
新的降维标准下的高维数据聚类算法*
2020-01-11 06:26何云斌
计算机与生活 2020年1期
万 静,吴 凡,何云斌,李 松
哈尔滨理工大学 计算机科学与技术学院,哈尔滨150080
1 引言
高维数据聚类是在图像分析和基因探索等领域常见的课题[1],它的主要目的是对大量未标注的数据集按照数据的内在相似性划分簇,使簇内相似度尽可能大,簇间相似度尽可能小[2-3]。目前高维数据对聚类算法提出了两个挑战:首先不相关的特征和噪声数据会对聚类算法产生误导;其次受维灾的影响,使高维数据点变得稀疏,从而很难在数据中发现任何结构[4-5]。现在针对这个问题的解决方案主要包括子空间聚类和降维技术[6]。子空间聚类方法是有效地抽取出存在于子空间的簇,经典算法有投影寻踪聚类(projected clustering,PROCLUS)算法[7]、熵加权软子空间聚类(entropy weighting subspace clustering,EWSC)算法[8]和聚类高维空间(clustering in quest,CLIQUE)算法[9]。降维技术是通过特征选择或者特征变换将高维数据空间归约到低维空间,主要算法有主成分分析(principal component analysis,PCA)[10]算法等。
国内外学者针对高维数据聚类做了一系列的研究。Azizyan 等人[11]在过滤式特征选择的基本框架下提出了新的筛选步骤来消除信息不足的特征,并在此基础上进行了特征密度的模式聚类,从而得到了聚类结果。新的筛选方法为多模态测试,对每个特征的边缘分布进行测试从而确定特征的信息量。该算法的理论证明较为清晰,算法通用性较强,时间复杂度较低,可以处理大规模数据。但是由于筛选标准脱离聚类算法导致算法的准确率难以保证。Ge 等人[12]将数据归一化后构造最近邻矩阵,计算评估数据最近邻数的逆近邻指数,将PCA 算法的最大方差标准改为通过逆近邻指数构造的偏度标准,最终在降维后采用hub 聚类法。这个方法消除了hub 聚类算法对噪声和冗余数据的敏感性,增加了聚类算法的准确性。但是当数据维数很高时受维灾的影响导致邻矩阵的生成是非常不准确的。Dash 等人[13]在面对高维数据聚类时将数据分为数字数据和属性数据,前者采用欧式距离,后者采用海明距离,得到距离结果后与信息熵结合构造出新的特征评价函数,评价某一维的信息量来消除冗余特征后再聚类,最后通过随机样本的方法改进算法的伸缩性,这个方法能够在最大限度保留数据信息的基础上完成数据的降维和聚类。Tinós 等人[14]提出了一种用于聚类的NK混合遗传算法,混合算法采用NK聚类验证准则2(NKclustering validation criterion 2,NKCV2),NKCV2使用N个小对象组的配置信息,每个组由数据集的K+1 个对象组成,在NKCV2 中,使用固定的k可以识别基于密度的区域,算法给出了决策变量之间的关系、变异因子、分块交叉(partition crossover,PX)和局部搜索策略。在PX 中,将评价函数分解为q个独立的分量,PX 确定地返回后代中可能的最佳值,NK混合算法可以检测到任意形状的簇,并且能自动评估簇。算法提高了聚类的应用范围,但是遗传算法固有的时间复杂度过高问题依旧没有解决。
