
基于变长时间间隔LSTM方法的胎儿异常体重预测①
2020-03-18 07:54张硕彦吴英飞袁贞明胡文胜
计算机系统应用 2020年3期
张硕彦,吴英飞,袁贞明,卢 莎,胡文胜
1(杭州师范大学 杭州国际服务工程学院,杭州 311121)
2(杭州市妇产科医院,杭州 310008)
1 介绍
预测胎儿体重是产前监护的重要内容,是医生对孕妇进行临床处理的重要依据.近年来研究显示,低体重儿的存活率和扛感染能力相对低下[1],并且与低智商有密切联系[2].而巨大儿则会引起胎儿宫内窘迫、新生儿窒息、肩难产[3,4]等.产前预测胎儿体重,对于避免新生儿体重异常,恰当选择分娩方式具有重要意义.孕妇的产前体检记录属于特殊的电子病历.围产医学规定的产前体检、孕妇个人的健康状况和高危妊娠的随访等使得孕妇的体检次数和体检时间间隔各不相同.因而造成了体检事件在妊娠时间上的不均匀时间间隔分布.图1 是孕妇产前体检示意图.矩形表示妊娠起点,3 个圆点表示孕妇的前3 次产前体检记录,倒三角表示分娩.以上事件以时间顺序在数轴上从左往右排列,事件之间的距离大小表示时间间隔的长短.妊娠时间用ΔTk表示,相邻两次体检之间的时间间隔用 Δtk表示(k=1,2,3,···,N).孕妇每次体检的时间间隔不仅与妊娠时间有关,而且与相邻两次体检之间的时间间隔有密切联系.传统的RNN 和LSTM 模型默认序列之间是相等时间间隔的,以序列的先后顺序表示时间信息,在模型层面并没有时间概念,难以充分有效地表征数据不均匀时间间隔的关系.基于以上,本研究从模型层面出发,将妊娠时间 ΔT和间隔时间 Δt做嵌入表示,在LSTM 模型中的“遗忘门”和“记忆门”分别增添“时间门”,模型以“时间门控”的方式控制“状态”信息,间接表征不均匀时间间隔信息.文章安排如下:第1 部分介绍,阐明胎儿体重预测的意义和孕妇的体检事件分布特点,第2 部分相关工作,阐述目前胎儿体重预测任务的主流方法和不足,以及深度学习在电子病历中的应用.第3 部分是任务定义和模型介绍,第4 部分是数据预处理和实验设计,第5 部分是实验结果和讨论,最后部分是结论.
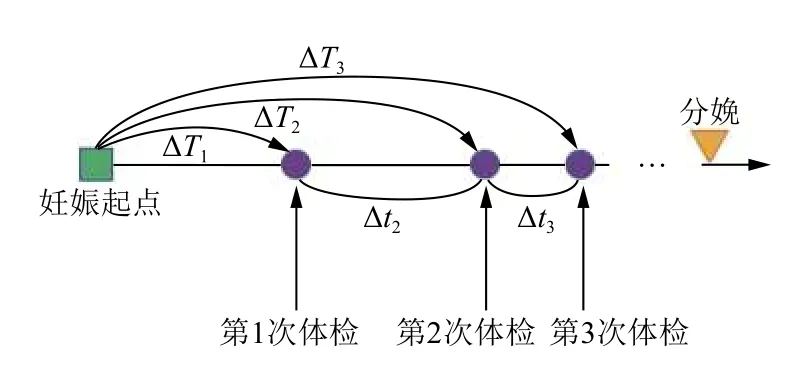
图1 孕妇产前体检记录分布示意图
2 相关工作
