
基于机器学习的RTS游戏实时胜率预测
2020-03-16 08:02温叶廷黄海于
网络安全与数据管理 2020年3期
温叶廷,黄海于
(西南交通大学 信息科学与技术学院,四川 成都 611756)
0 引言
实时战略游戏(RTS)在过去十年中一直是人工智能研究领域的一个热点[1]。由于RTS游戏复杂性、部分可观察和动态实时变化战局等游戏特点使得研究变得比较困难,因此对于获胜者的预测成为了人工智能研究的一个高度相关的主题。
现有的研究主要集中在MOBA游戏DOTA2中,比如,文献[2]使用两种不同的方法对游戏胜负做出了预测,第一种使用完整的赛后数据,第二种在英雄选择阶段,上述的两种方法是用来预测整局游戏的胜负,而不是实时胜率;文献[3]将赛前特征与比赛期间的特性相结合,使用逻辑回归,得到了实时游戏预测胜率的准确率为71.49%。虽然目前研究在游戏胜负预测方面已经有了一些成果,但是由于游戏不同,RTS与MOBA游戏有着很大的区别,而被广泛认为是最具挑战性的RTS游戏的星际争霸II[4]仍然没有得到解决。星际争霸II与其他的即时战略游戏一样分为双人或多人游戏。每一名玩家可以选择不同的种族(人族T、虫族Z和神族P)并且可以组建一支军队来击败敌人,而且每一位玩家可能在一场游戏中同时操作很多单位。想要建立军队,玩家就需要开采资源、建造建筑、研究科技和训练单位。最后通过摧毁敌方建筑获得胜利。
本文基于SC2LE公开的星际争霸II游戏数据集,该数据集是天梯赛1V1数据,总计106万场。本文通过对海量的游戏数据信息进行处理,得到了一些与游戏胜负相关的特征,这些特征主要分为两类:基础特性和统计特性,通过实验表明,与单独使用基础特性相比,加入统计特性能够提高实时胜率预测的准确率。
1 构建游戏数据集
1.1 数据预处理
利用游戏的回放数据去预测游戏的胜负是一种科学有效的方法。但是游戏数据集的质量好坏是影响预测结果的重要因素,因此,如何从106万局游戏中筛选出高质量的回放数据是至关重要的。本文构建游戏数据集基于以下原则:(1)选择高水平玩家的对局;(2)根据不同匹配对局游戏时长的均值和标准差选取游戏时间。
