
大数据集序列模式挖掘算法分析
2020-03-10 02:56李克
科学与财富 2020年33期
关键词:大数据
李克

摘 要:大数据时代背景下,网络技术和数据技术的使用非常关键,对于社会发展也起到了重要的作用。本文笔者针对大数据集序列模式挖掘算法进行了分析研究,文章中阐述了大数据以及序列模式挖掘,并针对BLSPM算法进行试验和结果分析。
关键词:大数据;BLSPM算法;序列模式挖掘
1 大数据和序列模式挖掘的概念
1.1 大数据的概念
大数据是信息社会发展过程中形成的数据集合,其发展的背景信息化技术。计算机技术问世,其两方面技术应用最为广泛,其一是数据运算,其二就是数据信息管理,能够实现数据的储存和分析。而随着社会技术的发展,数据量也不断增加,当前在社会发展的过程中,信息技术开始逐渐朝向数据技术发展,形成了大数据技术。大数据当前而言主要包括两个方面。其一,是数据处理储存量不断增大,计算机技术中数据处理的单位从MB已经达到了ZB,其数据变化巨大,并且相关数据专家预测,数据技术的储存容量还会继续增大10倍甚至20倍。另外一方面,大数据技术应用于数据分析,其中包括数据库分析、数据关系分析以及数据结构分析等,数据分析技术在当前社会中应用更加广泛,其具体分析过程中还包括数据采集、数据导入、数据统计以及数据挖掘等多个技术部分,对于数据的分析处理有非常重要的作用。在未来,数据容量更大,数据采集技术更加先进、数据挖掘也将会被更多的应用,大数据将会对世界带来重大的改变[2]。
1.2 序列模式挖掘的概念
序列模式挖掘是大数据背景下对数据挖掘的重要技术模式,在当前社会中的应用非常广泛,信息市场调研、预测天气变化、市场变化趋势、网络网站访问模式等。在序列模式挖掘具体应用的过程中,是在序列数据库当中将子序列频繁出现作为数据的挖掘模式进行数据分析,能够实现数据挖掘分析的精度提升。应用较为早期的序列模式挖掘算法为Apriori,其在计算中使用到關联性原则,而随着现代社会中数据量的逐渐增大,所以在实际的社会应用中Apriori算法应用精度较差,所以现代社会发展中,急需一种适应社会的序列发展模式,保证数据使用更加高效。
2 大数据集序列模式挖掘算法
2.1 BLSPM算法和实验结果
BLSPM是一种新式序列模式挖掘算法,其发展的前身是PrefixSpan算法以下是对该算法进行的分析研究。在BLSPM算法中,提出了利用隔层投影和剪枝策略的相互合作数据挖掘计算模式,可以减少数据库处理中的投影数据量,并完成对最小支持度数据序列模式的剪枝删除,从而保证数据分析更加精准。
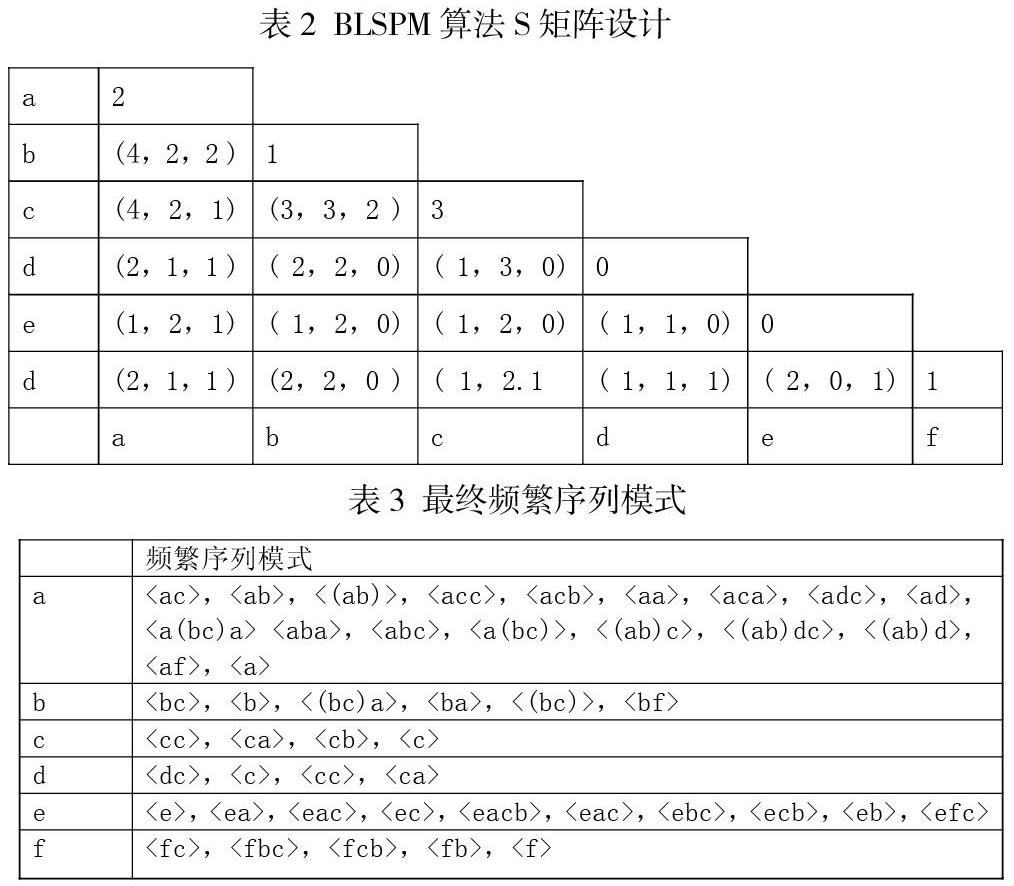
为了研究BLSPM算法,本文针对算法应用进行了具体的试验,试验中设立数据库为S(图1),并且设置为min_sup=2。以下是对BLSPM 算法挖掘记性的相关阐述。1.初始挖掘运算中,数据库开始完成对1个长度单位的序列模式进行查找,查找过程中对BLSPM序列集进行全盘扫描,挖掘频繁序列模式以及非频繁序列模式,并对费频繁序列模式进行减除。2.实际的数据挖算法中利用序列集中的频繁序列项作为X轴和Y轴,从而构建形成M矩阵。以下图2为S矩阵构建图。通过矩阵图构建能够完成对数据的有效采集,从而保证数据处理更加高效。
