
HEVC帧内预测算法加速设计与实现
2020-01-14 06:33王飞龙刘新闯辛晓斐石鹏飞
计算机应用与软件 2020年1期
王飞龙 刘新闯 刘 鹏 辛晓斐 石鹏飞
1(西安邮电大学电子工程学院 陕西 西安 710121)2(西安邮电大学计算机学院 陕西 西安 710121)
0 引 言
近年来,随着高清和超高清视频的发展,视频应用已经转向了数字视频广播、移动无线视频、远程监控和便携式摄影等的应用。文献[1]中阐明了高分辨率和多样性逐渐成为了视频应用的发展趋势,海量的数据处理对视频编码提出了高要求。文献[2]中指出了随着超大规模集成电路的发展,半导体工艺的进步为新型的数字媒体作出了巨大的贡献。在一个芯片内集成多个处理器成为了可能,为处理具有海量的数据像素,计算量繁琐的HEVC算法提供了新的思路。
在帧内预测并行化的过程中,国内外的众多研究人员和学者提出了不同的方法。文献[3]建议将序列划分为一些GOP。GOP之间的相关性很低,它不仅可以限制错误传播,还可以支持并行编码处理。但是,它需要在并行之前获取GOP中所有图片的数据。当GOP图片太多时,会导致严重的延迟,这对于实时视频编码应用来说并不方便。文献[4]提出在帧级实现并行编码。这种方法局限于帧之间的相关性,因此加速比不能随着处理器核的数目增加而线性增加。文献[5-6]提出将宏块(MB)的预测、变换和熵编码组织为流水线并将它们分配给多个核,以进行并行计算。如果工作负载在不同处理核处不平衡,则这类方法可以实现有限的并行性。在文献[7]中,通用四核计算机上的高清晰度序列提高了两倍的速度。
