
ALICE:一种面向中文科技文本分析的预训练语言表征模型
2020-02-19 11:26王英杰李宁波
计算机工程 2020年2期
王英杰,谢 彬,李宁波
(中国电子科技集团公司第三十二研究所,上海 201808)
0 概述
近年来,网络已经成为科研人员获得信息的重要渠道。由于网络中科技文献的数量飞速增长,因此亟需一种能自动分析大量科技文献并抽取有价值信息的自然语言处理工具。随着深度学习的快速发展,其在自然语言处理领域得到广泛应用[1],该领域的相关研究也取得了重大进展。然而,深度学习本身的局限性使得模型在训练时需要大量人工标注的数据集[2]。对一般领域而言,通过一些众包平台可以得到大量带标签的数据集,且获取方式比较简单,但是对于科技、医疗、军事等特殊领域,由于数据可能涉及不同层面的专业知识,标注数据需要专家的参与,因此数据集的获取难度较大且成本较高。
以BERT[3]为代表的预训练方法降低了模型对大型数据集的依赖性,其在多种自然语言处理任务中的表现均超越了ELMo[4]和GPT[5]方法。由于这些模型都是针对通用语料进行训练,因此在一些通用领域的自然语言处理任务中可以获得较好的效果。但是科技、医疗等专业领域存在大量专有名词,这些专有名词的词义与通用领域大不相同,模型对某些词的理解可能会出现偏差,进而影响模型决策的准确性[6-7]。
本文提出一种面向中文科技文本分析的预训练模型ALICE。在BERT模型的基础上对大量科技语料进行预训练,利用迁移学习得到的语言表征改善模型在小数据集上的自然语言处理性能。
1 相关工作
1.1 预训练模型
针对语言表征预训练的研究工作已经进行了数十年,从传统密集分布的非神经词嵌入模型[8]到基于神经网络的Word2Vec[9]和GloVe[10],这些工作为自然语言理解任务提供了一种初始化权值的方法,对模型的表现有明显的提升作用[11]。Word2Vec通过对前后n个词的依赖关系建模,学习词毗邻出现的概率,GloVe使用词共现矩阵学习更广泛的共现概率。CoVe[12]利用神经翻译的编码器在词嵌入中添加含有上下文背景的表征向量,使模型学习上下文背景化的语义。
ELMo[4]未采用这种传统的学习静态词向量的方法,其在大量语料中训练一个双向神经语言模型(bidirectional Neural Language Model,biNLM),通过该模型从语料集中抽取词汇在不同语境下的含义。OpenAI GPT[5]使用多层Transformer[13]解码器加强模型对上下文背景知识的感知能力。BERT使用多层Transformer编码器学习词汇前后的语义依赖关系,并通过遮罩语言模型(Mask Language Model,MLM)解决BERT的输入在多层Transformer结构中的“镜像问题”。文献[14]提出知识融合与对话语言模型的概念,针对中文通用领域的自然语言处理任务对BERT进行优化,得到ERNIE模型。
1.2 迁移学习
在自然语言处理领域,数据量最多的是无标签数据,在大量无标签的数据集上训练模型可以提高有监督任务的表现[15]。Skip-Thought[16]使用迁移学习方法通过上下文语句的向量预测输出内容,CoVe[12]从机器翻译任务中抽取知识并将其成功迁移至其他自然语言理解任务中。
深度学习模型需要数量庞大的人工标注数据[17],很多领域由于缺乏人工标注的数据资源,模型的表现受到限制。对于小数据集的自然语言处理任务,文献[18]提出一种高效的迁移学习方法,以缓解数据不足的问题。对于一些特殊的领域,如生物医疗,研究者直接从大量的生物医疗语料中抽取信息,并将其用于其他相关的自然语言处理任务中,以提高模型的表现[19-20]。即使在拥有大量有标签数据的情况下,也可以利用从大量语料中迁移学习得到的知识训练词表征,提升模型的表现[9]。
1.3 BERT预训练方法
BERT通过对语言模型进行无监督预训练,抽取出大量的语义知识,将这些知识迁移到其他自然语言处理任务中,不仅可以提高模型的表现,而且对于小数据集的任务有较好的效果。
BERT采用双向Transformer结构,通过放缩点积注意力与多头注意力直接获取语言单位的双向语义关系,其信息获取的准确性优于传统的循环神经网络(Recurrent Neural Network,RNN)模型和正反向RNN网络直接拼接的双向RNN模型。此外,BERT将输入词的15%按一定规则进行遮罩(Mask),通过训练语言模型进行预测,从而抵消“镜像问题”的影响。然而,语言模型无法学习到句子间的关系,为了解决这一问题,BERT引入下句话预测(Next Sentence Predicts,NSP)机制。在预训练后,BERT无需引入复杂的模型结构,只需对不同的自然语言处理任务进行微调并学习少量新参数,即可通过归纳式迁移学习将模型用于源域与目标域均不相同的新任务中。需要说明的是,BERT模型对100多种语言进行了预训练,而本文主要针对中文进行自然语言处理,因此,若没有特殊说明,下文出现的BERT均指针对中文语料训练的BERT-Chinese。
2 ALICE文本分析模型
本文ALICE文本分析模型主要从词语遮罩语言模型、命名实体级遮罩、Transformer编码器、预处理方法和预训练语料5个方面进行介绍。
2.1 词语遮罩语言模型
英文中单词(word)是可以表达具体意思的最小单位,与英文不同,在中文里,由两个或者两个以上的字(character)组成的词语(phrase)才是表达具体意思的最小单位。BERT对CJK Unicode范围内的每个字添加空格,并且使用WordPiece对句子进行分字(tokenize),将句子拆成不连续的字后作为Transformer的输入。这种方法虽然提高了模型对不同语言的适应能力和处理能力,但是削弱了对于中文这种以词语为最小语义单位的语言的语义表达。针对上述问题,本文对BERT的中文输入方式进行改进,将整个词语作为输入,并以词语为最小语言单位,选取15%的词进行类似于BERT中遮罩、替换和保持不变的操作,如图1所示。经过这种词语遮罩预测任务的训练,模型可以学习到更丰富的语义关系。

