、字符串m; 输出:字符串m在串S中的位置pos. l=m.length(); flag=0; num=rank_max(m[l-1]);*查找m[l-1]的最大排名* fori=0 tonumdo forj=0 toldo ifa≠⊥ a=find(F[m[l-j-1]],i); end if ifa==⊥ orL[a]≠m[l-j-2] flag=0,pos=null; end if returnpos; end for end for flag=1; r=rank(L[a]); a=find(F[L[a]],r); ifflag==1 pos.append(a); end if returnpos. FM索引是由3列数组组成.FM索引的第1列F列是矩阵W的第1列,第2列L列是矩阵W的最后1列,最后1列是原始字符串S的后缀数组SA.为了支持LF映射,F列和L列中每个字符的唯一排名也都需要存储在rF和rL中,其中rF和rL均来自于rank〈rF,rL〉二元组.最终通过LF映射利用公式[14]BWT(S)[i]=L[i]=S[SA[i]],可以计算出后缀数组SA来完成子串查询.FASSE方案利用文献[10]中加密的FM索引的方法来构造整个方案.其中FASSE方案中的加密方法包括对称加密方案SKE={Gen,Enc,Dec}和轻量级加密原语:伪随机函数PRFFkf(·),伪随机置换PRPΠkπ(·). 加密的FM索引结构如图1所示.其中L列和F列的值为Fkf(cLj)⊕Fkf(rFj‖cFj)‖Fkf(rLj‖cLj)和Fkf(cFj)⊕Fkf(rFj‖cFj).后缀数组SA为SKE.Enc(ke,SA[j]),最后执行PRPΠkπ(FM)打乱整个FM索引的顺序.其中kf,kl是伪随机函数密钥;kπ是伪随机置换密钥;ke是对称加密密钥.加密的FM索引执行LF映射算法会比明文FM索引执行LF映射算法要复杂.具体做法是:先生成字符c的搜索令牌Fkf(c),计算Fkf(c)⊕Fkl(c),通过查找对应位置的LLset异或解密相应的LL得到字符c对应的二元组lc=〈nptr,addr〉,其中nptr是下一个lc的位置,addr是字符c在F列中的位置.在F[addr]上执行Fkf(c)⊕Fkf(cFj)⊕Fkf(rFj‖cFj)异或运算解密得到Fkf(rFj‖cFj)并且得到的Fkf(rFj‖cFj)可以在L列中执行Fkf(rFj‖cFj)⊕Fkf(cLj)⊕Fkf(rFj‖cFj)异或解密得到Fkf(cLj),计算Fkf(cLj)⊕Fkf(rLj‖cLj),继续比对F列中的Fkf(cFj)⊕Fkf(rFj‖cFj),经过多轮循环后得到搜索结果,即加密的SA[j].最终使用ke解密得到真正的SA[j]. Fig. 1 Construction of an encrypted AFM图1 加密的AFM的构建 如图2所示,FASSE方案系统模型包含3个实体:云服务器、授权用户和数据拥有者.数据拥有者使用任意关键词提取算法对文档集合D提取的关键词KW.数据拥有者为每一个文档生成唯一文档标示符id.加密的唯一文档id得到唯一加密标示符d.数据拥有者加密文档标题TIT得到ETIT且为每一个文档构造出安全加密的EAFM索引.最后将加密文档集ED及EAFM索引上传至云服务器.云服务器保存ED和EAFM索引返回保存地址给用户.数据拥有者构建并发送字典Dic到服务器保存.在搜索阶段,授权用户先对搜索的关键词Q={q1;q2;…;qu}构造陷门TQ并上传.