选取高水平玩家的对局主要使用两个指标:MMR(星际争霸II大区中比赛匹配等级,Match Making Ration)和APM(玩家的每分钟操作数,Actions Per Minute)。图1所示为TvZ对局中MMR与APM的散点图,从图中可以看出两者没有相关性,而且高的MMR并不一定会有高的APM,反之亦然。因此,应该将两者结合使用。
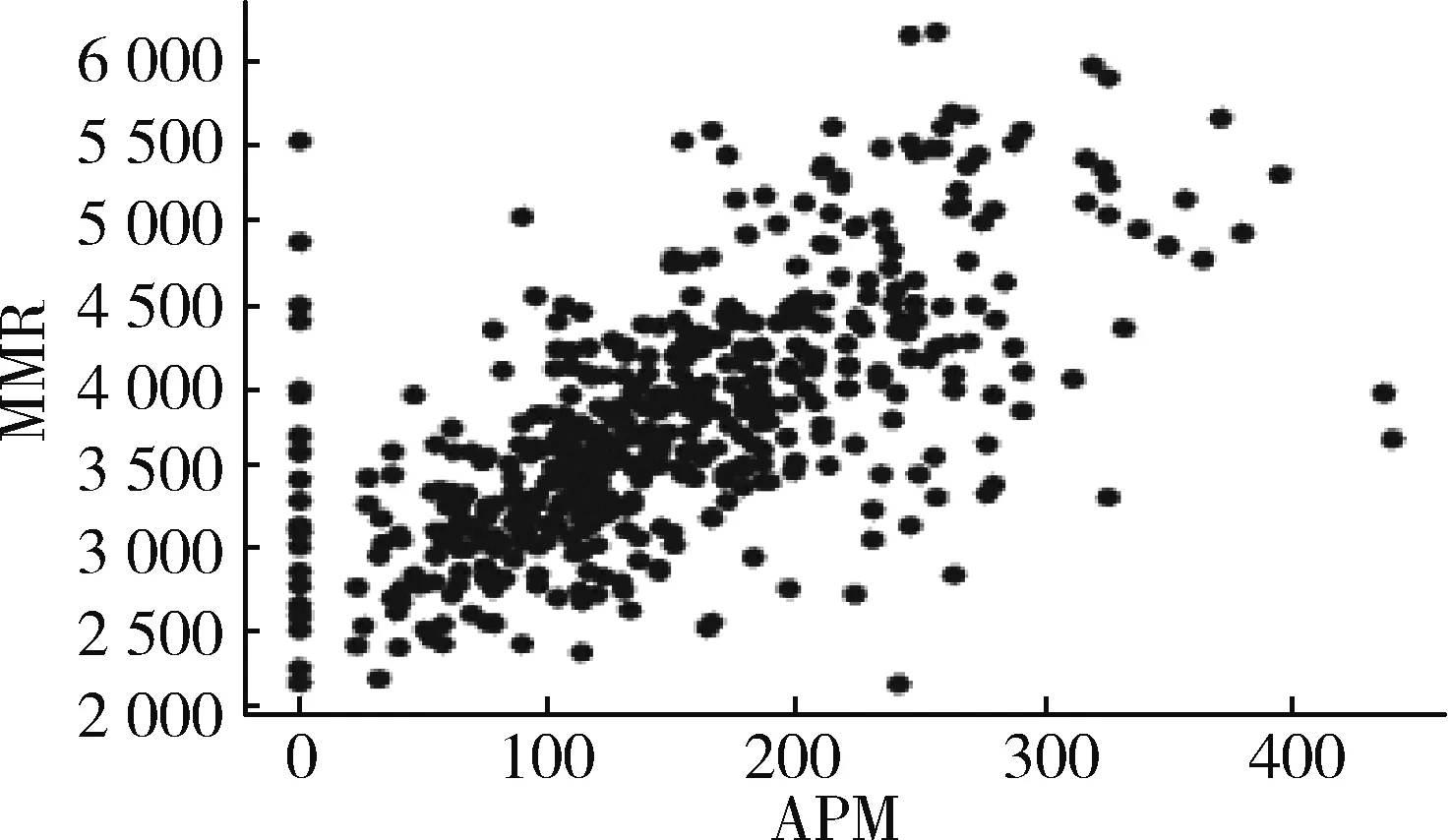
图1 TvZ对局的MMR和APM散点图
游戏时间的筛选也是判断游戏质量的指标,游戏时间太短或太长的对局,会造成数据偏差太大。通过计算不同匹配组合游戏时间的均值和标准差来选择游戏时长的范围。如表1所示,由于游戏中有3种不同的种族,因此会有6种不同的匹配对局,分别为:PvT、PvZ、TvZ、PvP、ZvZ和TvT。范围中的下限使用均值向下取整与标准差向上取整相减所得,上限使用均值向上取整与标准向上取整相加所得。

表1 不同匹配对局的均值、标准差和选择区间 (min)
这里将使用表1中的时间区间,并结合MMR(大于4 000)、APM(大于150,接近专业玩家水平)进行筛选。筛选前后对局数量如表2所示,FTS表示原始数据中的对局数量,ATS表示筛选后的对局数量。

表2 筛选前与筛选后的对局数 (万局)
1.2 解析数据
将筛选下来的高质量对局通过使用pysc2进行数据提取,在回放的每一帧都会返回Observation,使用ProtoBuf进行解析,解析后的每个观察值包括以下信息:
(1)玩家所拥有的建筑、单位和技术;
(2)玩家拥有的人口情况;
(3)玩家所使用和拥有的资源;
(4)玩家所观察到的敌人单位和建筑。
1.3 特征提取
1.3.1 基本特征
从游戏回放中解析出游戏状态,在这里,首先提取出基本的特征。这些基本特征主要包括:
(1)资源信息:包括当前时刻的瓦斯数量和晶体矿的数量。
(2)人口信息:包括当前时刻人口上限、已使用的人口数和未使用的人口数。
(3)单位信息:包括每种单位的数量,已经训练完毕的单位数量,正在建造的数量,快要建造完毕的数量,刚开始建造的数量以及平均建造数量。
(4)研究科技信息:包括已经升级的科技。
