
基于集群的分布式爬虫系统的架构研究
2020-03-10 22:12和乾
科学与财富 2020年33期
关键词:架构

摘 要:互联网时代,如何从海量数据中收集信息是一个关键问题。目前,使用最频繁的信息检索与收集工具是基于通用爬虫的搜索引擎。与通用爬虫相比,主题爬虫尽量避免与主题不相关页面的抓取,存储的页面数量更少,所获取的信息价值密度更高,是一种有效的信息收集工具。如何通过有效的架构设计降低爬虫任务的耗时是一个关键问题。
关键词:主题爬虫;架构;Scrapy
网络爬虫指的就是一种根据既定规则对Web网页中应用程序或脚本进行自动提取的技术。如今,各大搜索引擎网站和大型互联网企业均在大幅使用此类爬虫程序,爬取目标网站的网页信息,以实时更新企业内部服务器关于这类信息的内容。网络爬虫的步骤流程一般可分为采集数据,分析或转换数据,存储数据三个部分。在传统爬虫中,首先给定一个或者多个URL,爬虫程序开始运行,从给定的URL上获取网页的信息,分析过滤新获取的URL,存入等待爬取的URL数据库表中,不断重复此过程。
单机版本的网络爬虫存在很明显的缺陷,受限于单独的主机配置,不能任意扩展性能,在生产环境中极少使用。因此,目前网络爬虫一般均会使用分布式爬虫架构,可以在多个节点同时运行,大幅提高了爬虫速度和效率。对于分布式爬虫架构,常见的有主从式、对等式、混合式架构。
1 主从式架构
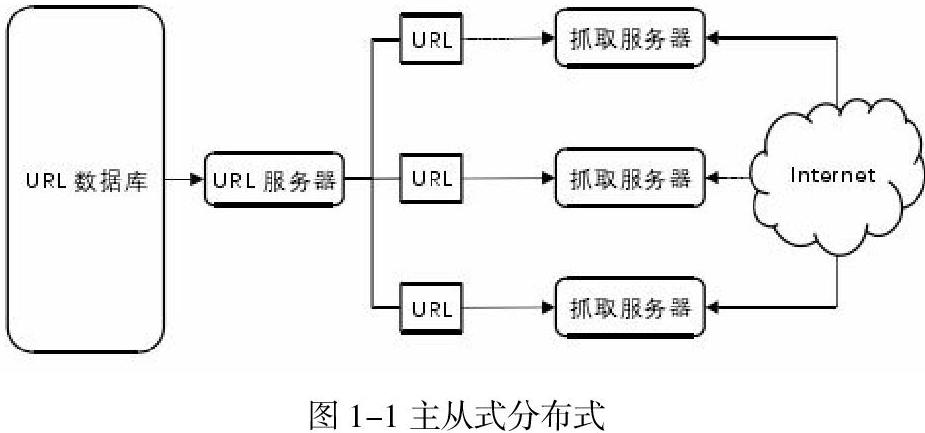
在主从分布式结构中,一般只有一个主节点,其余均为从节点。主节点负责URL的存储与分发,其它节点则进行网页的爬取下载工作。主节点服务器负责维护待爬取的URL队列,并且主动给从节点分配URL,所以主节点还需要考虑整个系统的负载均衡的问题。不能让某个从节点压力过大,也不能让某个从节点一直空闲。主节点需要根据从节点反馈的任务执行情况来增减某一个从节点的负载压力,以发挥整个系统最大的效率。在各个从节点之间一般没有通信链路,各个从节点只会和主节点相互联系。因为后期URL的数量巨大,所以主节点的URL服务器对待爬取队列的维护和URL的分发将会承受极大压力。
因此,主从分布式结构性能效率的提升关键在于主节点的URL服务器。主从分布式拓扑示意图如1-1所示。
2 对等式架构
在对等式架构中,各个节点之间不存在所谓的主从之分。每个节点都会有爬虫任务运行,各个节点各自维护自己的待爬取URL队列。因此这就存在数据
同步的问题,多个节点可能会对同一网页多次爬取,这会大大的浪费节点的资源。既然各个节点不能各自为政,那么如何分工协作就是一个问题了。常见的有以下两种解决方式:哈希取模和一致性哈希。哈希取模是在爬取之前各节点会计算网站域名的哈希值,然后对节点个数取模,取模的结果就代表了该域名下应由哪个节点进行爬取。但该方法存在一些弊端,若有一个节点宕机了,取模数就会发生变化,以致于最终结果就会发生混乱。另外,不同网站的网页数据量也不一样,不同的节点爬取不同域名下的网站,这也可能会存在负载均衡的问题。一致性哈希算法直接将网站主域名进行哈希映射,结果范围是0-2^32之间的某個数。将该范围首尾相连成环,每个服务器就负责其中的一小段,如果某一个节点服务器宕机,就将该服务器的任务顺延至下一个节点服务器。对等式架构不存在独立的URL服务器,因此不会存在性能瓶颈的问题,但是整个系统实现起来比主从式架构更加复杂。对等分布式拓扑示意图如图2-1所示。