当授权用户接收到陷门TQ后,云服务器通过字典Dic进行搜索,如果云服务器执行一次命中搜索协议则将结果返回.如果云服务器执行增强搜索协议则通过搜索EAFM索引将结果返回.最后,授权用户解密密文文档ED. 在FASSE方案构建的威胁模型中,服务器被定义为是“半诚实并且好奇”的,敌手和云服务器被视为潜在威胁对象.FASSE方案中云服务器确保会完整正确地执行FASSE方案设计的所有搜索协议,不会恶意删除用户文档和恶意泄露用户隐私.但是云服务器可能会分析文档和索引,例如统计分析字符频率、文档与关键词匹配的数目、文档的历史信息等.在FASSE方案中敌手可能会和云服务器合谋,那么上述的这些隐私信息很可能会被敌手利用去分析攻击系统,导致系统存在安全隐患.所以在此威胁模型中FASSE方案要确保所有历史信息、陷门、字典、文档信息和索引的安全. FASSE方案是7个多项式时间算法(KeyGen;Encrypt;PreProcess;DicGen;Trapdoor;Search;Decrypt)的集合,定义为: 1)K=KeyGen(1λ).其中,λ是安全参数.该算法用于生成加密密钥K={k,kf,kl,kπ,ke,kt,kid,kaddr},其中kf,kl是伪随机函数密钥,kπ是伪随机置换密钥,ke是对称加密密钥,kaddr由服务器生成.这些密钥都是随机数,均由系统随机生成. 2)ED=Encrypt(k,D).D为明文文档集合,D={D1,D2,…,Dn}.ED为密文文档集合,ED={ED1,ED2,…,EDn}.使用密钥k以及对称加密算法(比如AES)加密生成ED. 3)EAFM=PreProcess({kf,kl,kπ,ke},F‖L‖SA).F是BWT(S)生成矩阵W的第1列,L是W的最后1列.SA是字符串文本S的后缀数组.使用密钥{kf,kl,kπ,ke}以及对称加密算法加密F,L,SA生成EAFM索引. 4)Dic=DicGen(Enc({kf,kid,kt,kaddr},KW,id,tit,EAFMaddr,EDaddr)).其中,KW是关键词,id是文档标示符,tit是文档标题,EAFMaddr是EAFM的地址,EDaddr是ED的地址.使用密钥{kf,kid,kt,kaddr}以及对称加密算法加密KW,id,tit,EAFMaddr和EDaddr生成字典Dic. 5)TKW=SearchToken(kf,KW).其中KW是用户查询的关键词.利用密钥kf加密关键词KW生成对应的搜索令牌TKW. 6)ED(KW)=Search(Dic,EAFM,TKW).利用搜索令牌TKW、字典Dic和EAFM索引进行查找,输出与KW匹配的加密的文档集ED(KW).具体的实现细节需要依赖具体的实现算法,将在第4节的4个搜索过程中进行详细描述. 7)Di(KW)=Decrypt(K,EDi(KW)).使用对称加密算法以及密钥k解密包含关键词KW的密文文档EDi(KW),生成包含关键词的明文文档Di(KW). 如果灵活精度可控的对称加密方案FASSE是正确的,那么对于∀λ∈N,n∈Z,D={D1,D2,…,Dn},KeyGen(1λ)和Encrypt(k,D)输出的k和ED都有: Search(Dic,EAFM,SearchToken(kf,KW))=EDi(KW)和Decrypt(k,EDi(KW))=Di(KW)成立. 本文设计的FASSE方案假设服务器是“半诚实且好奇”的,所有的数据查询操作对服务器都是透明的,并且所有的明文数据处理都是由可信客户端处理后以密文的形式上传到服务器.