在临床工作中,产科医生经常采用宫高腹围测量法[5-8]和超声测量法[9,10]估算胎儿体重.两者根据孕妇的检查数据为参数,通过公式来估计胎儿体重.宫高腹围法简单快捷无副作用,孕妇可在家中自行测量.超声法则以其更精确的优点成为目前应用最广泛的方法.但是,这两种方法均存在不同的弊端.首先,由于产科工作的特殊性,在一些紧急情况下不能及时为孕妇完成超声检查,此时使用宫高腹围法便成为一个很好的选择.超声法是目前较为准确的测量方法,但是,多次做超声检查是否有副作用存在争议,一般情况下,孕妇产前的超声检查仅为3-4 次.除以上两种公式估算方法外,机器学习方法也可以将孕妇的宫高、腹围,胎儿的双顶径、头围、腹围、股骨长等数据为参数预测胎儿体重,在刁晓娣等的研究中[11],使用人工神经网络预测胎儿体重,Xu ZP 等[12]在人工神经网络中添加了正则化条件来预测胎儿体重.虽然,机器学习方法已应用到胎儿体重预测任务中,但是其方法大多为人工神经网络,不同的研究虽对人工神经网络有不同的修改,但其本质仍旧是MLP(多层感知机).无论是宫高腹围法、超声测量法还是经典机器学习方法,仅取孕妇分娩前一周内的数据作为估算或预测参数,而忽略了孕妇在多次体检记录中反映出来的变化.其次,在胎儿体重预测的研究中,尚未将孕妇的高危妊娠和疾病信息考虑进去.因此,此类研究不具有普适性.
3 变长时间间隔LSTM 模型
孕妇在孕周时间上的体检统计分布如图2 所示,横轴表示妊娠周,深色的小矩形表示孕妇在对应的妊娠周做了体检,每一横行表示孕妇体检周的一种统计分布,纵轴表示每一种统计分布的人数.例如,孕妇a 的体检时间周是序列[16,20,24,28,30,32,34,35,36,37,38,39],序列中的每一项是做体检的妊娠周,这串序列为一种体检周统计分布,假设孕妇b 与孕妇a 的体检时间周完全一致,即,孕妇b 的体检妊娠周也为[16,20,24,28,30,32,34,35,36,37,38,39],那么,符合该统计分布的孕妇的数量加1,反映在图2 中是最上方的第一横行,横坐标为[16,20,24,28,30,32,34,35,36,37,38,39]处是深色矩形.每一横行在左边对应的纵坐标上的数值是体检的妊娠周完全符合该统计分布的孕妇人数,即,体检孕周是[16,20,24,28,30,32,34,35,36,37,38,39]统计分布的孕妇共有21 人.10 473 个孕妇共有9480 种统计分布.按照每种分布的孕妇人数降序排列,图2 绘制了人数最多的前30 种统计分布.根据图2 可知,在9480 种体检统计分布中,人数最多的仅有21 人,由于大部分孕妇的体检周的分布差异巨大,因此,孕妇的体检记录在妊娠周时间上无法对齐,需要在传统的LSTM 中引入时间信息.