图1 BERT、ERNIE、ALICE输入方式的比较
Fig.1 Comparison of the input modes of BERT,ERNIE and ALICE
由于中文的字和词语数量庞大,为了降低训练时的内存开销,需要对词汇表进行筛选,选取53 494个常用词作为ALICE的词汇表,对于一些词汇表中没有出现的词语(OOV问题),需对其进行分字处理。
2.2 命名实体级遮罩
ERNIE[14]模型中引入了命名实体级遮罩的概念,对BERT模型的遮罩方式进行修改,ERNIE以命名实体为单位,选择连续的输入字进行遮罩,其遮罩形式如图1所示,这种连续的遮罩方式使模型的自然语言处理效果更好。
在ALICE模型中,由于词汇表只覆盖一部分常用的中文词语,一些命名实体、新词等并没有出现在词汇表中。因此,本文借鉴ERNIE的方法,使用命名实体级别的遮罩方式来弥补分字处理的不足,让模型学习到的语言表征包含更丰富的语义关系。引入命名实体级遮罩后,ALICE与ERNIE输入方式的对比如图2所示。

图2 ALICE和ERNIE的输入方式对比
Fig.2 Comparison of the input modes between ERNIE and ALICE
2.3 Transformer编码器
ALICE与BERT的结构类似,都使用多层Transformer编码器,通过多头自注意力层捕捉句中每个词的上下文信息。对于一个给定字,Transformer将该字在词汇表中的位置、分句的位置以及与其他字的相对位置相加,以获得该字的输入表示。对Transformer的输入方式进行修改后,ALICE模型的输入如图3所示。其中,E代表嵌入,I代表输入。