服务器仅用于存储和计算,而并不知道存储和计算的具体内容. 当存在一个敌手A在不知道密钥的情况下是无法得知存储在服务器上加密文档的任何信息.当敌手A在线攻击分析时,首先敌手A并不知道搜索令牌tokenm对应的是哪个关键词的令牌,那么敌手A就不可能知道搜索的是哪个关键词.即便敌手得知搜索令牌对应的是哪个关键词,最后也因为无法解密SA所以无法得知本次搜索结果是否有效,这也保护了用户的隐私信息安全. 敌手A不能通过LLset离线分析字符的频率去猜测攻击,因为FASSE方案使用了Fkl(c)加密,Fkf(c)使敌手A无法在不观察任何搜索令牌的情况下去执行离线频率攻击.即便敌手A获得了搜索关键词令牌也无法执行在线频率攻击,因为FASSE方案在LL中进行了填充使得每一个字符的频率都一样. 在存储安全性方面如果存在恶意敌手A想要恶意删除存在某个关键词k的文档时,在没有破解字典之前就无法得知文档的具体存储地址、破坏文件,这一定程度上提升了文档存储的安全性.当存在一个敌手A试图去离线分析字典Dic时,他无法得知服务器中存储了多少文档和每个关键词对应多少文档,因为客户端已经将随机记录添加到字典Dic中了.为了提高安全性,字典Dic按字典顺序排序.那么字典Dic在历史上是独立的,敌手A不能得知任何历史相关信息.但是,当用户在线搜索字符串时,服务器将向A暴露有多少个文档包含字符串m.如果敌手A想要分析EAFM索引,他也不能得知任何与明文有关的内容,因为Leontiadis[10]针对离线频率攻击(offline frequency attack)、在线差别攻击(online difference attack)、离线差别攻击(offline difference attack)、在线频率攻击(online frequency attack)已经做出了相应的对抗手段. 1) AFM. AFM是文档摘要的FM索引.FM索引在文献[10]中已经有了详细的描述,它是子字符串搜索的核心部分.客户端加密AFM后会得到EAFM,EAFM的结构如图1所示. 2) 字典Dic. FASSE用一个字典Dic代替创建关键字集合.字典Dic中每一条记录的第1个属性是EKW,它等于F(kf,KW),表示加密的关键词Fkf(KW).第2个属性是d,它等于Enc(kid,id),表示加密文档的标识符,其中kid是加密文档标示符id的对称加密密钥.这里将加密文档表示为ED.第3个属性是Etit,它等于Enc(kf,tit),表示文档的加密标题.第4个属性是EEDaddr,它等于Enc(kaddr,EDaddr),表示EDaddr的加密地址,其中kaddr是加密EDaddr的对称加密密钥,EDaddr是加密文档的地址.最后一个属性是EEAFMaddr,等于Enc(kaddr,EAFMaddr)表示EAFMaddr的加密地址,其中EEAFMaddr是加密的AFM的加密地址.通过对EDaddr和EAFMaddr加密尽可能地阻止敌手A在离线分析这些地址的时候可以获取到任何与明文文档相关的任何内容或者破坏文档.同时为了提高安全性,FASSE还将记录(EKW,d,Etit,EEDaddr,EEAFMaddr)按字典顺序添加到字典Dic中.另外,方案还会随机添加q个记录到词典Dic中(q的大小可以手动设置也可以随机生成)以防敌手A离线分析服务器端的文档总数以及每个关键词对应的文档总数.