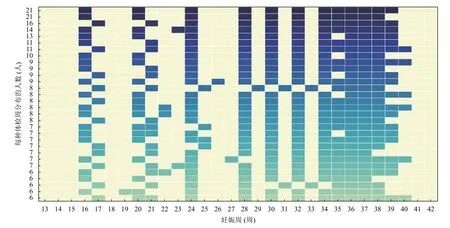
图2 孕妇体检周统计分布图(前30 种统计分布)
本文用P={p1,p2,···,pi,···,pN}表示孕妇集合,用R={r1,r2,···,ri,···,rN} 表示孕妇体检记录集合.N表示孕妇总人数,i表示第i个孕妇,孕妇pi对应的体检记录为ri.每一个孕妇的体检记录和体检时间表示为Mi:=其中,和分别表示第i个孕妇的第k次体检的记录和时间,l表示体检次数.根据当前的妊娠时间Δ和距上次体检的间隔时间Δ的计算方式分别如式(1),式(2):
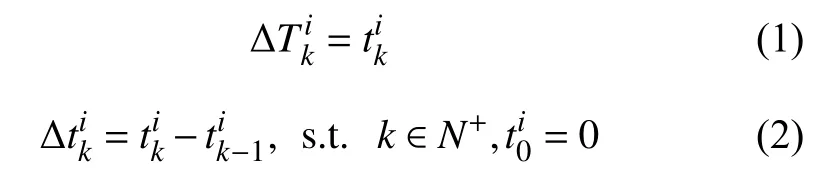
本文的目标是根据Mi,输出胎儿出生体重的预测值.在标准的RNN 和LSTM 中,第k个时间步的输入是xk=其中,⊕ 表示做向量拼接.在变长时间间隔LSTM 中,第k个时间步的输入是xk,由于孕妇第一次体检无间隔时间 Δt,故令
变长时间间隔LSTM 模型即为Variable Time Interval-LSTM(VTI-LSTM).标准的LSTM 模型的表达式[13]如式(3)-式(7):
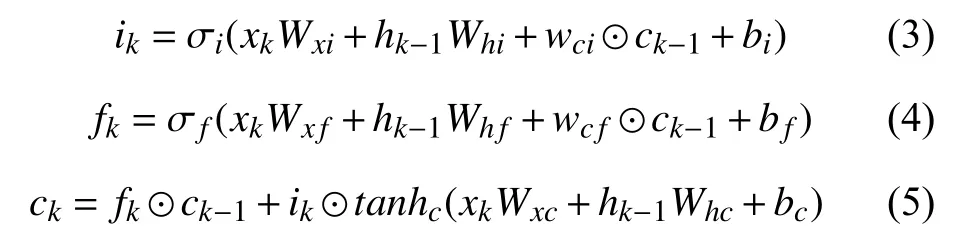
LSTM 模型结构如图3(a)所示.我们将妊娠时间ΔT和间隔时间Δt做嵌入表征[14],如式(8),式(9):

然后,本文分别向Standard LSTM 模型的“输入门”和“遗忘门”中以时间门控的方式引入妊娠时间ΔT和间隔时间Δt,即,将式(5)换为式(10):
对于式(10)中(1-T2k)项,时间间隔的嵌入表征T2k越小,模型对过去事件的“遗忘”越少.而T1k则表示某次体检的妊娠时间对该次输入的“记忆”的多少.VTI-LSTM 模型结构如图3(b)所示,左上角分别是两个“时间门”时间门1 和时间门2,时间门1 的输入是xk和ΔTk,时间门2 的输入是xk和Δtk.
4 实验和数据
4.1 特征筛选
研究表明,胎儿体重不仅与孕妇的宫高[15]、腹围[16]相关,而且与身高体重[17,18]、胎次[19]、年龄、糖尿病[20]等因素有关.本研究中,本文选取孕妇的宫高腹围和高危因素等方便获取的参数作为模型的输入特征.根据数据中的特征,计算各项特征与胎儿体重的皮尔森相关系数和P值.皮尔森相关系数计算公式如式(11).
图3 两个LSTM 模型图
其中,xi和yi分别是两个变量的数据项,和分别是两个变量的平均值,N是样本总数.sx和sy分别是两个变量的标准差.P值即为原假设H0:ρ =0,备择假设H1:ρ ≠0的t分布双边检验.P值计算公式如式(12),式(13):


其中,T服从n-2 自由度的t分布,Pvalue即为P值.计算结果如表1 所示,保留3 位有效数字.我们选择P值低于0.05 的特征,包含妊娠周、年龄、身高、体重、宫高、腹围、胎次、早产史、胎盘异常、胎位不正、胎膜早破、糖尿病、辅助生殖、多胎共14 个特征.其中,妊娠周、年龄、身高、体重、宫高、腹围、胎次属于数值型数据,早产史、胎盘异常、胎位不正、胎膜早破、糖尿病、辅助生殖、多胎属于类别型数据.