尽管在并行化方面现有编码算法做了很多努力,但由于帧内预测中的块之间的强依赖性以及顶部/左侧重建样本的滤波过程,小块的帧内亮度预测过程是一个挑战。原始进程处理串行块,效率不高。在文献[8-9]中已经说明了有效的体系结构,其建议以波前序列对MB进行处理,以便当相邻的MB可用时,可以同时对每条对角线中的MB进行编码。由于MB级别的细粒度并行性,这些方法可以实现良好的并行性,目前被广泛使用。
上述提出的方法均提高了帧内预测算法的执行效率。本文通过分析帧内预测算法在处理像素过程中数据之间的依赖关系,将帧内预测算法进行基于预测模式的细粒度并行性设计,并且块与块之间采用流水线处理,在保持失真率较低的前提下,减少了帧内预测算法的执行时间,显著地加速了帧内预测算法。相比于HM16.0官方测试标准,信噪比提高了10%,算法的执行时间减少了大约70%。
1 帧内预测算法分析
1.1 HEVC中的空域预测
HEVC是由JCT-VC(视频编码联合协作小组)在2013年提出的一种新的视频压缩标准,它是H.264的一个扩展。相比于H.264,它可以在保证相同视频质量的前提下,压缩效率提高50%,但是算法复杂度也随之提高。文献[10]指出了关于高效视频编码的部分内容已经被运用到HEVC测试模型(HM)中。帧内编码的主要改进来自如下两个工具。
1.1.1帧内预测
文献[11]指出了对于不同的尺寸大小,帧内预测支持16到34个预测方向,并且可以实现1/8像素精度。通过指示预测角度,允许在任意方向上进行块预测,从而显著提高了编码效率。
1.1.2基于四叉树的编码结构
利用尺寸大于16×16像素的宏块结构可以显著提高编码效率,特别是在高分辨率的序列中。为了实现更灵活的编码方案,HEVC利用基于四叉树的编码结构[12],支持尺寸为64×64、32×32、16×16、8×8和4×4像素的宏块。