字典Dic的结构如表1所示: Table 1 Dictionary Dic表1 字典表Dic 首先,数据拥有者会将原始的明文文档D上传到客户端同时会生成唯一的加密文档标识符d.客户端加密文档D,生成加密文档ED、文档摘要的FM索引AFM、加密的文档摘要的FM索引EAFM和加密的文档标示符d,并通过有效地提取关键词算法提取有效关键字kwi或者也可以使用预先设定好的关键词kwi.同时使用kf作为密钥的伪随机函数PRFF(·)加密有效关键字kwi生成Fkf(kwi).客户端通过计算Enc(kf,tit)来加密文档的标题得到加密的文档标题Etit.最后客户端将这些加密的数据全部都上传到服务器.服务器保存这些加密数据并且将这些加密文档的地址EDaddr和加密的文档摘要的FM索引即EAFM的地址EAFMaddr用kaddr进行加密得到加密文档的加密地址EEDaddr和EAFM的加密地址EEAFMaddr.最终得到(Ewi,d,Etit,EEDaddr,EEAFMaddr)并生成记录上传到字典表Dic中. 一次命中搜索、增强搜索和过滤搜索,它们分别对应着用户只用一次就在字典中找到关键词记录、没有在字典中找到关键词记录而只用一次就在摘要中找到记录或者多次在字典和摘要中查找到关键词记录的这3种搜索情况. 一次命中搜索主要适用于关键词提取精度比较高的搜索场景.增强搜索主要适用于关键词提取的比较粗糙的搜索场景.过滤搜索适用于存在关键词重要程度概念的搜索场景. 用户在输入搜索字符串m之后服务器会在词典Dic中依次去查找EKW=Fkf(m)的记录.如果存在相应的记录服务器会立即执行一次命中搜索,解密这些EEDaddr得到相应的加密文档地址EDaddr,并将这些加密文档标识符d、加密文档标题Etit和加密文档地址EDaddr全都发送给客户端.客户端会通过计算Dec(kf,Etit)来解密这些文件加密的标题得到明文的标题tit.用户通过tit选择对应需要的加密文档标识符d.客户端通过这些加密文档标识符d找到对应的加密文档地址EDaddr并将这些加密文档地址EDaddr发送到服务器并请求服务器下载这些加密文档ED.如图3所示,一次命中搜索协议的特点是对于搜索关键词已经在字典Dic中的这次搜索服务器会直接检索字典Dic中的EKW属性从而最快得到检索结果,它是整个FASSE搜索过程中耗时最短、精度最高的.但是和传统的基于关键词集合的SSE一样,对关键词的提取和关键词集的建立的要求都十分高.综上可得一次命中搜索主要适用于关键词提取精度比较高的搜索场景. 一次命中搜索协议如下: 客户端:生成搜索字符串m的搜索令牌tokenm并发送到服务器. 服务器:ifFind(tokenm,Dic)==⊥ 返回⊥(空)到客户端; else 返回d,Etit,EEDaddr和relativity到客户端; 其中relativity的每一个元素值都为“Max”. end if 客户端:if 从服务器端接收到⊥ 请求服务器执行增强搜索or结束退出; relativity* 设置relativity的每一个元素值都为1.0; 生成新的搜索字符串mi的搜索令牌 tokenmi; 发送tokenmi,d,Etit,EEDaddr和relativity 到服务器请求执行过滤搜索; or发送EEDaddr后等待接收从服务器发送的ED; else 解密Etit得到tit; 根据tit选择需要的d并得到相应的 EEDaddr; 发送EEDaddr到服务器请求服务器进行下载. end if end if 服务器:解密EEDaddr下载ED发送到客户端. 