(5)观测到的敌方玩家建筑和单位的数量。
将上面的信息进行序列化,但是由于种族不同,单位的类型数量以及研究科技的种类也不相同,因此不同的对局对应的序列长度也不一样,如表3所示。
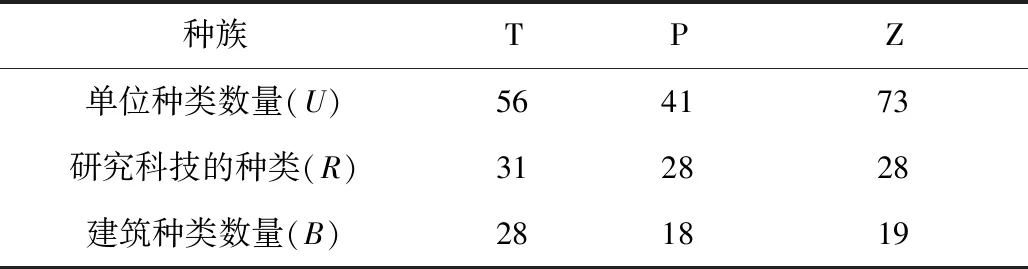
表3 不同种族对应的单位类型数量与科技研究种类
每场游戏的基本回放特征会被组织成一个N×M1大小的矩阵,N指行数,与游戏时间相关;M1根据使用的种族和对战种族不同而不同。表4所示为M1的组织形式。不同的种族由于其单位种类和研究种类数量上的差异,特征序列的长度也不相同,如表5所示。

表4 序列对应的每个字段的含义
注:(1)R大小为种族的研究数量(见表3)加20;
(2)S(U)大小为R加上6×种族的单位种类数量(见表3);
(3)E(U)大小为S(U)加上敌方单位种类数量(见表3)。
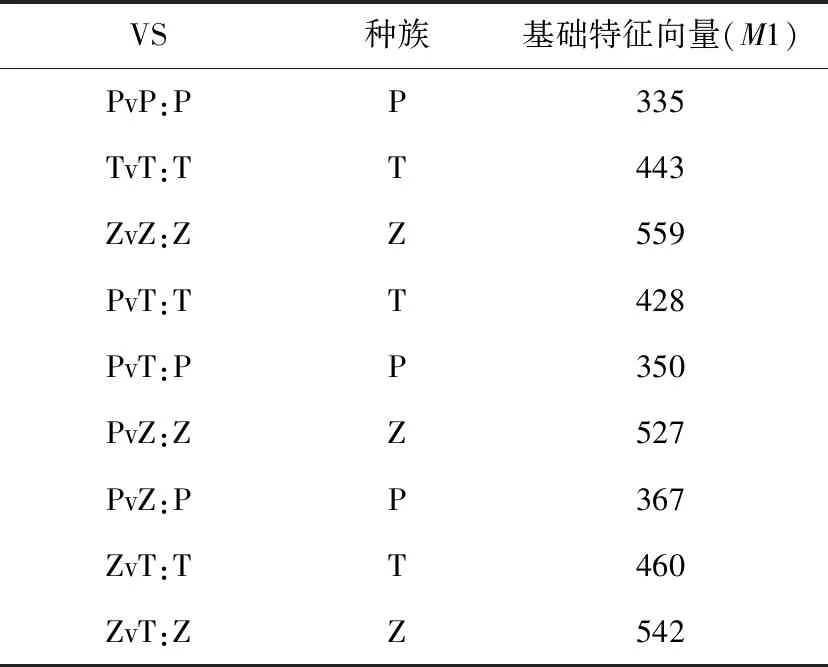
表5 不同匹配对局不同种族的特征序列长度
1.3.2 统计特征
除了上述的基本特征以外,这里提出了有关动作和地图的统计信息。统计信息主要分为两类,一类是对动作做统计,另一类是对地图和距离的部分信息进行统计。
星际争霸Ⅱ是一个需要有效利用游戏时间的游戏,一般在游戏过程中分为前期、中期和后期三部分,想要在每个时期达到预期的效果,则采用的命令也就不同。因此,命令的类型以及频率能够反映出游戏的状态,比如在前期时会大力地发展经济,所以关于建造的命令就相对较多。
首先统计某类类型的命令频率。可以发现最常用的6种命令为:MOVE,BUILD,TECH,TRAIN,SIEGE和BURROW。而且根据执行命令是否使用资源将命令分为两大类:一类是在执行过程中不使用资源,称为微观命令;否则为宏观命令。
受文献[5]的启发,可以将命令分为三类:控制命令、策略命令和战术命令。
动作统计信息包括上述最常用的6种命令,还包括微观命令、宏观命令、控制命令、策略命令和战术命令,共计11种命令。这些信息每隔1 min间隔统计一次。
整形:按照“单主干双主蔓”的树型整形。主干离架下40 厘米处摘心,培养双主蔓,主蔓长度为株距一半,主蔓两侧均匀分布结果母枝,结果母枝间距30厘米左右。