HEVC分别定义了三个块概念:编码单元(CU),预测单元(PU)和变换单元(TU)。在定义了最大编码单元(LCU)的大小和CU的分层深度之后,编解码器的整体结构以递归方式由CU、PU和TU的各种大小来表征。这允许编解码器容易地适用于具有不同能力的各种内容、应用或设备。CU分裂过程如图1所示,使用分裂标志来确保当前CU是否需要分割成更小的尺寸。
1.2 HEVC帧内算法的并行性分析
HEVC帧内预测算法规定一帧图像可以被划分为N×N(N=4,8,16,32,64)的块处理。对每种N×N块进行处理时,首先对参考像素进行滤波,运用滤波完成后的像素,遍历35种模式,分别得到每种预测模式下所对应的预测像素。运用下式求取残差值,并计算SAD值:
Diff(i,j)=BlockA(i,j)-BlockB(i,j)
(1)
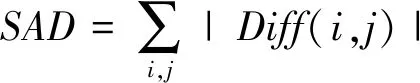
(2)
式中:BlockA(i,j)是原始像素块,BlockB(i,j)是预测像素块。
判断比较35个SAD值,选取最小SAD值,将此SAD值对应残差块传递给下一个模块DCT变换。对于一个N×N的块,在预测过程中,plannar模式、DC模式、33种角度模式均是利用参考像素进行计算,得到预测像素,而且plannar模式、DC模式、33种角度模式之间并不存在数据的依赖关系,彼此独立计算,所以是可以并行计算的。
2 动态可编程可重构视频阵列处理器
本文所用的验证平台是动态可编程可重构视频阵列处理器,它支持H.264/AVC、H.265/HEVC视频编码标准,还有并行度高的算法。它由1 024个PE(processor element)组成,可以完成海量的数据处理,不管是在空间上还是在时间上,都实现了并行。如图2所示,整个系统平台由三个部分组成。
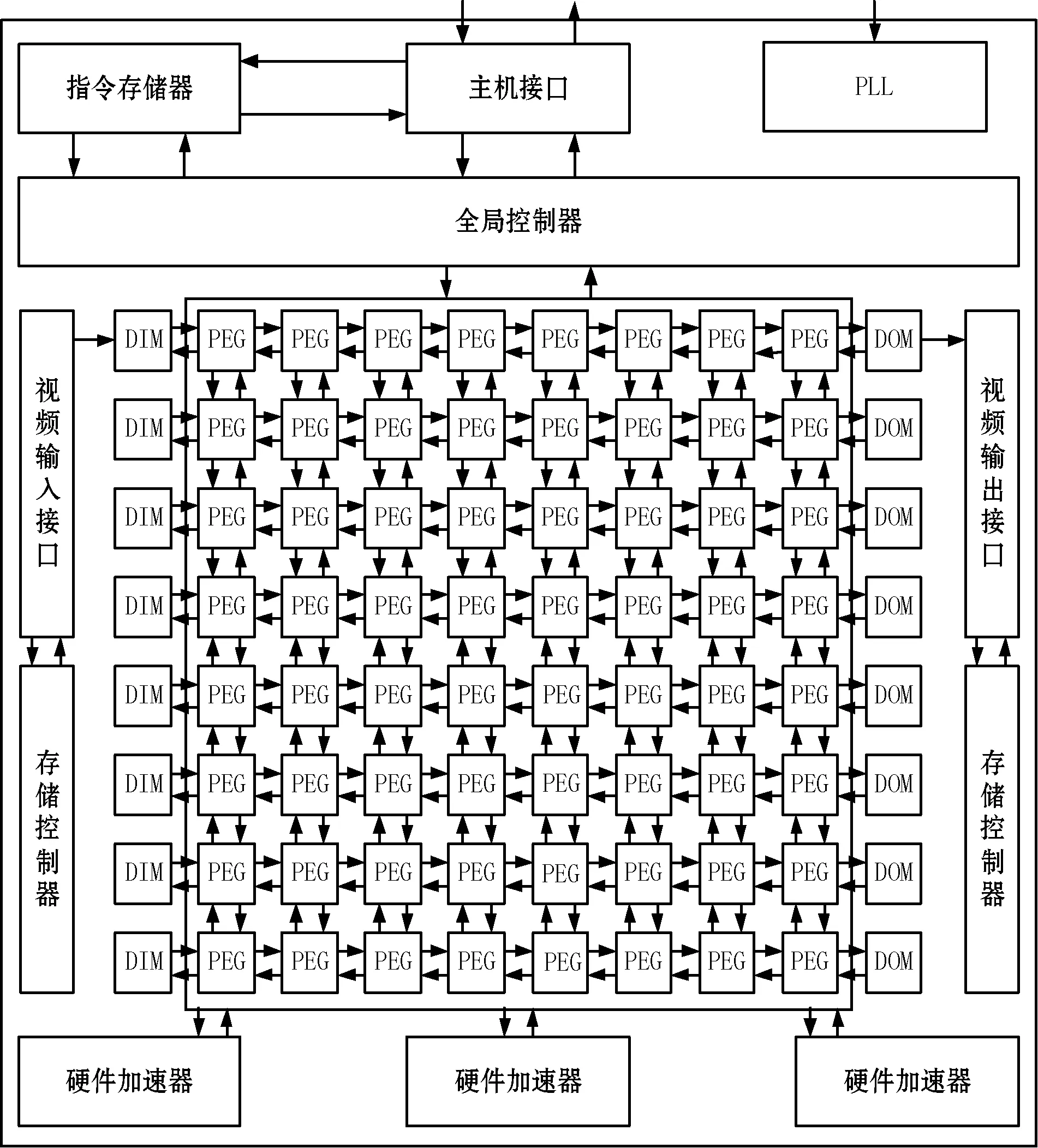