3 主从混合模式
此模式是参考了主从式架构的设计基础,并且也揉合了对等式架构的特性。在此架构模式中,由主节点和从节点之分,每个节点均会有爬虫任务。主节点上有着系统唯一的URL服务器,各个从节点与主节点相互通信,各个从节点之间不会相互通信。该模式主要是考虑到了目的网站链接的特殊性,主节点仅对一类特殊链接进行爬取,从节点也仅对另一类特殊链接爬取,两类节点爬取的链接不会交叠重复。此模式设计的好处是比对等式更简单,系统设计和程序代码实现起来更加容易;而与主从式相比,增设了主节点爬取小部分特殊链接的任务。本系统参考了Python语言编写的经典的爬虫框架Scrapy,利用Redis数据库,解决了其不支持分布式的缺点。
4 Scrapy-Redis框架
Scrapy 是一款基于Python开发的开源web爬虫框架,可快速抓取Web站点并提取页面中的结构化数据,具有高度的扩展性和鲁棒性。但是在面对大量的网页数据需要处理时,单主机的爬虫程序效率低下的缺点就显得尤为突出,远远不能满足项目的要求了,此时就必须使用分布式爬虫了。然而单独的原始Scrapy 框架并不支持分布式,因此在Scrapy的框架基础上衍生出了Scrapy-Redis分布式爬虫框架。它利用Redis 调度和存储需要爬取的请求,并存储爬取产生的项目以供后续处理使用。Scrapy-Redis重写了Scrapy一些比较关键的模块,使Scrapy支持了分布式架构。
在信息时代的今天,互联网数据量爆发增长,云计算和大数据的应用场景也越来越丰富。互联网大数据对于大型企业收集分析客户需求、意向和商业前景市场调研就极为重要。在企业的商业决策上、经营方向上需要大量准确的可靠数据做支撑,所以如何快速准确地获取大量的目的数据信息就是一个迫切需要解决的问题。本系统基于Docker容器集群部署的分布式爬虫系统,采用了Scrapy-Redis分布式爬虫框架,改进了URL去重模块,增设了页面文本去重模块,优化了对于反爬虫问题的处理,对于整个系统的高效性与健壮性增加了一层坚实保障。
参考文献:
[1] 杜晓旭,贾小云.基于Python 的新浪微博爬虫分析[J].软件,2019,40(04)
[2]邓万宇,刘光达,董莹莹.一种基于Scrapy-Redis 的分布式微博数据采集方案[J].信息技术,2018(11).
作者简介:
和乾(1981)男,黑龙江大庆人,讲师,大学本科, 主要从事计算机网络专业网络安全、网络操作系统的教学及安全理论考试点的运维工作。
(大庆职业学院 黑龙江 大庆 163255)
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
汽车工程(2021年12期)2021-03-08
时代人物(2019年27期)2019-10-23
计算机测量与控制(2017年6期)2017-07-01
电信科学(2017年6期)2017-07-01
油画艺术(2017年1期)2017-05-20
电信科学(2016年11期)2016-11-23
电测与仪表(2015年22期)2015-04-09
现代教育技术(2015年1期)2015-02-26
电测与仪表(2014年1期)2014-04-04
