
基于大数据技术的推荐系统研究
2020-03-10 09:09蒙德钦张钦锋
科学与财富 2020年33期
关键词:大数据
蒙德钦 张钦锋

摘 要:大数据时代已来临,基于大数据技术的推荐系统为我们生活带来了极大的便利,根据手机APP用户的访问日志信息可以为用户推荐相对应的功能、产品和服务,使得手机APP运营商能够更高效、精准地推荐产品、服务给用户,从而达到提升用户黏性、提高营销的目的。本文以大数据推荐系统在观影APP的应用为研究基础,总结凝练出一套适合应用在电商、旅游、医疗、教育等行业的构建大数据推荐系统的经验方法,并浅析开展大数据推荐系统研究的意义,最后对优化大数据推荐系统的措施进行分析,旨在为大数据推荐系统开发者提供一些优化算法参考。
关键词:大数据,电影推荐系统,算法设计
1.前言
随着5G时代的来临,网络信息数据量大幅增长,用户在面对海量信息时无法从中获得对自己真正有用的那部分有价值的信息,使得用户对信息的使用效率反而降低了。针对上述问题,推荐系统被称为当前最具潜力的解决办法,它是根据用户的信息需求、兴趣等,将用户感兴趣的服务、产品等推荐给用户的个性化推荐系统。和搜索引擎相比推荐系统通过分析用户的兴趣偏好,进行个性化计算,由系统发现用户的兴趣点,从而引导用户发现自己的信息需求。一个好的推荐系统不仅能为用户提供个性化的服务,还能和用户之间建立密切关系,从而达到提升用户黏性、提高营销的目的。
基于大数据的推荐系统现已广泛应用于电商、旅游、交通、医疗等领域,其中最典型并具有良好的发展和应用前景的领域就是电子商务领域。同时学术界对大数据推荐系统的研究热度持续升高,现阶段已形成了一门独立的学科。
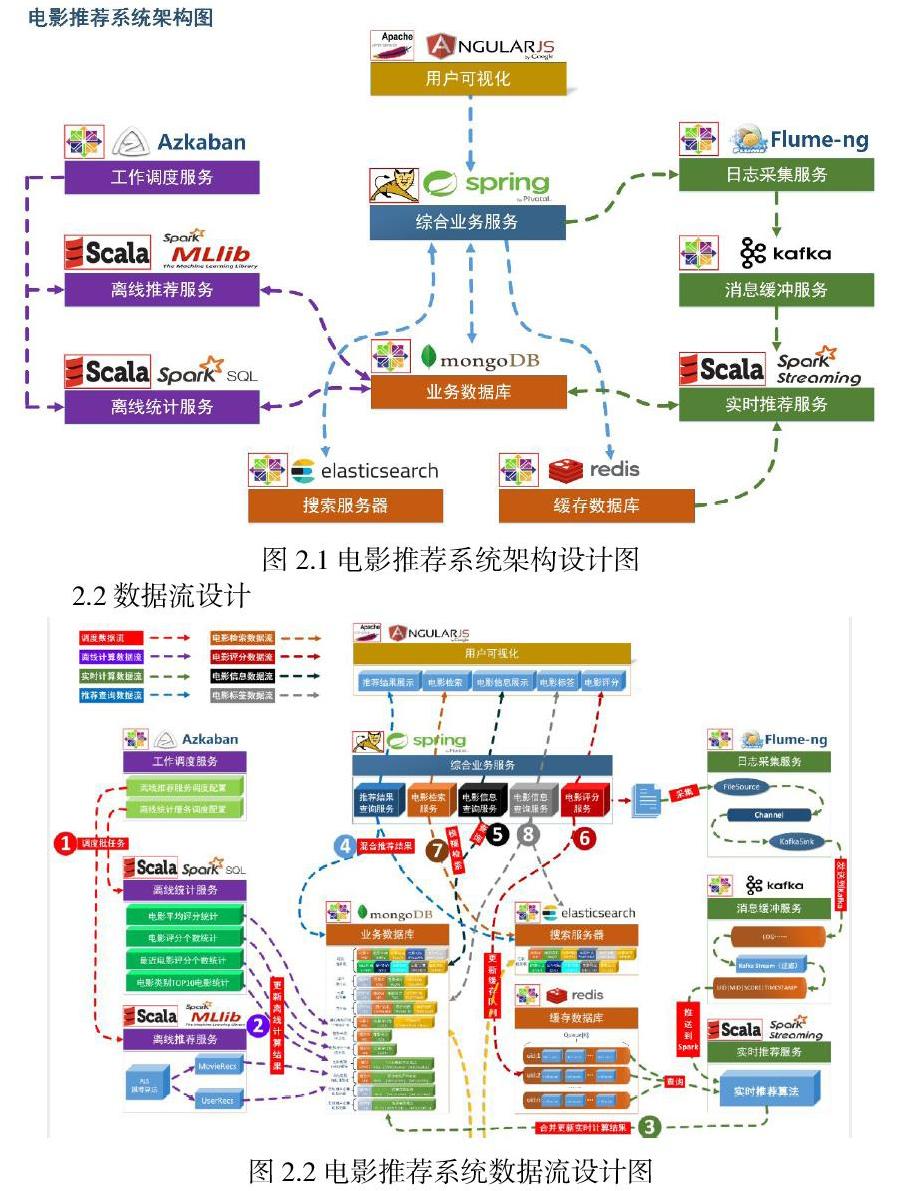
2.电影推荐系统的体系架构设计
项目以推荐系统建设领域知名的经过修改过的 MovieLens 数据集作为依托,以某科技公司电影网站真实业务数据架构为基础,构建了符合教学体系的一体化的电影推荐系统,包含了离线推荐与实时推荐体系,综合利用了协同过滤算法以及基于内容的推荐方法来提供混合推荐。提供了从前端应用、后台服务、算法设计实现、平台部署等多方位的闭环的业务实现。
2.1系统架构设计
2.2 数据流设计
3.电影推荐系统的体系架构介绍
本系统的实现过程中用到了多种工具进行数据的存储、计算、采集和传输,本章主要介绍设计的工具环境。
3.1數据存储部分架构介绍
业务数据库:项目采用广泛应用的文档数据库 MongDB 作为主数据库,主要负责平台业务逻辑数据的存储。
搜索服务器:项目使用 ElasticSearch 作为模糊检索服务器,通过利用 ES 强大的匹配查询能力实现基于内容的推荐服务。
缓存数据库:项目采用 Redis 作为缓存数据库,主要用来支撑实时推荐系统部分对于数据的高速获取需求
3.2离线推荐部分部分架构介绍
离线统计服务:批处理统计性业务采用 Spark Core + Spark SQL 进行实现,实现对指标类数据的统计任务。
离线推荐服务:离线推荐业务采用 Spark Core + Spark MLlib 进行实现,采用ALS 算法进行实现。