图2 动态可编程可重构视频阵列处理器结构图
2.1 轻核处理单元
阵列处理器由1 024个PE(processor element)组成,每16个PE在逻辑上划分为一个PEG(processor element group),共有64个PEG。每个PE由16个通用寄存器组成,可以支持算术、逻辑运算,分支跳转指令,用于视频像素点的计算。
2.2 互连机制
PE之间进行通信所用的机制是邻接互连,邻接互连采用2D-mesh结构,运用四个共享寄存器,完成相邻PE之间的数据交互。图3展示了邻接互连结构,有两种数据交互方式,分别用实线和虚线表示。在PEG之间,通过路由进行通信。
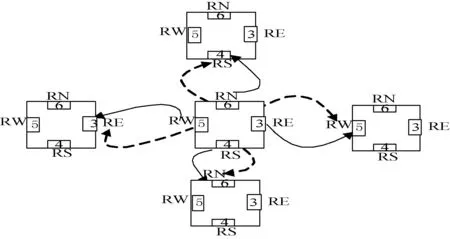
图3 邻接互联数据交互图
2.3 存 储
每个PE内部包含512×32 bit指令存储器,数据存储器,将每个PE的数据存储器统一编址,运用所设计的交叉开关逻辑,可以在一个PEG内,任意的PE可以对其他的PE进行访问,使得在一个PEG内实现存储共享。
3 算法的并行映射及块间处理
3.1 帧内预测算法并行映射
文献[15]阐述了在HEVC测试模型HM中,uiRd Mode List数组中排名第一的预测模式和MPM(Most Probable Mode)中的预测模式被选择的概率是非常大的。本文统计了在不同的测试序列下以及不同的CU划分下uiRd Mode List数组中排名第一的预测模式和MPM(Most Probable Mode)中的预测模式,结果显示,平面模式0、DC模式1、水平预测模式10、垂直预测模式26、角度模式18、角度模式22为被选中概率最大的6种模式。所以本文选取了这六种模式作为帧内预测算法中的模式。