本文针对高维数据,将PCA 算法中映射到低维空间的方差最大化[15]标准改进为一种基于新的特征度量的信息熵[16]标准,使降维后的数据有更好的分布特性,使其更利于聚类算法,实验证明新算法执行后再聚类结果的准确率比PCA 算法有明显的提升。由于降维结果中参数非零值过多而导致解释性变差的问题,提出了基于岭回归[17]的稀疏主成分算法[18],并通过坐标下降法得出了算法的解。最后通过改进的遗传算法[19]对数据进行聚类,算法改进交叉等操作[20]降低了算法的时间复杂度,并且具有较高的精度。
2 基本定义与说明
定义1(属性空间)给出包含维度为p的n个数据点的高维数据集D={x1j,x2j,…,xij,…,xnj},0 <j≤p,0 <i≤n。对数据集D转换后,将包含p个属性对象的集合称作属性空间,记为T,T={t1i,t2i,…,tji},0 <j≤p,0 <i≤n,其中每个属性对象与属性特征一一对应。
属性空间与数据空间的区别在于属性空间中的点是抽象属性的具象化,也就是说属性成为了空间中的点。这样做可以更加直观地看到各属性间的分布情况,属性空间的理论与数据空间到属性空间的转换方法在3.1 节有详细的解释。
定义2(属性距离)根据定义1,给出特征对象t1=(t11,t12,…,t1n)与特征对象t2=(t21,t22,…,t2n),则两个特征对象的属性距离为:
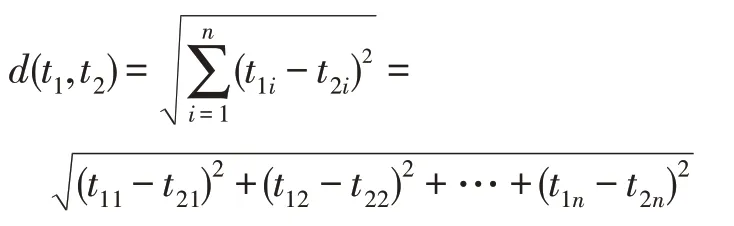
通过属性空间,可以很容易看到属性的远近程度,而属性距离可以具体测量出属性间的远近。
定义3(属性相似度)给出两个特征对象t1和t2的属性距离,则可以得到两特征之间的属性相似度,记为。
属性相似度建立在属性距离的基础上,α通过自动计算,其中是特征距离的平均值,而与定义4 有关,当属性相似度为时,属性空间信息熵最大,此时,于是,α的作用是防止属性距离波动过大对属性相似度造成不良的影响。例如当特征距离过小时,α的存在防止属性相似度分布过于陡峭,使属性相似度在区间(0,e-α]内均匀分布。
定义4(属性空间信息熵)给定一个属性空间T={t1i,t2i,…,tji},0 <j≤p,0 <i≤n,则可以得到属性空间信息熵,其定义为:
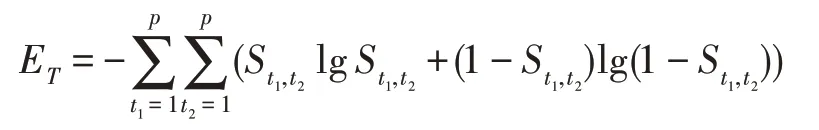
其中,t1和t2为属性空间中的任一特征对象。
定义5(entropy-variance,E-VAR 标准)给定一个属性空间T={t1i,t2i,…,tji},0 <j≤p,0 <i≤n,则E-VAR标准定义为,其中ET为选取的部分属性特征集合的属性空间信息熵,var是集合中特征对应的特征值的和。
协方差矩阵求解后特征值与映射到此特征数据的方差一一对应并且可排序,于是用特征值的和代替方差可以反映数据的方差情况。λ1和λ2为经验参数,实际应用中根据方差和信息熵的比例而调节。
定义6(总类内相似度)给出n个存在类标签的数据,类总数为K,任选其中一个类,编号为k,类中心记为ck,则对于所有数据中的任一数据点xi,0 <i≤n来说,存在成立,1 代表数据点在类k内,0 代表不在。于是类k的类内相似度记为Sk,,进一步得到总类内相似度为T(Sk)=。
定义7(选择函数)给出总类内相似度T(S),可以得到选择函数,记为F(S),其公式为。
定义8(CM 操作(cluster manipulate))给出的染色体串s={k1,k2,…,kn},ki∈{1,2,…,K},其中ki表示聚类中心,表示第i个类中数据量的大小,数据点xi∈ki,则CM 操作定义为对s重新计算聚类中心,即每个。
3 面向聚类的PCA 降维方法EN-PCA