图3 Transformer输入方式
2.4 预处理方法
对于需要进行预训练的句子,用[CLS]表示句子的开端,以[SEP]充当逗号对句子进行分割。如前文所述,本文未使用BERT的WordPiece分词方法,而是使用pkuseg[21]进行分词操作,然后在每个词的周围添加空格。pkuseg分词工具与THULAC、jieba相比拥有更高的F1值,在多种数据集上的平均F1值分别比THULAC、jieba高出3.21%和9.68%。
2.5 预训练语料
科技预训练语料集包括约80万篇文章,其中60万篇来自百度百科、微信公众号以及各领域期刊论文,其余的20万篇来自各大门户网站的相关文章。计算机、生物科技、军事科技、空间科技的文章分别占50%、20%、20%和10%。语料集少部分期刊论文为全文,大部分仅包含摘要部分。为了防止广告、推荐阅读列表、网站链接等与文章无关的噪音文字干扰模型的训练,需要对语料进行彻底的清洗,以保证其质量。此外,预训练语料还包括BERT所使用的维基百科中的100多万篇中文文章。表1统计了该语料的详细信息,需要注意的是,由于预处理时对新词、连词进行了分字处理,在统计词数时需将这些特殊词丢弃,因此统计数值与实际数值略有偏差。
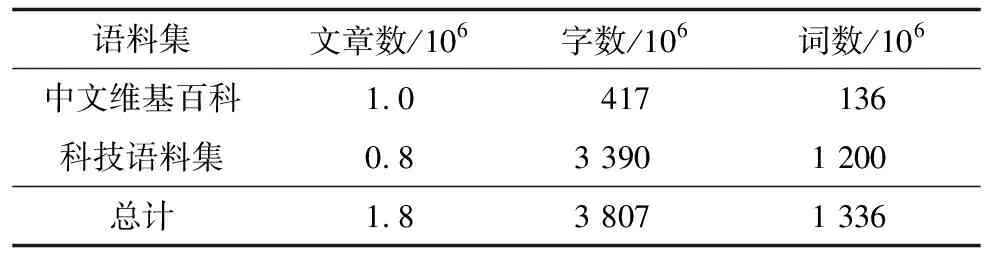
表1 预训练语料详细信息
3 实验结果与分析
为了方便比较,ALICE与BERT-Chinese使用同样的模型结构,其中包含12个编码器层、768个隐层单元和12个注意力头。本文主要在3个自然语言处理任务中,比较本文方法与BERT、ERNIE方法的性能。需要说明的是,除文本分类任务外,其他任务都采用BERT[3]中的微调方法。
3.1 中文自然语言处理任务
本文的中文自然语言处理任务主要包括文本分类、命名实体识别和自然语言推断。
3.1.1 文本分类

本文使用的文本分类数据集共包含8 000个人工标注的文本,其中生物科技、空间科技、军事科技、高新科技相关文章各1 500篇,其他6个领域的文章共2 000篇。将其中6 000篇文章作为训练集,1 000篇作为开发集,剩下的1 000篇作为测试集。
3.1.2 命名实体识别
命名实体识别数据集包括5 000条人工标记数据,其采用BIO标注策略,实体设计的范围包括生物、空间、军事、高新技术4个科技领域的人名、地名、组织名和其他专有名词。在该数据集中,将4 000条数据作为训练集,其余数据平均分配给开发集和测试集。
3.1.3 自然语言推断
自然语言推断任务的目的是判断两句话之间是否存在蕴含、中立和矛盾关系。为了证明ALICE在通用领域和大数据集上的自然语言推断性能,本文在XNLI[23]的中文数据集上进行实验,详细信息如表2所示。
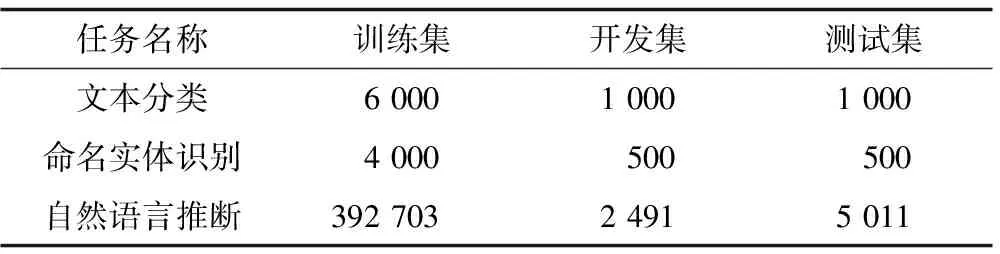
表2 3种任务数据集的数据量
3.2 SOTA模型
为了证明经过微调的ALICE模型性能优于其他具有复杂结构的模型,本文分别选取在上述中文自然语言处理任务中取得SOTA(State Of The Art)的模型进行比较。例如,文本分类任务的SOTA模型选取RMDL[24],命名实体识别任务选取MSRA中文数据集的Lattice LSTM模型[25],自然语言推断选取XNLI多语言数据集上的LASER模型[26]。由于RMDL与Lattice LSTM需要词嵌入层来初始化模型权值,因此需在科技语料中训练200维的GloVe词向量作为RMDL的词嵌入矩阵。对于Lattice LSTM,本文采用文献[25]提供的50维Chinese Giga-Word和Word2Vec词嵌入矩阵。
经测试可知,RMDL在公开文本分类数据集THUCNews中的准确率为92.3%,Lattice LSTM在MSRA命名实体识别数据集中的F1值为93.18%。THUCNews数据集包含14个类别,每个类别约63 086篇新闻,总共88万篇新闻,本文从10个类别中随机抽取10万篇作为训练集,3 000篇作为开发集,5 000篇作为测试集,具体的数据集信息如表3所示。