SC2LE中的数据集主要是收集天梯赛的对局,天梯赛在每个版本都会有几种不同的地图。每种地图都有各自的风格,地图的主要特点主要有补给距离、空间距离、矿区范围、矿区高地口宽度和矿区的资源数量。根据文献[6]对于游戏地图特点的分析,可以得出地图对于玩家的胜负也是较为关键的。
除了基本的地图统计信息以外,建筑物的摆放位置对于游戏胜负的影响很大,好的摆放位置,可以用来抵挡敌人[7],在这里通过计算同种类型建筑物的相对距离和指挥中心周围建筑与指挥中心的相对距离两个指标,来反映出建筑物的位置信息。式(1)计算了同种建筑的相对距离,因为游戏地图较大,所以使用指挥中心进行分组,将距离某个指挥中心较近的分为一组,指挥中心的个数就是组的个数,用m表示。
(1)
其中,uij代表第i类建筑中第j个单位的位置,n代表某组中某种建筑的数量,dik代表第k组i类单位的相对距离。
(2)
Di为i类单位的平均距离。
式(3)表示的是建筑物相对于指挥中心的距离,同样也是按照指挥中心分组计算,一般情况下,建筑物都是围绕着指挥中心建造的。
(3)
其中ck为第k个指挥中心的位置,pj为第k组中第j个建筑的位置,s为第k组的单位个数。
式(4)表示指挥中心周围建筑与指挥中心的相对距离。对于建筑物的位置摆放需要集中,过于分散不利于防守。
(4)

表6 统计特征每个字段的含义
注:S(B)大小为17加上建筑物类型数量(见表3)减1。
统计特征不同于基础特性,其大小与匹配对局无关,只与种族相关。如表7,统计特征大小用M2表示。

表7 统计特征序列长度
2 实验结果与分析
每场游戏的回放特征会被组织成一个N×M大小的矩阵,N与回放游戏时间有关。在本文中,采取每隔1 min构建一个M,但是在提取数据时为了不丢失动作信息是按照每8帧提取一次数据[8],这里M的大小是M1+M2,例如M(T)PvT=M1(T)PvT+M2(T)=428+45=473。经过数据处理后,得到每种不同匹配对局下的数据总条数,对每局游戏每隔1 min做一次数据采样作为一个M(游戏刚开始不做采样),最后每一种匹配的数据总条数如表8所示。