PCA 算法根据方差最大化理论使得投影后方差最大,从而使得映射到低维空间的数据点之间较为分散,与此同时也导致降维后数据的聚类精度有所下降,不能获得好的聚类效果。例如当数据点分布如图1 所示时,图中有9 个数据点记为{x1,x2,…,x9},投影到x轴的坐标记为,投影到y轴的坐标记为,如果存在降维需求时,投影到y轴的数据方差,同时得到映射到x轴的数据方差var(x)≈1.58,可以看到var(y)>var(x)。根据PCA 算法降维理论,数据点应该映射到y轴,但是图中可以明显看到只有当数据点映射到x轴后才能获得更好的聚类效果,组成簇集C1、C2和C3。

Fig.1 Clustering effect after dimensionality reduction图1 降维后聚类效果
针对以上问题,本文在方差最大化理论的基础上拓展信息熵理论,基于PCA 算法构造新的降维标准,使其能更好地适应高维数据降维后聚类的需求。本章首先给出数据空间转换到属性空间的基本理论方法,紧接着提出了新的降维标准并给出了具体的算法和时间复杂度分析。
3.1 数据空间到属性空间
与属性空间相对的数据空间以属性为坐标度量,空间中的点为数据对象。而本文提出的属性空间将数据对象作为坐标度量,属性为空间中的点,属性点的集合构成了属性空间。从数据空间转换到属性空间就是将数据对象作为空间中的坐标尺度,属性成为空间中的点,坐标为对应坐标轴上数据在此属性上的值。
如图2 所示,在三维数据空间中存在两个数据点x1=(5,5,1),x2=(4,5,4),x1和x2分别有3 个特征,分别记为x、y和z。将图2(a)的数据空间转换成一个属性空间:首先将x1和x2作为属性空间的横纵坐标轴,属性空间中的点分别为x、y和z,则特征属性x的坐标为(5,4),y的坐标为(5,5),z的坐标为(1,4),于是可以得到图2(a)的属性空间为图2(b)。通过对比图2(a)和图2(b)可以发现,在数据空间图2(a)中很难发现属性间的远近关系,但是转换到属性空间图2(b)后,可以很直观地看到属性x与y距离较近,而它们都与z距离较远。如果存在属性约简需求,x与y的组合并不能很好地区分数据,而属性z与x和y中任一属性的组合都可以反映数据间的区别性。

Fig.2 Data space to attribute space图2 数据空间到属性空间
将数据空间转换到属性空间存在两个直观的问题,首先由于属性的量纲不同而导致属性点在属性空间中分布不均匀,这样就不能很好地反映属性间的关系,也不能度量属性的相似度。其次当数据量很大时,属性空间维度也会变大,从而引发一系列高维问题。
针对问题一可采用归一化的处理方式,将各个特征量化到统一的区间,运用标准化的方法,其中pi和表示归一化前和后的特征,μ表示特征的均值,δ表示特征的标准差。经过标准化后特征将分布在[-1,1]区间内,并且服从标准正态分布,为了让属性点分布得更加均匀,可以将特征分布区间扩大n倍,得到新的特征分布区间为[-n,n]。针对第二个问题的解决方法是抽取部分数据参与属性空间的建立,抽取方案为选择典型数据点。具体做法有两种:第一种是按比例选取数据点,但显然这样的选取方式并不能确保数据的典型性;第二种方法中数据点的选取方式为在第一种方法的基础上加入剔除特征为0 值过多的数据点,具体做法为当为0 的特征值数量占总特征的比例大于预设阈值则剔除此数据点。
3.2 新的降维算法