表1 相关性分析结果
4.2 数据预处理
将胎儿体重以小于2500 g、在2500 g 和4000 g之间、大于4000 g 为标准分别划分为低体重儿、正常体重儿、巨大儿,如表2 所示,可以看出,低体重儿和巨大儿样本量与正常体重儿数量差距较大,因此在分类任务的训练集中,将低体重儿和巨大儿样本做过采样处理,在总体的回归任务上不做过采样处理.为避免数据中不同的量纲对模型造成影响,本文采用归一化的方式处理数值型数据.绘制胎儿体重分布图,如图4所示,横坐标表示胎儿体重,纵坐标表示与该体重对应的胎儿数量.根据横坐标间距和样本数量,将样本划分为3 段,分别用倒三角、圆点、正三角表示.观察可得,胎儿体重大多集中在中间圆点的区域,两边倒三角和正三角区域则较为稀疏,并且胎儿体重在横坐标上跨度较大,使用常规的归一化方法必然导致中间区域大量样本的归一化结果差异非常小,导致模型表现较差.因此,我们采用分段缩放的方法,牺牲小样本上横坐标的间距,放大大量样本的横坐标间距.倒三角样本点、圆样本点、正三角样本点分布的横坐标区间分别记为I1、I2、I3,区间内胎儿体重数值种类的数量分别记为C1、C2、C3,则各区间的密度分别记为式(14)~式(16),

表2 胎儿体重分类
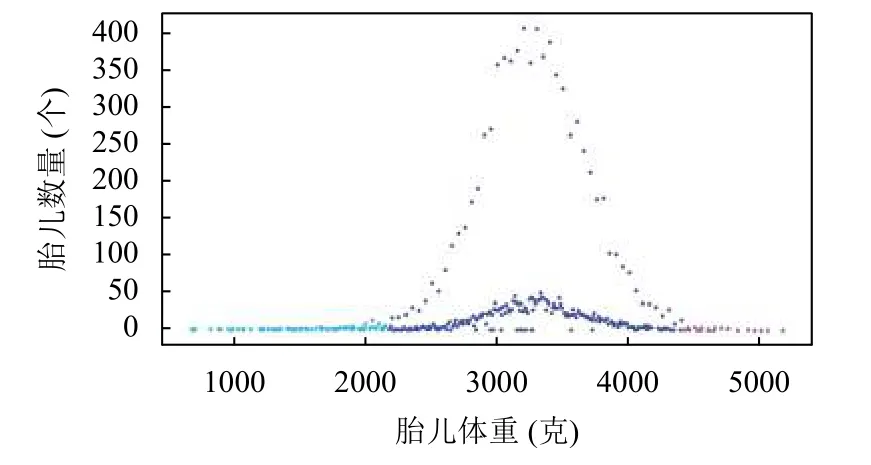
图4 胎儿体重分布图
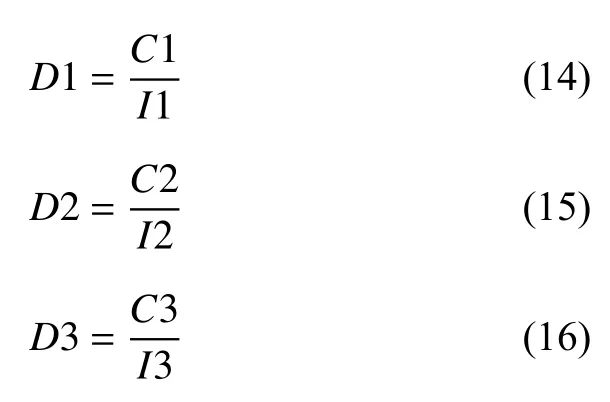
在区间I1 上,对样本进行一次线性归一化,如式(17):
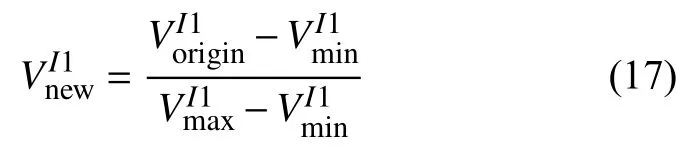

将I1new、I2new、I3new合并为一个大区间,记为Itotal,再对Itotal做一次类似式(14)的线性归一化计算.
