
基于知识图谱的恶意域名检测方法*
2020-03-25 07:34邹福泰
通信技术 2020年1期
张 奕,邹福泰
(上海交通大学 网络空间安全学院,上海 200240)
0 引 言
尽管互联网在不断发展和改善,但是利用互联网的服务和协议进行恶意活动的行为仍然屡见不鲜。域名系统(Domain Name System,DNS)是互联网的基础核心服务之一,主要提供IP地址和域名之间的映射,通俗讲是将人类易记忆的域名翻译为机器易于识别的IP地址。DNS本身是一个完全开放的协作体系,所以域名是各种网络恶意行为(如垃圾邮件、恶意软件、钓鱼网站和僵尸网络等)中使用的主要攻击媒介。为了有效打击网络攻击者,必须有效检测发现恶意域名并加以阻拦。
2016年6月,日本大型旅行社JTB由于员工打开附带恶意域名连接的邮件而遭到非法网络入侵,造成将近800万客户资料外泄,包括姓名、地址及护照号码等。2019年8月,沉寂近3个月的Emotet服务器再次被唤醒,网络攻击者建立了新的传播渠道,利用来自385个顶级域名的3万多个域名发送了垃圾电子邮件,感染美国多个州和地方政府[1]。中国国家计算机网络应急技术处理协调中心发布的《2019年上半年我国互联网网络安全态势》指出,2019年上半年CNCERT自主检测发现约4.6万个针对我国境内网站的仿冒页面,此外CNCERT监测发现恶意电子邮件数量超过5 600万封,涉及恶意邮件附件37万余个,平均每个恶意电子邮件附件传播次数约151次。大部分的恶意行为都与域名系统息息相关,对恶意域名检测的需求日益增长。
近年来,随着计算机设备的计算能力和效率的不断提升,知识图谱和人工智能技术的发展在网络安全相关领域得到了越来越广泛的应用。但是,目前域名检测的主要手段还是基于传统的检测方式,此类方法存在更新维护及时性差且开销大的缺陷。因此,为了解决上述问题,本文建立了一个基于知识图谱的恶意域名检测系统,主要贡献如下:
(1)首次将知识图谱与DNS日志相结合,提出了一种将DNS日志信息转化为知识图谱知识存储与知识表示的方法。
(2)提出使用基于深度学习模型将知识图谱中的属性三元组向量化,完成知识图谱嵌入,并基于此使用神经网络模型进行进一步特征提取。
(3)实现基于知识图谱的恶意域名检测原型系统,采用合理指标进行性能评估实验。实验研究表明,本文提出的恶意域名检测系统具有较高的准确性和适用性。
1 相关工作
目前,最传统的恶意域名检测方法是通过黑名单的方式,但是该方法存在更新维护开销极大的缺陷。由于一些域名快速生成技术(如Fast-Flux、Domain-Flux、Double-Flux等)的兴起,静态检测即黑名单方式越来越不可行。