属性空间是对属性特征的具象化,能更加直观地观察出属性的分布情况以及属性间的相似度,但是属性相似度是度量两个特征间相似程度的工具。当需要度量整个属性空间的分布情况时,需要有更好的度量方式,于是信息熵是本文的解决方案。由于信息熵是通过数据的概率分布情况来反映数据不确定性的一种手段,那么对于属性点来说,通过信息熵依旧可以反映出特征属性的不确定性,而不确定性又决定了特征属性的价值。
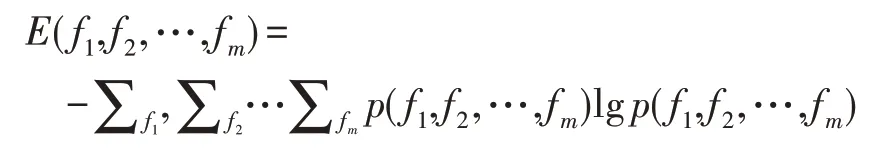
为信息熵的初始定义,其中p(f1,f2,…,fm) 是在点(f1,f2,…,fm)的概率。由于并没有分布的先验信息导致概率分布不能直接得到,于是本文将属性相似度引入到信息熵中得到属性空间信息熵,如定义4 所示,其分布与单调情况和信息熵的初始定义近似。通过信息熵理论可知,属性空间信息熵可以反映特征的相似情况,比仅考虑方差对于特征的分布情况描述得会更加准确。
如果仅将属性空间信息熵作为PCA 算法的降维标准,有时在得到降维数据后再聚类虽然可以获得较好的聚类结果,但是当降维属性不能很好地反映原数据的分布情况或者信息时,聚类结果的意义就会减弱。于是为了让降维后的数据可以更好地服务于聚类算法,并且聚类结果依然能反映出原高维数据真实的分布情况,定义4 构建了新的降维标准EVAR,新的标准融合了属性空间信息熵的同时也将反映数据分布情况的方差度量加入其中,使E-VAR 标准成为一个较为完善的降维标准。
基于以上的理论分析,算法的主要过程和计算步骤可以得出:输入数据矩阵An×p,包含了n个p维的数据,矩阵的每一个元素表示为aij(0 <j≤p,0 <i≤n)。首先需要对数据矩阵的列去中心化处理,消除特征之间的量纲,具体做法为矩阵的每一个元素减去列的均值:固定j,得到,其中。去中心化处理后,计算A的协方差矩阵,,由于Dcov为方阵,于是选择公式法求解得到Dcov的特征值为λ1,λ2,…,λn,对应的特征向量分别为α1,α2,…,αn,对特征值排序得到由大到小的特征值序列为。由于特征值与方差一一对应,根据特征值选择降维后特征数量k的大小,保证(经验参数)前提下的k值。EN-PCA 算法是在p个特征中选择k个特征,k个特征必须满足E-VAR 最大才能获得好的降维效果,于是算法在p个特征中遍历计算,在得到最大E-VAR标准时选择对应的特征向量。最后将矩阵A与矩阵相乘得到降维后的数据矩阵。具体算法如算法1 所示。


算法的时间复杂度分析:算法在第2 步去中心化处理,需要计算n次,此步的时间复杂度为O(n)。在第3 步计算协方差矩阵时间复杂度为O(p2n),步骤4在进行特征值分解时需要p3次运算,时间复杂度为O(p3),在6~10 步遍历选择特征值及计算E-VAR 的值,获得最大值最多需要遍历n次,每次计算E-VAR 值p2次,故时间复杂度为O(p2n),最后求得降维后矩阵W,因此算法的总时间复杂度为O(p2n)。与经典PCA算法时间复杂度一致,但是由于新的降维标准存在额外操作,EN-PCA算法会比PCA算法时间消耗多一些。
何守二一听这个,知道权筝妈不是善茬儿,态度变缓:“放心,我不会跟何东说的,跟他父母也不会提。”心里话,我招这事干嘛?
4 基于岭回归的稀疏主成分算法ESPCA
EN-PCA 算法得到的主成分间互不相关,是原特征的线性组合,线性组合中的因子载荷往往是非零的,这些非零因子载荷使得降维特征很难被解释。针对这个问题,本文提出了基于主成分结果的稀疏主成分算法(sparse principal component algorithm based on ridge regression,ESPCA)。算法在岭回归的基础上,对回归方程施加l1范数约束,通过使系数向0 收缩[21]的方式,获得稀疏主成分结果,增加主成分结果的可解释性。