经过上述分段缩放和归一化计算,最终,数值类型数据的间隔相对均匀,且保留了各子区间内的线性关系,可提升模型效果.我们对身高、体重、宫高、腹围、胎儿体重5 个数值型数据做了上述计算,其他数值型数据分布较为均匀,仅做简单的线性归一化.对于类别型数据,本文采用one-hot 的编码方式,当某一孕妇的体检记录包含多种类别型数据,那么与该孕妇对应的类别信息为multi-hot 向量.
孕妇的体检次数如图5 所示,横坐标表示孕妇体检次数,纵坐标表示孕妇人数.最少体检次数为1 次,最多体检次数为24 次,孕妇的体检记录是一个变长序列.对于时序模型,需要将孕妇的体检记录做填充.上面提到的特征筛选中,孕妇的一次体检记录共有14 维.本文用1×14 的0 向量将孕妇的体检记录填充至24 次,0 向量不参与模型计算.因此,10 473 个孕妇的122 462条体检记录转化为一个三维矩阵,第一维度表示最大体检次数,第二维度表示每条体检记录的特征数量,第三维度表示孕妇总人数.
4.3 实验设置
本文将产前的体检记录作为模型的输入,胎儿出生体重作为预测目标,10 473 个孕妇的最后一次体检记录与分娩时间在同一周内.实验分为公式法和机器学习方法2 部分.公式法是选取4 个不同的胎儿体重估算公式[5-8]作为对照,4 个估算公式如式(21)~式(24),分别对应公式法1~公式法4.其中,BW是胎儿的出生体重(单位为g),FH是宫高(单位为cm),AG是腹围(单位为cm).

机器学习方法采用GBDT、MLP、SVR、RNN、LSTM、VTI-LSTM 等6 种模型,损失函数采用二次代价函数,如式(25):
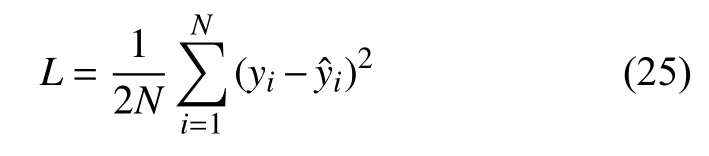
其中,yi和分别是预测值和真实值.N是训练集中孕妇总人数.为直观展示预测误差,我们采用平均相对误差如式(26):

其中,yj是 预测值,是真实值.M是测试集中孕妇总人数.在实际临床工作中,我们更关注异常体重胎儿,仅以回归任务的相对误差作为预测结果显然是不够的,因此,实验分为两个任务:
(1)对低体重儿、正常体重儿、巨大儿的分类.分类按照表2 划分为3 类,我们从低体重儿、正常体重儿、巨大儿中各抽取50 个作为分类任务的测试集,根据分类预测结果计算各类体重的MRE 并绘制混淆矩阵.由于胎儿体重的各类样本数量不平衡,因此需要对训练集中的低体重儿和巨大儿做过采样处理.
(2)计算总体上的回归误差,训练集不做过采样处理,总体回归的测试集保持数据中原始的各类体重儿的比例.训练集和测试集按照10:1 划分.