3.利用序列模式数据库进行子集查找。支持度不小于 2序列模式在数据集中查找,递归地挖掘频繁序列的子集。4. BLSPM算法中第四部是对两部分进行重复查找和执行,并对所有的长度频繁序列进行集合,从而保证频繁序列集合查找更加精准。5.是BLSPM算法的最终结果步骤,其中包括频繁项目集的序列模式并将进行排序。以下表三为最终序列图。
2.2 基于Map-Reduce的BLSPM算法和结果
基于Map-Reduce的BLSPM算法也是当前BLSPM算法的发展,在其行和具体计算的过程中其计算主要分为以下几方面内容;1.数据分片是BLSPM算法中的重要组成部分,在实际的计算过程中,选择将BLSPM的大数据集进行分部,将其分部成连续性的数据片,从而做好数据分类。2.数据并行计数。数据并行技术也是利用大数据库进行扫描,实际的计算过程中,选择利用Map-Reducwe型进行序列支持度计算,计算全局的长度为 1 的频繁项集Flist。3.建立三角矩阵。在Map-Reduce的BLSPM算法中,也是利用Flist1 中 n 个序列进行三角矩阵设计,分别建设X轴和Y轴。4.均衡分组设计。均衡分组设计是在实际的计算过程中,选择使用到负载均衡策略进行序列模式分组,制定成为新Glist数据表。5. 在Map-Reduce的BLSPM算法中选择使用并性挖掘技术对大数据集中的组别进行划分,利用Glist数据表进行并行数据挖掘,也选择使用Map-Reduce软件来完成第二阶段的数据挖掘,完成对序列集的数据挖掘和计算。以下是Map-Reduce软件的数据计算代码。
Input: key is the number of each shard, value is T
Output:
Begin
String str= value.toString();
While(str.hasNext())
{
Item=str.next();
//输出
Context.Write (item,1);
}
End
3.结束语
本文以具体试验详细阐述了BLSPM算法与Map-Reduce的BLSPM算法的计算过程,希望能够对大数据集序列模式挖掘算法的发展有所帮助。
参考文献:
[1]曾毅, 张福泉. 基于多效用阈值的分布式高效用序列模式挖掘[J]. 计算机工程与设计, 2020, 041(002):449-457.
(河北省信息资源管理中心 河北 石家庄 050000)
猜你喜欢
中国市场(2016年36期)2016-10-19
中国市场(2016年36期)2016-10-19
商(2016年27期)2016-10-17
今传媒(2016年9期)2016-10-15
今传媒(2016年9期)2016-10-15
新闻世界(2016年10期)2016-10-11
科技视界(2016年20期)2016-09-29
中国记者(2016年6期)2016-08-26