岭回归是对不适定问题进行回归分析时最常用的一种正则化方法,其极值求解函数表达形式为,其中λ是控制收缩量的参数,λ值越大,收缩量越大,系数越向0 收缩[22]。
下面定理1 证明了主成分结果与岭回归结合的正确性。
定理1给出数据矩阵Xn×p,令Yi=UiDi,Yi为第i个主成分,存在岭回归,其中V={vi},是解的集合。
证明首先明确0 <λ时岭回归有效,对X矩阵分解后可得到XXT=VD2VT,且VVT=I,将岭回归的表达式写成矩阵形式为:
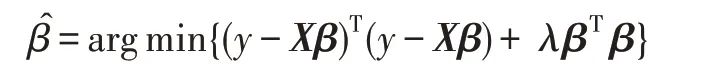
于是对这个极值表达式求导后得到:


通过定理1 证明了将回归方法与主成分联系起来的正确性,但是定理1 的输入为数据矩阵,从而直接得到稀疏结果,但是对于ESPCA 算法来说需要输入的是主成分降维后的结果,于是得到其回归表达式为,其中Y是输入的降维矩阵,X为数据矩阵,λ是控制V收缩的非负参数,λ值越大,系数越会趋向0,于是将稀疏问题转换为变量选择问题。但是通过岭回归的特性得知:其主要用于解释自变量与因变量之间的数量关系,并且当输入中存在多个相关变量时,它们的系数确定性会变差,并且呈现高方差性,岭回归可以避免这种情况。
于是为了得到稀疏的主成分,本文在岭回归的基础上,施加了l1范数的约束条件,通过加入l1范数约束,使各系数的绝对值之和小于某一常数,由于l1范数约束的自然属性,使添加了l1范数的模型得出的结果中有的系数会为0,因此可以得到稀疏的主成分。综上所述在岭回归约束的基础上添加l1范数约束会将稀疏属性带到约束模型中,同时岭回归分析的稳定性也为稀疏化提供了保障。因为如果仅存在l1范数,当数据矩阵的特征数大于降维后数据矩阵时,会导致结果过于稀疏,大量信息会因此损失。
ESPCA 算法输入的k个主成分表示为,i=1,2,…,k,为了得到稀疏主成分,利用施加l1范数的岭回归可以使系数自动缩减为0 的特点,用稀疏主成分Xvi拟合主成分可以得到k个独立的岭回归问题:

可以看出只要分别求解k个岭回归问题就可以得到稀疏载荷解V=(v1,v2,…,vk),于是接下来在求解(1)问题时采用坐标下降法。
坐标下降法在当前点沿某一坐标方向进行一维搜索,同时固定其他坐标方向,从而求解函数的极小值。对于任意的α∈R,λ>0,代表函数-αx+λ|x|的最小值点,其中lλ(α)的值取决于α和λ值的大小,即:

对于问题(1)而言,运用坐标下降法对第i个分量vi求解时,需要固定vj(j≠i)的值不变,于是相当于求解,其中,则根据式(2)的划分得到vi的解为:

基于以上分析,两阶段算法的第一段获取主成分结果可以在EN-PCA 算法降维后得到,再根据岭回归函数施加对k成分的约束后得到k个独立的岭回归问题,对于每个问题的解可以通过解(3)得到稀疏结果,循环k次后得到k个主成分的稀疏解,最后标准化每个解后返回结果。如算法2 所示:
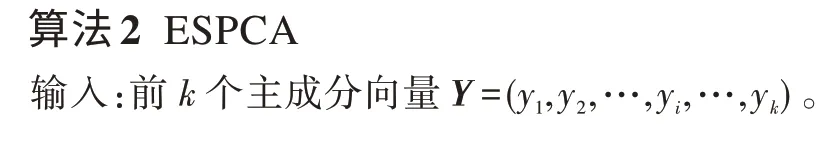