针对这些转换技术,之后的系统[2-5]主要采用基于功能的方法。这些研究在一定层面上取得了极好效果,但是仍然存在一些潜在问题。这些检测系统大量运用一些人工选择的统计特征(如不同的IP的地址数,TTL的标准偏差等),使得检测系统易被攻击者规避。
此外,文献[6]提出了一种用于发现将来可能会被滥用的恶意域名的系统,系统的关键思想是利用域名的时间变化模式,通过读取DNS日志并分析域名的事件变化模式,从而预测给定的域名是否将用于恶意目的。很大一部分的恶意软件都使用域生成算法(Domain Generation Algorithm,DGA)生成大量伪随机域名,以连接到命令和控制服务器。文献[7]提出了一种DGA分类器,利用长短期记忆(Long Short Term Memory,LSTM)网络预测DGA及其各自的家族,而无需先验特征提取。文献[8]将重点放在基于每个域的检测(和生成)域上,利用生成对抗网络的概念构建基于深度学习的DGA,生成器学习生成越来越难以检测的域名;反过来,检测器模型更新参数,以补偿对抗生成的域从而达到收敛。然而,此类检测方法所用的信息主要为域名本身,其他相关信息使用较少,使得大量信息未被开发。
基于网络结构的恶意域名检测通过将DNS相关数据建模为图形进行进一步分析。文献[9]中,通过分析与顶点区域的偏差和不同顶点域之间的相关性来确定一组独特的特征,以独特地描述图形区域。在这些功能基础上,训练分类器将其应用到大型开放式安全扫描服务VirusTotal中。然而,在上述网络方法的限制下,几乎所有这些研究人员都将DNS相关数据建模为客户端域双向图[10]或域-IP双边图[11]。在这种情况下,它们最多只能代表两种类型的实体,大量其他关系仍未被挖掘。
不同于上述已有工作,本文结合DNS日志信息,将DNS响应记录和DNS权威相应资源记录,利用知识图谱进行知识表示,并完成其向量化的工作,基于神经网络模型实现对恶意域名的检测。
2 相关知识
2.1 知识图谱
知识图谱于20世纪中叶被普莱斯等人提出。1977年,知识工程的概念亮相于第五届人工智能大会,以专家系统为代表的知识库系统开始被研究。直到2012年,谷歌[12]正式提出知识图谱的概念,并将其应用于搜索业务。知识图谱是一种用图模型来描述知识和建模世界万物之间的关联关系的技术方法[12]。
2.1.1 知识表示
知识表示主要研究如何利用计算机符号来表示人脑中的知识。三元组是最常用的一种表示方法,即G=(E,R,S),其中E是知识图谱的实体集合,R是知识图谱中的关系集合,S ⊆E×R×E 代表知识图谱中的三元组集合。三元组集合的表现形式包括头实体、尾实体、边关系、属性和属性值等。虽然通过这样的离散的符号化表达方式可以有效将数据结构化,但是这些符号并不能在计算机中表达对应的语义信息并进行计算。