图4给出了帧内预测并行算法的流程图,主要包括三个部分:参考像素以及原始像素的获取;6种模式的计算;判断SAD值并进行最优模式的选取。图5是所设计的帧内预测并行算法在阵列处理器上的映射图。处理过程包括三个部分:数据加载;预测计算;最优模式的选取。
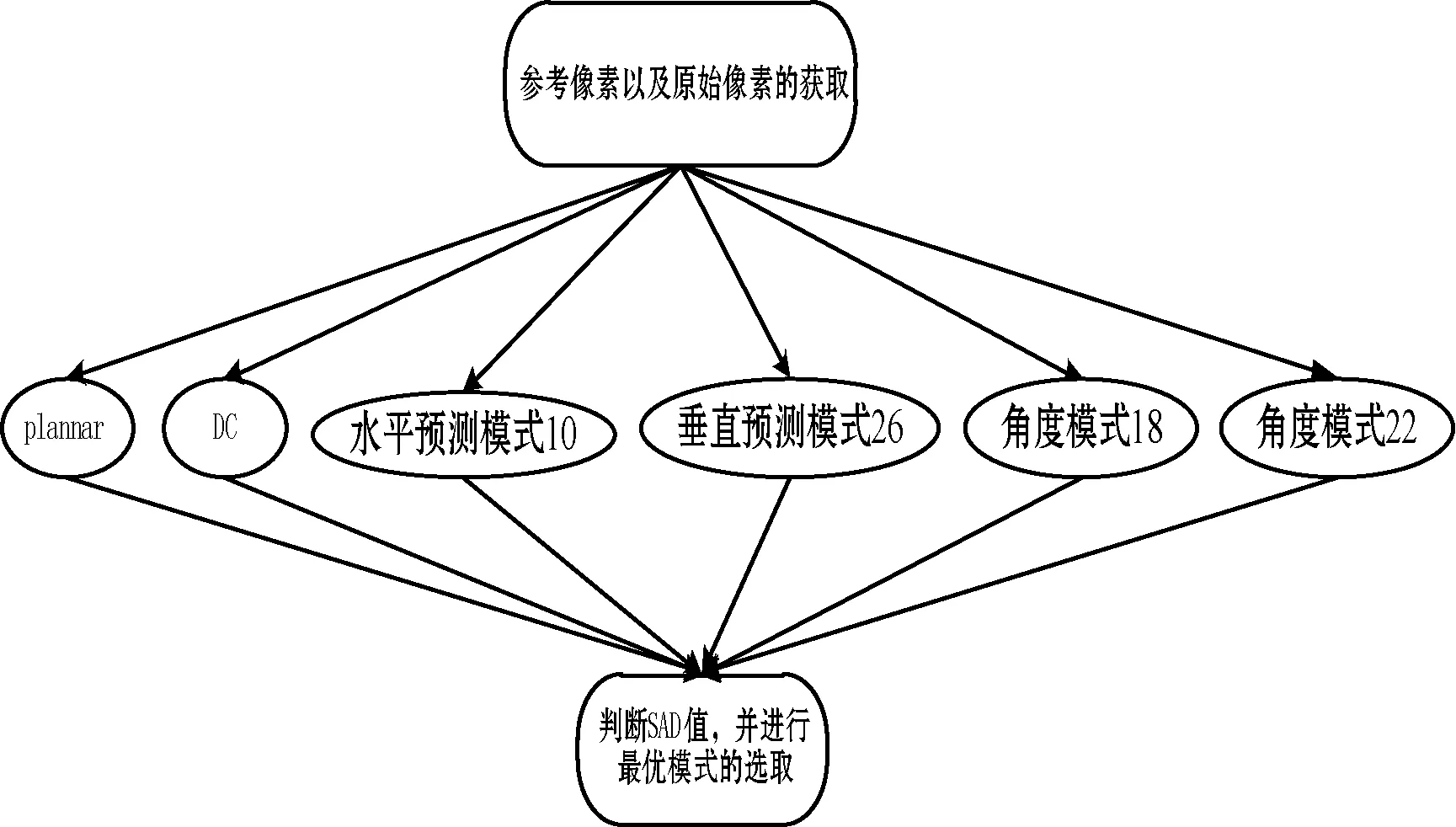
图4 帧内预测并行算法的流程图
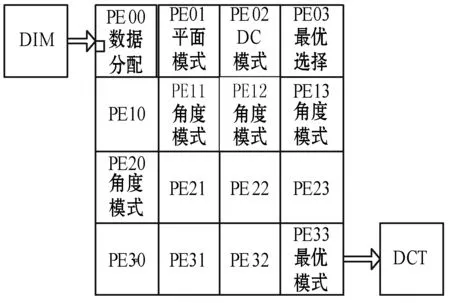
图5 帧内算法映射图
3.1.1数据加载
本文以8×8块为例进行说明。如图6所示,在DIM中存入一帧图像的像素,运用邻接互连指令,每次从DIM中取出97个像素,包括64个原始像素,以及原始块左上方的33个参考像素。存入PE00数据存储器中,运用共享存储指令,将PE00中数据存储器中的97个像素加载到PE01、PE02、PE11、PE12、PE13、PE20的存储中,加载完成后,在PE01、PE02、PE11、PE12、PE13、PE20数据存储中的固定地址存入一个确定的值,用来表示数据存储已完成。

图6 邻接互联数据交互图
3.1.2计算预测像素
在PE01、PE02、PE11、PE12、PE13、PE20中,读取各自存储中已存入的确定值,比较相等后,说明参考像素已经存储到相应的PE存储中。分别在各自的PE中处理平面模式、DC模式、角度模式中的26、10、18、22号模式,从而得到不同预测模式下的64个预测像素。运用式(1)、式(2)得到不同的模式下的SAD值、残差值,并存入PE03的数据存储中。最后,在PE03的数据存储中写入一个确定值,表示数据SAD值已经存入完成。
3.1.3选取最优模式