算法时间复杂度分析:第2 步算法对k个主成分进行稀疏化处理,时间复杂度是O(n),第3~4 步算法求解约束函数,对于每一个主成分梯度下降的运算次数是p次,时间复杂度是O(p),于是求解k个主成分的稀疏化算法时间复杂度是O(np),第5 步标准化vi执行k次,时间复杂度是O(n),因此ESPCA 算法的时间复杂度是O(np)。因为ESPCA 具有不需要迭代的特点,所以与其他稀疏主成分算法相比时间消耗要低。
5 基于遗传算法聚类的改进算法GKA++
上文通过改进PCA 算法将高维数据进行了降维处理,并稀疏化了主成分结果,接下来需要对降维后数据进行聚类。本文提出了一种新的基于遗传的聚类方法。由于初始种群选择是随机生成的,并且选择和变异操作是基于概率式的选择,在选择操作时采用的轮盘法并不能保证最优个体一定会被选择到,因此当遗传算法中数据量很大时,可能会导致算法的耗时过大。
GKA++算法对选择操作进行了改进,并保留了最优个体,使其始终参与进化,改进了变异操作,对离某聚类中心较近,但是还未在类内点的个体赋予较大的变异概率,使其变异为此类内点,最后去除了遗传算法中复杂的交叉操作,改进为重新计算聚类中心(CM 操作),更新染色体,使其更加适用于聚类算法。
算法首先论证了遗传算法中核心的适应度函数的正确性,接着详细介绍了算法的编码、初始化、选择、变异和CM 操作,最后给出了算法流程。
定理2适应度函数是反映种群聚类质量的标准。
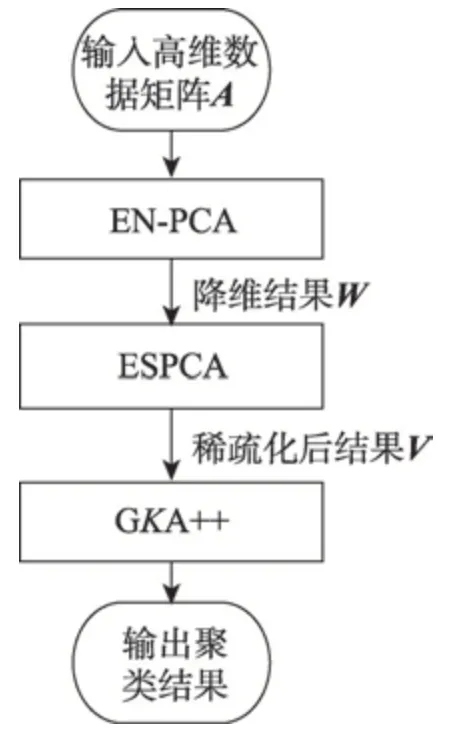
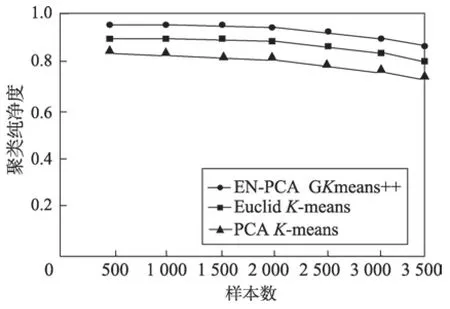
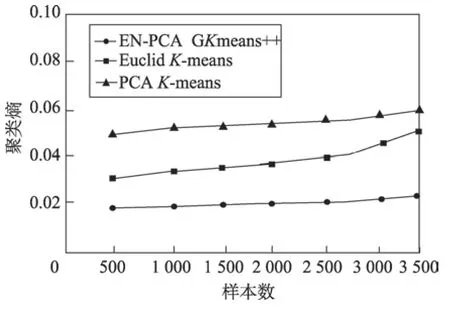
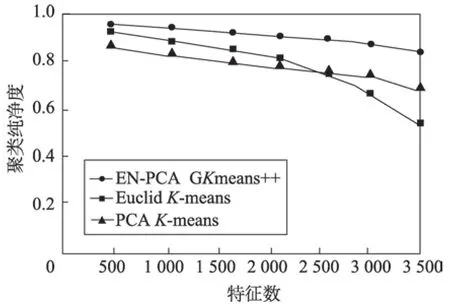
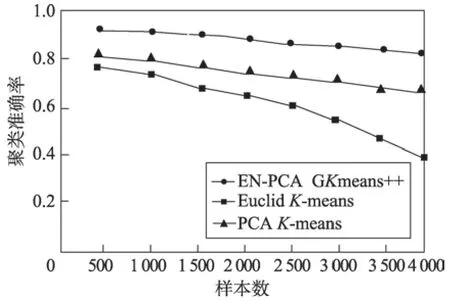
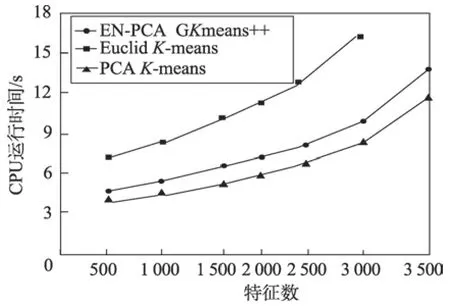
证明当类内的数据点i与当前聚类中心的距离lki(k代表类编号,i代表数据编号)大于到其他聚类中心k′(k′≠k)的距离lk′i时,数据i一定属于类k,即lki 对全体对象编码,这会让算法的计算更加方便。其中编码方式分为浮点数编码和二进制编码。如果是二进制编码,那么染色体的长度会随着维数的增加或者精度的提高而显著上升,这样做会使搜索空间变得很大,于是本文采用浮点数编码。给出数据对象集合X,元素为xi,并且聚类数目为K的集合来说,染色体结构为s={k1,k2,…,kn},ki∈{1,2,…,K},其中s是包含n个元素的数组,每一个元素在数组中的位置代表数据的标号,元素ki的值是数据所属的类标号k。 种群初始化:由于遗传算法对初始点不敏感,算法采用随机选择初始点,初始种群记为p(0),,将初始种群的每一个个体基因随机赋值为类标号,并且不允许有类内数据为空,即。 选择操作:定理2 证明F(S)选择函数的正确性,个体适应度越高,参与后代繁殖的概率就越大。算法在选择个体的时候采用了轮盘的方法,为了防止最优个体没有被选择到,选择操作加入了最优策略保存法,具体操作如下:首先计算当前种群中个体的适应度,保存适应度最大的个体,计算个体被选择的概率,再根据个体被选择的概率,使用轮盘法选出下一代个体,最后当下一代个体进行完交叉、变异后,用保存的最优个体替换掉下一代的最差个体。 变异:经典的遗传算法变异是随机方向的变异,但是在GKA++算法中,变异是朝着结果的变异,于是变异操作根据每个数据对象与聚类中心的距离对个体中相应的基因值进行改变。如果一个对象距离某个聚类中心比较近,那么对象对应的个体基因变异为这个类的编号的概率就比较高,这样可以使种群向更优的方向进化,提高算法的效率。