为了解决上述问题,知识图谱研究者在词向量的启发下,将知识图谱中实体和关系映射到连续的向量空间。知识图谱的嵌入也是通过人工智能的模型进行学习,但是该方法的训练需要监督学习。如图1所示,在知识图谱嵌入的学习过程中,模型将三元组转化为同一维度的向量。
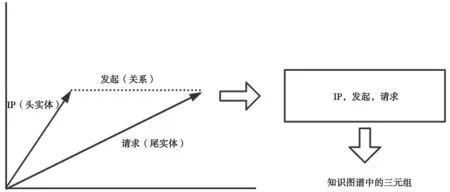
图1 语义信息嵌入知识图谱的向量表示方法
2.1.2 知识图谱嵌入的主要方法
多数知识图谱以所有已知的三元组进行模型训练,但是这样的任务难以满足所有的应用,所以当前的研究开始关注知识图谱中额外信息的嵌入,如属性值、实体类型及关系路径等。
目前,知识图谱嵌入的方法主要分为3类——转移距离模型、语义匹配模型和考虑附加信息的模型。其中,以TransE模型[13]为代表的转移距离模型的应用最广泛。
TransE作为知识图谱嵌入的主要手段,完成了实体与关系的向量化,也为本文的嵌入模型提供了基础支撑。
2.2 神经网络模型
双向长短期记忆网络由前向LSTM与后向LSTM组合而成。一个前向的LSTM利用过去的信息,一个后向的LSTM利用未来的信息。在当前时刻下,可以同时利用双向的信息,所以会比单向LSTM的预测更加准确。
BiLSTM的结构如图2所示,每个节点为LSTM神经元。训练过程中,将每个训练序列分为前向和后向两个独立的递归神经网络,并最终连接同个输出层。
3 系统设计
3.1 系统概述
本文系统通过搭建知识图谱嵌入模型,通过神经网络进行分类,最终实现恶意域名检测的功能。系统框架图如图3所示,首先对DNS日志信息进行预处理,获取所需的统计特征后,提取出对应的实体、关系以及属性存入知识图谱。其次,将知识图谱中的存储实体通过设计的嵌入模型完成数据向量化表示。最后,基于嵌入模型的输出,利用神经网络模型进行训练和验证。下面将详细讲解系统的各个模块。
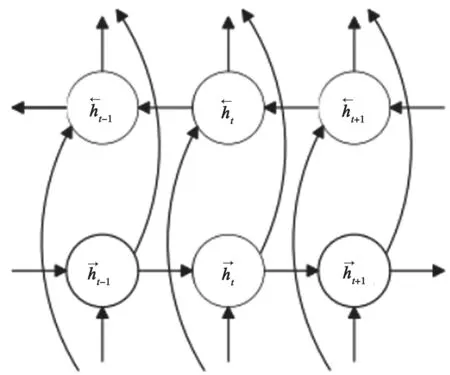
图2 双向LSTM结构

图3 系统框架
3.2 数据预处理
本文的原始研究数据集为DNS日志,包括DNS响应记录和DNS权威相应资源记录。本模块将日志中的数据与知识图谱中的实体、关系以及属性相转换。
主要的转换实体如图4所示。客户端IP为请求发起方,DNS请求实体主要包含属性如表1所示,DNS应答实体主要包含属性如表2所示。

图4 主要转换实体

表1 DNS请求实体属性

表2 DNS应答实体属性
除了上述表1和表2中的属性外,通过处理数据提取了频率、存活时间等统计特征作为实体属性,之后将处理完的数据存入知识图谱数据库中,为嵌入模块提供数据支撑。
3.3 嵌入模型
本文使用的嵌入模型不单单对于实体和关系进行嵌入,也包含了对于属性值的嵌入。嵌入模型主要由两部分组成,一部分为三元组的嵌入,另一部分为实体属性的嵌入,如图5所示。

图5 嵌入模型