如果服务器在词典Dic中未找到任何相应的记录时,这种情况是经常遇到的,那么增强搜索将起到重要的作用.服务器将通过字典Dic去搜索每个文档的EAFM,并将与字符串搜索令牌即Fkf(m)相匹配的记录中的d,Etit和服务器解密后得到的EDaddr发送到客户端.如果担心服务器返回大量无效填充位置,那方案也可以使用文献[10]中的bucke-tization技术并选取适当大小的窗口使填充节点的数量大大减少.通过计算Dec(kf,Etit)来解密得到这些文件的标题tit.用户通过tit选择需要的d.最后,客户端将EDaddr发送到服务器请求下载这些ED.增强搜索结构如图4所示.如果服务器有足够的空间资源FASSE也可以采用建立内容的FM索引即CFM(FM index of the content)的方法来进一步提高搜索结果的精确性.增强搜索协议的特点是针对字典Dic中不存在搜索关键词的情况下从而对文档摘要进行搜索,那么增强搜索相对一次命中搜索速度就会慢上很多,但它也打破了传统基于关键词集合的SSE因为在关键词集合中未检索到搜索关键词而无结果的尴尬局面.综上可见增强搜索主要适用于关键词提取的比较粗糙的搜索场景. Fig. 4 Reinforcement search图4 增强搜索 增强搜索协议如下: 服务器:解密整个字典Dic中的EEAFMaddr得到EAFM; 对EAFM执行SubLF映射算法; 计算m在所有摘要中不算填充的有效次数Occur; ifOccur中的每一元素的值都为0 返回⊥并结束退出; else 从Occur中选最大的nk项Occurk; 取出Occurk对应字典Dic中nk项的记录 Temp; 设置relativity的每一个元素值与Temp[Occurk]相对应;*当从过滤搜索执行增强搜索时relativity等于上一次的relativity加上0.2*Temp[Occurk]* 发送Temp[d,Etit,EEDaddr,Occurk]到客户端. end if 客户端:取出Temp[Occurk]; 生成新的搜索字符串mi的搜索令牌tokenmi; 发送tokenmi,d,Etit,EEDaddr和relativity到服务器请求执行过滤搜索; or发送EEDaddr后等待接收从服务器发送的ED; else 解密Temp[Etit]得到tit; 根据tit从Temp[d]选择需要的d并得到 相应的EEDaddr; 发送EEDaddr到服务器请求服务器进行下载. end if 服务器:解密EEDaddr下载ED发送到客户端. Fig. 5 Filter search图5 过滤搜索 用户在经过了一次命中搜索或者增强搜索之后仍然得到了许多难以选择的tit和d,这是最常见的但也同时是最麻烦的情况.这种情况如果服务器的查询结果中只有少量的小文件时,那么用户就可以直接发送请求给服务器请求服务器下载这些文档到本地来筛选并确定哪些文档是自己需要的.但是如果服务器的查询结果中有许多大文档时,那么巨大的网络开销是服务器和客户端双方都难以承受的.事实上FASSE中的过滤搜索其实是相当于一个筛子,可以连续地过滤用户不满意的文档.FASSE将成功匹配m1搜索令牌的数量定义为相关性,字符串m1出现在摘要中的频率越高,那么文档的相关性越大,反之亦然.服务器会选择相关度最高的前n%个文件进行下一步处理.n可以通过计算成功匹配了字符串m1摘要的总数的百分比或手动设置合适的数字来确定.