于是对于对象i,对应的基因表示为G(i),变异概率记为pi,dmax表示到所有中心点最大的距离,dj表示i到某个聚类中心j的距离,则变异概率,其中c为大于1 的常量,pi∈(0,1)。 基于以上理论,GKA++算法如算法3 所示。 算法时间复杂度分析:在第1 步初始化时对n个对象随机赋予基因编号,时间复杂度O(n)。第2 步为算法的整体循环。第3~8 步为选择操作,对每一个对象计算适应度函数值和选择概率n次,并选择出M个下一代遗传个体,时间复杂度为O(n)。第9~12 步为变异操作,K个聚类中心计算变异概率最大的点k次,对于每一个中心需要遍历n个点,则时间复杂度为O(Kn)。第13~17 步为CM 操作,n个点重新计算中心需要n×K次操作,时间复杂度也是O(Kn),最后结束迭代次数循环,最大的循环次数为GKn,于是基于以上分析,算法的时间复杂度为O(GKn)。 本文通过EN-PCA 算法完成了对高维数据的降维操作,使降维后的数据更加适用于聚类算法。ESPCA 算法通过稀疏主成分的解,解决了降维后数据可解释差的问题,通过前两个算法的处理得到了较好的降维数据,GKA++改进了基于遗传算法的聚类算法,使其更加高效,更加准确。图3 为本文的算法设计思路。 Fig.3 Clustering process after data reduction图3 数据降维后聚类流程 为了验证文章算法的有效性,实验分析在Intel Core i5 2.5 GHz 和8 GB 内存的PC 机上进行,操作系统为Windows 10,实验程序采用Python 语言编写。数据集采用UCI数据集,详情如表1 所示。 Table 1 UCI data set表1 UCI数据集 实验主要反映了当样本数、特征数变化时,CPU运行时间以及聚类准确率等方面的变化情况,并加入了聚类纯净度P(C)和聚类熵E(C)的质量评价指标[23]。由于数据集为分类数据,可以通过结果与分类标签对比来计算准确率。 实验选择PCA 降维算法加K-means 聚类算法、基于欧式距离的降维算法加K-means 聚类算法与本文的EN-PCA 降维算法加GKA++聚类算法的组合互相对比聚类结果,以此来验证EN-PCA 算法的有效性和效率,验证结果均已给出。 如图4 所示,算法聚类纯净度随着样本数的增加而缓慢减少。可以看到,数据量对算法的影响并不大,其中PCA 降维后对聚类的效果最差,对后续聚类操作影响最大,而EN-PCA 算法和GKA++算法均可以获得较好的聚类纯净度。 Fig.4 Effect of sample number on P(C) value图4 样本数对P(C)值的影响 Fig.5 Effect of sample number on E(C) value图5 样本数对E(C)值影响 图5 显示了聚类熵随着样本数增加的变化情况,聚类熵越接近0,则表示聚类簇越均匀分布。从实验图可以看到EN-PCA 与GKA++算法的组合随着数据量的增加,E(C)值始终在Euclid 和K-means,PCA 和K-means 算法之上,表现了良好的降维和聚类的稳定性,并且由于GKA++算法的全局能力,E(C)值随着数据量的增加而保持稳定。 如图6 所示,实验图表示的是特征数对聚类纯净度的影响,可以看到在高维数据下,EN-PCA 算法随着特征数的增加并没有出现明显的下滑,保持了对高维数据降维和聚类的有效性。 