在PE03中读取已经存入的确定值,比较相等后,说明SAD值、残差值已经存入到PE03中。然后比较每种预测模式下的SAD值大小,选出最小值,此模式作为最优预测模块,将残差值存入PE33中,通过邻接互连指令,输出给下一级的DCT模块。
3.2 帧内预测算法的块间流水处理
运用视频阵列处理器多核并行处理的优势,通过邻接互连机制结合比较跳转指令,可以将任务组织为串行的形式进行处理。在上述处理8×8块的例子中,计算预测模式运用数据加载模块的结果,最优模式的选取运用计算预测像素模块的结果,均存在数据依赖关系。本文通过共享存储指令结合与比较跳转指令,使数据加载模块,计算预测像素,选取三个模块反复执行,将块与块之间组织为流水线处理。
图7为块与块之间进行流水处理的示意图,横坐标代表时间,纵坐标代表所用的PE资源。块的加载时间为T1,计算预测模式T2,最优模式的选取T3,并且T1>T2>T3,从而保证每个块正确执行。在第一个T1时间段内加载第一个块;在第二个T1时间段内加载第二个块,同时计算第一个模块的预测像素;在第三个T1时间段内加载第三个块,同时计算第二个模块的预测像素,并且选取第一个块的最优模式;在第四个T1时间内可以得出第二个块的最优预测像素。照此执行直到一帧图像中的所有块被处理完。
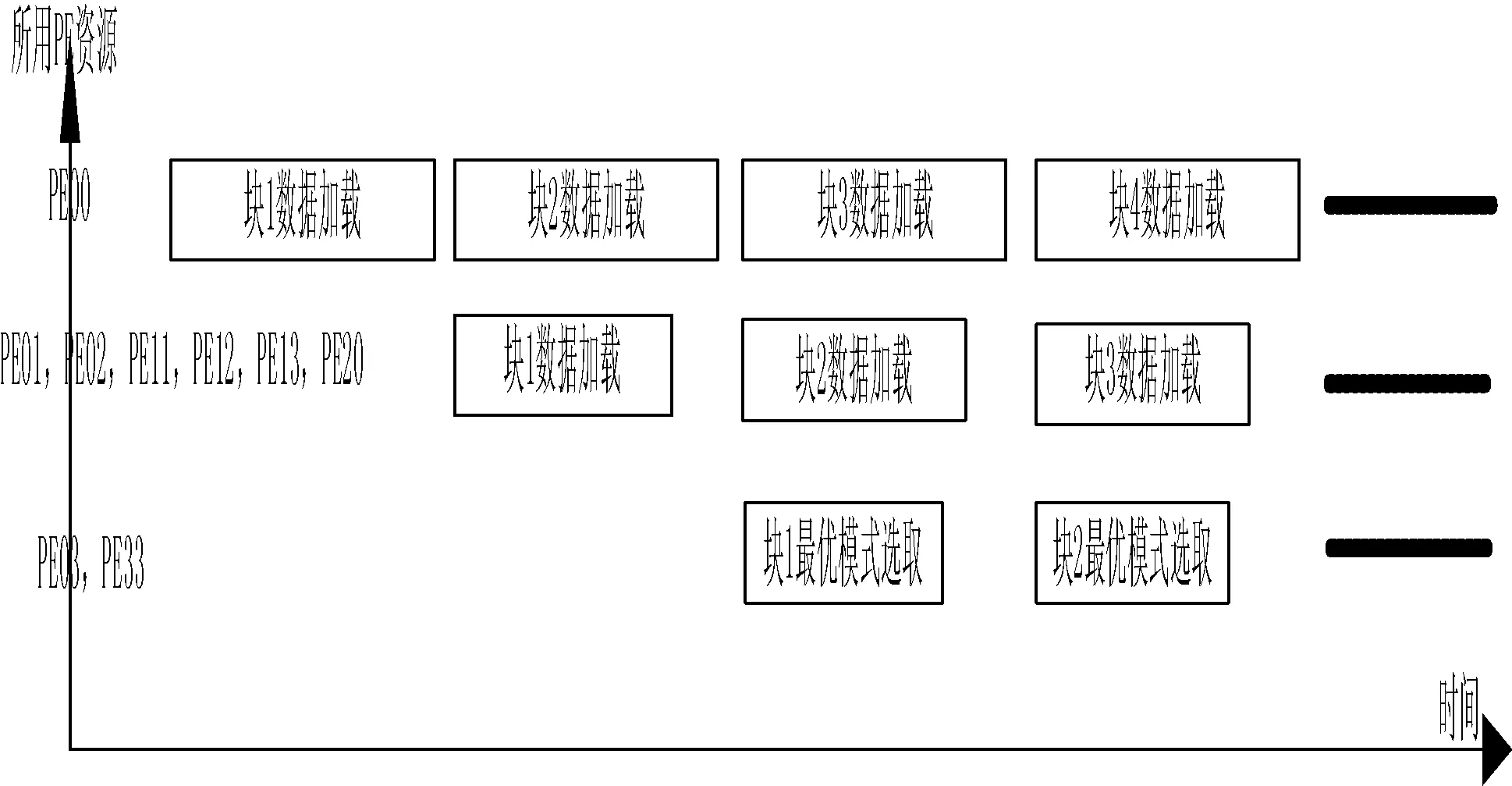
图7 块与块之间进行流水处理的示意图
4 实验分析
文献[14]规定了帧内、帧间预测的配置以及测试序列类别。为了使得所选的测试序列具有代表性,实验选取了(class A,class B,class C,class D,class E)不同分辨率下的两种序列来验证所提出的帧内预测并行算法。