工作调度服务:对于离线推荐部分需要以一定的时间频率对算法进行调度,采 用 Azkaban 进行任务的调度。
3.3实时推荐部分架构介绍
日志采集服务:通过利用 Flume-ng 对业务平台中用户对于电影的一次评分行为进行采集,实时发送到 Kafka 集群。
消息缓冲服务:项目采用 Kafka 作为流式数据的缓存组件,接受来自 Flume 的数据采集请求。并将数据推送到项目的实时推荐系统部分。[1]
实时推荐服务:项目采用 Spark Streaming 作为实时推荐系统,通过接收 Kafka中缓存的数据,通过设计的推荐算法实现对实时推荐的数据处理,并将结构合并更新到 MongoDB 数据库。[2]
4.电影推荐系统实现前准备
系统使用 Scala语言编写,采用 IDEA工具作为开发环境进行项目编写,采用maven 作为项目构建和管理工具。在项目的src/main/目录下,将经过修改过的 MovieLens 数据集movies.csv,ratings.csv,tags.csv 复制到资源文件目录src/main/resources 下,我们将从这里读取数据并加载到 mongodb 和elasticsearch 中。从而完成电影数据的加载准备。
5.离线推荐服务建设
离线推荐服务是综合用户所有的历史数据,利用设定的离线统计算法和离线推荐算法周期性的进行结果统计与保存,计算的结果在一定时间周期内是固定不变的,变更的频率取决于算法调度的频率。离线推荐服务主要计算一些可以预先进行统计和计算的指标,为实时计算和前端业务相应提供数据支撑。[3]离线推荐服务主要分为统计性算法、基于 ALS 的协同过滤推荐算法以及基于ElasticSearch 的内容推荐算法。
在 resources 文件夹下引入 log4j.properties,然后在 src/main/scala 下新建 scala 单例对象StatisticsRecommender。
5.1 实现历史热门电影统计
根据所有历史评分数据,计算历史评分次数最多的电影。通过 Spark SQL 读取评分数据集,统计所有评分中评分数最多的电影,然后按照从大到小排序,将最终结果写入MongoDB 的RateMoreMovies 数据集中。
5.2 实现最近热门电影统计
根据评分,按月为单位计算最近时间的月份里面评分数最多的电影集合。通过 Spark SQL 读取评分数据集,通过 UDF 函数将评分的数据时间修改为月,然后统计每月电影的评分数 。 统计完成之后将数据写入到 MongoDB 的RateMoreRecentlyMovies 数据集中。
5.3 实现电影平均得分统计
根据历史数据中所有用户对电影的评分,周期性的计算每个电影的平均得分。通过 Spark SQL 读取保存在 MongDB 中的 Rating 数据集,通过执行以下 SQL 语句实现对于电影的平均分统计:
统计完成之后将生成的新的 DataFrame 写出到 MongoDB 的 AverageMoviesScore 集合中。
5.4基于隐语义模型的协同过滤推荐
采用 ALS 作为协同过滤算法,分别根据 MongoDB 中的用户评分表和电影 数据集计算用户电影推荐矩阵以及电影相似度矩阵。