表8 不同对局下的数据条数 (万条)
在本节中,将使用机器学习算法XGB构建模型,将预测胜负转化为一个二分类任务。首先,为每一种匹配类型设计一个单独的模型,用于预测不同对局下的实时胜率。
XGBoost[9]是Gradient Boosting方法的一个特定实现,使用更精确的近似来找到最佳树模型。它采用了许多漂亮的技巧,使其非常成功,尤其是结构化数据。最重要的是,计算二阶梯度,即损失函数的二阶导数(类似于牛顿方法),其提供了关于梯度方向以及如何达到损失函数最小值的更多信息和高级正则化(L1和L2),提升了模型的泛化能力[10]。
将数据集按照6:2:2分为训练集、验证集和测试集,在训练过程中对样品进行了10次交叉验证。为了避免偏差,对于任意对局,样本要么在训练集中,要么在测试集中,但不同时存在。如表9所示,B代表基本特征情况下的准确率,B+S代表组合特征情况下的准确率。
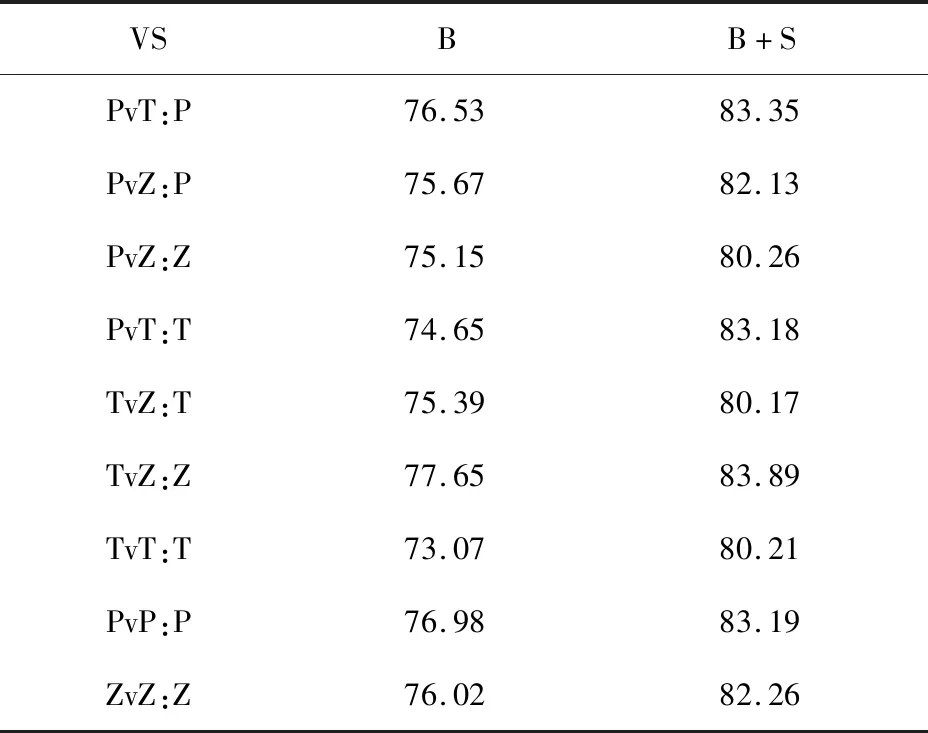
表9 基本特征与组合特征下的实时准确率 (%)
从上述实验结果可以看出,本文提出的组合特性的预测效果比单独使用基础特征的效果要好。
3 结束语
游戏实时胜率预测是游戏AI的重要一环,本文通过使用SC2LE公开的数据集构建特征数据集,分析了不同匹配对局下使用基础特征和统计特征时不同模型的研究结果,结果表明,在基础特性中加入统计特性能够提升实时胜率预测的准确率。通过使用本文中的预测模型,可以解决在游戏AI中使用强化学习时关于奖励稀疏的问题,能够加快强化学习的模型训练。
猜你喜欢
娃娃乐园·综合智能(2022年3期)2022-04-19
英语文摘(2021年11期)2021-12-31
网络安全和信息化(2019年1期)2019-12-22
英美文学研究论丛(2018年2期)2018-08-27
军营文化天地(2018年2期)2018-04-20
小火炬·智漫悦读(2018年8期)2018-03-20
时代英语·高一(2017年5期)2017-11-14
电脑爱好者(2016年22期)2016-12-16
棋艺(2016年6期)2016-11-14
棋艺(2014年7期)2014-09-09