服务器将nd,nEtit和解密后的nEDaddr返回给客户端,客户端通过计算Dec(kf,Etit)来解密这些tit.最后,用户通过tit选择需要的d和EDaddr最终获得需要的ED.过滤搜索是通过使用不同的字符串mi在这些难以选择的d上执行重复搜索.用户将得到n1,n2…直到有确定可以下载的nk个d时,下载这nk个文件,因为重复过滤后文件的相关性达到了最大.过滤搜索结构如图5所示.因此可得,用户可以控制搜索的精准性,以便搜索需要的文档.搜索的准确度越高,用户获得预期文档的可能性就越大,FASSE通过控制用户获得预期文档的可能性就越大.FASSE通过控制过滤搜索的次数来达到精度的控制,从而实现精度可控的搜索.过滤搜索协议的特点是针对在一次关键词搜索字典和文档摘要后得到太多的结果的局面,对文档进行反复多次地一次命中搜索或增强搜索,它消耗的时间最多、速度最慢,并且需要用户手动设置新的关键词.综上所述过滤搜索适用于存在关键词重要程度概念的搜索场景. 过滤搜索协议如下: 服务器:接收从客户端发送的d,Etit,EDaddr,relativity; ifFind(tokenmi,Dic,d)==⊥ 返回⊥(空)到客户端; else 返回d,Etit,EEDaddr和relativity到客户端; 其中relativity的每一个元素值都为“Max”. end if 客户端:if 从服务器端接收到⊥ 请求服务器在d上执行增强搜索; or发送EEDaddr后等待接收从服务器发送的ED. relativity* end if if 搜索结果相关性低 设置relativity的每一个元素值都为1; 生成新的搜索字符串mi的搜索令牌tokenmi; 发送tokenmi,d,Etit,EEDaddr和relativity 到服务器请求执行过滤搜索; or发送EEDaddr后等待接收从服务器发送的ED; else 解密Etit得到tit; 根据tit选择需要的d并得到相应的EDaddr; 发送EDaddr到服务器请求服务器进行下载. end if 服务器:解密EDaddr下载ED发送到客户端. 模糊增强搜索操作是利用通配符‘*’和‘?’在普通增强搜索的基础上进行简单的修改.当服务器在成功匹配到搜索令牌Fkf(T[i])时,如果发现Fkf(T[i])=Fkf(‘?’),那么直接跳过这次与L列中Fkf(cLj)的比对,利用从F列中得到的Fkf(rFj‖cFj)异或L列中的Fkf(cLj)⊕Fkf(rFj‖cFj)‖Fkf(rLj‖cLj)获得L列中的Fkf(cLj)‖Fkf(rLj‖cLj),继续通过异或运算得到Fkf(cLj)⊕Fkf(rLj‖cLj)Fkf(cLj)‖Fkf(rLj‖cLj)并通过LLset依次在F列中查找与Fkf(cLj)⊕Fkf(rLj‖cLj)相等的Fkf(cFk)⊕Fkf(rFk‖cFk),经过多次迭代后就可以找到需要搜索的关键词.为了进一步提高方案的灵活性,方案提出了最大容忍错拼字符数em,并且默认em=0;也可以手动设置em的值,只要em的值合理即可.关于错拼的搜索本质基本和‘?’一样,它需要引入一个错误程度变量e,当发现Fkf(cLj)不等于Fkf(T[i-1])时直接跳过这次在L列中的比对,同时执行e++一次,只要e不超过设定的最大容忍错拼字符数em就属于错误可容忍范围内.关于通配符‘*’,FASSE设置‘*’最大能够表示r个字符.本文在实现FASSE方案时将r的值设置为2.例如“he*lo”={“helo”,“he?lo”,“he??lo”}.