通过 ALS 训练出来的 Model 来计算所有当前用户电影的推荐矩阵,主要思路如下:
1. UserId 和 MovieID 做笛卡尔积,产生(uid,mid)的元组
2. 通过模型预测(uid,mid)的元组。
3. 将预测结果通过预测分值进行排序。
4. 返回分值最大的 K 个电影,作为当前用户的推荐。
最后生成的数据结构如下:将数据保存到 MongoDB 的 UserRecs 表中。
5.5电影相似度矩阵
通过 ALS 计算电影见相似度矩阵,该矩阵用于查询当前电影的相似电影并为实时推荐系统服务。
离线计算的 ALS 算法,算法最终会为用户、电影分别生成最终的特征矩阵,分别是表示用户特征矩阵的 U(m x k)矩阵,每个用户由 k 个特征描述;表示物品特征矩阵的 V(n x k)矩阵,每个物品也由 k 个特征描述。[4]V(n x k)表示物品特征矩阵,每一行是一个 k 维向量,虽然我们并不知道每一个维度的特征意义是什么,但是 k 个维度的数学向量表示了该行对应电影的特征。 所以,每个电影用 V(n x k)每一行的
数据集中任意两个电影间相似度都可以由公式计算得到,电影与电影之间的相 度在一段时间内基本是固定值。[5]最后生成的数据保存到 MongoDB 的MovieRecs 表中。
6.实时推荐服务建设
实时计算与离线计算应用于推荐系统上最大的不同在于实时计算推荐结果应该反映最近一段时间用户近期的偏好,而离线计算推荐结果则是根据用户从第一次评分起的所有评分记录来计算用户总体的偏好。[6]
用户对物品的偏好随着时间的推移总是会改变的。比如一个用户 u 在某时刻对电影 p 给予了极高的评分,那么在近期一段时候,u 极有可能很喜欢与电影 p 类似的其他电影;而如果用户 u 在某时刻对电影 q 给予了极低的评分,那么在近期一段时候,u 极有可能不喜欢与电影 q 类似的其他电影。所以对于实时推荐,当用户对一个电影进行了评价后,用户会希望推荐结果基于最近这几次评分进行一定的更新,使得推荐结果匹配用户近期的偏好,满足用户近期的口味。[7]
如果实时推荐继续采用离线推荐中的 ALS 算法,由于算法运行时间巨大,不具有实时得到新的推荐结果的能力;并且由于算法本身的使用的是评分表,用户本次评分后只更新了总评分表中的一项,使得算法运行后的推荐结果与用户本次评分之前的推荐结果基本没有多少差别,从而给用户一种推荐结果一直没变化的感觉,很影响用户体验。
另外,在实时推荐中由于时间性能上要满足实时或者准实时的要求,所以算法的计算量不能太大,避免复杂、过多的计算造成用户体验的下降。[8]鉴于此,推荐精度往往不会很高。实时推荐系统更关心推荐结果的动态变化能力,只要更新推荐结果的理由合理即可,至于推荐的精度要求则可以适当放宽。
6.冷启动问题处理
整个推荐系统更多的是依赖于用于的偏好信息进行电影的推荐,那么就会存在一个问题,对于新注册的用户是没有任何偏好信息记录的,那这个时候推荐就会出现问题,导致没有任何推荐的项目出现。
处理这个问题一般是通过当用户首次登陆时,为用户提供交互式的窗口来获取用户对于物品的偏好。
在本项目中,当用户第一次登陆的时候,系统会询问用户对于影片类别的偏好。