Fig.6 Effect of feature number on P(C) value图6 特征数对P(C)值的影响 图7 也揭示了随着特征数的增加E(C) 在ENPCA 和GKA++算法上影响最小。可以看到,由于维灾的影响,Euclid 算法随着特征数的增加,聚类效果呈大幅下滑。 如图8 所示,折线图显示了当特征数量变化时,降维后再聚类结果的准确率。从图中可以看到,随着特征数的上升,EN-PCA 和GKA++算法、PCA 和Kmeans 算法与Euclid 和K-means 算法的准确率都有所下降,但是由于EN-PCA 算法是针对聚类的降维,因此准确率一直居于首位。 Fig.7 Effect of feature number on E(C)value图7 特征数对E(C)值的影响 Fig.8 Effect of feature number on accuracy图8 特征数对准确率的影响 从图9 可以看出,样本数的增大对聚类的准确率有很大的影响。EN-PCA 算法与GKA++算法的组合具有很高的准确率,但是随着样本数的增加准确率也有所下降,Euclid 与K-means 算法由于算法的缺陷导致随着样本数的增加,准确率急剧下降。 Fig.9 Effect of sample number on accuracy图9 样本数对准确率的影响 图10 显示了当特征数量上升的时候,CPU 运行时间的变化情况。从中可以看到EN-PCA 算法的运行时间比PCA 算法的运行时间会多一些,并且都随着特征数量的增加而持续上升,其中Euclid 算法的运行时间随着特征数量的增加运行时间呈指数上升。 Fig.10 Effect of feature number on CPU runtime图10 特征数对CPU 运行时间影响 综上所述,样本数量和特征数量都对聚类结果产生了很大的影响。本文提出的EN-PCA 算法和GKA++算法在聚类纯净度和聚类熵的标准下,实验表现要优于其他两个算法组合。由于EN-PCA 算法在标准中引入了信息熵的降维标准,使得算法在样本数增加和特征数增加的情况下依然可以保持良好的降维效果,同时GKA++聚类算法消除了遗传聚类算法在种群初始化、选择、变异等操作的问题,并且有更好的聚类效果。 随着新技术层出不穷的发展,高维数据越来越成为聚类算法的难点,本文针对高维数据聚类将经典的PCA 算法中方差最大化标准改为E-VAR 标准,提高了降维的准确性,使降维后数据能更好地聚类。同时针对降维后数据线性组合参数过多的问题,本文提出了基于岭回归的稀疏算法,对约束采用梯度下降法求解,使其可解释增强。最后在遗传算法的基础上,针对收敛问题提出了新的聚类算法,该算法为以后应用遗传算法聚类提供了参考。

6 实验



7 结束语
猜你喜欢
车主之友(2022年4期)2022-08-27
军民两用技术与产品(2022年1期)2022-06-01
计算技术与自动化(2022年1期)2022-04-15
汽车实用技术(2022年4期)2022-03-07
海峡姐妹(2019年12期)2020-01-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
世界知识画报·艺术视界(2017年7期)2017-07-27
今日中国(2017年3期)2017-03-31
中国水运(2016年11期)2017-01-04
电脑知识与技术(2016年27期)2016-12-15