通过观察发现增强模糊搜索本质上还是对包含‘?’的字符串搜索.关于e,它和“?”一样相当于在不匹配的位置上加上了“?”.本方案通过对em,r,“?”和“*”的设置来实现灵活的精度可控的模糊搜索.最后可能还会得到一些不相关的结果,可以通过返回结果的相关性来剔除相关性低的结果,从而得到一个相对不错的结果. 本方案实验测试使用的计算机操作系统是Windows7,机器配备了Intel®CoreTMi5-4590 CPU @ 3.30 GHz四核处理器,具有8 GB RAM内存.实验是在本地同时模拟了一台服务器和一个客户端,开发环境为Eclipse_4.5.0,使用语言为Java编程语言.对称加密算法是使用AES密码算法且实现均调用的是java.security和javax.crypto下工具包.本系统的实现Java代码已经全部上传至https:github.comtaoruyuFA-SSE.git上. 本实验主要从2个方面测试方案的性能效率.首先测试上传生成索引的时间效率,研究生成索引的时间与文档的数量和摘要包含的字符数的相关性;其次对搜索的效率进行进一步的实验研究.对于搜索的效率研究,本文从增强搜索和模糊增强搜索2个方面进行对比试验,探索文档的数量与搜索关键词长度和文档包含的字符总数对搜索效率的影响.关于本次实验的所有实验数据均来自于真实数据集eprint中所有文章的英文摘要.FASSE方案搜索的时间效率主要取决于是否是执行了一次命中搜索.如果搜索过程中的所有操作都是一次命中搜索,这意味着它在搜索过程中所需的时间几乎等于在字典Dic中搜索全部记录的时间.这个时间相对于其他搜索过程是可以被忽略不计的.然而,搜索操作不可能都是一次命中搜索,大多数情况下都是增强搜索或过滤搜索,并且搜索过程中的大部分时间也都会消耗在这2种搜索过程中.经过多轮搜索后,增强搜索和过滤搜索的次数将继续不断增加,搜索所需的总时间会越来越多,但是每一轮新的搜索所需要的时间也会越来越短同时准确性会越来越高.本实验中未对过滤搜索的性能进行实验研究,因为过滤搜索的时间是可以从增强搜索的时间效率图中计算出来的.过滤搜索本质也是一次命中搜索和增强搜索的不断循环交替,不同的是过滤搜索的文档范围会越来越小. Fig. 6 Efficiency of uploading and searching for the FASSE图6 FASSE方案的上传和搜索的效率 FASSE方案的上传和搜索的结果具体参考图6.其中图6(a)展示了FASSE方案上传文件所需的时间效率图.从中可以计算出当摘要包含500字符以内时,上传效率平均每个为0.09 s;当摘要包含500~1 000字符时,上传效率平均每个为0.32 s,当摘要包含1 000~1 500字符时,上传效率平均每个为0.79 s;当摘要包含1 500~2 000字符时,上传效率平均每个为1.42 s;当摘要包含2 000~2 500字符时,上传效率平均每个为2.34 s.图6(b)表示增强搜索的时间性能图(固定摘要包含2 000~2 500字符),可以发现当文档数逐渐增加时,搜索所需时间越来越不稳定,这是由于不同的搜索关键词在文档中的频率不一样导致的.图6(c)表示关键词搜索与文档摘要包含的字符总数的关系图(固定搜索关键词长度为3).图6(c)可以发现摘要包含字符总数与搜索时间呈现正相关,且呈现出当文档数越多这种正相关性越强的趋势.