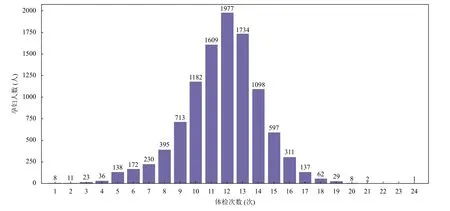
图5 孕妇体检次数分布图
5 实验结果和讨论
胎儿体重预测结果的平均相对误差如表3 所示.其中,实验结果的前3 列是分类任务在低体重儿、正常体重儿、巨大儿的预测上的MRE.第4 列是总体回归任务的误差,也即,前3 列的机器学习方法中,对训练集中的小样本做了过采样处理,第4 列的机器学习方法中,对训练集中的小样本没有做过采样处理,保留原始数据中各类样本的比例.公式法无训练集,直接在测试集上计算即可.总体来看4 个公式法预测的结果弱于机器学习方法.式(21)、式(24)方法包含宫高腹围两个参数,式(22)仅有宫高参数,式(23)仅有一个腹围参数,所以,式(23)法容易受到孕妇腹部脂肪的干扰,结果较差,式(22)相对式(23)较好,但弱于式(21)和式(24).式(21)的预测结果偏向于正常体重儿,在所有的方法中取得最小的正常体重儿预测结果误差.GBDT、MLP、SVR 等3 种经典的机器学习模型的预测结果并无较大差异.RNN、LSTM、VTI-LSTM 等3 种时序模型方法中,LSTM 结果仅次于VTI-LSTM,RNN 结果较差,说明仅使用简单的递归循环难以学习到孕妇多次体检的变化.VTI-LSTM 在低体重儿和巨大儿MRE 上取得最好的预测结果,而在正常体重儿MRE 上弱于式(21).
由于在分类任务中,我们对小样本做了过采样处理,所以导致机器学习模型牺牲正常体重儿的结果,偏向低体重儿和巨大儿.观察第4 列的结果,不做小样本过采样处理的总体回归误差仍旧是VTI-LSTM 效果最好,根据表2 的统计结果,占据样本大多数的正常体重儿的体重范围是2500~4000 g,区间跨度并不大,所以导致机器学习模型的总体MRE 结果相差较小.由于我们采用的是MRE 作为误差度量的方式,根据图4 可以看出,低体重儿的多样性比巨大儿丰富,并且低体重儿计算MRE 公式的分母较小,所以在所有的方法中,低体重儿的MRE 高于巨大儿.
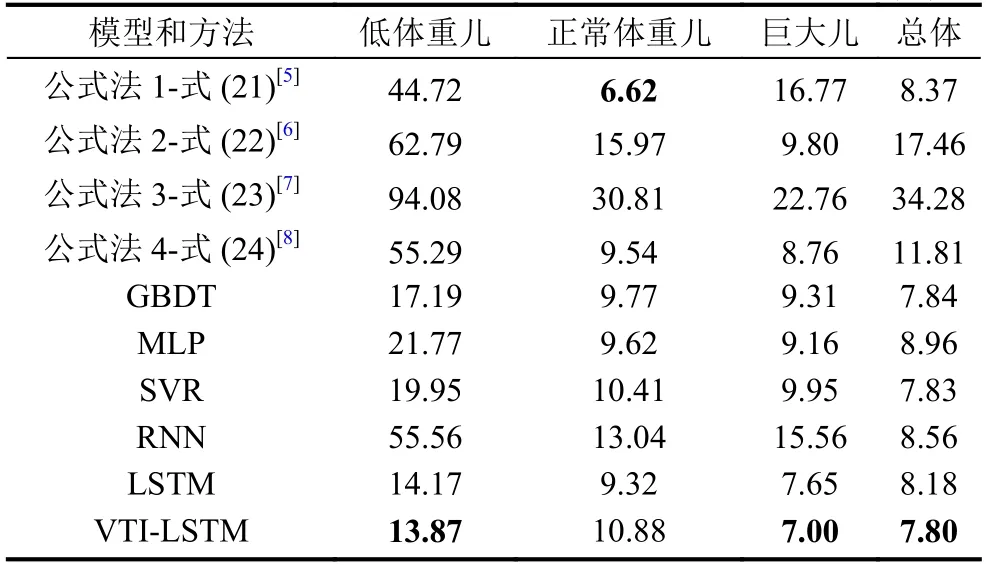
表3 测试集中胎儿体重预测的平均相对误差MRE(%)
分类预测结果的混淆矩阵如图6 所示.纵坐标表示真实类别,横坐标表示预测类别.L表示低体重儿(low birth-weight infant),N表示正常体重儿(normal birth-weight infant),M表示巨大儿(macrosomia).