为了使得属性嵌入与三元组嵌入的结果处于一个统一的向量空间,系统会同时训练这两个模块,其中三元组嵌入使用TransE来进行实体对其的嵌入。TransE是基于实体和关系的分布式向量表示,模型受word2vec启发,利用了词向量的平移不变现象。其中,定义一个距离函数d(h+r,t),用来衡量h+r和t之间的距离,在实际应用中可以使用L1或L2范数。在模型训练过程中采用最大间隔方法,最小化目标函数,目标函数如下:
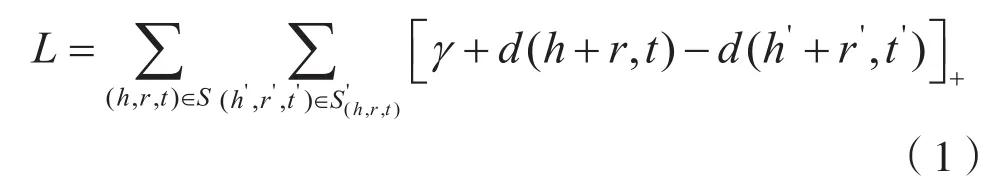
其中,S为三元组集合;S´为负采样的三元组,通常随机生成;γ为取值大于0的间隔距离参数。梯度更新只需计算距离 d(h+r,t)和 d(h´+r´,t´)。
对于属性嵌入,同样借鉴上述模型的思想,但是差别在于将属性作为三元组中的关系以及将属性值作为三元组中的尾实体进行训练。由于在这个基础上的训练的最终结果会导致属性值类似于实体的情况存在,为了避免某些含义不同的相同值被重复训练,如AA的属性值为1、TC的属性值同样为1,如果同时训练两者会导致最终的训练结果指向同一个属性值1,但在含义上两者是不同的,所以系统对属性值进行了区分。
3.4 神经网络模型
本系统的神经模型网络模型如图6所示。
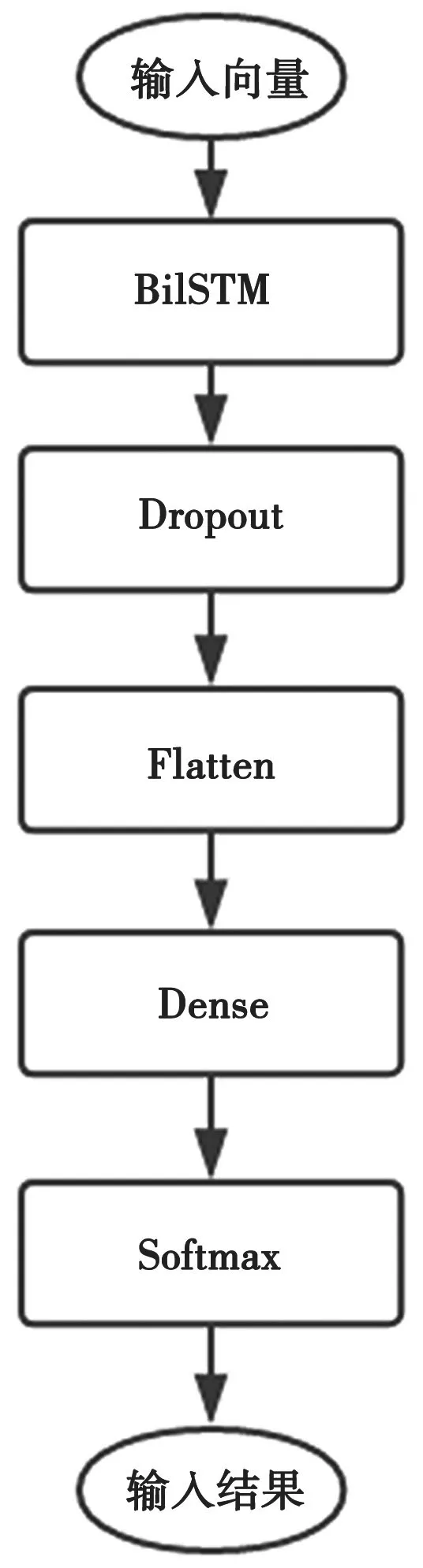
图6 神经网络模型
嵌入模型完成了输入的向量化过程,所以神经网络模型主要用于分类,模型的输入为实体、关系以及属性值的序列化向量。考虑到长度不一的问题,这里对于数据进行分析,选取合适的长度对过长的序列进行截取,对过短的序列进行补长处理。
本模型选用BiLSTM双向长短期记忆网络的优点在于能够学习序列中向量的上下文关系,同时包括前向的向量和后向的向量,从而更好地提取特征进行分类。
4 实验结果与分析
4.1 实验准备
本文实验基于ubuntu16的系统,训练用显卡为Nvidia 1080Ti,使用基于Keras的主流深度学习框架进行训练。
本文使用的数据集为某网络中心抓取的7日DNS日志信息镜像信息,约有42亿条数据。为了从中获取有效的训练数据集,构建了一个程序对其进行过滤。在过滤掉一部分无用日志信息后,基于原有的恶意域名黑名单采集负面样本(黑名单上的恶意域名通过VitusTotal进行验证),而对于正面样本选取Alexa前1 000的域名作为筛选标准。然而,在这种情况下,正面样本和负面样本的比例极度不均衡,负面样本的比例较少,最后通过随机选取正面样本的方式保持数据集的正负样本比例为1:1。
正负样本的个数都为6 180个,通过将正负样本转化为知识图谱中的实体、属性值和关系后,可以获取28 950个实体以及属性值实体和39种关系。这里将属性值同样看为实体是基于嵌入模型,因为在训练过程中属性值与实体是等价的。
4.2 评价指标