阵列处理器实验平台是运用verilog HDL搭建的,运用Synopsys公司的DC(designcompiler)工具,在SMIC90nm工艺库下进行综合。表1给出了一个PEG的综合结果。

表1 一个PEG的综合结果
将表2中的10种测试序列分别存入到DIM中,对并行设计的帧内预测算法进行评估。
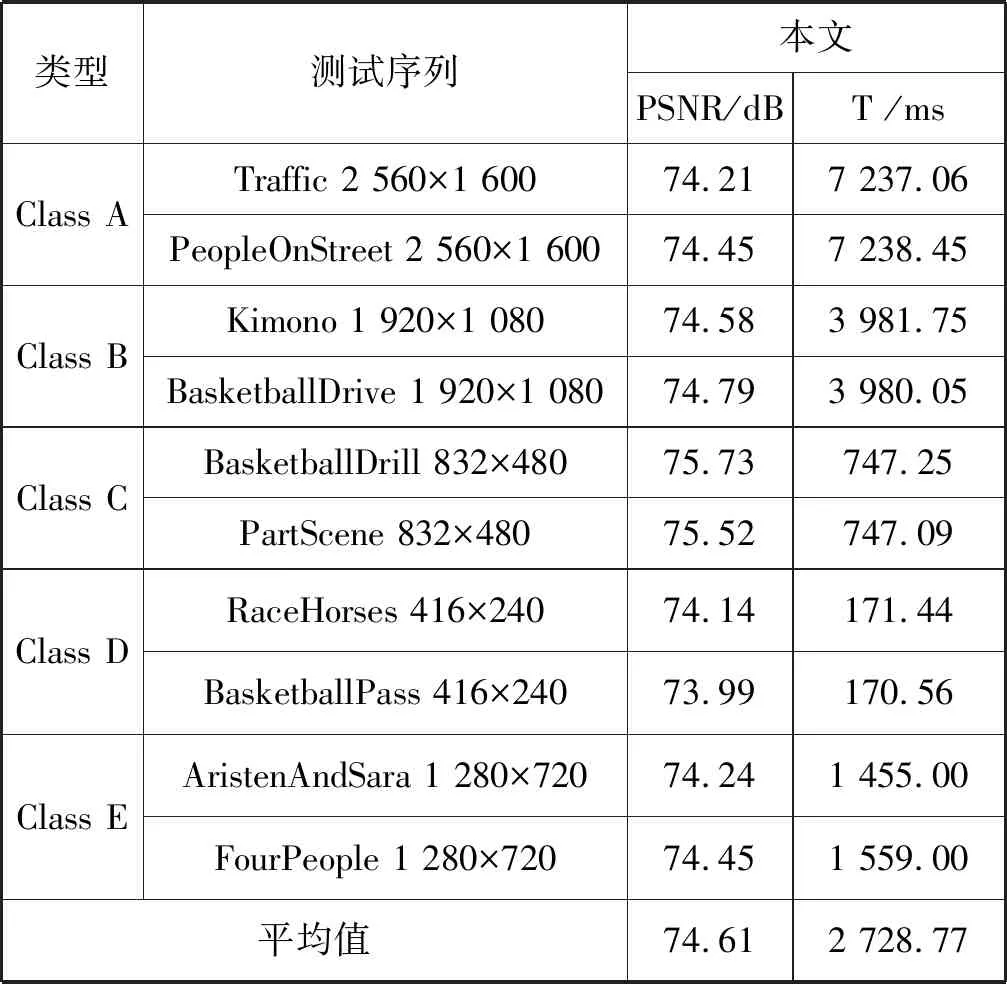
表2 本文设计的并行算法性能统计
信噪比PSNR的计算公式如下:
(3)
(4)
式中:m、n代表图像像素为m×n;I、K分别代表原始图像和处理完成后的图像;Kmax表示图像处理完成后,m×n个像素中像素最大的值。统计原图像与处理图像像素I和K,计算得到每种测试序列下的PSNR。
在modelsim10.0c软件下统计所用的时钟周期数n,除以综合频率,得出每种测试序列下的运行时间T。
T=t/f
(5)
式中:n为帧内预测算法所用的时钟周期数;f表示综合频率。
实验环境为intel(R)Core(TM)i5-8400 CPU@2.80 GHz,内存为16 GB。运用HM16.0软件,分别测试上述10种序列,得出帧内预测算法的运行时间T,信噪比PSNR,如表3所示。

表3 HM16.0性能统计
THM、Y_PSNRHM分别为HM软件所得出的时间和信噪比,Tpro、Y_PSNRpro分别为本文所设计的并行算法的时间和信噪比,则:
(6)
(7)
如表4所示,本文所提出的并行算法相比于官方HM16.0测试软件,平均ΔY_PSNR提高了大约10 dB,平均ΔT减少了74.20%。在相同的HM16.0测试环境下,实验对比结果如表5所示,用本文算法的平均ΔT减去文献[13]、文献[16]、文献[17]算法的ΔT,分别比文献[13]、文献[16]、文献[17]算法多减少了24.20%、34.28%、41.78%。由此可见,本文所提出的方案对HEVC帧内预测算法实现了显著的加速效果。