7.基于内容的推荐服务
原始数据中的 tag 文件,是用户给电影打上的标签,这部分内容想要直接转成评分并不容易,不过我们可以将标签内容进行提取,得到电影的内容特征向量,进而可以通过求取相似度矩阵。这部分可以与实时推荐系统直接对接,计算出与用户当前评分电影的相似电影,实现基于内容的实时推荐。[9]为了避免热门标签对特征提取的影响,我们还可以通过 TF-IDF 算法对标签的权重进行调整,从而尽可能地接近用户偏好。
8.总结
本文通过整合当前主流的大数据架构,构建了一个智能的电影推荐系统,针对不同用户,通过使用基于内容的推荐、基于协同过滤等经典数据挖掘算法,剖析数据间的关系,从而完成电影推荐系统的相关功能。用户为系统提供一个电影的名称,系统做出与这部电影在电影所属类别、电影演员、受欢迎程度、电影发布时间等综合程度相似度最高的若干影片推荐。最后通过对电影推荐系统的研究,总结凝练出一套适合应用在电商、旅游、医疗、教育等其他行业的构建大数据推荐系统的经验方法,旨在为大数据推荐系统开发者提供一些优化算法、架构技术等方面参考。
参考文献:
[1]温向慧,基于流计算的实时推荐系统的研究[D] :西北师范大学硕士论文,2018
[2]周虎,基于Spark Streaming实时推荐系统的研究与实现 [D]武汉邮电科学研究院硕士论文,2019
[3]刘忠宝,李花,宋文爱,孔祥艳,李宏艳,张静,基于二部图的学习资源混合推荐方法研究[J] 电化教育研究,2018
[4]李琛轩,面向推荐的大数据计算与存储平台设计与实现 [D]哈尔滨工业大学硕士论文,2016
[5]孙远帅,基于大数据的推荐算法研究[D],厦门大学硕士论文
[6]王发旺,结合属性特征的混合推荐系统研究与实现 [D],浙江工商大学硕士论文,2019
[7]柴华,基于协同过滤和内容过滤的混合广告推荐技术的研究,北京邮电大学硕士论文,2015
[8]姜鹏,许峰,周文欢,大规模互联网推荐系统优化算法[D]计算机工程与科学,2013
[9]刘仲民,基于图论的图像分割算法的研究[D],兰州理工大学博士论文,2018
作者简介:
蒙德钦(1997.08-),男,汉族,广西贵港人,毕业于玉林师范学院计算机科学与技术专业,本科学士,广西城市职业大学,研究方向:大数据系统开发、算法设计
张钦锋(1980.03-),男, 漢族, 广西北海市,毕业与贵州大学计算机科学与技术专业,本科学士,广西城市职业大学,讲师,研究方向:软件开发、算法设计、计算机网络
基金项目:本文系2020年度广西高校中青年教师基础能力提升项目(基于大数据技术的推荐系统研究)(编号:2020KY66013)
(广西城市职业大学信息工程学院 广西壮族自治区崇左市 532200)
猜你喜欢
中国市场(2016年36期)2016-10-19
中国市场(2016年36期)2016-10-19
商(2016年27期)2016-10-17
今传媒(2016年9期)2016-10-15
今传媒(2016年9期)2016-10-15
新闻世界(2016年10期)2016-10-11
科技视界(2016年20期)2016-09-29
中国记者(2016年6期)2016-08-26