在图6(c)中,当摘要包含的字符总数小于500时,对于各个不同文档数量的平均搜索时间依次为36.425 ms,67.375 ms,109.125 ms,149.125 ms,209.25 ms,故平均搜索时间为114.26 ms.文献[15]讨论了面向多关键字的模糊密文搜索,与本文设计的方案相近,同本文具有一定的可比性.该文通过将文件数分为6类进行可搜索对称加密实验,该文的平均搜索时间约为120 ms,本文的搜索效率略有提高. Fig. 7 The efficiency of fuzzy enhanced search with different n图7 文档数n不同时模糊增强搜索效率 通过图6的实验看到了搜索关键词对实验结果的影响,图7将给出模糊增强搜索的搜索效率图.(由图6(b)得到结果,设置固定关键词长度为6). 由图7可以发现通配符‘?’对搜索结果的影响其实并不大,所以方案会在提高实用性的同时也会兼顾搜索的效率. 本文基于Leontiadis[10]可搜索对称加密方案提出了一种能够支持灵活的精度可以控制的可搜索对称加密方案——FASSE方案,它支持灵活精度可控的加密搜索并且节省了大量的存储开销.FASSE方案提供了4种基本搜索方式:一次命中搜索、增强搜索、过滤搜索和模糊增强搜索.同时,本文还结合这4种搜索方式设计了一种基于通配符技术的模糊增强搜索,并且通过设置部分参数从而达到灵活可控精度的搜索效果从而进一步增强系统的实用性.最后实验得出FASSE方案在实验论文数据集中平均搜索完每一篇论文的时间为114.26 ms.通过实验可以发现FASSE方案可以轻松应对各种关键词的搜索.但是目前FASSE方案不支持动态更新EAFM索引,所有的EAFM索引都是静态的,对用户操作(增、删、改)都无法做到及时更新,必须重新生成EAFM索引,这会导致时间和空间开销增加,所以一个可以动态更新EAFM索引的解决方案是我们今后的目标.FASSE将会参考文献[16],并且在未来希望它能帮助改进FASSE.此外,FASSE方案的模糊搜索方案中暂时不提供一次命中模糊搜索,所以在今后的工作中希望可以弥补这一点.2.2 后缀和后缀数组
2.3 LF映射
2.4 FM索引
3 定义FASSE方案
3.1 方案系统模型
3.2 FASSE方案威胁模型
3.3 FASSE方案算法描述
3.4 FASSE方案系统安全性分析
3.5 数据结构图

3.6 初始化
4 FASSE加密搜索过程
4.1 一次命中搜索
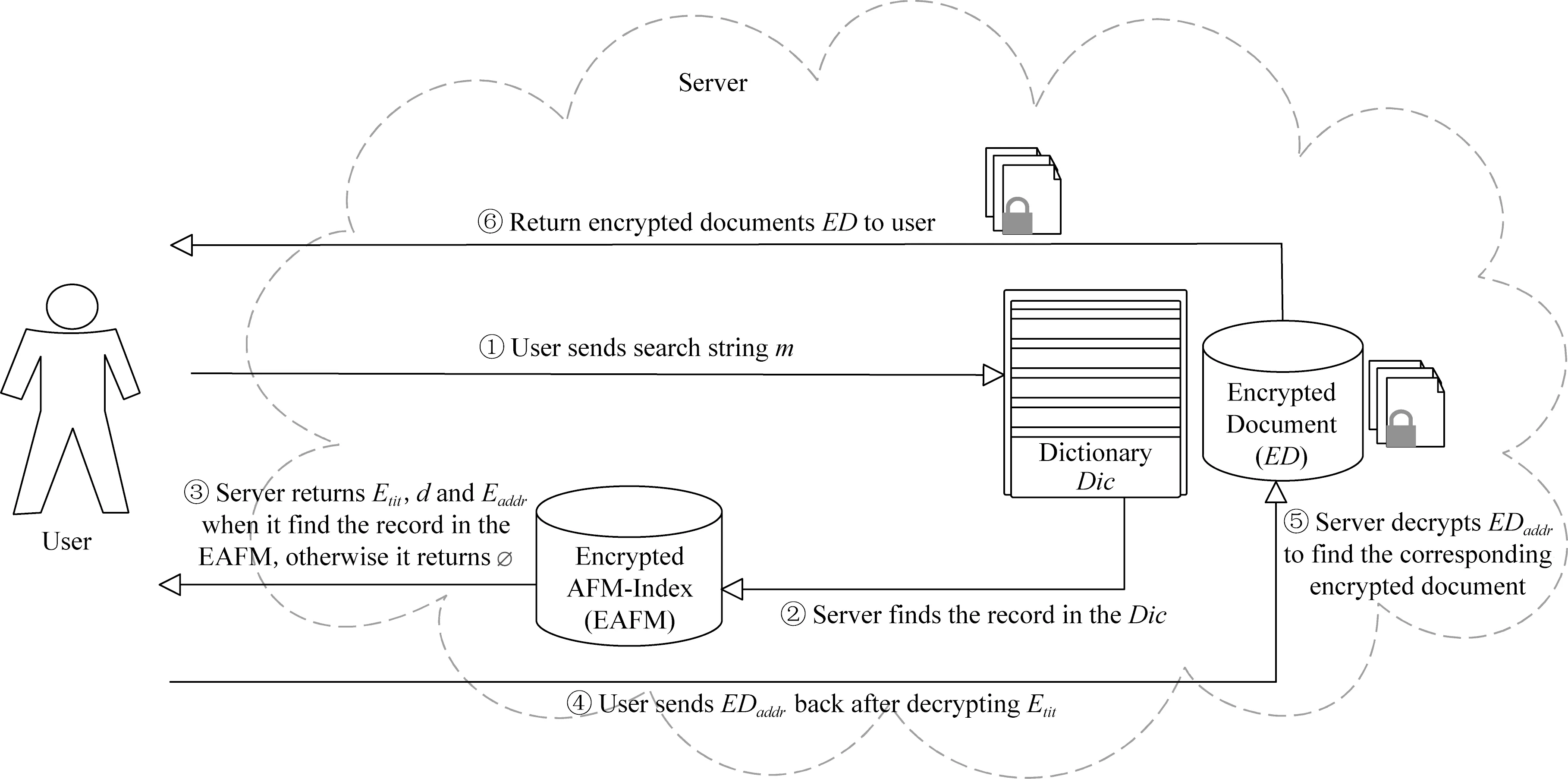
4.2 增强搜索
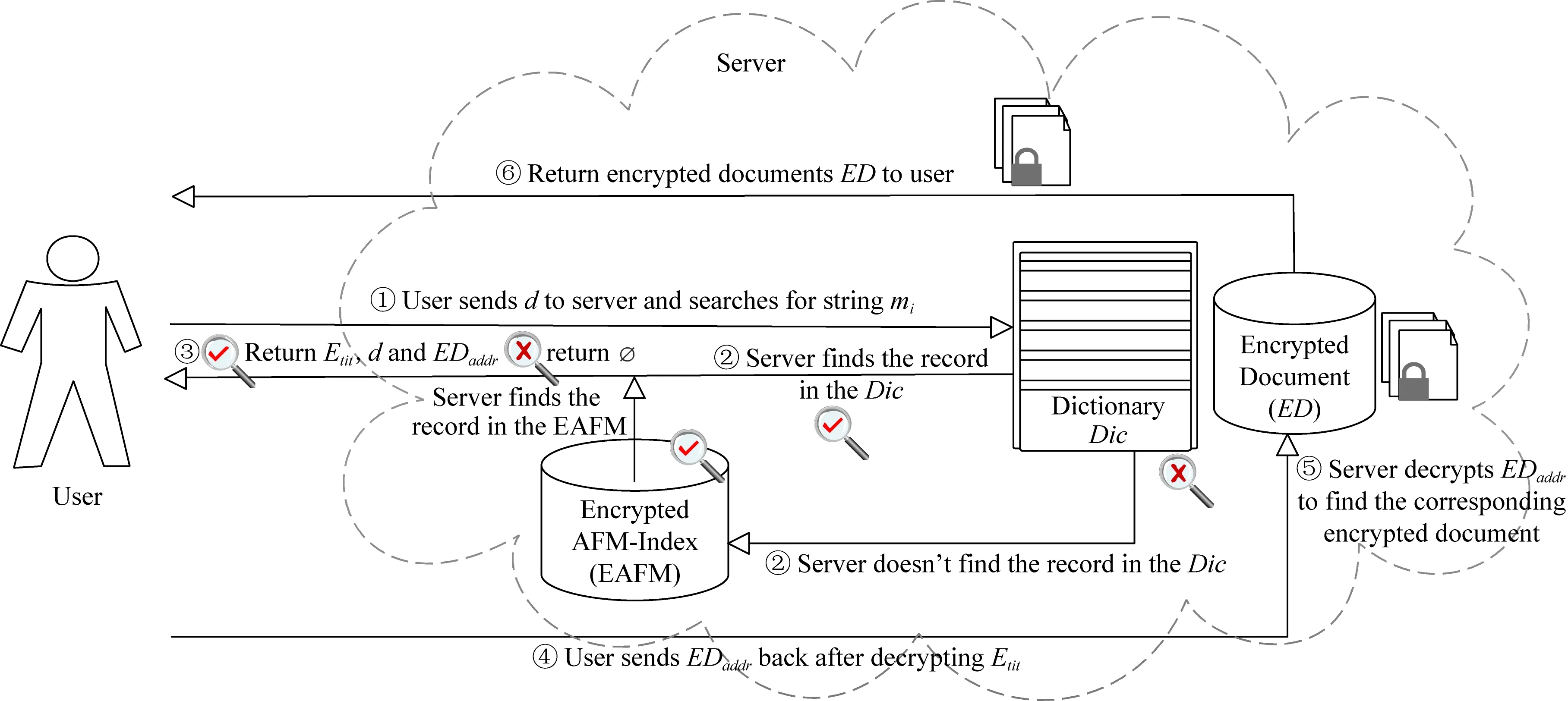
4.3 过滤搜索
4.4 基于通配符的模糊增强搜索
5 实验验证
5.1 测试环境搭建
5.2 实验设计
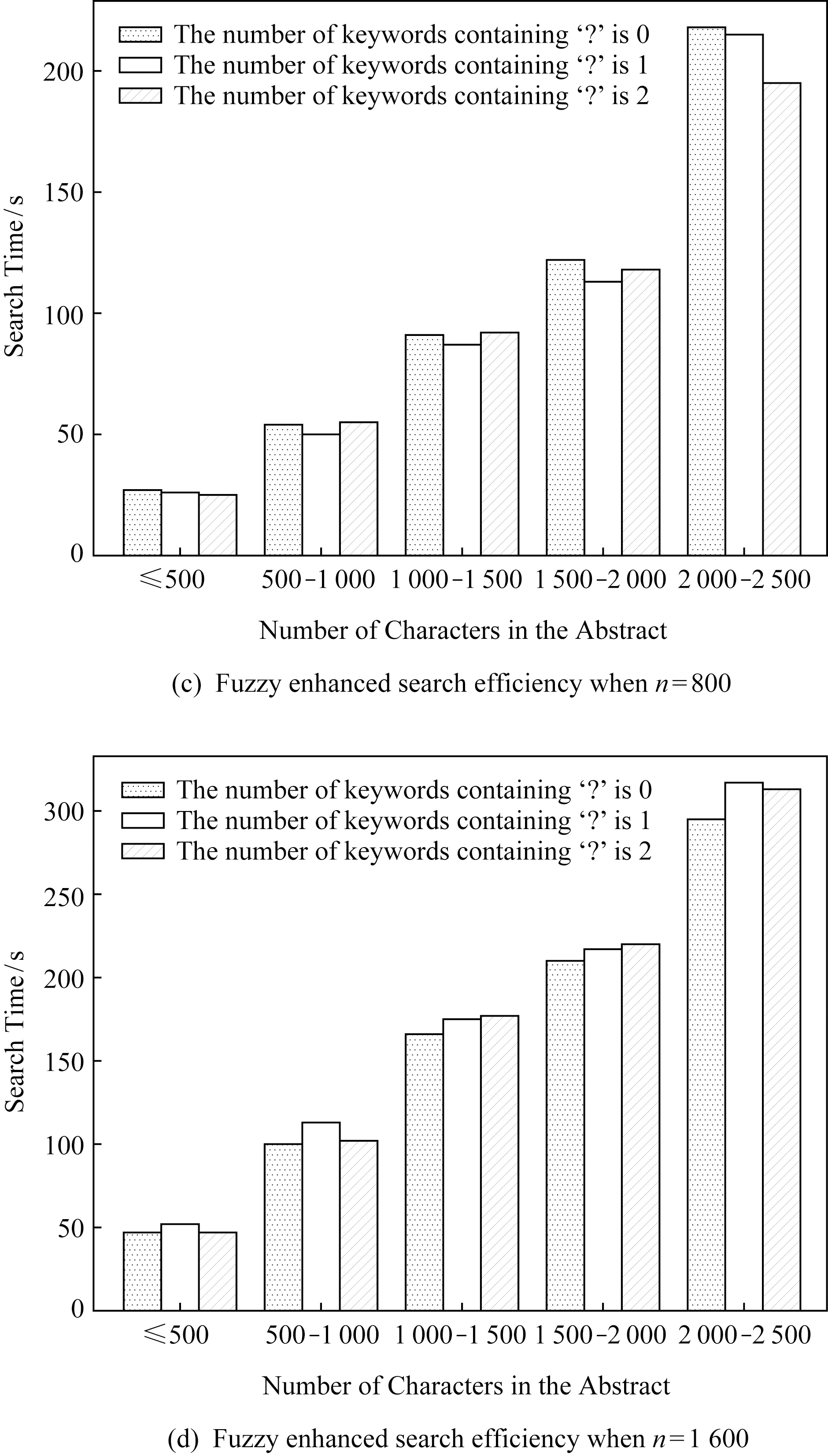
5.3 实验结果

6 总 结
猜你喜欢
无线互联科技(2020年11期)2020-12-01
小学阅读指南·低年级版(2019年11期)2019-07-01
小天使·一年级语数英综合(2017年11期)2017-12-05
科教导刊·电子版(2016年30期)2016-12-26
中国新通信(2016年17期)2016-11-17
读者(2016年14期)2016-06-29
电脑知识与技术·经验技巧(2016年1期)2016-03-14
电脑爱好者(2015年24期)2015-09-10
中国信息技术教育(2015年21期)2015-09-10