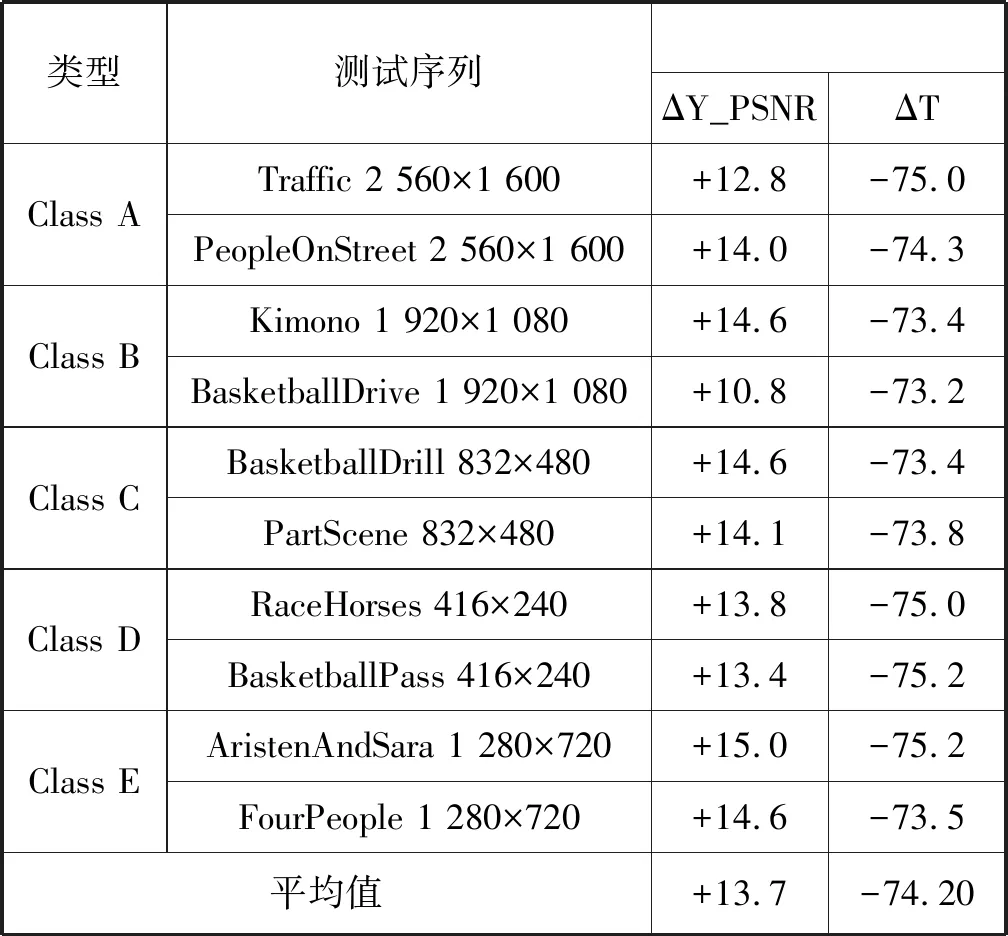
表4 不同测试序列下相比于HM16.0的结果 %

表5 实验对比结果 %
5 结 语
本文通过对HEVC帧内预测算法的处理流程进行分析,挖掘出数据之间的依赖性,将帧内预测算法进行了基于预测模式的细粒度并行设计,并且块与块之间采用流水线进行处理,在视频阵列处理器上进行映射。运用10种测试序列进行验证,结果显示,相比与HM16.0官方测试软件,在时间上减少了74.20%,信噪比增加了10 dB,有了显著的加速效果。本文从算法分析的角度对帧内预测算法进行并行性的设计,相比于块、图片组的粗粒度并行算法,本文提出了一种细粒度的并行方法,在块与块之间进行流水技术,对帧内预测算法实现了显著的加速。邻接互连的数据交互时间、共享存储的访问时间,都会影响PE之间数据的通信效率。对这两种机制进行改进,帧内预测算法的执行时间和图像的失真率将会进一步减少,对视频的实时性处理有很大的帮助。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
小学生学习指导(中年级)(2021年12期)2021-12-30
速读·下旬(2021年11期)2021-10-12
昆明医科大学学报(2021年4期)2021-07-23
大东方(2019年12期)2019-10-20
红领巾·萌芽(2019年8期)2019-08-27
疯狂英语·新读写(2018年3期)2018-11-29
科学与财富(2017年22期)2017-09-10
商情(2017年1期)2017-03-22
CHIP新电脑(2016年3期)2016-03-10