本系统的主要模型表现为最终的检测结果,所以主要选取准确率和F1-Score,计算方式如下:
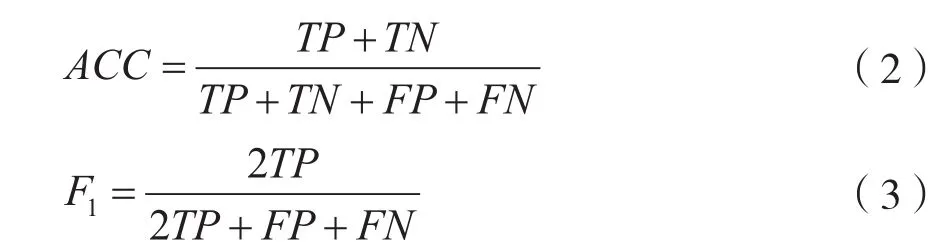
其中TP是将正类预测为正类的数量,TN是将负类预测为负类的数量,FP是将负类预测为正类的数量,FN为将正类预测为负类的数量。
4.3 结果与评估
本系统的最终目标为检测出恶意域名。为了更好地比较检测结果,对使用RNN模型、LSTM模型以及BiLSTM模型的检测模型分别进行实验观测,综合比较其优劣。
对于数据集,采用8:2的比例重新划分训练集和测试集。通过嵌入模型,所有的实体、属性值以及关系已经转换为100维向量。同时,综合比较训练集中的序列长度,选取的序列长度为68。对于长度不足的序列,通过补零向量补至长度为68;对于长度过长的序列则进行截取。
表3显示了各模型在不同训练迭代时的准确率,这里的F1值基于正面样本。实验整体采用消融分析的方式,将模型的batchsize设置为64。通过实验发现,当epoch选为20时,模型已经基本收敛,模型的分类效果已经达到全局最优。
从表3可以看出,对于3种不同的神经网络分类模型,无论是ACC值还是F1-Score值,BiLSTM明显优于另外两种,而LSTM相较于RNN也更优。在训练集上,模型的准确率最高可达99.31%,F1-Score最高可达99.32%。
综上,在进行恶意域名检测时,BiLSTM效果良好,原因可能在于输入序列在前后文的内容上存在较强的关联性,同时验证了本系统嵌入模型的优越性。
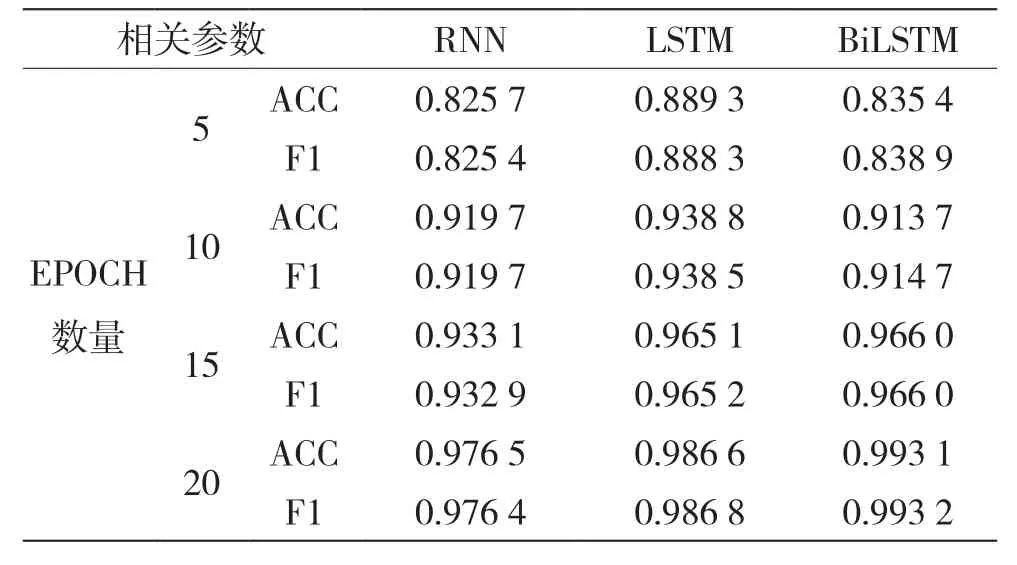
表3 不同模型的实验结果
5 结 语
本文提出了一个高准确率的基于知识图谱的恶意域名检测系统,使用知识图谱嵌入模型和BiLSTM深度神经网络等技术,从DNS日志中整合有效信息,深度提取信息特征,最终完成恶意域名的检测分类。实验证明,该系统检测性能良好,相较其他模型有较高的准确率。然而,系统仍有部分不足,后续工作将主要针对系统的泛化能力和对一些额外统计特征的研究进一步提高对恶意域名的检测能力。
猜你喜欢
军事文摘(2022年24期)2022-12-30
北京航空航天大学学报(2022年8期)2022-08-31
计算机与生活(2022年3期)2022-03-13
少先队活动(2020年12期)2021-01-14
江苏教育研究(2020年2期)2020-04-10
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机技术与发展(2018年12期)2018-12-20
计算机系统应用(2017年5期)2017-06-07
领导科学论坛(2016年9期)2016-06-05
互联网天地(2012年6期)2012-03-24