表3 THUCNews与MSRA数据集的数据量
3.3 结果分析
表4给出ALICE在3个中文自然语言处理任务中的性能对比,可以看出,ALICE在3个任务上的性能均优于BERT模型和针对不同任务的SOTA模型,但是在自然语言推断任务中,ERNIE的性能更好。

表4 在3个中文自然语言处理任务中的性能对比
在公开的通用数据集上,RMDL与Lattice LSTM模型(即文本分类任务和命名实体识别任务的SOTA模型)分别取得了92.3%与93.18%的优秀表现[25],但是在科技领域的任务中,其性能指标分别降低了2%与1.38%,其主要原因是本文构建的科技自然语言数据集的数据量不到上述通用领域数据集的1/5,针对这种小数据集任务,传统的深度学习模型无法发挥其优势。由于BERT模型需要在大量的通用语料上进行预训练,可以通过迁移学习获得的知识解决小数据集数据量不足的问题,因此其文本分类的准确率和命名实体识别的F1值比SOTA模型分别提升了0.5%和1.6%。
与BERT模型相比,ALICE模型通过词语遮罩语言模型与命名实体遮罩两处改进以及从科技语料预训练中学习到的专业知识,其科技文本分类准确率和命名实体识别的F1分别提高1.2%和0.8%。此外,自然语言推断任务的准确率提高了0.9%。
ERNIE针对中文进行优化,通过知识融合与对话语言模型学习更丰富的语义关系。与ERNIE模型相比,针对科技领域进行预训练的ALICE模型的科技文本分类准确率与命名实体识别任务的F1值分别提高0.5%和0.3%。在自然语言推断任务中,ALICE模型的准确率略低于ERNIE模型。
3.4 消融实验
为了证明本文改进的词遮罩语言模型能够理解更丰富的语义关系,本文从语料集中随机选取10%的数据进行消融实验,结果如表5所示。
表5 不同遮罩策略的效果对比
Table 5 Comparison of effects of different mask strategies

遮罩策略文本分类准确率/%自然语言推断准确率/%开发集测试集开发集测试集MLM90.889.993.392.1PMLM91.090.393.292.6PMLM+NERM91.390.593.993.0
由表5可知,在中文的自然语言处理任务中,ALICE的词语遮罩策略PMLM的效果优于BERT的遮罩语言策略MLM,添加ERNIE的命名实体遮罩策略NERM后效果更佳。此外,本文在10倍数据量的预训练语料上进行实验后发现,模型的文本分类准确率和命名实体识别F1值分别提高1.5%和1.2%。
4 结束语
本文提出一种针对科技领域文本处理的预训练模型ALICE。在大量科技文本上进行无监督预训练,通过改进的遮罩语言模型,使其更适用于中文的自然语言处理任务。实验结果表明,该模型在科技领域的文本分类、命名实体识别任务中的性能均优于BERT模型。下一步将通过动态遮罩对ALICE模型进行预训练,提高模型对预训练语料的利用率。
猜你喜欢
通信技术(2021年12期)2022-01-25
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
中国外汇(2019年18期)2019-11-25
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