公式法1、公式法2、公式法4 中,将大部分样本分类到正常体重中,仅使用腹围作为预测参数的公式法3 则倾向于将样本分类到巨大儿中,预测结果受到了孕妇腹部脂肪的影响.GBDT、MLP、SVR 三者中,MLP 结果相对较差,GBDT 和SVR 无明显差异.RNN 的分类结果与公式法接近,LSTM 和VTI-LSTM 明显优于其他方法,LSTM 与VTI-LST 相比,LSTM 偏向于分类到正常体重儿中,VTI-LSTM 则在低体重儿和巨大儿的分类中取得最好的结果,说明不均匀离散时间在“输入门”和“遗忘门”上的嵌入表征起到了很大的作用.上述的方法和模型中,无论是哪一种,对低体重儿和巨大儿的分类仍旧是一个挑战.根据表2 中的数据,低体重儿和巨大儿分别仅占新生儿总数的3.41%和3.27%,各类样本比例失衡,虽然在训练集中我们采取了对小样本过采样的预处理方式,但仍旧难以避免小样本数据缺乏多样性的问题.另外,体重低于2 000 g 的低体重儿和体重高于4 500 g 的巨大儿分别占低体重儿和巨大儿较小的比例,导致低体重儿、正常体重儿、巨大儿的分类间隔较小.对比低体重儿和巨大儿的分类,低体重儿的分类结果明显优于巨大儿.原因有如下两点:第一,在我们的特征中,包含孕周信息,分娩低体重儿的孕妇的妊娠时间普遍少于正常的妊娠时长.第二,由于现代社会生活水平普遍较高,胎儿体重偏大,在孕36 周时,许多胎儿已经发育成熟,且体重在正常范围内,这类胎儿和足月儿相比会提前1-2 周分娩,增加了模型识别巨大儿的难度.
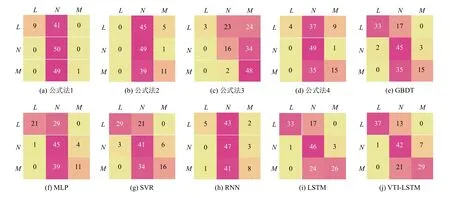
图6 测试集上预测结果的混淆矩阵
6 结论
本研究在胎儿体重预测任务上分别使用了4 种公式法和3 种经典的机器学习方法以及3 种时序模型方法.其中,本研究提出的VTI-LSTM 模型在低体重儿和巨大儿的分类预测中取得了较好的结果并在总体的误差回归上取得最小的MRE.传统的公式法弱于经典的机器学习模型和时序模型.而时序模型中的LSTM 可以学习到孕妇每次体检的变化以及胎儿的生长速率,预测结果有大幅提升.VTI-LSTM 将每次体检的时间间隔和体检的妊娠时间在模型层面上表征,模型可以学习到孕妇体检记录的不均匀时间间隔,又在LSTM 的基础上得到提升.综上,本研究可为医生和孕妇判断胎儿生长发育提供一个相对准确的参考.
猜你喜欢
中国典型病例大全(2022年10期)2022-05-10
现代临床医学(2021年4期)2021-07-31
健康体检与管理(2021年10期)2021-01-03
特别健康·下半月(2020年2期)2020-03-13
小学生学习指导(低年级)(2019年3期)2019-04-22
Coco薇(2015年1期)2015-08-13
读写算·小学低年级(2014年4期)2014-07-24
小雪花·成长指南(2009年10期)2009-12-04
祝您健康(1991年2期)1991-12-30
祝您健康(1989年2期)1989-12-30
